Word Representation이란
머신러닝이나 딥러닝을 통한 분석을 하기 위해 자연어를 의미있는 형태로 표현하는 것을 의미합니다.
- 자연어 ?
자연어란 옛날부터 자연스럽게 사용하면서 생성되고 발전되어 온 언어를 뜻합니다.
예를들어 한국어나 일본어 영어와 언어를 의미합니다.
의미있는 형태 ?
자연어를 아무렇게나 표현한다면 의미있는 분석을 하기 어렵습니다.
옛날부터 자연어를 의미있는 형태로 표현하기 위해 여러가지 방법을 사용했습니다.
처음에는 단순하게 문장에서 단어들을 어떻게 표현할까? 라는 고민부터 시작했습니다.
그 생각의 결과는 One-hot Vector와 Count기반의 표현방법입니다.
-
One-hot Vector
원핫벡터는 벡터들 중 한 원소만 1인것을 말합니다.
이 원핫 벡터를 사용하여 단어를 표현하는 방법은 각 단어에 고유 인덱스를 부여하는 것 입니다.
word_list = [ "오늘", "날씨가", "좋다" ]
one_hot_word = []
#1
for i in range(len(word_list)):
one_hot=[0] * len(word_list)
one_hot[i] = 1
one_hot_word.append(one_hot)
#2
import numpy as np
one_hot_word = np.eye(len(word_list), dtype=int32)

-
Bag of Words (BoW)
Bow는 말 그대로 단어 주머니라고 생각하시면 됩니다.
"어제 날씨가 흐렸는데,오늘 날씨가 좋다" 라는 문장이 있을 때 (어절단위분석),어제 : 1
날씨가 : 2
흐렸는데 : 1
오늘 : 1
좋다 : 1위와 같이 단어의 빈도수를 나타낼 수 있고 이 표현을 그대로 사용하는 것이 bag of word입니다.
"어제 날씨가 흐렸는데,오늘 날씨가 좋다" 라는 문장은 [ 1, 2, 1, 1, 1 ]로 표현할 수 있습니다.
import re
source = "어제 날씨가 흐렸는데, 오늘 날씨가 좋다"
#컴마 삭제
source = re.sub(",","",source)
source = re.split(" ",source)
print(source)
dic = {}
Bow = []
for word in source:
if word not in dic:
dic[word] = len(dic)
Bow.insert(len(dic)-1,1)
else:
index = dic[word]
Bow[index] += 1
print(dic)
print(Bow)
Bow의 표현방법은 2개 이상의 문장이나 문서들을 표현하고 그 사이의 유사도를 구하는데에 사용하기도 했습니다.
import re
source1 = "어제 날씨가 흐렸는데, 오늘 날씨가 좋다"
source2 = "좋다 오늘 날씨가, 흐렸는데 어제 날씨가"
sources = [source1, source2]
dic = {}
Bow = []
for source in sources:
#컴마 삭제
source = re.sub(",","",source)
source = re.split(" ",source)
tmp_Bow = [0]*len(set(source))
for word in source:
if word not in dic:
dic[word] = len(dic)
tmp_Bow[dic[word]] += 1
else:
index = dic[word]
tmp_Bow[index] += 1
Bow.append(tmp_Bow)
print(dic)
print(Bow)
result = sum([ a*b for a,b in zip(*Bow)])
print(result)
결과를 보시면 눈치를 채셨겠지만 Bow는 단어의 빈도수로만 문장을 표현하기 때문에 이 단어가 어떤 순서로 이루어져 있는지는 전혀 고려하지 않습니다. 따라서 2개의 문장이 전혀 다른 의미여도 비슷한 단어가 많이 나온다면 유사도가 높은 문장이라고 판단하는 단점이 있습니다.
유사도는 Bow로 표현된 문서들끼리 요소별로 곱하여 모두 합친 값을 사용합니다.
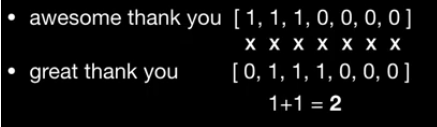
import re
source1 = "나는 파인애플 피자가 좋아"
source2 = "나는 파인애플 파인애플 음료수가 좋아"
source3 = "나는 피자가 좋아"
sources = [source1, source2, source3]
N = len(source2.split())
dic = {}
Bow = []
for source in sources:
#컴마 삭제
source = re.sub(",","",source)
source = re.split(" ",source)
tmp_Bow = [0]*N
for word in source:
if word not in dic:
dic[word] = len(dic)
tmp_Bow[dic[word]] += 1
else:
index = dic[word]
tmp_Bow[index] += 1
Bow.append(tmp_Bow)
print(dic)
print(Bow)
result = 0
for i in range(len(Bow)):
for j in range(i+1,len(Bow)):
a=sum([a*b for a,b in zip(Bow[i],Bow[j])])
print(f"{sources[i]} -- {sources[j]}의 유사도 : {a}")
문장의 의미상 피자와 음료수는 전혀 관계가 없음에도 파인애플의 빈도수가 높아 문장의 유사도 또한 높게 측정되는 오류가 있는 것을 알 수 있습니다. 또한 문장의 중요한 요소인 단어의 순서가 무시가 되고 있습니다. 마지막 단점은 총 단어의 개수가 커질 수록 각 문장도 총 단어의 개수만큼 표현되기 때문에 효율성도 낮다고 판단할 수 있습니다.
-
TF - IDF ( Term Frequency Inverse Document Frequency)
TF : Bow와 같은 개념으로 단어의 빈도수를 의미합니다.
DF : 특정 단어가 문서에 등장한 빈도 수 ( 특정 문서에서 단어가 많이 나온다해도 1개로 측정 )
위의 예에서 파인애플의 DF는 2이고 source2에서 파인애플이 2번 나왔어도 빈도수는 1이다.IDF : DF값에 역수를 표현한 값.
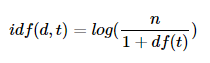
IDF가 의미하는 것은 특정한 단어가 여러 문서에서 빈번하게 등장하면 그 단어는 중요도가 매우 낮은 단어라는 의미를 가지고 있다. 위의 파인애플이 여러 문장에서 등장하면 그 중요도를 낮게 측정하겠다 라는 의미
log가 없을때 DF값이 작아질 수록 배수적으로 IDF값이 커지기 때문에 가중치의 차이를 줄여주기 위해 사용한다.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
source1 = "나는 파인애플 피자가 좋아"
source2 = "나는 파인애플 파인애플 음료수가 좋아"
source3 = "나는 피자가 좋아"
DOCS = [source1, source2, source3]
print("=============Bow=================")
vector = CountVectorizer()
print(vector.fit_transform(DOCS).toarray())
print("=============TF-IDF=================")
tfidfv = TfidfVectorizer().fit(DOCS)
print(tfidfv.transform(DOCS).toarray())
print(tfidfv.vocabulary_)

위와 같은 표현방법들은 결국 문장의 순서를 고려하지 않고 단어의 개수가 증가할 수록 표현해야하는 벡터의 차원도 그만큼 증가한다는 단점이 있습니다. 이 문제를 해결하기 위해 나온 방법으로 단어를 분산으로 표현하는 방법들이 등장하기 시작했습니다.
-
단어의 분산표현
단어의 의미는 주변 단어에 의해 형성된다는 분포가설에 기반을 두어 표현하는 방법입니다.
i guzzle beer
i drink wineguzzle과 drink는 앞 뒤의 문맥단어(context word)를 통해 비슷한 의미를 가진다는 것을 알 수 있습니다.
이처럼 나는 파인애플 피자가 좋아 의 문장을 분산표현을 하면,
나는 파인애플 피자가 좋아 나는 0 1 0 0 파인애플 1 0 1 0 피자가 0 1 0 1 좋아 0 0 1 0 위와 같이 양 옆의 단어 1개를 고려한 행렬의 형태로 표현할 수 있는데 이를 동시발생행렬이라고 합니다.
동시발생행렬의 문제점은 한국어에서는 "-은,-는 ..." , 영어에서는 "a, the..."와 같은 불용어들 때문에 의미를 파악하기에 문제가 생길 수 있습니다.drive the car
wash the car
drive the car
위의 예시처럼 결국 car --- drive과의 관련성이 더 높아야하는데 앞의 "the"가 더 많이 출현하여 의미를 파악하기 어려울 수 있습니다.
이 문제를 해결하기 위해 나온 방법이 PMI(Pointwise Mutual Infomation)입니다.
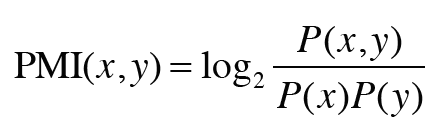
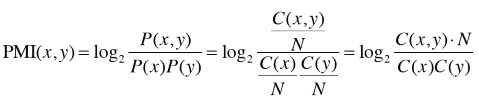
예를들어, "the"와 "car"와 "drive"라는 단어가 1000번, 20번, 10번 등장하고
"the"와 "car"가 동시에 발생한 횟수를 10번, "car"와 "drive"가 동시에 발생한 횟수를 5회라고 가정할 때
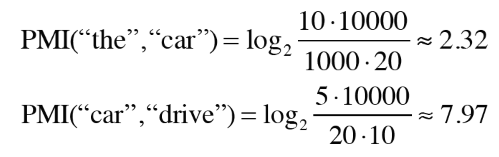
결과적으로, PMI("the", "car") 보다 PMI("car", "drive")의 값이 더 큰 것을 볼 수 있습니다.
이 PMI를 바로 적용하면 동시발생 횟수가 0이 되면 PMI값이 음의 무한대의 값을 나타내기 때문에
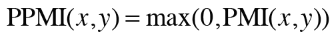
PPMI를 적용하여 항상 양의 값을 사용합니다.
동시발생행렬을 PPMI를 적용하여 나타낼 수 있습니다.
"나는 파인애플 피자가 좋아 너도 파인애플 피자가 좋지"
| 나는 | 파인애플 | 피자가 | 좋아 | 너도 | 좋지 | |
|---|---|---|---|---|---|---|
| 나는 | 0 | 1 | 0 | 0 | 0 | 0 |
| 파인애플 | 1 | 0 | 2 | 0 | 1 | 0 |
| 피자가 | 0 | 2 | 0 | 1 | 0 | 1 |
| 좋아 | 0 | 0 | 1 | 0 | 1 | 0 |
| 너도 | 0 | 1 | 0 | 1 | 0 | 0 |
| 좋지 | 0 | 0 | 1 | 0 | 0 | 0 |
PPMI
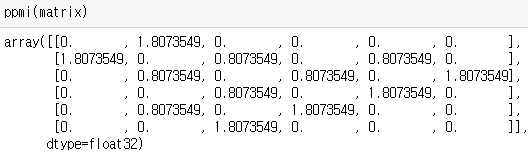
위와 같은 PPMI 행렬을 얻었을 경우, "피자가"와 "좋지" 관련성이 더 높다고 판단할 수 있습니다.
그런데 위의 행렬을 보시면 대부분의 원소들이 0인것을 확인할 수 있습니다.
이런 형태의 행렬을 희소행렬 ( sparse matrix )이라고 표현합니다.
벡터의 대부분의 정보들이 중요하지 않다는 것을 의미하는데 이 문제를 해결하기 위해
차원축소를 통하여 밀집벡터 ( dense matrix ) 로 표현할 수 있습니다.
차원을 감소시키는 방법중에 특이값 분해(SVD)를 이용합니다.
특이값 분해는 임의의 행렬 를 아래와 같이 분해할 수 있는 행렬 분해 중 한가지 방법입니다.
U와 V는 직교행렬이며 그 열벡터는 서로 직교
S는 대각행렬 (대각성분 외, 모두 0인 행렬)
U행렬은 하나의 "단어 공간"으로 취급할 수 있고, S는 대각행렬로 그 대각성분에는 "특이값"이 큰 순서대로 나열되어 있습니다. 이 값들은 중요도로 간주됩니다.
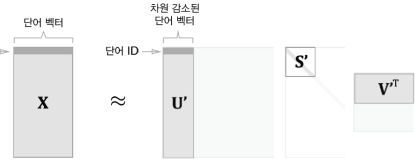
이 방법을 적용하여 희소벡터를 밀집벡터로 변환이 가능합니다.
- 단어의 추론표현
추론기반으로 단어를 표현하는 방식은 현재 딥러닝에서 다양하게 사용되는 방법이다.
추론기반이란 맥락이 주어졌을 때, 해당 위치에 어떠한 단어가 들어가야 하는지 추측하는 것이다.
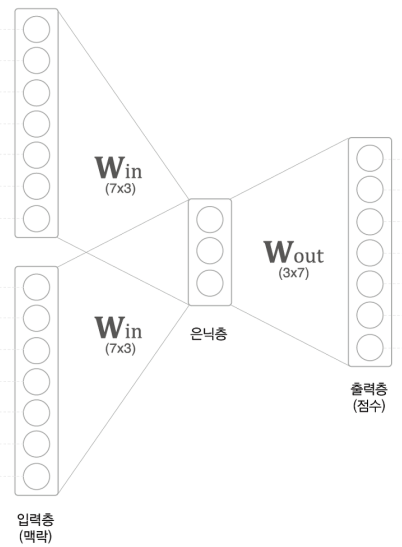
위와 같이 입력단어의 원핫벡터값이 가중치 과 행렬곱하여 나온 결과를 과 행렬곱하여 그 값으로 어떤 단어가 나와야하는지 추론하는 기법이다.
여기서 단어의 표현으로 쓰이는 부분은 으로, 정답을 찾아가기 위해 학습이 계속 진행되며 학습이 완료된 벡터를 사용한다.

단어의 추론표현은 현재 널리 사용하고 있으며 최근에는 단어를 학습시키기 위한 효율적인 기법과 모델들이 다양하게 나오고 있어 자세한 내용은 따로 공부를 해야 할 것으로 보인다.
