Relation Extraction
문장 속 단어간의 관계성을 파악하는 Task를 말한다.
이 Task의 목적은 관계성을 파악해 문장의 전체적인 의미나 의도를 해석하는데 도움을 줄 수 있다.
관계추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조화된 검색이나 감정 분석 혹은 질문에 답변, 요약과 같이 자연어처리 전반적인 Task에 도움을 줄 수 있다.
목표
- private에서 성능이 하락하지 않도록 보다 강건한 모델을 만들어보는게 목표!
- 협업을 위한 git을 사용해보자!
- gitflow 전략 사용해보기!
Model
- BERT
- ELECTRA
- RoBERTa
왜 이모델을 선택했나?
어떤 단어(Entity)들 간의 관계를 파악하기 위해서는 단어의 임베딩 벡터가 중요하다고 생각한다.
이 Task의 SOTA모델들도 BERT기반의 Encoder모델이 대부분 차지하고 있다.
따라서 baseline으로 BERT의 성능을 파악했고 뒤이어 BERT기반의 Encoder모델들로 실험을 하여 가장 우수한 성능을 내는 모델을 선택했다.
RoBERTa는 BERT와 달리 더 많은 데이터와 큰 배치사이즈를 사용하였고 NSP를 제거, Dynamic Masking기법을 적용한 모델이다. BERT를 개선한 모델로 볼 수 있으며 성능지표 또한 BERT보다 높은것을 확인할 수 있었다. ELECTRA는 BERT보다 성능이 낮은 것을 확인할 수 있었는데 Pretraining당시 Original인지 replace인지 확인하는 Discrimination Model이 Token을 적절한 값으로 나타내는게 다소 부족하여 나타난 현상이라고 생각한다.
모델 개선
- Entity Embeddings
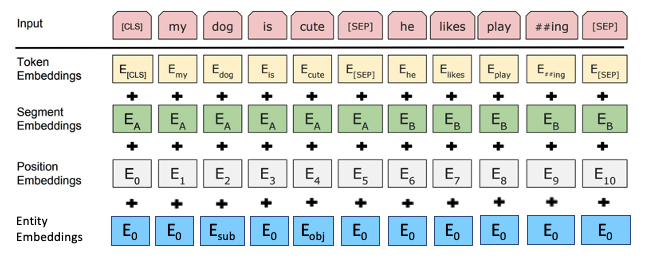
Entity 정보를 모델에게 구체적으로 전달해주기 위해 Entity Embedding Layer를 추가
- Entity Type Embeddings
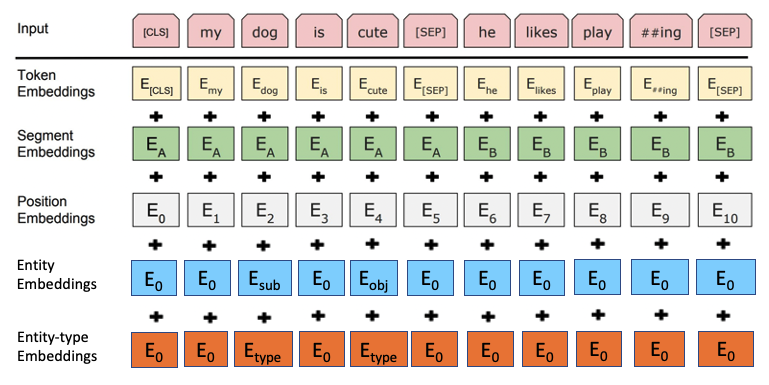
Entity에는 6가지 Type이 존재하는데 이 Type에 대한 Embedding Layer를 추가
- Specific
관련 논문으로 R-BERT가 존재하는데 CLS토큰 벡터를 사용하여 분류하는 것이 아니라 Entity들의 벡터들을 평균내어 분류하는 모델
- Multi-Sentence
Input Data에 Sub-Entity와 Obj-Entity의 관계는?이라는 문장을 추가하여 전달
결과
| MODEL | AUPRC |
|---|---|
| BERT | 74.812 |
| ELECTRA | 70.195 |
| RoBERTa | 75.029 |
| RoBERTa with Entity | 79.579 |
| RoBERTa with Entity type | 75.231 |
| RoBERTa with Specific | 75.424 |
| RoBERTa(multi) | 78.334 |
아쉬웠던 점
-
모델을 선정하고 기본 성능을 파악하기 위한 코드를 짜는데 많은 시간을 사용하여 다양한 시도를 못해봤다.
-
validation data의 분포와 test data의 분포가 상이하여 validation 성능을 일반화하기 힘들었다.
다양한 시도 및 생각해볼 점
-
validation data를 만들때 최대한 test data의 분포와 비슷하게 맞추는 작업이 필요할 것 같다.
-
협업을 하기 위한 코드를 짜는게 중요하다고 생각한다. 내가 실험하기 편하게만 하다보면 협업에 문제가 생길 수 있다.
-
데이터 증강을 할때 BERT의 MLM기능을 사용해볼 필요가 있을것 같다.
