이 글은 백기선님의 라이브 스터디 참여 및 학습 내용에 관한 정리한 글입니다.
학습 목표
- Thread 클래스와 Runnable 인터페이스
- 쓰레드의 상태
- 쓰레드의 우선순위
- Main 쓰레드
- 동기화
- 데드락
멀티 쓰레드의 경우 쓰레드로 부터 연관된 주제들이 다양하다. 동기화, 비동기화, ExecutorService, Collable, Future, CompelteableFuture 등등 다양한 내용이 파생되는데 일단 나는 Thread를 완벽히 이해를 한 상태가 아니며, 주의해야하고 자주 듣게되는 내용이지만 실제로 누군가에게 설명하라고 한다면 말문이 막혀 명확하게 설명을 못할 것 같다. 따라서 이번 기회를 통해 차근차근 다시 복습하며 정리해나가려고 한다.
쓰레드 연관 용어
멀티 태스킹(Multi-Tasking)
현재 우리가 사용하는 윈도우나 유닉스를 포함한 대부분의 OS는 멀티 태스킹을 지원하기 때문에 여러 개의 프로세스가 동시에 실행될 수 있는 환경이다.
멀티 쓰레딩(Multi-Threading)
하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것. CPU의 코어가 한 번에 단 하나의 작업만 수행할 수 있으므로, 실제로 동시에 처리되는 작업의 개수는 코어의 개수와 일치한다.
그러나 처리해야하는 쓰레드의 수는 언제나 코어의 개수보다 훨씬 많기 때문에 각 코어가 아주 짧은 시간동안 여러 작업을 번갈아 가며 수행함으로써 여러 작업들이 모두 동시에 수행되는 것처럼 보이게 한다.
프로세스의 성능이 단순히 쓰레드의 개수에 비례하는 것은 아니며, 하나의 쓰레드를 가진 프로세스 보다 두 개의 쓰레드를 가진 프로세스가 오히려 더 낮은 성능을 보일 수 도 있다.
멀티 쓰레딩의 장단점
- 장점
- cpu의 사용률을 향상시킨다.
- 자원을 보다 효율적으로 사용할 수 있다.
- 사용자에 대한 응답성이 향상된다.
- 작업이 분리되어 코드가 간결해진다.
- 단점
- 멀티 쓰레드 프로세스는 여러 쓰레드가 같은 프로세스 내에서 자원을 공유하여 작업을 하기 때문에 발생할 수 있는 동기화, 교착상태와 같은 문제들이 발생할 수 있다. 따라서 개발자는 이와 같은 문제들을 고려하여 신중이 프로그래밍을 해야 한다.
Process, Thread 차이
Process
- 단순히 실행 중인 프로그램이라고 할 수 있다.
- 사용자가 작성한 프로그램이 운영체제에 의해 메모리 공간을 할당받아 실행 중인 것을 말한다.
- 프로세스는 프로그램에서 사용되는 데이터와 메모리 등의 자원 그리고 쓰레드로 구성된다.
Thread
- 프로세스 내에서 실제로 작업을 수행하는 주체를 의미한다.
- 모든 프로세스에는 한 개 이상의 쓰레드가 존재하며 작업을 수행한다.
- 두 개 이상의 쓰레드를 가지는 프로세스를 멀티 쓰레드 프로세스(Multi-Threaded Process)라고 한다.
쓰레드의 생성과 실행
자바에서 쓰레드를 생성하는 방법으로 2가지 방법이 있다.
생성 방법
1. Runnable 인터페이스를 구현하는 방법
2. Thread 클래스를 상속받는 방법
각각 방식별로 run() 메서드를 오버라이딩을 하여 개발자가 각 쓰레드별로 실행되길 원하는 코드 흐름을 작성하면된다.
실행 방법
쓰레드 클래스의 start() 메소드를 호출
쓰레드객체.start();
Runnable 구현 방법
RunnableSample
public class RunnableSample implements Runnable {
@Override
public void run() {
System.out.println("RunnableSample : " + Thread.currentThread().getName());
}
}ThreadSample
public class ThreadSample extends Thread {
@Override
public void run() {
System.out.println("ThreadSample : " + Thread.currentThread().getName());
}
}MainSample
public class MainSample {
public static void main(String[] args) {
// 1. Runnable 구현체인 RunnableSample을 쓰레드 생성자에 넣고 생성.
Thread thread = new Thread(new RunnableSample());
thread.start();
// 2. Thread를 상속한 TreadSample 자체를 인스턴스화하여 생성
ThreadSample threadSample = new ThreadSample();
threadSample.start();
System.out.println("Main Method : " + Thread.currentThread().getName());
}
}
console 출력
ThreadSample : Thread-1
Main Method : main
RunnableSample : Thread-0Runnable의 구현체일 경우 Tread클래스 생성자에 RunnableSample객체를 인자로 넣어서 쓰레드를 인스턴스화 시키면되고, Thread를 상속한 ThreadSample은 바로 해당 클래스를 인스턴스화 시켜서 생성하면 된다.
Thread 을 실행하는 것은 구현체에 start() 메소드를 호출해주어야 비로소 쓰레드가 실행되는 것이며, JVM이 해당 쓰레드의 run() 메소드를 호출하여 실행되는 구조다.
해당 출력문을 보면 main메소드의 쓰레드 각각 쓰레드를 구현화 한 객체들의 쓰레드의 name 값이 다른 것을 볼 수 있다.
start() 주의점
- 사실 start() 호출되었다고 바로 실행되는 구조가 아니다. 일단 먼저 '실행대기' 상태에 들어가게 되며 자신의 차례가 오면 실행되는 구조이다. 물론 실행대기 중인 쓰레드가 하나도 없다면
바로 실행 상태로 넘어간다.
참고: 쓰레드의 실행순서는 OS의 스케줄러가 작성한 스케줄에 의해 결정된다. - 한 번 실행이 종료된 쓰레드는 다시 실행할 수 없다. 따라서 하나의 쓰레드에 대해서 start()는 단 한 번만 호출될 수 있다. 만약에 start()를 두 번 이상 호출하게 되면 IllegalThreadStateException이 발생하게 된다.
Thread thread = new Thread(new RunnableSample());
thread.start();
thread.start();
console 출력:
Exception in thread "main" java.lang.IllegalThreadStateException
at java.base/java.lang.Thread.start(Thread.java:794)
at study.algorithm.studysample.MainSample.main(MainSample.java:9)쓰레드의 실행 순서
각 쓰레드가 독립적으로 자신이 맡은 일을 수행하는 것을 볼 수 있다. 그런데 각 여러개의 쓰레드가 존재할 때 각 쓰레드가 실행되는 순서는 어떻게 될까?
결론부터 말하자면면 쓰레드는 개발자가 작성한 코드라인 순서대로 따라서 실행되지 않는다.
다음 예시를 보자.
public class MainSample {
public static void main(String[] args) {
Thread[] threads = new Thread[10];
Thread[] threads2 = new Thread[10];
for(int i = 0; i < 10; i++) {
threads[i] = new Thread(new RunnableSample());
threads2[i] = new ThreadSample();
threads[i].start();
threads2[i].start();
}
System.out.println("Main Method : " + Thread.currentThread().getName());
}
}
console 출력:
RunnableSample : Thread-8
RunnableSample : Thread-16
RunnableSample : Thread-14
RunnableSample : Thread-0
Main Method : main
ThreadSample : Thread-3
ThreadSample : Thread-17
RunnableSample : Thread-12
ThreadSample : Thread-1
ThreadSample : Thread-19
ThreadSample : Thread-9
ThreadSample : Thread-13
RunnableSample : Thread-2
ThreadSample : Thread-5
ThreadSample : Thread-7
ThreadSample : Thread-15
ThreadSample : Thread-11
RunnableSample : Thread-4
RunnableSample : Thread-10
RunnableSample : Thread-18
RunnableSample : Thread-6나는 RunnableSample쓰레드를 첫번째로 실행하고 ThreadSample을 두번째로 실행하는 순으로 반복문 10번을 돌렸다. 코드 라인 순서대로라면 RunableSample 한번 ThreadSample 한번 순으로 출력이 되었어야 할 것이다. 그런데 출력문은 순서가 뒤죽박죽인것을 볼 수 있다.
이는 Thread는 실행할 때 먼저 대기 상태로 진입하고 컴퓨터 OS에서 스케줄링된 순서에 따라 실행되기 때문에 위와 같은 코딩 방식은 쓰레드의 실행 순서를 보장하지 못하고 컴퓨터의 성능에 따라 달라지게 되며 매번 실행 순서에 대한 결정이 다르게 나타난다.
Tread 클래스에서 쓰레드 스케줄링과 연관된 메소드들
| 메소드명 | 설명 |
|---|---|
| static void sleep(long millis) static void sleep(long millis, int nanos) | 지정된 시간(1/1000초 단위)동안 쓰레드를 일시정지 시킨다. 지정한 시간이 지나고 나면, 자동적으로 다시 실행 대기 상태로 전환된다. |
| void join() void join(long millis) void join(long millis, int nanos) | 지정된 시간동안 쓰레드가 실행되도록 한다. 지정된 시간이 지나거나 작업이 종료되면 join()을 호출한 쓰레드 다시 돌아와 실행을 계속한다. |
| void interrupt() | 쓰레드에게 작업을 멈추라고 요청한다. 쓰레드의 interrupted 상태를 false에서 true로 변경한다. |
| static boolean interrupted() | sleep()이나 join()에 의해 일시정지 상태인 쓰레드를 깨워서 실행 대기상태로 만든다. 해당 쓰레드에서는 interruptedException이 발생함으로 일시정지 상태를 벗어나게 된다. |
| @Deprecated void stop() | 쓰레드를 즉시 종료한다. |
| @Deprecated void suspend() | 쓰레드를 일시정지 시킨다. resume()을 호출하면 다시 실행대기 상태가 된다. |
| @Deprecated void resume() | suspend()에 의해 일시정지 상태에 있는 쓰레드를 실행대기 상태로 만든다. |
| static void yield() | 실행 중에 자신에게 주어진 실행시간을 다른 쓰레드에게 양보(yield)하고 자신은 실행 대기상태가 된다. |
위 Deprecated가 명시된 메소드들은 쓰레드를 교착 상태로 만들기 쉽기 때문에 Deprecated 된 것이며 사용해서는 안된다.
이외 메소드들
- currentThread() : 현재 실행중인 thread 객체의 참조를 반환합니다.
- destroy() : clean up 없이 쓰레드를 파괴합니다. @Deprecated 된 메소드로 suspend()와 같이 교착상태(deadlock)을 발생시키기 쉽습니다.
- isAlive() : 쓰레드가 살아있는지 확인하기 위한 메소드 입니다. 쓰레드가 시작되고 아직 종료되지 않았다면 살아있는 상태입니다.
- setPriority(int newPriority) : 쓰레드의 우선순위를 새로 설정할 수 있는 메소드입니다.
- getPriority() : 쓰레드의 우선순위를 반환합니다.
- setName(String name) : 쓰레드의 이름을 새로 설정합니다.
- getName(String name) : 쓰레드의 이름을 반환합니다.
- getThreadGroup() : 쓰레드가 속한 쓰레드 그룹을 반환합니다. 종료됐거나 정지된 쓰레드라면 null을 반환합니다.
- activeCount() : 현재 쓰레드의 쓰레드 그룹 내의 쓰레드 수를 반환합니다.
- enumerate(Thread[] tarray) : 현재 쓰레드의 쓰레드 그룹내에 있는 모든 활성화된 쓰레드들을 인자로 받은 배열에 넣습니다. 그리고 활성화된 쓰레드의 숫자를 int 타입의 정수로 반환합니다.
- dumpStack() : 현재 쓰레드의 stack trace를 반환합니다.
- setDaemon(boolean on) : 이 메소드를 호출한 쓰레드를 데몬 쓰레드 또는 사용자 쓰레드로 설정합니다.
JVM은 모든 쓰레드가 데몬 쓰레드만 있다면 종료됩니다. 이 메소드는 쓰레드가 시작되기 전에 호출되야합니다. - isDaemon() : 이 쓰레드가 데몬 쓰레드인지 아닌지 확인하는 메소드입니다. 데몬쓰레드면 true, 아니면 false 반환
- getStackTrace() : 호출하는 쓰레드의 스택 덤프를 나타내는 스택 트레이스 요소의 배열을 반환합니다.
- getAllStackTrace() : 활성화된 모든 쓰레드의 스택 트레이스 요소의 배열을 value로 가진 map을 반환합니다. key는 thread 입니다.
- getId() : 쓰레드의 고유값을 반환합니다. 고유값은 long 타입의 정수 입니다.
- getState() : 쓰레드의 상태를 반환합니다.
쓰레드의 상태
Thread.State Enum 클래스이며 현재 쓰레드의 상태를 표현하는 상수다. Thread.State 종류는 다음과 같다.
- NEW : 쓰레드 객체가 생성된 상태, 아직 시작되지 않은 상태다
- RUNNABLE : 쓰레드가 실행중인 상태
- BLOCKED : 쓰레드가 실행 중지 상태이며, 모니터 락(monitor lock)이 풀리기를 기다리는 상태
- WAITING : 쓰레드가 대기중인 상태
- TIMED_WAITING : 특정 시간만큼 쓰레드가 대기중인 상태
- TERMINATED : 쓰레드가 종료된 상태

- 이미지 참조 : https://t1.daumcdn.net/cfile/tistory/254E9F3A5496858C2B
위 쓰레드 상태 사이클에 대한 구조를 보며 정리를 하자면 다음과 같다
1) 쓰레드를 생성하고 start() 호출 시 실행 대기열(큐)에 저장되어 자신의 차례를 기다린다. 대기열은 큐의 구조이므로 FIFO 니까 들어온 순서대로 실행된다.
2) 실행대기 상태에 있다가 자신의 차례가 오면 실행 상태로 바뀐다.
3) 주어진 실행시간이 다 되거나 yield() 만나면 다시 실행대기 상태가 되며 다음 차례의 쓰레드가 실행된다.
4) 실행 중 suspend(), sleep(), wait(), join(), I/O Block에 의해 일시정지 상태가 될 수 있다. I/O Block은 입출력 작업에서 발생하는 지연상태를 말한다. 사용자 입력을 기다리는 경우를 예로 들 수 있는데, 이런 경우 일시정지 상태에 이싿가 사용자가 입력을 마치면 다시 실행 대기 상태가 된다.
5) 일시정지 시간이 다 되거나(time-out), notify(), resume(), interrupt()가 호출되면 일시정지 상태를 벗어나 다시 실행 대기열에 저장되어 자신의 차례를 기다린다.
6) 실행을 모두 마치거나 stop().이 호출되면 쓰레드는 소멸된다.
주의: 위 구조 처럼 매번 번호 순서대로 쓰레드가 실행되는 것은 아니다
sleep - 일정시간동안 쓰레드를 멈추게 한다
class ThreadEx {
public static void main(String[] args) {
A threadA = new A();
B threadB = new B();
threadA.start();
threadB.start();
try {
threadA.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class A extends Thread {
public void run() {
for (int i = 0; i < 300; i++) {
System.out.print("-");
}
System.out.print("<<A 종료>>");
}
}
class B extends Thread {
public void run() {
for (int i = 0; i < 300; i++) {
System.out.print("|");
}
System.out.print("<<B 종료>>");
}
}
console 출력 :
-------------------------------------------------||||---------------------------||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||---------------------------------------------
--------------------------------------------------------||||||||||||||||||||||||||||||||||||
|||||-------------------------------------------------------------------------------||||||||
|||||||--------------------------------------------<<A 종료>>||||||||||||||||||||||||||||||||
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||<<B 종료>><<Main 종료>>위 결과를 보면 A 쓰레드가 먼저 종료되고 그 다음순으로 B, main 쓰레드가 종료되었다. A쓰레드의 sleep(2000)을 걸었으니 2초간 작업을 멈추고 일시정지 상태로 있도록 했으니 A가 늦게 종료되는 결과를 기대했을 것이다. 원인은 sleep()은 항상 현재 실행 중인 쓰레드에 대해서 작동하기 때문이다 여기서는 threadA.sleep(2000)을 호출하였어도 A 쓰레드가 아닌 다음 메소드를 호출한 main쓰레드가 영향을 받게 된다. sleep은 static으로 선언되어 있어 참조변수를 통해 호출하는 방식이 아닌 Thread.sleep(2000);와 같은 방법으로 코딩을 해야한다.
interrupt(), interrupted() - 쓰레드의 작업을 취소한다
두 메소드는 비슷해 보이지만 역할들은 서로 다르다. interrupt()는 쓰레드에게 작업을 멈추라고 요청을 보내는 것이다. 실제로 쓰레드를 종료시키는게 아니라 단지 요청을 하여 그저 Thread의 interrupted 상태를 바꾸는 것이다. interrupted()는 쓰레드에 대해 interruptr()가 호출되었ㄲ는지를 알려준다. 호출됐으면 true를 호출되지 않았으면 false를 리턴한다.
void interrupt() 쓰레드의 interrupted 상태를 false에서 true로 변경
boolean isInterrupted() 쓰레드의 interrupted 상태를 반환
static boolean interrupted() 현재 쓰레드의 interrupted상태를 반환 후, false로 변경예로, sleep(), wait(), join()에 의해 WAITING(일시정지) 상태에 있을 때 해당 쓰레드에 대해 interrupt()를 호출하게 되면 WAITING에서 깨어나 RUNNABLE(실행대기) 상태로 바꾸는 것이다. 아례 예시를 보자
public class MainSample {
public static void main(String[] args) {
A threadA = new A();
threadA.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadA.getState());
threadA.interrupt();
System.out.println(threadA.isInterrupted());
}
}
class A extends Thread {
public void run() {
int i = 10;
while (i != 0 && !isInterrupted()) {
System.out.println(i--);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
System.out.println(getState());
}
for (long x = 0; x < 2500000000L; x++);
}
System.out.println("카운트 종료");
}
}
console 출력 :
10
TIMED_WAITING
true
RUNNABLE
java.lang.InterruptedException: sleep interrupted
at java.base/java.lang.Thread.sleep(Native Method)
at study.algorithm.studysample.A.run(MainSample.java:32)
9
8
7
6
5
4
3
2
1
카운트 종료위 코드는 main쓰레드가 주기적으로 3초동안 TIMED_WAITING 상태인 A쓰레드를 interrupt() 하는 계획이다. A쓰레드가 TIMED_WAITING 상태일 때 interrupt()를 호출하게 되면 InterruptedException이 발생하게 되고 A 쓰레드의 interrupted 상태는 false로 자동 초기화가 되고 다시 RUNNABLE의 상태가 된다.
yield() - 다른 쓰레드에게 양보하다
yield()는 쓰레드 자신에게 주어진(스케줄링된 실행시간) 실행 시간을 다음 차례의 쓰레드에게 양보(yield)한다. 예로 자신이 약 1초의 실행시간을 부여 받은 쓰레드가 0.5초만 작업을 수행한 뒤 yield()가 호출되었을 때 나머지 0.5초는 포기하고 다시 실행대기 상태로 간다.
yield()와 interrupt()를 적절히 사용하면 프로그램의 응답성을 높이고 보다 효율적인 실행이 가능하게 한다. 다음 예시를 보자.
public class MainSample {
public static void main(String[] args) {
ThreadExample a = new ThreadExample("A");
ThreadExample b = new ThreadExample("B");
ThreadExample c = new ThreadExample("C");
a.start();
b.start();
c.start();
try {
Thread.sleep(2000);
a.suspend();
Thread.sleep(2000);
b.suspend();
Thread.sleep(3000);
a.resume();
Thread.sleep(3000);
a.stop();
b.stop();
Thread.sleep(2000);
c.stop();
} catch (InterruptedException e) {
}
}
}
class ThreadExample implements Runnable {
boolean suspended = false;
boolean stopped = false;
Thread th;
ThreadExample(String name) {
th = new Thread(this, name);
}
public void run() {
String name = th.getName();
while (!stopped) {
if(!suspended) {
System.out.println(name);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println(name + " - interrupted");
}
} else {
Thread.yield();
}
}
System.out.println(name + " - stopped");
}
// 일시 정지 상태로 만든다.
public void suspend() {
suspended = true;
// Thread.sleep으로 인한 쓸모없이 대기상태에 빠져있는 쓰레드를 즉시 interrupt시킨다.
th.interrupt();
System.out.println(th.getName() + " - interrupt() by suspend()");
}
// 정지 상태로 만든다
public void stop() {
stopped = true;
// Thread.sleep으로 인한 쓸모없이 대기상태에 빠져있는 쓰레드를 즉시 interrupt시킨다.
th.interrupt();
System.out.println(th.getName() + " - interrupt() by stop()");
}
// 작업을 다시 재개한다.
public void resume() {
suspended = false;
}
// 작업을 처음 시작한다.
public void start() {
th.start();
}
}
console 출력 :
A
B
C
B
A
C
B
C
A - interrupt() by suspend()
B
C
B
B - interrupt() by suspend()
C
B - interrupted
C
C
A
A - interrupted
A
C
A
C
A
C
A - interrupted
A - interrupt() by stop()
A - stopped
B - stopped
B - interrupt() by stop()
C
C
C - interrupt() by stop()
C - interrupted
C - stopped위 예시를 보면 그냥 suspend() 를 호출했을 때 else 블럭에 있는 yield() 가 없었을 경우라면 그저 while문을 의미없이 계속 loop를 돌면서 낭비를 하게되고 프로그램상 비효율적인 상태인 것이다. 이 상태를 '바쁜 대기상태(busy-waiting)'이라고 한다.
yield()를 추가함으로써 supendded 값이 true일 경우 else 블럭에 있는 yield()를 만나 이 작업은 다른 쓰레드에게 남은 작업시간을 양보하는 것으로 더 효율적으로 돌아가게 된다. 또한 suspend()와 stop()에서 interrupt()를 호출하는 것을 볼 수 있다. 이유는 이 쓰레드에 while문 안에서는 Thread.sleep(1000) 으로 인해 1초씩 계속 대기 상태에 빠지게된다. 만약 stop() suspend()를 호출하는 순간에도 1초가 지날 때까지 계속 대기 상태를 유지하게 된다면 프로그램적으로 시간지연이 발생하게 되는 것이다. 따라서 suspend(), stop() 호출 시 interrupt()를 호출함으로써 바로 InterruptedException으로 빠지게 만들어 즉시 실행대기 상태로 만들어 응답성을 높이는 것이다. 사용자 입장에서 좀 더 좋은 반응성을 제공하는 것이다.
join() - 다른 쓰레드의 작업을 기다린다
쓰레드 자신이 하던 작업을 잠시 멈추고 다른 쓰레드가 지정된 시간동안 작업을 수행하도록 할 때 join()을 사용하게 된다.
void join()
void join(long millis)
void join(long millis, int nanos) join이 언제 사용할지에 대한 다음과 같은 예시를 보자, 이 코드는 Memory를 랜덤 값으로 지속적으로 누적하는 main쓰레드와 MAX_MEMORY가 1000인 현재 MEMORY 값이 MAX값을 넘기면 지속적으로 청소하는 GarbageCollector를 간단하게 구현한 것이다.
public class JoinPractice {
public static void main(String[] args) {
ThreadJoinSample gc = new ThreadJoinSample();
gc.setDaemon(true);
gc.start();
int requiredMemory = 0;
for (int i = 0; i < 20; i++) {
requiredMemory = (int) (Math.random() * 10) * 20;
if(gc.freeMemory() < requiredMemory
|| gc.freeMemory() < gc.totalMemory() * 0.4) {
gc.interrupt();
}
gc.usedMemory += requiredMemory;
System.out.println("usedMemory : " + gc.usedMemory);
}
}
}
class ThreadJoinSample extends Thread {
final static int MAX_MEMORY = 1000;
int usedMemory = 0;
@Override
public void run() {
while (true) {
try {
Thread.sleep(10 * 1000);
} catch (InterruptedException e) {
System.out.println("Thread Awaken by interrupt()");
}
gc();
System.out.println("Garbage Collected. Free Memory : " + freeMemory());
}
}
public void gc() {
usedMemory -= 300;
if (usedMemory < 0) usedMemory = 0;
}
public int totalMemory() {
return MAX_MEMORY;
}
public int freeMemory() {
return MAX_MEMORY - usedMemory;
}
}
console 출력 :
usedMemory : 160
usedMemory : 300
usedMemory : 340
usedMemory : 380
usedMemory : 420
usedMemory : 560
usedMemory : 620
usedMemory : 760
usedMemory : 860
Thread Awaken by interrupt()
usedMemory : 960
usedMemory : 820
usedMemory : 920
usedMemory : 1080
usedMemory : 1240
usedMemory : 1420
usedMemory : 1460
usedMemory : 1480
usedMemory : 1540
usedMemory : 1620
usedMemory : 1700
Garbage Collected. Free Memory : 340
Thread Awaken by interrupt()
Garbage Collected. Free Memory : -400위 출력 결과를 보면 이상한 점이 있다. MAX_MEMORY 한계 값은 1000인데도 불구하고 1000이상의 숫자가 계속 찍히고 있고, MEMORY가 0 아래로 떨어질 경우 0으로 다시 setting하는 코드가 있는데도 불구하고 이상한 값들이 찍히고 있다. 왜 그럴까?
바로, 메모리가 60퍼센트를 초과하거나 필요한 메모리가 현재 GC의 여유 MEMORY 값보다 작을 경우에 대한 조건을 걸은 if문 블럭에서 sleep에 들어간 GC쓰레드를 interrupt()를 하여 깨우고 main쓰레드는 지속적으로 돌고 있다. main쓰레드가 GC쓰레드의 작업 상태와 상관없이 지속적으로 메모리를 사용하기 때문에 이러한 결과가 출력되는 것이다. 내가 원하는 결과를 도출하기 위해서는 main쓰레드가 GC쓰레드를 깨운 뒤 GC쓰레드가 작업할 시간을 어느정도 주고 main쓰레드는 그 시간동안 대기하도록 해야한다. 이때, join()을 사용하여 대기할 시간값을 인자로 넣어서 해당 시간만큼 main쓰레드가 대기상태에 있도록 처리해야한다.
if문 블럭에서 interrupt() 수행한 뒤 다음과 같이 처리해보자.
- before
if(gc.freeMemory() < requiredMemory
|| gc.freeMemory() < gc.totalMemory() * 0.4) {
gc.interrupt();
}- after
if(gc.freeMemory() < requiredMemory
|| gc.freeMemory() < gc.totalMemory() * 0.4) {
gc.interrupt();
try {
gc.join(100); // 0.1초 만큼 GC의 작업을 기다린다.
} catch (InterruptedException e) { }
}
변경후 console 출력 :
usedMemory : 40
usedMemory : 120
usedMemory : 180
usedMemory : 200
usedMemory : 280
usedMemory : 280
usedMemory : 400
usedMemory : 540
usedMemory : 700
Thread Awaken by interrupt()
Garbage Collected. Free Memory : 600
usedMemory : 500
usedMemory : 620
Thread Awaken by interrupt()
Garbage Collected. Free Memory : 680
usedMemory : 320
usedMemory : 340
usedMemory : 500
usedMemory : 640
Thread Awaken by interrupt()
Garbage Collected. Free Memory : 660
usedMemory : 480
usedMemory : 560
usedMemory : 740
Thread Awaken by interrupt()
Garbage Collected. Free Memory : 560
usedMemory : 460
usedMemory : 640join()을 사용함으로써 내가 원하던 결과값을 확인할 수 있었다. 필요에 의해서 join()을 적절히 이용하는 것도 괜찮을 것 같다.
쓰레드 우선순위
쓰레드는 우선순위라는 변수(속성)을 가지고 있다. 이 우선순위 값에 따라서 쓰레드가 얻는 실행 시간이 달라지게 된다. 쓰레드가 수행하는 작업의 중요도에 따라서 쓰레드들의 우선순위를 서로 다르게 지정하고 특정 쓰레드가 더 많은 작업시간을 갖도록 할 수 있다.
우선순위 상수 값
- public static final int MAX_PRIORITY = 10 // 최고 우선순위
- public static final int MIN_PRIORITY = 1 // 최소 우선순위
- public static final int NORM_PRIORITY = 5 // 보통 우선순위
우선순위 지정방법
void setPriority(int newPriority) // 쓰레드의 우선순위를 지정한 값으로 변경
int getPriority() // 쓰레드의 우선순위를 반환쓰레드의 우선순위 지정시 알아야 할 사항이 한 가지 있다. 새로 생성된 쓰레드의 우선순위는 쓰레드를 생성시킨 주체의 우선순위를 상속받는다. main 메소드를 실행시킨 쓰레드는 기본적으로 우선순위가 5이고 main 메소드 내에서 생성한 새로운 쓰레드는 main 쓰레드의 우선순위를 상속받는 것이다. 만일 쓰레드의 우선순위를 변경하고 싶으면 해당 쓰레드의 setPriority 메소드를 호출하여 우선순위 값을 변경해야한다.
예제
public class ThreadPractice {
public static void main(String[] args) {
ThreadPrioritySample thread = new ThreadPrioritySample();
// main 쓰레드의 우선순위
System.out.println(Thread.currentThread().getPriority());
// sample 쓰레드의 우선순위
System.out.println(thread.getPriority());
// sample 쓰레드 우선순위 변경
thread.setPriority(Thread.MAX_PRIORITY);
System.out.println(thread.getPriority());
thread.start();
}
}
class ThreadPrioritySample extends Thread {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {}
}
}
}
console 출력 :
5 // main 쓰레드 우선순위
5 // sample 쓰레드 우선순위
10 // 변경된 sample 쓰레드의 우선순위
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
Main 쓰레드
사실 우리가 Java를 실행하기 위해 사용하던 main() 를 수행하는 일꾼도 쓰레드이며 이를 main쓰레드라고 부른다. 우리는 자바를 처음 배울 때 부터 이 쓰레드를 사용해오고 있었던 것이다. 프로그램이 실행되기 위해서는 최소한 하나의 쓰레드가 필요하고 JVM 실행시 이것은 하나의 프로세스이며 이 JVM이 하나의 쓰레드를 생성하고, 이 쓰레드가 main()를 호출하면서 작업이 수행되는 것이다.
위 예제들에서 따로 구현체로 만든 쓰레드들은 각각 main 쓰레드 위에서 실행이 되면서 각각의 쓰레드 생성하고 별도의 스택을 형성되어 각각의 작업을 진행한다. 다음 그림을 보자
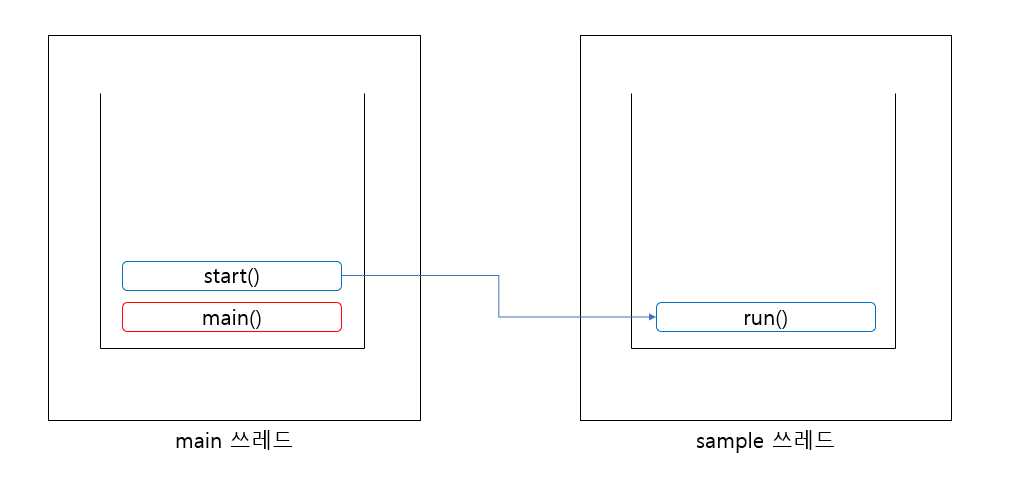
이와 같은 구조를 멀티 쓰레드라고 하며 각각의 쓰레드는 서로 문맥교환(Context Switching)을 하며 일종의 작업 전환을 하는 것이다.
데몬 쓰레드
데몬 쓰레드(Daemon Thread)는 다른 일반 쓰레드(데몬 쓰레드가 아닌 쓰레드)의 작업을 보조하는 역할을 가진 쓰레드이다. 일반 쓰레드가 모두 종료된다면 데몬 쓰레드는 강제적으로 자동으로 작업을 종료한다. 앞서 설명한대로 데몬 쓰레드는 일반 쓰레드의 보조자이고 일반 쓰레드가 종료되는 순간 데몬 쓰레드의 역할도 끝나 더 이상 존재의 의미가 없기 때문에 종료시키는 것이다.
데몬 쓰레드를 만드는 방법은 먼저 쓰레드를 생성한 뒤 해당 쓰레드를 실행하기 전에 미리 setDaemon(true) 를 호출하여 데몬 쓰레드로 셋팅하면 된다.
boolean is Daemon() // 쓰레드가 데몬 쓰레드인지 확인(true: 데몬/false: 일반)
void setDaemon(boolean on) // 쓰레드를 데몬 쓰레드 또는 일반 쓰레드로 변경
// 매개변수에 true 면 데몬 쓰레드로 지정된다.예제
public class ThreadPractice {
public static void main(String[] args) {
DaemonSample thread = new DaemonSample();
thread.setDaemon(true);
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main 메소드 종료!");
}
}
class DaemonSample extends Thread {
@Override
public void run() {
while (true) {
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(100);
} catch (InterruptedException e) {}
}
}
}
console 출력 :
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
main 메소드 종료!위 예제는 Daemon 쓰레드로 활성화한 쓰레드의 작업은 while 반복을 지속적으로 돌리고있다. main 메소드에서 약 1초간의 sleep() 후 바로 프린트문을 실행시키고 끝나게되면서 main 메소드의 종료와 함께 Daemon 쓰레드도 함께 종료되는 것을 확인할 수 있다.
데몬쓰레드가 활용되는 예시
자바 실행 시 JVM은 가비지컬레션(GC), 이벤트 처리, 그래픽 처리와 같은 프로그램이 실행되는 데 필요한 보조 작업을 수행하는 쓰데드들은 데몬 쓰레드이며, 자동적으로 생성되어서 실행되는 구조다.
동기화(synchronization)
멀티 쓰레드 프로세스일 경우 여러 쓰레드가 같은 프로세스 내의 자원을 공유해서 작업하기 때문에 서로의 작업에 영향을 줄 수 있다. 공유된 자원을 각 쓰레드들이 서로 변경하는 작업이 있다면 아마 의도한대로 결과를 얻지 못할 것이다. 이를 방지하기 위해서 한 쓰레드가 작업을 모두 마칠때까지 다른 쓰레드의 간섭을 받지 않도록 하는 장치가 필요하다. 그래서 생겨낸 개념이 임계 영역(critical section)과 잠금(Lock)이다.
공유 데이터를 사용하는 코드 영역을 임계 영역으로 지정해놓고, 공유 데이터가 가지고 있는 Lock을 획득한 단 하나의 쓰레드만이 이 영역 내 코드를 수행할 수 있게 하는 것이다. 수행을 마친 쓰레드는 Lock을 반납하고 다른 쓰레드가 반납된 Lock을 다시 가져가 임계 영역의 코드를 수행하는 구조이다.
이렇게 한 쓰레드가 진행 중인 작업에 대해서 다른 쓰레드가 간섭하지 못하도록 막는 것을 동기화라고 한다.
자바에서 동기화 방식
- Synchronized 키워드
- Atomic 클래스
- Lock과 Condition
- Volatile 키워드
현재는 내가 이해한 synchronized 키워드부터 설명하고 나머지 방식들은 추가적으로 공부해서 내용을 추가해야겠다.
synchronized
- 사용법
// 1. 메소드 전체를 임계 영역으로 지정한다.
public synchronized void run() {
// 코드
}
// 2. synchronized 블럭으로 감싸진 특정 영역의 코드만 임계 영역으로 지정
synchronized(객체의 참조변수) {
// 코드
}첫번째 방식은 쓰레드가 메서드가 호출된 시점부터 해당 메서드가 포함된 객체의 Lock을 얻고 작업을 수행하다가 메서드가 끝나면 Lock을 반납한다.
두번째 방식은 참조 변수를 Lock을 걸고자하는 객체를 참조해야하는 것이며 이 블럭 영역 안으로 코드 흐름이 들어가면서부터 쓰레드는 지정된 객체의 Lock을 얻게되고 이 블럭이 끝나는 순간 Lock을 반납한다.
두 사용 방식 모두 Lock의 획득과 반납은 모두 자동으로 이루어지며 개발자는 임계 영역만 지정해주면 되는 것이다. 임계 영역은 멀티 쓰레드 프로그래밍에서 성능을 좌우하는 요소이기 때문에 가능하면 메소드 전체를 임계영역으로 지정하는 것 보단 synchronized 블럭으로 임계 영역을 적절히 필요한 곳에 최소화되도록 지정해주어 효율적으로 프로그래밍을 해주어야한다.
- 예제
synchronized 적용 전
public class ThreadPractice {
public static void main(String[] args) {
Runnable r = new Sample();
new Thread(r).start();
new Thread(r).start();
}
}
class Account {
private int balance = 1000;
public int getBalance() {
return balance;
}
public void withDraw(int money) {
if (balance >= money) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) { }
balance -= money;
}
}
}
class Sample implements Runnable {
Account acc = new Account();
@Override
public void run() {
while (acc.getBalance() > 0) {
int money = (int) (Math.random() * 3 + 1) * 100;
acc.withDraw(money);
System.out.println(Thread.currentThread().getName() + " balance : " + acc.getBalance());
}
}
}console 출력 :
Thread-1 balance : 400
Thread-0 balance : 400
Thread-0 balance : 300
Thread-1 balance : 200
Thread-1 balance : -100
Thread-0 balance : -100
결과를 보면 withDraw메소드 if문에 조건이 있는데도 불구하고 마이너스 금액이 찍히는 것을 볼 수 있다. 이것은 동기화 처리가 안되어 있어 공동의 공유 자원을 여러 쓰레드가 작업을 하면서 1번 쓰레드는 200원이 남았을 때 if문을 통과가 되는 순간에 제어권이 0번 쓰레드에게 넘어가 0번 쓰레드에서 200원을 출금해 0원이 되고 다시 1번 쓰레드에서 조건문 통과 직후 멈췄던 작업을 다시 이어나가서 -100 원이 찍히게 되고 정확한 시나리오는 아니지만 아마 이와 비슷한 맥락으로 쓰레드들이 스케줄링된 작업들을 이어갔을 것이다. 이렇게 공유 자원을 여러 쓰레드에서 조작하는 것은 위험하며 동기화 작업은 반드시 필요하다.
위 작업에서는 Account 객체에서 withDraw 메소드가 balance 값과 money의 값을 비교하는 부분이 있고 balance 값에 money 값을 빼는 연산 과정이 있다. 이 과정 모두 임계 영역으로 들어가야 한다. 이 예제에서는 메소드에 synchronized 키워드를 붙이는 것이 좋을 것 같다
synchronized 적용 후
// withDrwa 메소드에 synchronized 키워드를 붙여 임계 영역으로 지정했다.
public synchronized void withDraw(int money) {
if (balance >= money) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) { }
balance -= money;
}
}console 출력
Thread-0 balance : 900
Thread-1 balance : 700
Thread-0 balance : 400
Thread-1 balance : 200
Thread-1 balance : 0
Thread-0 balance : 0
withDraw 메소드에 동기화 처리를 해주니 전과 같은 오류는 일어나지 않았다. 추가적으로 주의할 점이 있는데 동기화를 했다고 해서 모든 경우에 대해서 방어가 되는 것은 아니다. 만일 balance 변수의 접근 지시자가 private이 아닌 이외의 접근지시자였다면 외부에서 직접 접근하여 수정이 가능해져 문제가 생길수도 있다.
데드락
데드락(DeadLock, 교착상태)이란 둘 이상의 쓰레드가 Lock을 획득하기 위해 대기하는데, 이 Lock을 잡고 있는 자원에 서로 다른 쓰레드들이 Lock을 동시에 획득하려고 할 때 발생할 수 있다. 예를 들자면 A와B 두개의 쓰레드가 있고 A쓰레드는 r1이라는 자원의 Lock을 가지고 있는 상태며 B쓰레드는 r2라는 자원의 Lock을 가지고 있다고 가정하자 이 때, A쓰레드는 r2자원의 Lock을 획득하길 원하고 B쓰레드는 r1자원의 Lock을 획득하려고 동시에 서로 접근하고 이 두 쓰레드는 서로 이러한 사실에 대한 유무를 모르는 상태이다. 이 두 쓰레드는 r1,r2자원에 대한 Lock을 계속 무한히 대기하는 현상에 빠지게 된다 이 현상을 데드락(교착상태)라고 한다.
- 예제
public class ThreadPractice {
public static String r1 = "자원1";
public static String r2 = "자원2";
public static void main(String[] args) {
Runnable r1 = new Sample();
Runnable r2 = new Sample2();
new Thread(r1).start();
new Thread(r2).start();
}
}
class Sample implements Runnable {
@Override
public void run() {
synchronized (ThreadPractice.r1) {
System.out.println(Thread.currentThread().getName() + " r1 자원 점유중..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
System.out.println(Thread.currentThread().getName() + " r2 자원 대기중..");
synchronized (ThreadPractice.r2) {
System.out.println(Thread.currentThread().getName() + " r2 자원 점유중..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
}
}
}
}
class Sample2 implements Runnable {
@Override
public void run() {
synchronized (ThreadPractice.r2) {
System.out.println(Thread.currentThread().getName() + " r2 자원 점유중..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
System.out.println(Thread.currentThread().getName() + " r1 자원 대기중..");
synchronized (ThreadPractice.r1) {
System.out.println(Thread.currentThread().getName() + " r1 자원 점유중..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
}
}
}
}console 출력 :
Thread-0 r1 점유중..
Thread-1 r2 점유중..
Thread-1 r1 대기중..
Thread-0 r2 대기중..
위 예제를 설명하자면 0번 쓰레드는 r1의 Lock을 가지고 있고 1번 쓰레드는 r2의 Lock을 가지고 있는 상태다. 이제 0, 1번 쓰레드가 서로의 자원의 Lock을 가져가길 원하며 대기를 하게되는 상황을 연출한거다. 서로의 작업은 자신이 점유중인 자원에 대한 synchronized 블럭을 벗어나지 않은 상태에서 각자가 점유하고 있는 자원에 Lock을 가져오려고 하기 때문에 데드락에 빠지게 된 것이다.
참조
