
검색 알고리즘
배열은 한 자료형의 여러 값들이 메모리상에 모여 있는 구조입니다. 컴퓨터는 이 값들에 접근할 때 배열의 인덱스 하나하나를 접근합니다. 만약 어떤 값이 배열 안에 속해 있는지를 찾아 보기 위해서는 배열이 정렬되어 있는지 여부에 따라 아래와 같은 방법을 사용할 수 있습니다.
선형 검색
배열의 인덱스를 처음부터 끝까지 하나씩 증가시키면서 방문하여 그 값이 속하는지를 검사합니다.
의사코드는 아래와 같습니다:
For i from 0 to n–1
If i'th element is 50
Return true
Return false이진 검색
만약 배열이 정렬되어 있다면, 배열 중간 인덱스부터 시작하여 찾고자 하는 값과 비교하며 검색합니다. 만약 찾고자 하는 값이 해당 인덱스 값 보다 작다면 그보다 작은(작은 값이 저장되어 있는) 인덱스, 아니라면 더 큰 (큰 값이 저장되어 있는) 인덱스로 이동을 반복하면 됩니다.
아래 의사코드와 같이 나타낼 수 있습니다.
If no items
Return false
If middle item is 50
Return true
Else if 50 < middle item
Search left half
Else if 50 > middle item
Search right half알고리즘 표기법
알고리즘을 실행하는데 걸리는 시간을 표현하자면 아래와 같습니다.
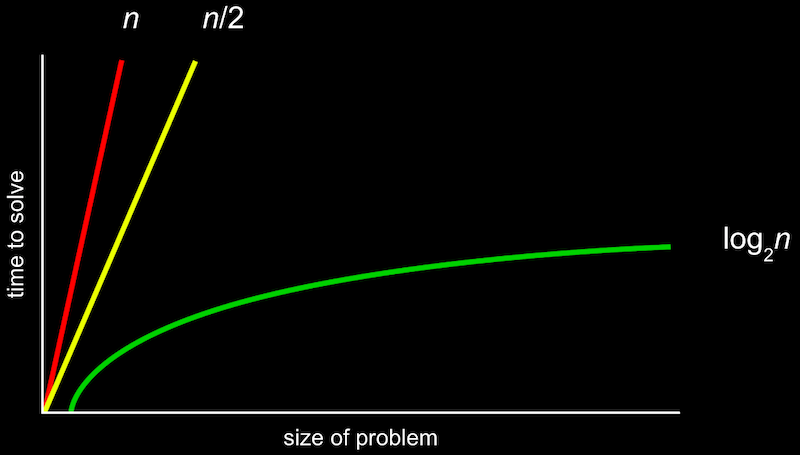
Big O (빅 오) 표기법
위와 같은 그림을 공식으로 표기한 것이 Big O 표기법입니다.
Big O (빅 오) 표기법: 알고리즘 실행 시간의 상한(시간 복잡도)을 나타내는 표기법이며, O(f(n))으로 나타냅니다. 알고리즘 시간이 최악인 경우를 나타냅니다.
여기서 O는 “on the order of”의 약자로, 쉽게 생각하면 “~만큼의 정도로 커지는” 것이라고 볼 수 있습니다.
O(n) 은 n만큼 커지는 것이므로 n이 늘어날수록 선형적으로 증가하게 됩니다. O(n/2)도 결국 n이 매우 커지면 1/2은 큰 의미가 없어지므로 O(n)이라고 볼 수 있습니다.
주로 아래 목록과 같은 Big O 표기가 실행 시간을 나타내기 위해 많이 사용됩니다.
- O(n^2)
- O(n log n)
- O(n) - 선형 검색
- O(log n) - 이진 검색
- O(1)
Big Ω (빅 오메가) 표기법
Big O가 알고리즘 실행 시간의 상한을 나타낸 것이라면, 반대로 Big Ω는 알고리즘 실행 시간의 하한을 나타내는 것입니다.
Big Ω (빅 오메가) 표기법: 알고리즘 실행 시간의 하한(시간 복잡도)을 나타내는 표기법이며, O(f(n))으로 나타냅니다. 알고리즘 시간이 최선인 경우를 나타냅니다.
예를 들어 선형 검색에서는 n개의 항목이 있을때 최대 n번의 검색을 해야 하므로 상한이 O(n)이 되지만 운이 좋다면 한 번만에 검색을 끝낼수도 있으므로 하한은 Ω(1)이 됩니다.
아래 목록과 같은 Big Ω 표기가 많이 사용됩니다.
- Ω(n^2)
- Ω(n log n)
- Ω(n) - 배열 안에 존재하는 값의 개수 세기
- Ω(log n)
- Ω(1) - 선형 검색, 이진 검색
선형 검색
선형검색은 원하는 원소가 발견될 때까지 처음부터 마지막 자료까지 차례대로 검색합니다. 즉, 선형 검색은 찾고자 하는 자료를 찾을 때까지 모든 자료를 확인해야 합니다.

예를 들어, 정렬되지 않은 전화번호부에서 '김코딩' 이라는 이름을 찾아야 한다고 할 때 선형 검색을 사용할 수 있습니다. 전화번호부 첫장 부터 하나씩 확인해나가며 원하는 이름이 나올 때 까지 훑어 보는게 선형 검색입니다.
만약 전화번호부가 이미 가나다 순으로 정렬이 되어있다면 더 효율적인 알고리즘을 사용할 수 있지만, 정렬이 되지 않다면 하나씩 찾아보는 선형 검색을 사용할 수 있습니다.
효율성 그리고 비효율성
선형 검색 알고리즘은 정확하지만 아주 효율적이지 못한 방법입니다.
리스트의 길이가 n이라고 했을 때, 최악의 경우 리스트의 모든 원소를 확인해야 하므로 n번만큼 실행됩니다. (여기서 최악의 상황은 찾고자 하는 자료가 맨 마지막에 있거나 리스트 안에 없는 경우를 말합니다.) 예를 들어, 만약 100만 개의 원소가 있는 리스트라고 가정해본다면 효율성이 매우 떨어집니다. 반대로 최선의 상황은 처음 시도했을 때 찾고자 하는 값이 있는 경우입니다.
정렬의 중요성
선형 검색은 자료가 정렬되어 있지 않거나 그 어떤 정보도 없어 하나씩 찾아야 하는 경우에 유용합니다. 이러한 경우 무작위로 탐색하는 것보다 순서대로 탐색하는 것이 더 효율적입니다. 따라서 검색 이전에 정렬을 하는 것은 매우 중요합니다.
정렬은 시간이 오래 걸리고 공간을 더 차지합니다. 하지만 이 추가적인 과정을 진행하면 여러 번 리스트를 검색해야 하거나 매우 큰 리스트를 검색해야 할 경우 시간을 단축할 수 있을 것입니다.
선형 검색 예시
주어진 배열에서 특정 값을 찾기 위해서 선형 검색을 사용한다면, 아래와 같은 코드를 작성할 수 있습니다.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
// numbers 배열 정의 및 값 입력
int numbers[] = {4, 8, 15, 16, 23, 42};
// 값 50 검색
for (int i = 0; i < 6; i++)
{
if (numbers[i] == 50)
{
printf("Found\n");
return 0;
}
}
printf("Not found\n");
return 1;
}배열의 크기만큼 for 루프를 돌면서 배열의 인덱스를 차례대로 방문하며 찾는 값이 있는지를 검사하면 됩니다.
버블 검색
정렬되지 않은 리스트를 탐색하는 것 보다 정렬한 뒤 탐색하는 것이 더 효율적입니다. 정렬 알고리즘 중 하나는 버블 정렬입니다. 버블 정렬은 두 개의 인접한 자료 값을 비교하면서 위치를 교환하는 방식으로 정렬하는 방법을 말합니다.
버블 정렬은 단 두 개의 요소만 정렬해주는 좁은 범위의 정렬에 집중합니다.
이 접근법은 간단하지만 단 하나의 요소를 정렬하기 위해 너무 많이 교환하는 낭비가 발생할 수도 있습니다.

한번의 버블 정렬을 실행한 예시 사진입니다. 한번 정렬을 하면 1, 5, 2, 4, 6의 순서로 정렬이 되었는데, 6이 제 자리에 와있는것을 볼 수 있습니다. 다음 정렬에서는 같은 방식으로 나머지 1~5 원소를 정렬해주면 됩니다.
버블 검색 실행

아래와 같은 6개의 숫자가 임의의 순서로 나열되어 있습니다. 이 순자들을 오름차순으로 정렬하기 위해 바로 옆의 있는 숫자들과 비교하는 방법을 사용해 보겠습니다.
5, 1, 6, 2, 4, 3비교하는 숫자는 [괄호]로 표현해보겠습니다.
[5, 1], 6, 2, 4, 31) 먼저, 가장 앞의 5와 1을 비교해서 순서를 바꿉니다.
[5, 1], 6, 2, 4, 3교환 전: 5, 1, 6, 2, 4, 3
교환 후: 1, 5, 6, 2, 4, 3
2) 다음 쌍인 5, 6을 비교하면 이미 정렬이 되어있기 때문에 그대로 둡니다.
1, [5, 6], 2, 4, 3교환 전: 1, 5, 6, 2, 4, 3
교환 후: 1, 5, 6, 2, 4, 3
3) 다음 쌍인 6, 2는 정렬을 해주어야 하기 때문에 위치를 바꿉니다.
1, 5, [6, 2], 4, 3교환 전: 1, 5, 6, 2, 4, 3
교환 후: 1, 5, 2, 6, 4, 3
이런 식으로 숫자 끝까지 진행하면 아래와 같이 정렬이 됩니다.
1, 5, 2, 4, 3, 6하지만 아직 오름차순으로 정렬이 되지 않았기 때문에, 다시 처음부터 동일한 작업을 반복합니다.
[1, 5], 2, 4, 3, 6
1, [2, 5], 4, 3, 6 (교환)
1, 2, [4, 5], 3, 6 (교환)
1, 2, 4, [3, 5], 6 (교환)
1, 2, 4, 3, [5, 6]. (교환)
조금 더 잘 정렬이 되었습니다. 이 과정을 끝까지 반복하면 최종적으로 아래와 같이 오름차순 정렬이 될 것입니다.
1 2 4 3 5 6
이러한 정렬 방식을 ‘버블 정렬’이라고 합니다. 마치 거품이(비교 및 교환이) 터지면서 위로 올라오는 (배열의 옆으로 이동하는) 방식이기 때문입니다.
버블 검색 big-o
버블 정렬은 아래와 같이 의사 코드로 나타낼 수 있습니다.
Repeat n–1 times
For i from 0 to n–2
If i'th and i+1'th elements out of order
Swap them중첩 루프를 돌아야 하고, n개의 값이 주어졌을 때 각 루프는 각각 n-1번, n-2번 반복되므로 (n-1)*(n-2) = n^2-3n+2 번의 비교 및 교환이 필요합니다.
- 가장 크기가 큰 요소는 n^2 이므로 위와 같은 코드로 작성한 버블 정렬 실행 시간의 상한은 O(n^2)이라고 말할 수 있습니다.
- 정렬이 되어 있는지 여부에 관계 없이 루프를 돌며 비교를 해야 하므로 위와 같은 코드로 작성한 버블 정렬의 실행 시간의 하한도 여전히 Ω(n^2)이 됩니다.
버블 정렬은 수행 한 번 만에 모든 원소가 정렬되는 것을 보장하지 않습니다. 최악의 경우 n개의 요소를 정렬해주기 위해서는 n-1번 실행해주어야 하기 때문에 경제적이지 못한 알고리즘입니다.
선택 정렬
선택 정렬도 정렬을 위한 알고리즘입니다.
- 선택정렬은 배열 안의 자료 중 가장 작은 수(혹은 가장 큰 수)를 찾아 첫 번째 위치(혹은 가장 마지막 위치)의 수와 교환해주는 방식의 정렬입니다.
- 선택 정렬은 교환 횟수를 최소화하는 반면 각 자료를 비교하는 횟수는 증가합니다.
선택 정렬 실행

다음과 같은 정렬되지 않은 숫자들을 오름차순 정렬해보도록 하겠습니다.
5, 1, 6, 2, 4, 3비교하는 숫자는 [괄호]로 표현해보겠습니다.
[5], [1], 6, 2, 4, 3먼저 아래 숫자들 중에서 가장 작은 값을 찾습니다.
[5], [1], 6, 2, 4, 3가장 작은 값인 1은 가장 앞에 있어야 하므로 현재 리스트의 첫 번째 값인 5와 교환합니다.
[1], [5], 6, 2, 4, 3그리고 정렬되어 있는 1은 제외하고, 두 번째 숫자부터 시작해서 또 가장 작은 값을 찾습니다.
1, [5], [6], 2, 4, 31, [5], 6, [2], 4, 3가장 작은 값인 2는 정렬되지 않는 숫자들 중에서 가장 앞에 있어야 하므로 5와 교환합니다.
1, [2], 6, [5], 4, 3이 과정을 더 이상 교환이 일어나지 않을때까지 반복하면, 아래와 같이 오름차순 정렬이 완료됩니다.
1 2 3 4 5 6선택 정렬 big-o
이러한 정렬 방법을 선택 정렬 이라고 합니다. 의사 코드로 아래와 같이 표현할 수 있습니다.
For i from 0 to n–1
Find smallest item between i'th item and last item
Swap smallest item with i'th item버블 정렬과는 다르게, 몇 번의 교환을 했는지 횟수를 셀 필요가 없습니다. 하지만 선택 정렬은 훨씬 더 많은 비교가 필요하므로 비용이 많이 듭니다.
여기서도 두 번의 루프를 돌아야 합니다. 바깥 루프에서는 숫자들을 처음부터 순서대로 방문하고, 안쪽 루프에서는 가장 작은 값을 찾아야 합니다.
원래 배열의 순서와 상관없이, 선택 정렬로 정렬되는 배열은 n-1 번의 교환이 필요합니다. n-1번의 교환은 확실히 버블 정렬의 교환 횟수 보다는 적습니다. 하지만, 한 번의 교환이 일어나기 위해서는 정렬되지 않은 모든 수와 비교가 이루어져야 하므로, n^2 번의 비교가 이루어집니다.
- 따라서 소요 시간의 상한은 O(n^2)이 됩니다.
- 하한도 마찬가지로 Ω(n^2) 입니다. 버블 정렬과 동일합니다.
정렬 알고리즘의 실행시간
선형 검색, 이진 검색, 버블 정렬, 선택 정렬의 실행시간은 각각 어떻게 되는지 정리해 보겠습니다.
실행시간의 상한
- O(n^2): 선택 정렬, 버블 정렬
- O(n log n)
- O(n): 선형 검색
- O(log n): 이진 검색
- O(1)
실행시간의 하한
- Ω(n^2): 선택 정렬, 버블 정렬
- Ω(n log n)
- Ω(n)
- Ω(log n)
- Ω(1): 선형 검색, 이진 검색
여기서 버블 정렬을 좀 더 빨리 할 수 있는 방법을 알아보겠습니다. 만약 정렬이 모두 되어 있는 숫자 리스트가 주어진다면 어떨까요?
원래 의사 코드는 아래와 같습니다.
Repeat n–1 times
For i from 0 to n–2
If i'th and i+1'th elements out of order
Swap them여기서 안쪽 루프에서 만약 교환이 하나도 일어나지 않는다면 이미 정렬이 잘 되어 있는 상황일 것입니다.
따라서 바깥쪽 루프를 ‘교환이 일어나지 않을때’까지만 수행하도록 다음과 같이 바꿀 수 있습니다.
Repeat until no swaps
For i from 0 to n–2
If i'th and i+1'th elements out of order
Swap them따라서 최종적으로 버블 정렬의 하한은 Ω(n)이 됩니다. 상황에 따라서는 선택 정렬보다 더 빠른 방법이 되는 것이죠.
실행시간의 하한
- Ω(n^2): 선택 정렬
- Ω(n log n)
- Ω(n): 버블 정렬
- Ω(log n)
- Ω(1): 선형 검색, 이진 검색
재귀
재귀란, 함수가 본인 스스로를 호출해서 사용하는 방법을 말합니다.

러시아 인형을 예로 들 수 있습니다. 러시아 인형 속에 더 작은 러시아 인형이 있고 또 그 인형 안에 더 작은 인형이 있는데, 이는 러시아 인형이 너무 작아서 다른 인형을 담지 못할 때까지 계속 됩니다. 이처럼 어떤 문제를 해결하기 위해 알고리즘을 설계할 때 동일한 문제의 조금 더 작은 경우를 해결함으로써 그 문제를 해결하는 것입니다. 문제가 간단해져서 바로 풀 수 있는 문제로 작아질 때까지 말이죠. 이런 테크닉을 재귀라고 합니다. 출처: 재귀란? - Khan Academy
재귀 예시
아래와 같이 피라미드 모양을 출력하기 위해 다음과 같은 코드를 작성할 수 있습니다.
@
@@
@@@
@@@@
void draw(int h);
int main(void)
{
// 사용자로부터 피라미드의 높이를 입력 받아 저장
int height = get_int("Height: ");
// 피라미드 그리기
draw(height);
}
void draw(int h)
{
// 높이가 h인 피라미드 그리기
for (int i = 1; i <= h; i++)
{
for (int j = 1; j <= i; j++)
{
printf("@");
}
printf("\n");
}
}높이를 입력 받아 중첩 루프를 통해 피라미드를 출력해주는 draw 함수를 정의했습니다.
여기서 꼭 중첩 루프를 써야만 할까요? 사실 바깥 쪽 루프는 안 쪽 루프에서 수행하는 내용을 반복하도록 하는 것일 뿐입니다. 따라서 바깥 쪽 루프를 없앤 draw함수를 만들고, 이를 ‘재귀적으로’ 호출하도록 해서 똑같은 작업을 수행할 수 있습니다.
즉, draw 함수 안에서 draw 함수를 호출 하는 것이죠. 아래 코드와 같이 수정할 수 있습니다.
void draw(int h);
int main(void)
{
int height = get_int("Height: ");
draw(height);
}
void draw(int h)
{
// 높이가 0이라면 (그릴 필요가 없다면)
if (h == 0)
{
return;
}
// 높이가 h-1인 피라미드 그리기 (재귀)
draw(h - 1);
// 피라미드에서 폭이 h인 한 층 그리기
for (int i = 0; i < h; i++)
{
printf("@");
}
printf("\n");
}draw 함수 안에서 draw 함수를 다시 호출 하는 부분을 주목해주세요.
h라는 높이를 받았을 때, h-1 높이로 draw 함수를 먼저 호출하고, 그 후에 h 만큼의 @을 출력합니다. 여기서 내부적으로 호출된 draw 함수를 따라가다 보면 h = 0인 상황이 오게 됩니다. 따라서 그 때는 아무것도 출력을 하지 않도록 하는 조건문을 추가해줘야 합니다.
이렇게 재귀를 사용하면 중첩 루프를 사용하지 않고도 하나의 함수로 동일한 작업을 수행할 수 있습니다.
재귀 예시 2
재귀를 이용해 시그마를 구현하는 함수 예시입니다.

추가) 스택 이란?
재귀 함수에서 동일한 함수를 계속 호출할 때마다, 함수를 위한 메모리가 계속해서 할당됩니다. 함수가 호출될 때 마다 사용되는 메모리를 스택이라고 부릅니다.
컴퓨터가 일을 처리하는데 관리를하는 역할인 운영체제는 함수를 실행할 수 있도록 일정량의 바이트를 주고, 그 공간에 함수의 변수나 다른 것들을 저장할 수 있도록 합니다. 그래서 재귀함수를 이용하다 보면 함수가 종료되지 않고, 계속해서 호출되는 경우가 발생하기도 합니다.
이 경우, 스택 공간은 초과되고 프로그램 충돌이 발생하게 됩니다. 그렇기 때문에 재귀를 사용할 때는 과도하게 스택 메모리가 사용되지 않도록 주의해야 합니다. 메모리 사용 문제 때문에 재귀는 매우 유의해야 하지만, 특정 자료구조를 다룰 때 매우 유용하게 사용됩니다.

재귀함수 factorial이 스택 메모리에 할당되고 종료되는 과정
병합 정렬
병합 정렬은 원소가 한 개가 될 때까지 계속해서 반으로 나누다가 다시 합쳐나가며 정렬을 하는 방식입니다. 전화번호부의 분할 정복 탐색처럼 데이터를 반으로 나누어간다는 것과 공통점이 있습니다.
이 과정은 재귀적으로 구현되기 때문에 나중에 재귀를 학습하면 더 이해하기 쉽습니다.
병합 정렬

병합 정렬은 배열의 원소들이 반으로 나누어지는 과정과, 정렬된 후 합쳐지는 과정으로 나누어져 있습니다.
병합 정렬을 히용해 아래 숫자들을 오름차순으로 정렬해 보겠습니다.
7 4 5 2 6 3 8 1먼저 숫자들을 반으로 나눕니다.
7 4 5 2 | 6 3 8 1
그리고 나눠진 부분 중 첫번째를 한번 더 반으로 나눠봅니다.
7 4 | 5 2 | 6 3 8 1마지막으로 한 번 더 나눠봅니다.
7 | 4 | 5 2 | 6 3 8 1이제 숫자가 두 개 밖에 남지 않았으므로 더 이상 나누지 않고, 두 숫자를 다시 병합합니다. 단, 이 때 작은 숫자가 먼저 오도록 합니다. 4와 7의 순서를 바꿔서 병합하는 것이죠.
4 7 | 5 2 | 6 3 8 1
마찬가지로 5 2 부분도 반으로 나눈 후에 작은 숫자가 먼저 오도록 다시 병합할 수 있습니다.
4 7 | 2 5 | 6 3 8 1그럼 이제 4 7과 2 5 두 개의 부분들을 병합하겠습니다.
각 부분들의 숫자들을 앞에서 부터 순서대로 읽어들여 비교하여 더 작은 숫자를 병합되는 부분에 가져옵니다. 즉, 4와 2를 먼저 비교해서 2를 가져옵니다. 그 후에 4와 5를 비교해서 4를 가져옵니다. 그리고 7과 5를 비교해서 5를 가져오고, 남은 7을 가져옵니다.
2 4 5 7 | 6 3 8 1
이제 남은 오른쪽 4개의 숫자들도 위와 동일한 과정을 거칩니다.
2 4 5 7 | 1 3 6 8
마지막으로 각각 정렬된 왼쪽 4개와 오른쪽 4개의 두 부분을 병합합니다.
2와 1을 비교하고, 1을 가져옵니다. 2와 3을 비교하고, 2를 가져옵니다. 4와 3을 비교하고, 3을 가져옵니다. 4와 6을 비교하고… 이 과정을 병합이 끝날때까지 진행하면 아래와 같이 정렬이 완료됩니다.
1 2 3 4 5 6 7 8
전체 과정을 요약해서 도식화해보면 아래와 같습니다.
7 | 4 | 5 | 2 | 6 | 3 | 8 | 1 → 가장 작은 부분 (숫자 1개)으로 나눠진 결과입니다.
4 7 | 2 5 | 3 6 | 1 8 → 숫자 1개씩을 정렬하여 병합한 결과입니다.
2 4 5 7 | 1 3 6 8 → 숫자 2개씩을 정렬하여 병합한 결과입니다.
1 2 3 4 5 6 7 8 → 마지막으로 숫자 4개씩을 정렬하여 병합한 결과입니다.
이러한 방법을 ‘병합 정렬’ 이라고 합니다.
병합 정렬의 big-o
병합 정렬 실행 시간의 상한과 하한은 모두 O(n log n) 입니다.
-
숫자들을 반으로 나누는 데는 O(log n)의 시간이 들고, 각 반으로 나눈 부분들을 다시 정렬해서 병합하는 데 각각 O(n)의 시간이 걸리기 때문입니다.
-
실행 시간의 하한도 역시 Ω(n log n) 입니다. 숫자들이 이미 정렬되었는지 여부에 관계 없이 나누고 병합하는 과정이 필요하기 때문입니다.
