
본 게시글은 인프런의 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한) 강의를 듣고 정리한 내용입니다.
인터넷 네트워크
인터넷 통신
모든 웹 기술을 HTTP 위에서 돌아가기 때문에 백엔드/프론트엔드 관계없이 HTTP 기술을 배워야 한다. HTTP도 결국 모두 인터넷 네트워크 안에서 동작함으로 네트워크, 즉 인터넷 통신에 대한 개념이 필수적이다.
그렇다면 인터넷 통신이란 무엇일까? 클라이언트와 서버가 직접 통신하지 않고 인터넷을 통해서 통신하는 것이다. 인터넷에는 수많은 노드들이 있는데, 원하는 목적지까지 여러개의 노드를 타면서 통신을 하게 된다. 이러한 통신에 대해서 제대로 알기위해서는 우선 IP에 대한 개념을 정리해야한다.
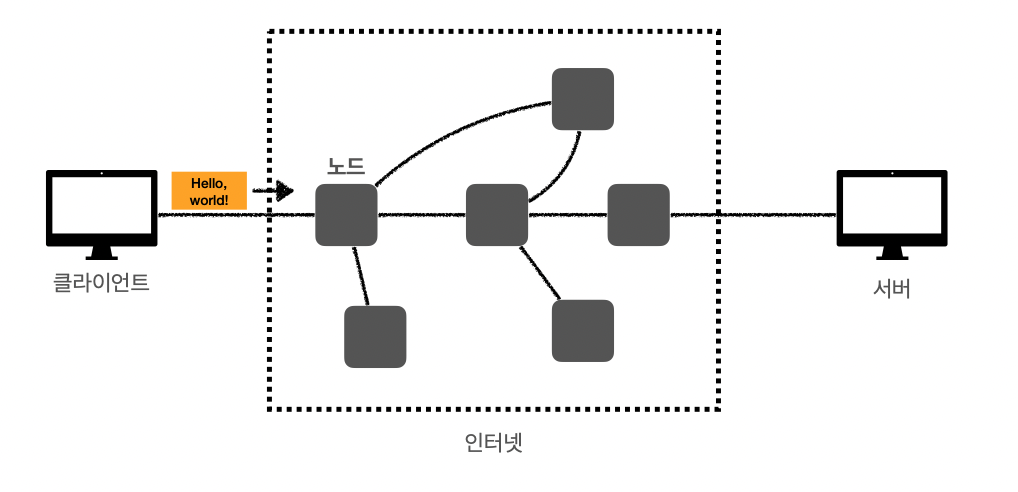
이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
IP(인터넷 프로토콜)
복잡한 인터넷 망에서 요청을 주고받을 때는 규칙이 있어야 한다. 인터넷에서 통신을 위해 요청을 주고 받는 규칙을 바로 IP(Internet Protocol)이라고 한다. 즉, 클라이언트의 IP 주소에서 서버 IP 주소로 데이터를 보내서 인터넷 통신을 하게 된다. 데이터는 전달할 때 패킷 통신 단위로 전달을 하는데, 클라이언트 IP 에서 출발하여 서버 IP에 도착할 때까지 서로 노드끼리 이동을 하다가 최종적인 목적지에 도착하게 된다. IP 패킷에는 세 가지 정보가 있는데, 출발지 IP 주소, 목적지 IP 주소, 그리고 전송 데이터가 들어있다.
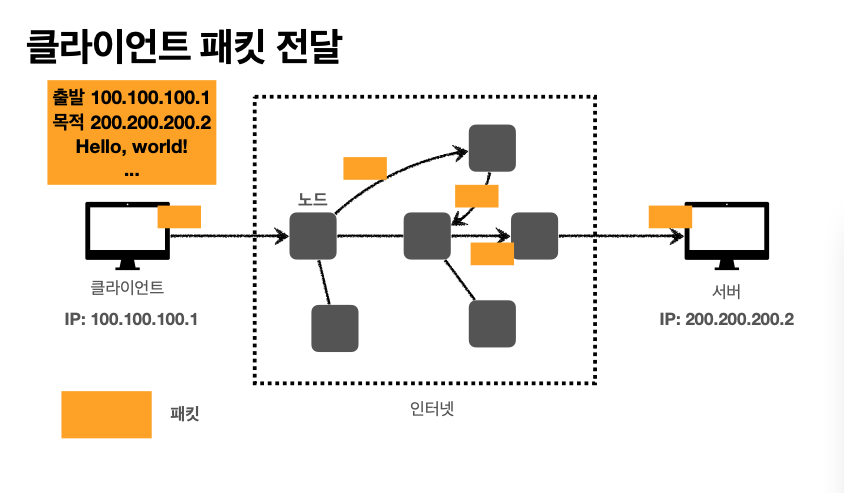
이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
다만, IP 프로토콜만을 이용해서 데이터를 주고 받으면 몇가지 한계점이 있다. 우선 비연결성이라는 특성 때문에, 패킷을 받을 대상이 없거나 불능 상태 (ex. 서버가 꺼져있음)에 있더라도 무조건 패킷을 전송하게 된다. 두번째는 비신뢰성이다. 패킷이 중간에 유실되어도, 어떤 패킷이 유실되었는지 알려주거나 유실된 패킷을 방지할 수단이 없고, 패킷의 순서 보장도 어렵다. 마지막으로, 프로그램 간 구분이 어렵다. 예를들어, 같은 IP를 사용하는 서버에서 통신하는 애플리케이션이 여러개가 있을 수 있다. 이 경우, IP 프로토콜은 서버 IP만 가지고 있으므로 어떤 프로그램에 요청을 하는건지 구분하기가 어렵다. 이 모든 한계점을 해결하기 위해 생긴 기술이 바로 TCP/UDP 이다.
TCP/UDP
TCP/UDP는 각각 Transfer Control Protocol/User Datagram Protocol의 약자로, 인터넷 프로토콜 4계층중 세 번째 계층인 전송 계층이다. IP 계층 위에서 보완해주는 용도라고 생각하면 된다.

이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
위 4계층에 따라 순서대로 메세지가 전송되는데, 전송되는 순서는 아래와 같다:
- [애플리케이션] 프로램이 "Hello World" 메세지 생성
- [애플리케이션] Socket 라이브러리에서 OS 계층으로 메세지 전달
- [OS] Hello 메세지에 TCP 정보를 한번 씌움
- [OS] 그다음 IP 관련 데이터 정보를 한번 더 씌움 (= ip 패킷)
- [네트워크 인터페이스] 마지막으로 Ethernet Frame이 씌워져서 LAN 카드로 나감 (맥주소 등 물리적인 주소 포함)
- 인터넷으로 데이터 전달됨
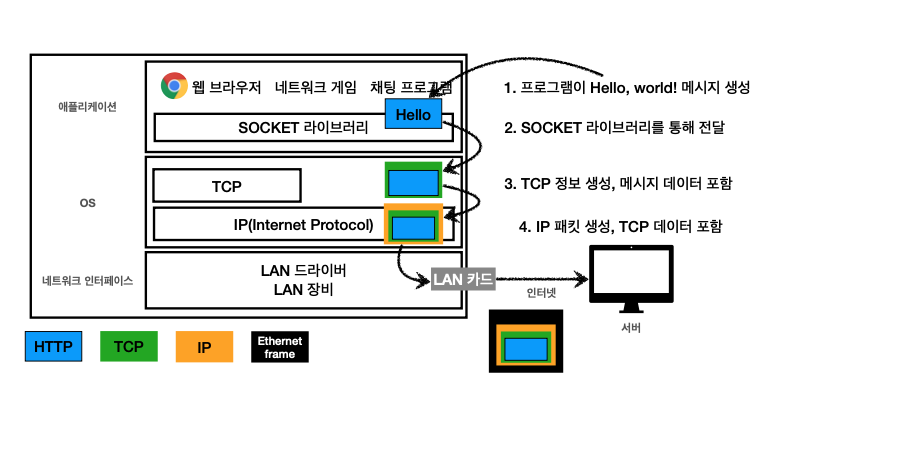
이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
TCP/IP 패킷은 기존에 출발지 IP, 목적지 IP, 데이터만을 담고 있던 IP 패킷에 TCP 세그먼트를 추가하여 IP 패킷의 한계점을 보완한다. 패킷은 수화물을 뜻하는 패키지(package)와 덩러리를 뜻하는 버킷(bucket)을 합친말인데, 데이터를 넣는 박스같은 것을 뜻한다. TCP/IP 패킷은 출발지 및 목적지 정보 뿐만 아니라, 출발지 port, 목적지 port, 전송 제어, 순서, 검증 정보 등의 추가적인 내용을 담는다. 따라서, IP 에서 해결되지 않던 문제들을 TCP 세그먼트가 해결하게 되었다.

이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
TCP(Transfer Control Protocol) 특징
TCP 특징은 크게 세 가지가 있다. 연결 지향, 데이터 전달 보증, 순서 보장이다. TCP는 3 way handshake라는 가상 연결 방식으로 통신을 하게 되는데, 클라이언트와 서버가 서로 연결이 가능한 상태인지 확인하는 절차를 거치고 연결하기 때문에 신뢰성을 높인다. 또한, 데이터 누락을 알 수 있게 해주기 때문에 데이터 전달이 보증된다. 마지막으로, TCP 패킷에는 순서와 관련된 정보가 추가되기 때문에, 패킷의 순서를 보장해준다. 그렇다면, TCP 3 way handshake가 무엇인지부저 확인해보자.
TCP 3 way handshake
TCP 3 way handshake는 TCP/IP 프로토콜을 이용해 통신을 하기 전, 정확한 전송을 보장하기 위해 상대 컴퓨터와 사전에 연결이 잘 되는지 확인하는 과정이다. 참고로 TCP 연결은 전용 랜선 직접 연결이 아닌 논리적인 연결이므로 클라이언트와 서버를 연결하는 수많은 노드(서버)들은 제외하고, 논리적으로 연결되었다고 간주하는 방식이다. TCP 3 way handshake는 크게 세 단계로 나뉜다:
- 클라이언트에서 SYN (synchronize) 메세지를 보낸다 (=연결해달라고 요청)
- 서버에서 알았다는 뜻으로 ACK(acknowledgement)와 나도 연결해달라는 SYN 메세지를 두개 보낸다.
- 클라이언트에서 응답을 확인했다는 뜻으로 ACK를 보낸다.
결국 둘다 SYN + ACK 메세지를 각각 세 번에 걸쳐서 보내는 방식이다. TCP 연결이 세 단계를 걸쳐 성공적으로 연겨로디면 데이터를 전송하게 된다. 만약 처음이나 혹은 중간단계에서 서버가 꺼져있으면 응답을 받지 못해서 연결이 되지 않고, 데이터도 보낼 수 없게 된다. 다만, 최근에는 해당 과정이 최적화 되어서 ACK 보낼 때 메세지도 같이 보내기도 한다.
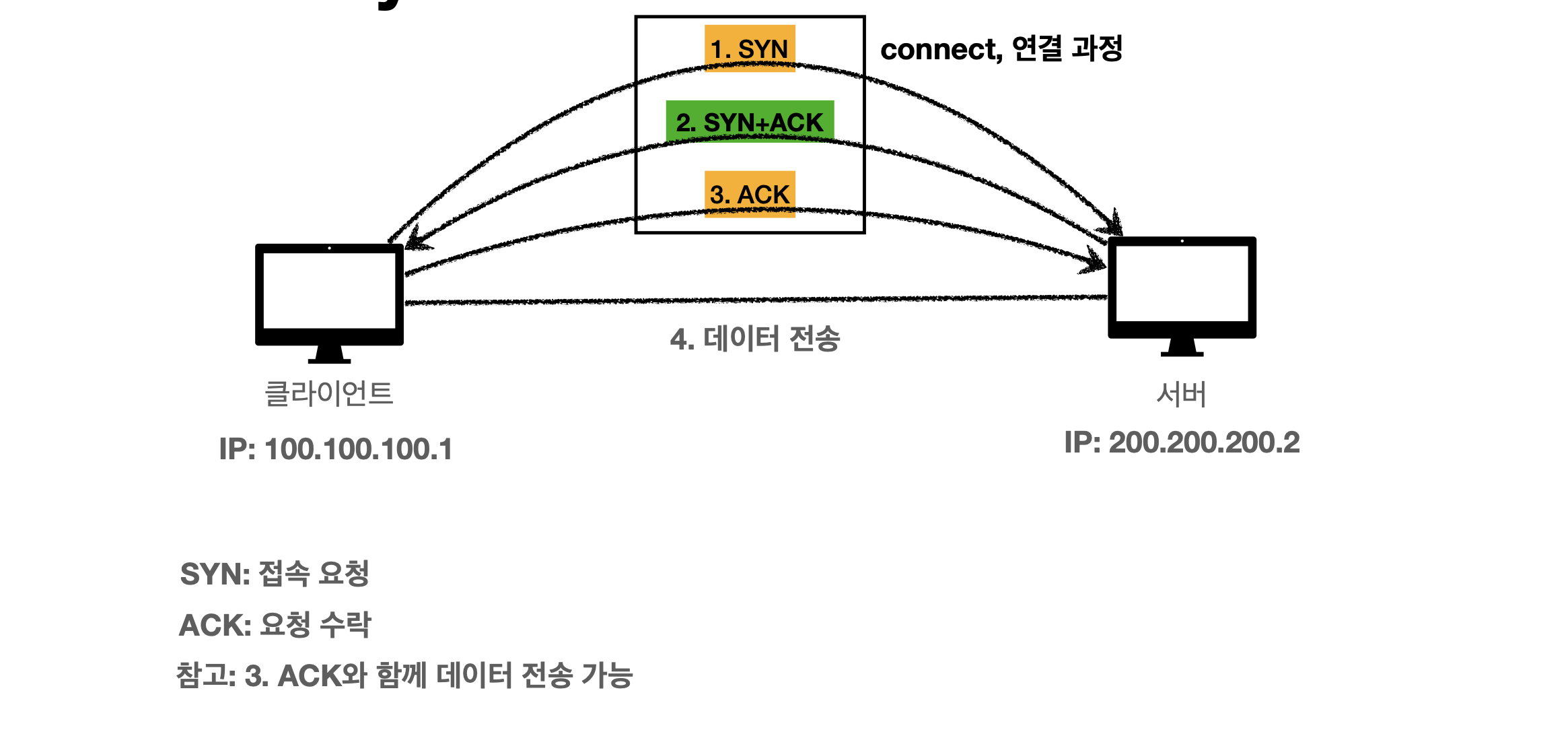
이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
UDP(User Datagram Protocol)
UDP의 경우 TCP에 비해 기능이 거의 없는 프로토콜이다. UDP는 비연결성, 비신뢰성 전송 프로토콜로, 3 way handshake 과정도 없고 데이터 전달 및 순서가 보장이 안된다. IP 프로토콜과 거의 비슷한 기능을 가지고 있지만, 다른점은 PORT가 추가되었다는 것이다. 정확히 PORT와 체크섬이라는 속성이 추가된 비연결성 전송 프로토콜이다.
- PORT: 포트는 컴퓨터의 세부 주소라고 이해할 수 있다. 예를 들어, 하나의 컴퓨터로 노래도 들으며 웹 서핑도 하고 동시에 게임까지 할 수 있다. 이때, 내 PC는 하나의 IP를 가지고 있기 때문에 어떤게 게임 패킷이고, 어떤게 음악용 패킷인지 구분하기 어렵다. 이걸 구분해주는 것이 바로 포트이다.
- 체크섬: 체크섬은 메세지가 제대로 왔는지 검증해주는 데이터를 말한다
그렇다면 UDP는 사용성이 떨어지는 TCP일 뿐일까? 오히려 기능이 적기 때문에 내가 원하는 기능을 추가해서 커스텀할 수 있다는 장점이 있다. 원래는 빠르게 데이터를 전송하는 영상, 노래 등을 들을 때 사용되는 프로토콜이었지만, 최근은 영상도 TCP 프로토콜을 한다고 한다. (다만 요즘은 UDP가 다시 뜨는 중이라고 함) 추가로, HTTP 3 에서는 기본적으로 UDP 프로토콜을 사용한다고 한다.
PORT
위에 짧게 언급한 포트(Port)에 대해서 구체적으로 알아보자. 포트(Port)는 뜻 그대로 배가 도착하는 '항구'의 뜻을 가지고 있다. 한번에 두 개 이상 서버와 연결해야할 때, IP만 보내면 어디서 오는 패킷인지 알 수가 없다. 이러한 문제를 출발지/목적지 PORT를 추가함으로서 구분할 수 있다. 하나의 컴퓨터라도 사용하는 연결마다 포트를 다르게 저장할 수 있기 때문이다. 비유를 하자면, IP가 아파트이고 Port는 동/호수이다.
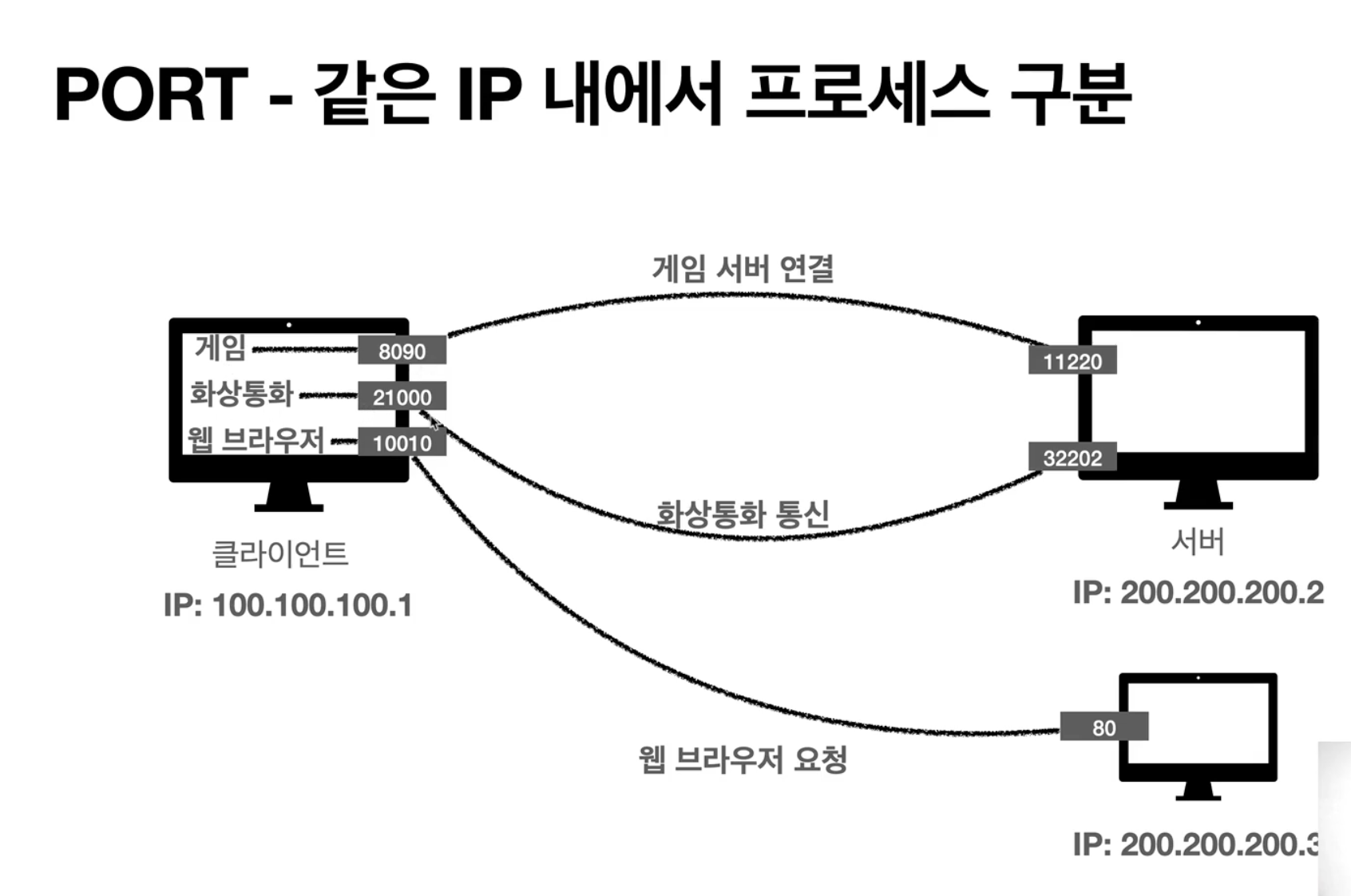
이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
Port는 0 ~ 65535 까지 할당이 가능한데, 0 ~ 1023 까지는 잘 알려진 포트이고 이미 할당이 된 경우가 많으니 사용하지 않는게 좋다. 예를 들어 FTP는 포트 20, 21을 사용하고 HTTP는 포트 80, HTTPS는 포트 443을 사용한다.
DNS
인터넷 네트워크의 마지막 주제인 DNS에 대해서 알아보자. DNS는 도메인 네임 시스템의 약자로 IP 주소에 도메인 이름을 등록할 수 있게 해준다. IP 주소는 외우기도 어렵고, 변경될 수도 있기 때문에 접근하기 어려운 문제가 있다. 따라서, DNS를 통해 전화번호부 같은 서버를 제공해서 쉬운 도메인을 등록할 수 있다. 아래 사진처럼 클라이언트에서 특정 도메인을 검색하면, DNS 서버에서 해당하는 도메인의 IP 주소를 주고, 해당 IP로 접속을 하게 된다.
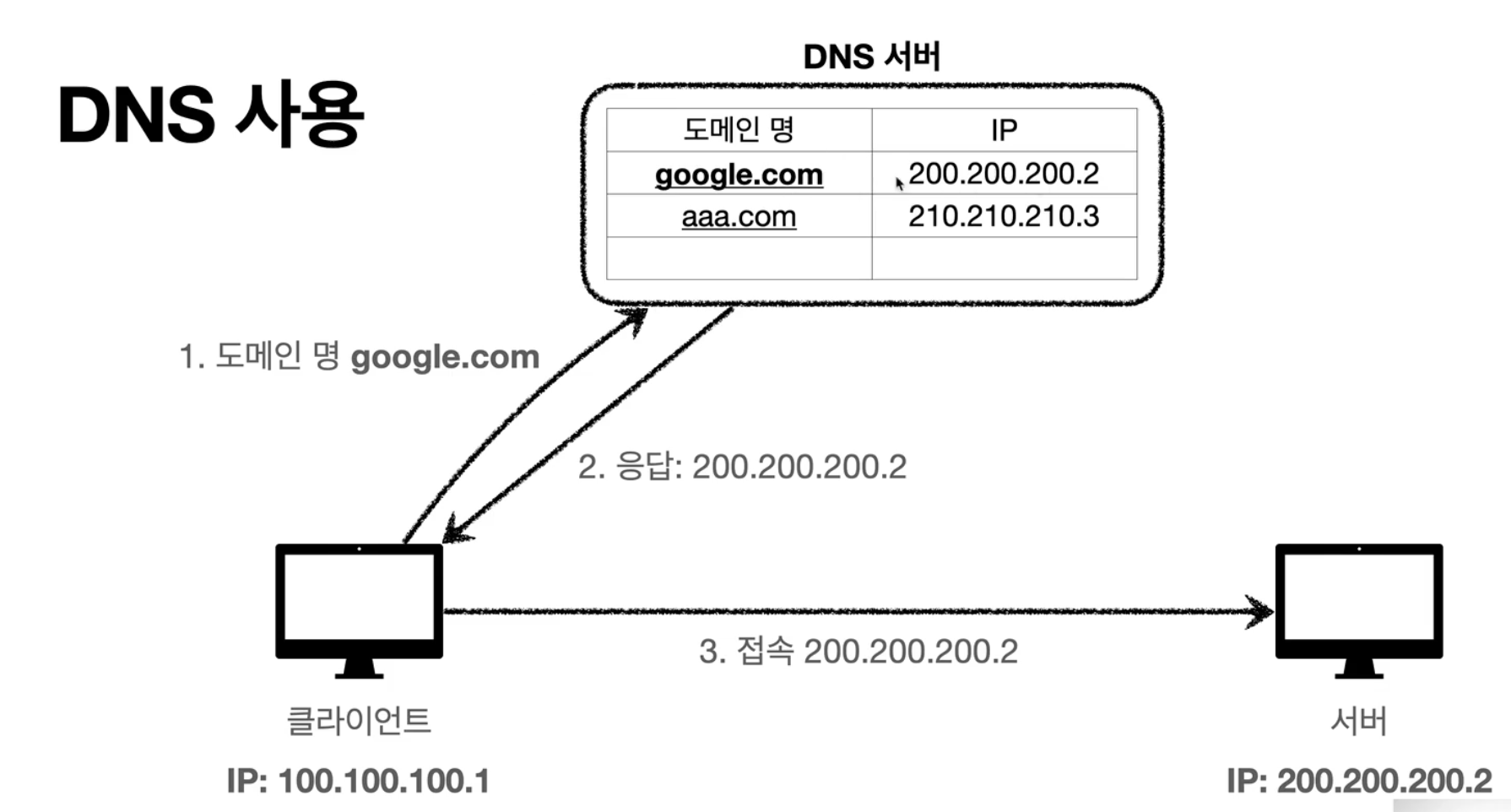
이미지 출처: 모든 개발자를 위한 HTTP 웹 기본 지식 (김영한)
URI와 웹 브라우저 요청 흐름
URI
URI는 Uniform Resource Identifier의 약어로 리소스를 식별하는 통합된 방법을 뜻한다. URI, URL, URN이라는 비슷한 이름들이 있어 헷갈릴 수 있는데, 각각의 정의는 다음과 같다:
- URI: 로케이터, 이름 또는 둘다 추가로 분류될 수 있음
- URL: URI 범주 내에서 위치를 나타냄
- URN: URI 범주 내에서 이름을 나타냄
즉, 우리가 웹 브라우저에서 적는게 URL이고, 이름을 부여한게 URN이다. 거의 URL만 사용한다고 보면 된다.
그리고 URI의 각 단어 뜻을 해석자하면 아래와 같은 의미가 나온다:
- Uniform: 리소스 식별하는 통일된 방식
- Resource: 자원. (HTML 파일 뿐만 아니라, 실시간 교통정보 등 구분할 수 있는 모든것)
- Identifier: 식별자
URL 분석
그렇다면 가장 자주 사용한다는 URL을 분석해보자, 아래와 같은 URL이 있다고 하자:
그리고 해당 URL를 공식화 하면 아래와 같이 나타낼 수 있다
- scheme://[userinfo@]host[:port][/path][?query][#fragment]
위 예시에서 볼 수 있듯 URL에는 스키마 (주로 프로토콜 https) / 호스트 (www.google.com) / 포트 번호 (443) / 패스(/search)/ 쿼리 파라미터(q=hello&hl=ko) 등이 들어간다. 포트번호는 생략될 수 있다.
URL Scheme에는 주로 프로토콜이 사용된다. 어떤 방식으로 자원 접근할 것 인지에 대한 약속 규칙인데, 주로 http나 https를 사용한다. Http는 포트 80, httpss는 포트 443을 사용하지만 URL에서는 주로 생략하여 사용한다. (https는 보안이 적용된 http 프로토콜이다)
URL Path는 리소스가 있는 경로이다. 대부분 컴퓨터 디렉토리 처럼 계층 구조로 되어있다.
URL Query는 key=value 형태로 작성이 되는데, ?로 시작하고 &문자열을 사용해 쿼리를 더 추가할 수 있다. 숫자로 적어도 결국은 모두 문자로 변환되어 넘어가기 때문에 쿼리 스트링이라고 부른다.
마지막으로, URL Fragment는 내부 북마크 등으로 사용할 수 있다. 주로 #id 형태로 샵(#)과 id명을 뒤에 작성해서 작업한다. Fragment는 서버로는 요청이 가지 않고 내부 페이지 이동에서 사용된다.
웹 브라우저 요청 흐름
위에서 배운 개념들을 적용해서 검색창에 특정 URL을 검색했을 때 어떤 과정을 거치는지 알아보자:
- https://www.google.com/search?q=hello&hl=ko 를 브라우저에 검색
- DNS 서버에 호스트 (google.com) 조회해서 IP 및 PORT 얻어옴
- 웹 브라우저가 HTTP 요청 메세지 생성
- Socket 라이브러리 통해서 애플리케이션 -> OS 계층으로 전달
- TCP/IP 패킷 생성 (전송 데이터에 아래와 같은 HTTP 메세지를 추가함)
- 패킷 정보가 인터넷으로 흘러들어감
- 구글 서버에 요청 패킷 도착
- 구글 서버에서 TCP/IP 패킷 다 까서 버리고, HTTP 메세지 분석함
- 구글 서버에서 응답 메세지를 만듦 (200 OK, Content-Type, Content-Length 등)
- 클라이언트에 응답 패킷 도착
- 응답 메세지를 열어서 웹 브라우저에 HTML 렌더링
URL (https://www.google.com/search?q=hello&hl=ko)을 검색하면 바로 해당 url로 이동하는 것이 아니라, IP 주소를 얻어야 한다. 따라서, 먼저 DNS 서버에 호스트 주소를 조회해서 IP 및 Port를 얻어오는 과정을 거치게 된다. IP 주소를 얻게 된다면, 웹 브라우저가 HTTP 요청 메세지를 생성하게 된다. GET 요청이므로 GET /search?q=hello&hl=ko HTTP/1.1 형태의 URL 내용과 호스트 Host:www.google.com 내용을 넣어서 HTTP 메세지를 만든다.
웹 브라우저에서 생성된 HTTP 요청 메세지는 Socket 라이브러리를 통해 애플리케이션에서 OS 계층으로 전달이 된다. OS 계층으로 온 메세지는 TCP/IP 패킷에 추가되어 전송을 할 준비를 한다. 전송 데이터에 HTTP 메세지를 추가한 후 TCP 3 way handshake로 서버와 연결을 확인한다. 만약 연결이 잘 된 경우 패킷이 인터넷으로 흘러 들어가게 되며 결국 구글 서버에 요청 패킷이 도착한다.
구글 서버는 TCP/IP 패킷을 까서 버리고, 그 안에 있던 HTTP 메세지를 꺼내서 분석하게 된다. 어떤 페이지를 어떤 형태로 보내야하는지 확인 후에 구글 서버에서 응답 메세지를 만들게 된다. 이때 HTTP 코드, Content-Type, Content-Length 등의 속성과 HTML 파일을 함께 전송하게 된다. 예를 들어 다음과 같은 응답 메세지를 보낼 수 있다:
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 3423
<html>
<body>...</body>
</html>해당 패킷은 똑같은 방식으로 클라이언트로 전달이 되는데, 응답 패킷이 도착하면 클라이언트는 응답 패킷을 확인한다. 그리고 응답 메세지를 열어 웹 브라우저에 HTML을 렌더링 한 후 사용자에게 요청한 화면을 보여주게 된다.
