Ⅰ. 📚 오늘 배운 내용
- 웹스크래핑(크롤링) 기초
1) beautiful soup 사용법- [prac] 순위 / 영화제목 / 별점 print하기
- DB
1) 형식
2) mongoDB 연결
단일・다중 데이터 추가하기
모든・특정 데이터 가져오기
데이터 업데이트/삭제- 웹스크래핑 결과 저장하기
- [prac] 웹스크래핑 데이터 활용
1) 'title'이 '가버나움'인 영화의 별점 가져오기
2) '가버나움'과 같은 'star' 점수를 가진 영화 'title' 가져오기
3) '가버나움'의 'star' 점수를 '0'으로 수정
웹스크래핑(크롤링) 기초
📍 크롤링할 때 필요한 것
- html 가져오기 (requests를 통해)
- 가져오는 정보 특정하기 (beautiful soup 설치)
PyCharm > 환경설정 > 프로젝트 : pythonprac > Python 인터프리터 > + 버튼 > bs4 검색 > 패키지 설치
1) beautiful soup 사용법
(1) selector 복사하기
가져올 정보가 있는 웹사이트 접속 > 정보 텍스트 항목 마우스 우클릭 > 검사 > 복사 > selector 복사 > 코드 내 복붙
(2) 선택한 텍스트를 print하기
title = soup.select_one('#복사한 코드 복붙')
print(title.text).selct_one을 쓴 건 하나라서
(3) 선택한 텍스트를 href링크 print하기
title = soup.select_one('#복사한 코드 복붙')
print(title['href'])(4) 같은 형식의 여러 정보 가져오기
① (1) selector 복사하기를 2회 정도 해서 어떤 코드가 반복되는 지 확인하기
ex) #old_content > table > tbody > tr이 겹침
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
#old_content > table > tbody > tr:nth-child(4) > td.title > div > a👉 input
movies = soup.select('#old_content > table > tbody > tr')
print(movies)👇 개발자 모드로 확인하면 <tr></tr> 구조의 리스트가 반복되는 데이터인 것을 확인할 수 있음
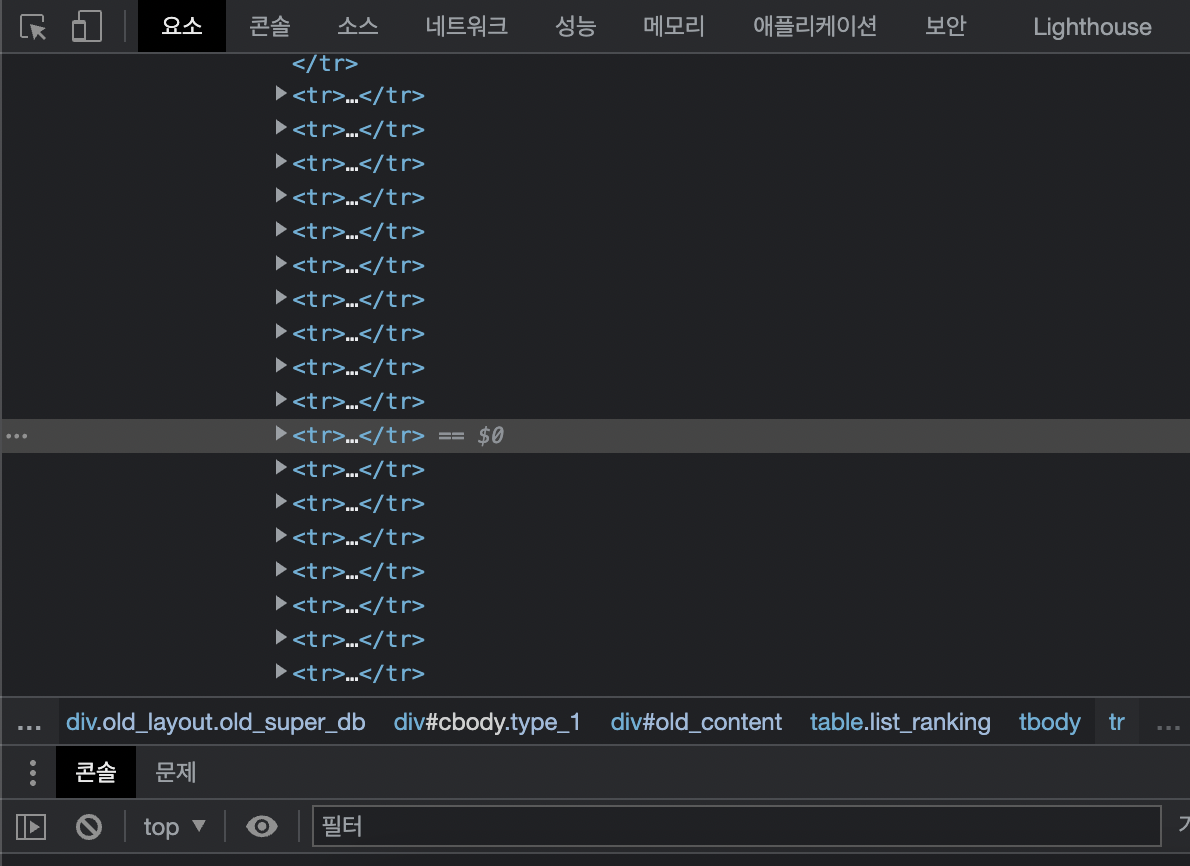
② 페이지상 같은 형식의 여러 정보를 텍스트로 가져오기
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a != None:
print (a.text)
- 조건문에서 같지 않다의 표현법 :
!=,is not None- None값이 있어서 제외하기 위해 조건문 사용
🔥 [prac] 순위 / 영화제목 / 별점 print하기
👇 오류코드
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
b = movie.select_one('td:nth-child(1) > img')['alt']
c = movie.select_one('td.point')
if a != None:
title = a.text
rank = b.text
star = c.text
print(rank, title, star)/Users/hailey/Desktop/sparta/pythonprac/venv/bin/python /Users/hailey/Desktop/sparta/pythonprac/week3_crawling_220801.py
Traceback (most recent call last):
File "/Users/hailey/Desktop/sparta/pythonprac/week3_crawling_220801.py", line 33, in <module>
b = movie.select_one('td:nth-child(1) > img')['alt']
TypeError: 'NoneType' object is not subscriptable
종료 코드 1(으)로 완료된 프로세스📍 오류 이유를 못 찾았다. 알게 되는 대로 업데이트할 예정
👇 정상코드
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a != None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank, title, star)
DB
- 엑셀과 같은 일종의 프로그램, 데이터를 나중에 찾아서 잘 뽑아 쓰기 위해 index로 데이터를 정렬
- 주로 cloud 형태로 사용
1) 형식
- SQL : 칸으로 나눠져있어 정해진 데이터를 정리하기 쉬움 / 데이터 종류나 양이 늘어날때 유연하게 대처하기 어려움
- NoSQL(not only SQL) : 들어오는 대로 정리 / 초기 서비스나 초기 스타트업이 쓰기 유용. 대표적으로 mongoDB가 있음
2) mongoDB 연결
(1) 패키지 설치
PyCharm > 환경설정 > 프로젝트 : pythonprac > Python 인터프리터 > + 버튼 > pymongo와 dnspython 검색 후 패키지 설치
(2) mongoDB
① 가입 및 세팅
계정 생성 및 database 만들기까지 완료 > connect > Allow Access from Anywhere > Add IP Address > user name과 password 기입 > Create Database user > Choose a connection method > Connect your application > Driver : Pyton / VERSION : 3.6 or later > 2번째에 있는 application code 복사하기
② 파이썬에서 활용하기
- 기본 세팅코드에 복사한 application code 붙여넣기
from pymongo import MongoClient
client = MongoClient('mongoDB 코드붙여넣기')
db = client.내프로젝트이름📍 코드 내에 아이디, 비밀번호, DB명 등이 내가 설정한 값이 맞는 지 확인하기
from pymongo import MongoClient
client = MongoClient('mongodb+srv://아이디:패스워드@c내DB명.내주소.mongodb.net/내DB명?retryWrites=true&w=majority')
db = client.내프로젝트이름단일 데이터 추가하기
from pymongo import MongoClient
client = MongoClient('mongodb+srv://아이디:비밀번호@내DB명.내주소.mongodb.net/내DB명?retryWrites=true&w=majority')
db = client.내프로젝트이름
doc = {
'name':'bob',
'age':27
}
db.컬렉션이름.insert_one(doc)❗️코드가 틀린 곳이 없는 데 계속 오류가 난다?!
문의 결과 내 경우에는 '인터넷 환경에 따라 보안관련 추가 설정이 필요하여 생긴 오류'라고 한다.❗️
📍 인터넷 보안에 의한 오류 해결방법
① PyCharm에서 'certifi' 패키지 설치 후 하단에 수정된 코드를 입력
👉 input
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://아이디:비밀번호@c내DB명.내주소.mongodb.net/내DB명?retryWrites=true&w=majority', tlsCAFile=ca)
db = client.내프로젝트이름
doc = {
'name':'bob',
'age':27
}
db.컬렉션이름.insert_one(doc)👉 output
추가한 데이터는 browse collections에서 확인할 수 있다. 이것 때문에 30분간 씨름했다...😇

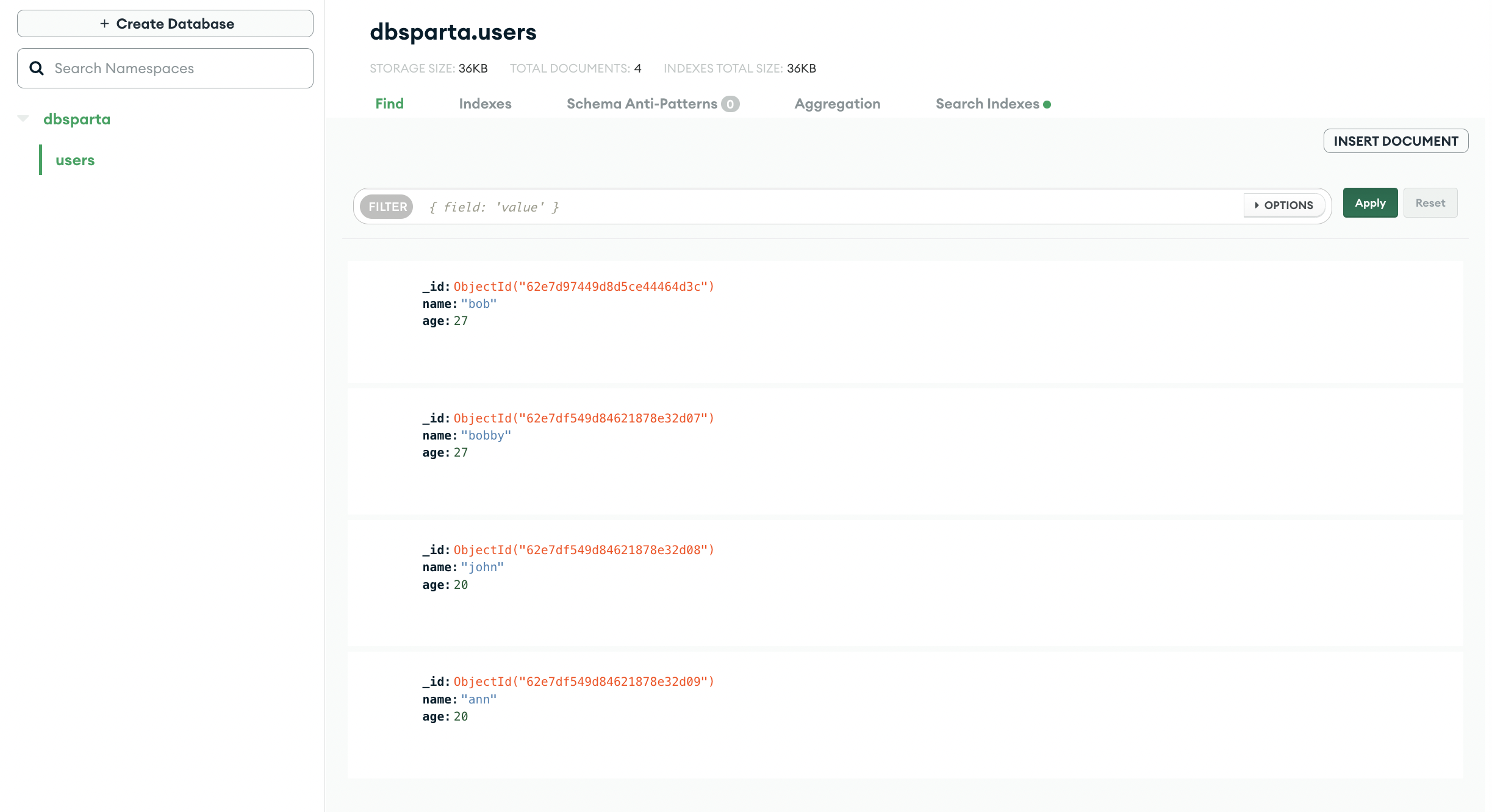
다중 데이터 추가하기
👉 input
db.컬렉션이름.insert_one({'name':'bobby','age':27})
db.컬렉션이름.insert_one({'name':'john','age':20})
db.컬렉션이름.insert_one({'name':'ann','age':20})👉 output
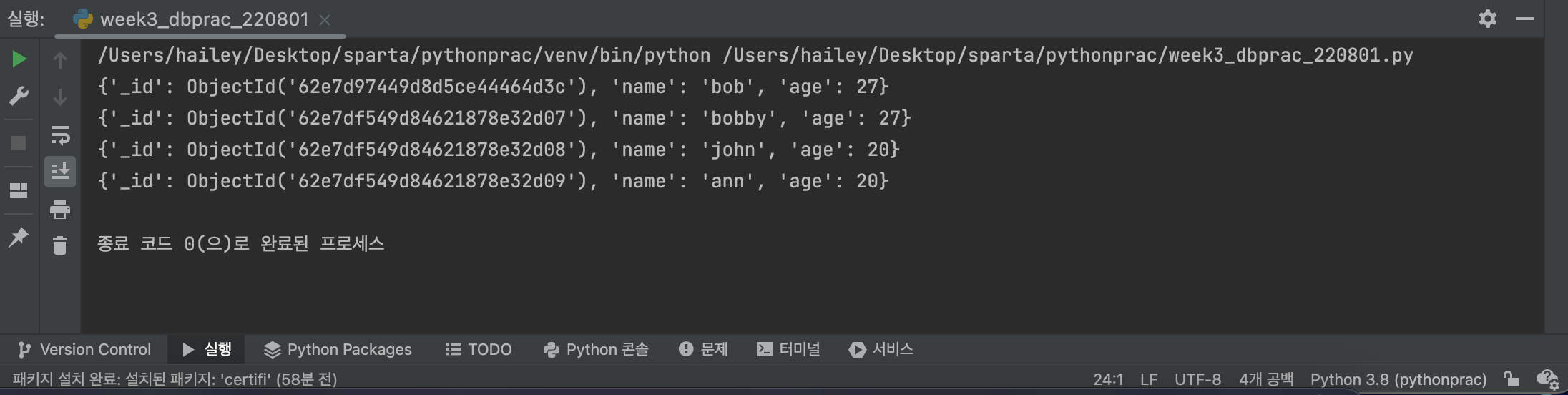
모든 데이터 가져오기
👉 input
all_users = list(db.users.find({}))
for user in all_users:
print(user)👉 output
📍 '_id' 생략해서 가져오기
👉 inputall_users = list(db.users.find({},{'_id':False})) for user in all_users: print(user)
👉 output
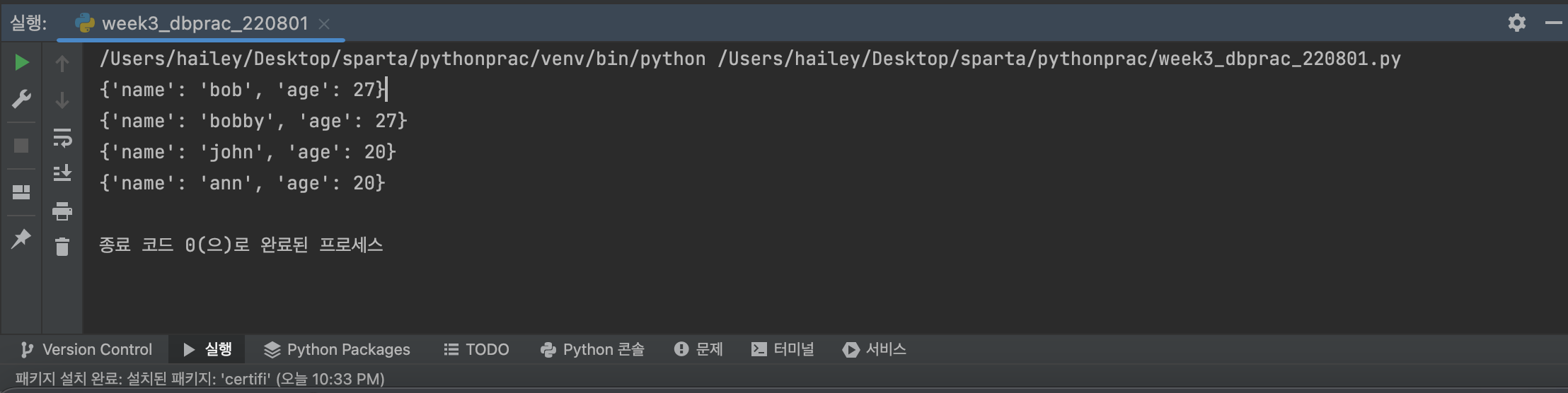
특정 데이터 가져오기
- 'name'이 'bob'이라는 데이터의 'age' 가져오기
👉 input
user = db.users.find_one({'name':'bob'},{'_id':False})
print(user['age'])👉 output
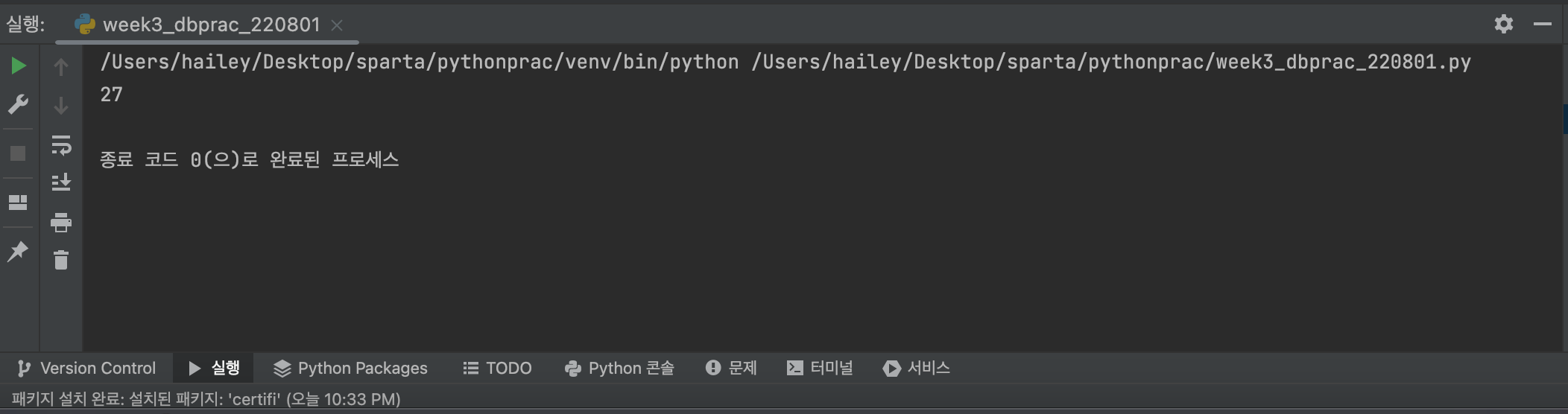
데이터 업데이트
- 'name'이 'bobby'이라는 데이터의 'age'를 19로 수정하기
👉 input
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})데이터 삭제
- 'name'이 'bobby'이라는 데이터 삭제
👉 input
db.users.delete_one({'name':'bobby'})웹스크래핑 결과 저장하기
- 필요한 사항
beautiful soap으로 크롤링한 데이터 + 데이터를 저장할 mongoDB
👉 input
…
# 크롤링 데이터 mongoDB에 저장
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a != None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank, title, star)
doc = {
'title':title,
'rank':rank,
'star':star
}
db.movies.insert_one(doc)👉 output
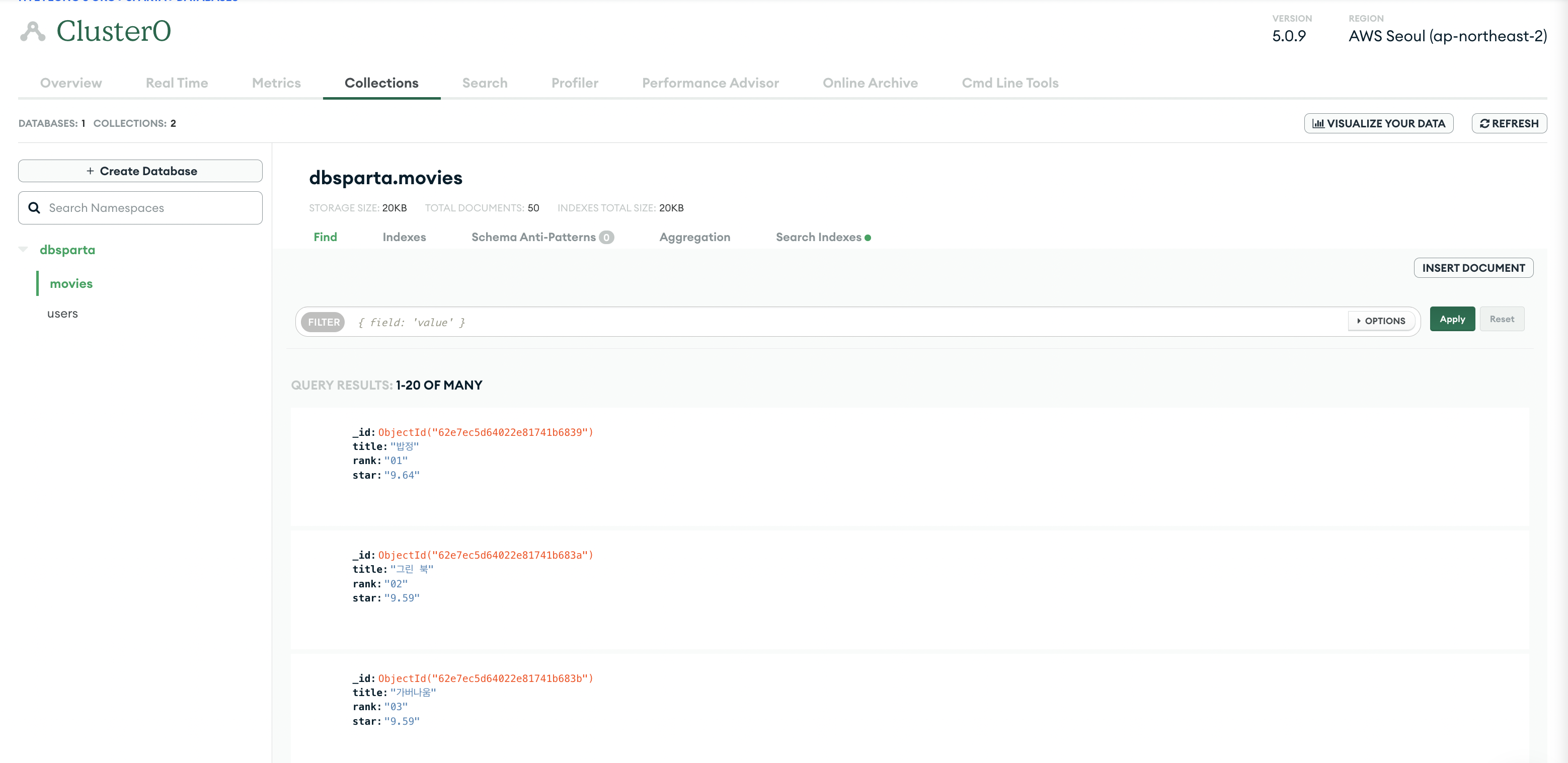
🔥 [prac] 웹스크래핑 데이터 활용
1) 'title'이 '가버나움'인 영화의 별점 가져오기
movie = db.movies.find_one({'title':'가버나움'})
print(movie['star'])
➟ 9.592) '가버나움'과 같은 'star' 점수를 가진 영화 'title' 가져오기
👇 오류 코드
movie = db.movies.find_one({'star':'9.59'})
print(movie['title'])
➟ 그린 북📍오류 이유
- '가버나움'의 현재 별점인 9.59로 조회하려고 함. 하지만 현재는 이 수치더라도 나중에 데이터가 변경될 수 있기에 조건을 잘못 입력함
- 데이터 값이 '그린 북'만 표시됨
👇 정답 코드
movie = db.movies.find_one({'title':'가버나움'})
star = movie['star']
all_movies = list(db.movies.find({'star':star},{'_id':False}))
for a in all_movies:
print(a['title'])
➟ 그린 북
➟ 가버나움3) '가버나움'의 'star' 점수를 '0'으로 수정
👉 input
db.movies.update_one({'title':'가버나움'},{'$set':{'star':'0'}})Ⅱ. 📝 회고
[prac] 순위 / 영화제목 / 별점 print하기가 왜 오류났는 지 모르겠다. 구체적으로는 for movie in movies: 단락에 a = movie.select_one('td.title > div > a')만 들어가야는 지 모르겠다... 답을 찾아보자!
Ⅲ. ☑️ TO DO
- 3주차 homework

안녕하세요!
저도 지금 웹개발 종합반 듣고 있는데
3주차에서 error 해결하고 싶어서 찾다가 이 블로그를 찾게 되었습니다.
저도 지금 TypeError: 'NoneType' object is not iterable 이 부분을 해결하지 못 했네요😂
그리고 저도 velog로 개발일지 쓰고 있습니다