추상화 메커니즘
- 추상화의 목적 : 복잡성을 이해하기 쉽게 단순화하는 것
- 타입을 정의함으로써 객체의 특징을 추상화할 수 있다.
- 즉, 타입을 정의하는 방법이 추상화 메커니즘!

Swift에서 추상화 메커니즘을 선택할 때 3가지를 고려하는데,
1. 정의한 인스턴스가 Stack에 할당되는지? Heap에 할당되는지?
2. 인스턴스를 전달할 때 얼마나 많은 참조 카운팅 오버헤드가 일어나는지?
3. 인스턴스의 메서드를 호출할 때 그게 Stack Dispatch를 통해 일어나는지? Dynamic Dispatch를 통해 일어나는지?

오른쪽으로 갈수록 성능이 저하되고, 왼쪽으로 갈수록 성능이 좋아집니다.
할당(Allocation)
Swift는 자동으로 메모리에 할당하고 해제하는데, 메모리 중 일부는 Stack에 저장된다.
- Stack
- 함수 호출시 함수의 지역변수, 매개변수, 리턴 값 등등이 저장된다.
- 함수, 즉 코드블럭이 종료되면 메모리에서 해제된다.
- 컴파일 타임에 크기가 결정되기 때문에 Heap과 달리 동적 할당/해제가 불가능하다.
- 메모리를 할당할 때는 Stack Pointer가 가리키는 곳에 할당한다.
- LIFO(Last-In, First-Out) 구조로, Stack의 끝인 Top에서만 Push/Pop이 가능하다.
- Stack 메모리 할당의 시간복잡도는 O(1)로 매우 빠르다. - Heap
- ARC에 의해 Reference Counting이 가능한 영역이다.
- 사용자의 동적 할당에 기반하여 런타임에 크기가 결정된다.
- 클래스의 인스턴스, 클로저와 같은 참조 타입이 저장된다.
- 메모리에 제한이 없다는 장점이 있지만, 메모리 할당/해제 작업으로 인해 속도가 저하된다는 단점이 있다.- Heap 메모리를 할당하려면, 실제 Heap 데이터 구조를 검색하여 사용하지 않은 적절한 크기의 블록을 찾아야 한다.
- Heap 메모리를 해제하려면, 해당 메모리를 적절한 위치로 다시 삽입해야 한다.
- 여러 Thread가 동시에 Heap 메모리를 할당할 수 있기 때문에, Heap은 locking/기타 동기화 메커니즘을 통해 무결성을 보장해야한다.
Struct 타입인 경우
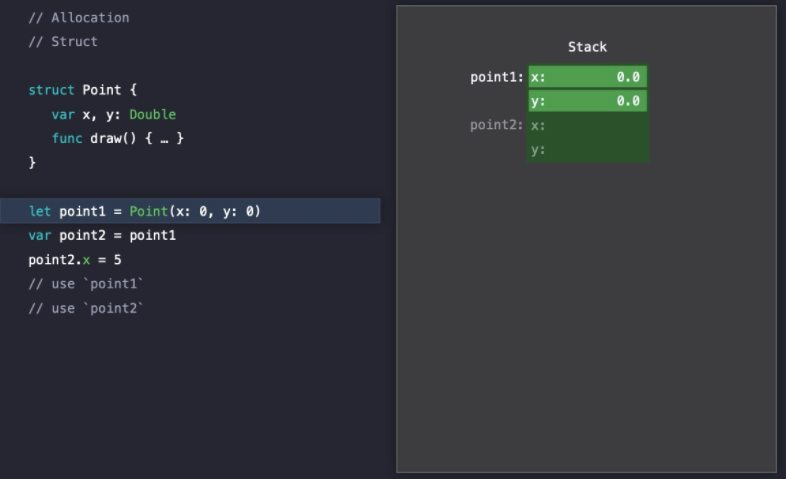
Point라는 Struct 타입의 인스턴스를 만들고 복사한 모습인데, 타입 정의 때부터 이미 메모리는 할당되었고 Point(x: 0, y: 0)으로 초기화를 해줄 때에는 이미 할당된 메모리를 초기화하는 것이다.
그리고 point2에 point1을 초기화 할 때에는 point에 대한 복사본을 만들고 Stack에 이미 할당된 메모리를 다시 초기화해주는 것이다.
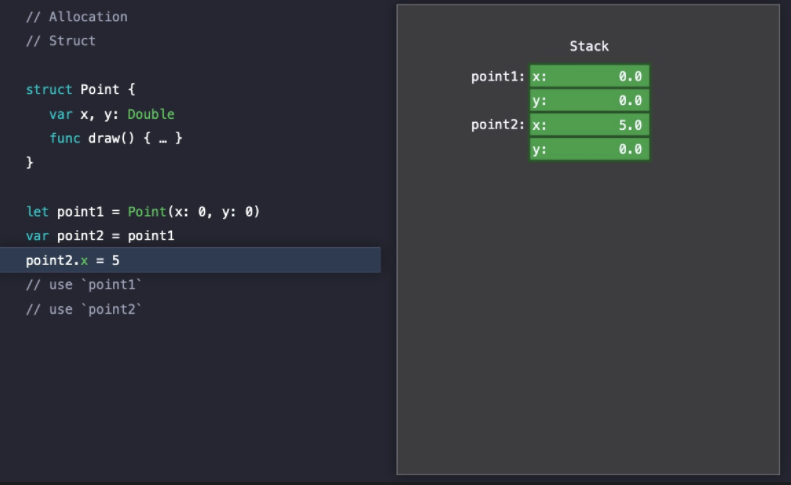
point1과 point2는 독립된 인스턴스이기 때문에 point2.x 값을 변경해도 point1.x의 값은 변경되지 않는다.
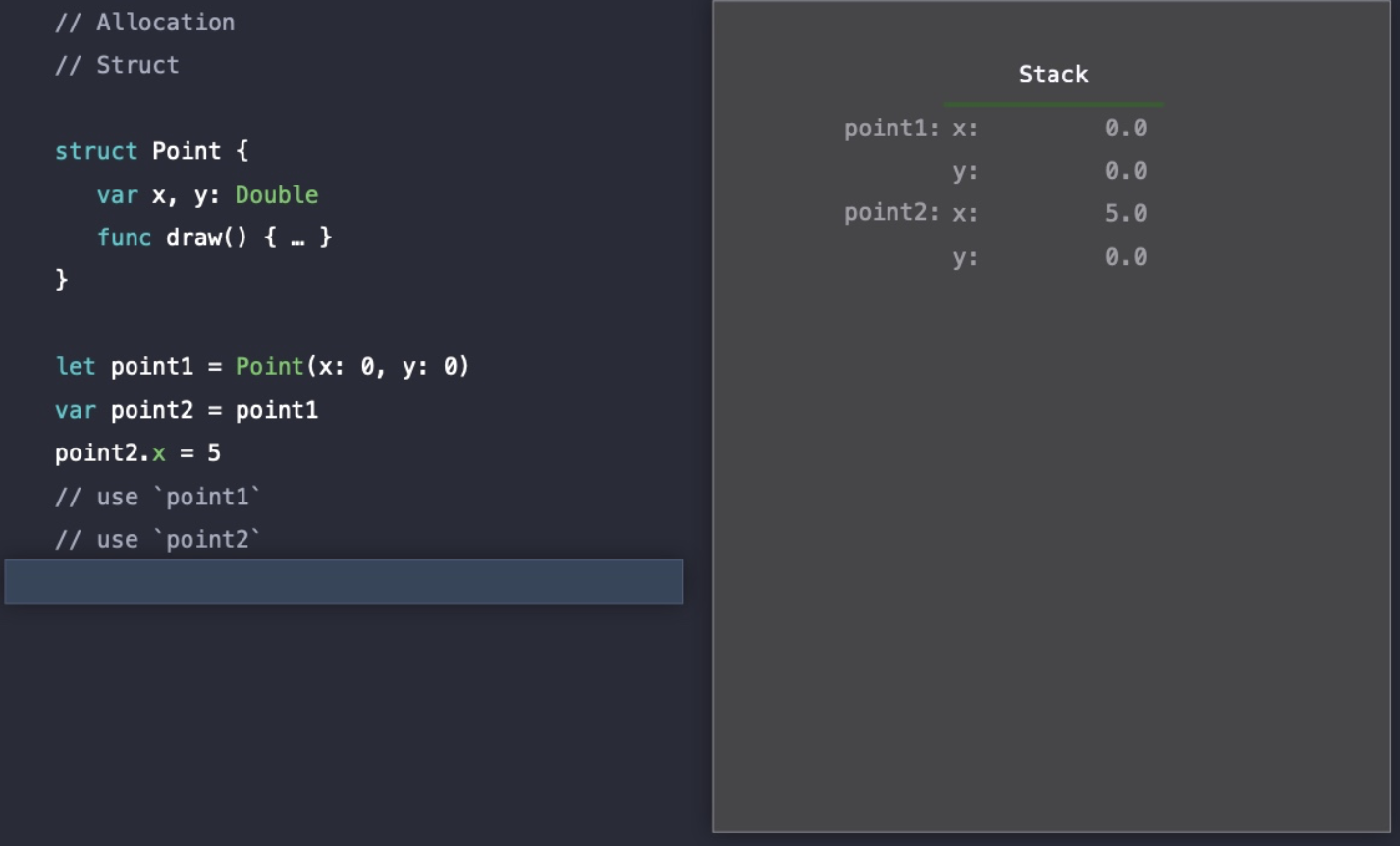
point1과 point2의 사용이 끝나면, Stack Pointer를 점차 증가시켜 메모리 할당을 해제한다.
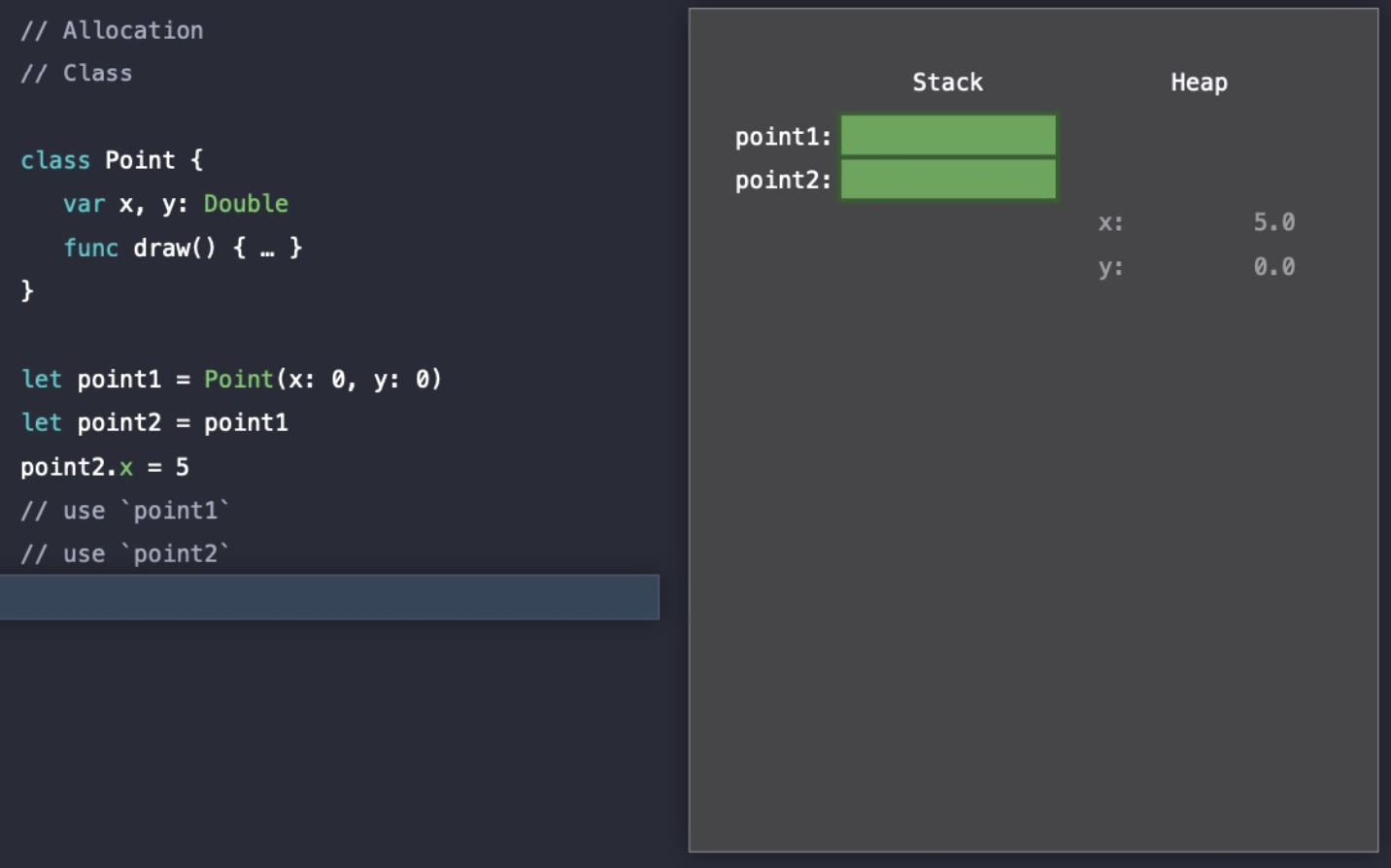
Class 타입인 경우
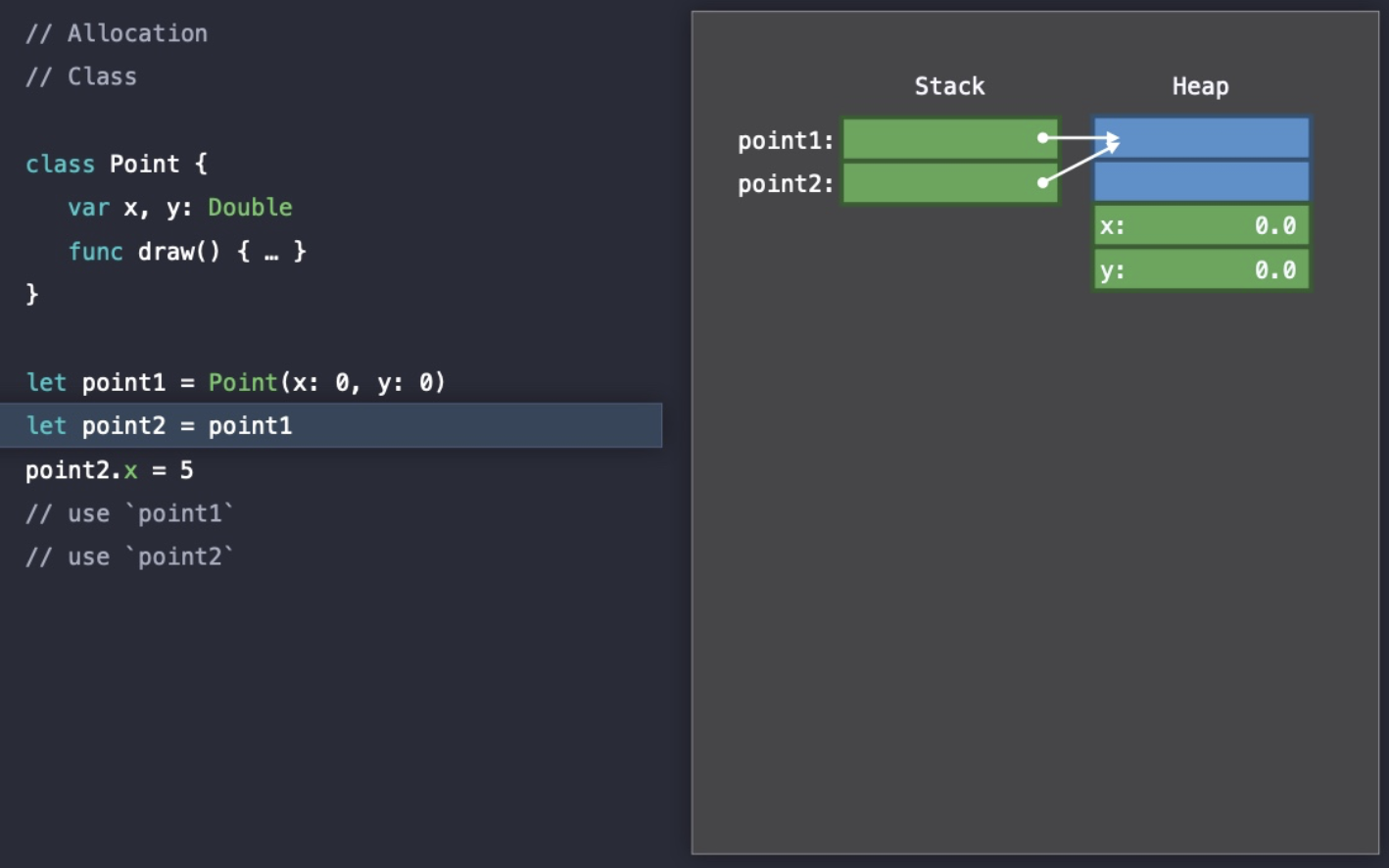
이번에도 코드가 실행되기 전부터 Stack 영역에 point1과 point2에 대한 메모리가 할당된다.
그러나 Class 타입으로 선언된 경우 Heap에 실제 데이터(프로퍼티)가 저장되고 Stack에는 해당 메모리 주소를 저장한다.
Point(x: 0, y: 0) 인스턴스를 만들 때 Swift는 데이터 무결성을 위해 Heap를 Lock하고, 해당 크기의 메모리 블록을 검색한다.
참고로 Heap 메모리 크기가 4개인 이유는, Heap에 프로퍼티 저장 공간 외에도 Swift가 우리를 대신해서 관리하기 위한 공간도 만들기 때문이다.
그리고 Class 타입이기 때문에 point2에 point1을 복사해도 메모리 주소가 복사되고, 동일한 Heap 메모리 주소를 가리키고 있다.
즉, point2.x의 값을 변경시켜주면 동일한 Heap 메모리 주소를 가리키고 있기 때문에 point1.x의 값도 같이 변경된다.
이제 point1과 point2의 사용이 끝나면 Swift는 다시 Heap을 잠그고, 사용하지 않는 블록들을 적절한 위치로 재삽입한다.


위와 같이, Class는 동적 할당/해제가 필요하기 때문에 Struct보다 생성 비용이 많이 든다.
그래서 결론은, Struct가 Class보다 Allocation 측면에서 성능이 더 우세하다!
One more...
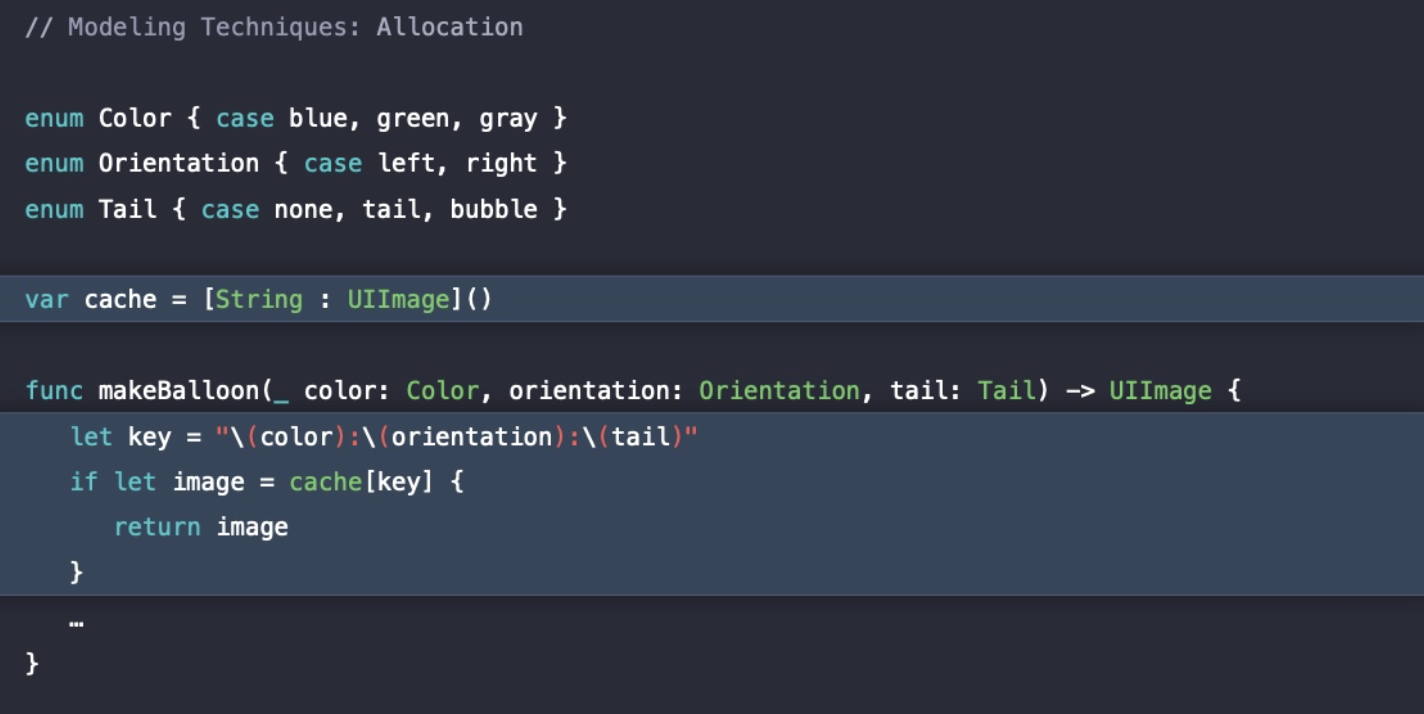
한가지 예시를 더 보자면, 해당 예시는 enum의 case에 따라 풍선을 만드는 코드다.
makeBalloon() 메서드가 스크롤로 인해 빈번하게 호출되고 있다는 가정 하에, 이미 만든 풍선을 다시 만드는 일을 방지하기 위해 Dictionary 타입의 cache를 선언했다.
cache의 Key가 String 타입으로 선언되어 있는데, String의 경우 동적 할당으로 Heap에 저장되기 때문에 Allocation 측면에서 Heap 할당을 지양하기 위해서 String의 사용을 개선해보았다.
(String이 Stack에 저장되는 경우도 있지만 해당 예시에서는 무조건 Heap에 저장된다는 가정 하에 설명한 듯 싶다..!)

Key 타입에 String 타입이 아닌 Struct 타입을 선언하였고, Struct 타입 내부 프로퍼티 또한 Enum 타입이기 때문에 위와 같이 String 사용과 메모리 할당에 대한 오버헤드를 피할 수 있다.
Reference Counting
Swift는 Heap에 저장된 인스턴스에 대한 총 Reference Count를 유지한다.
이때 Reference Count는 인스턴스 내부에 존재하는데, 참조를 추가하거나 제거함으로써 Reference Count가 증가 혹은 감소한다.
즉, Reference Count가 0이 되면 아무도 Heap에서 해당 인스턴스를 가리키고 있지 않으며 메모리에서 해제하면 안전하다는 것을 알 수 있다.
그리고 Heap 할당처럼 여러 Thread에서 동시에 참조 추가/제거할 수 있기 때문에 Thread-Safe를 보장해야 한다.
Class 타입인 경우
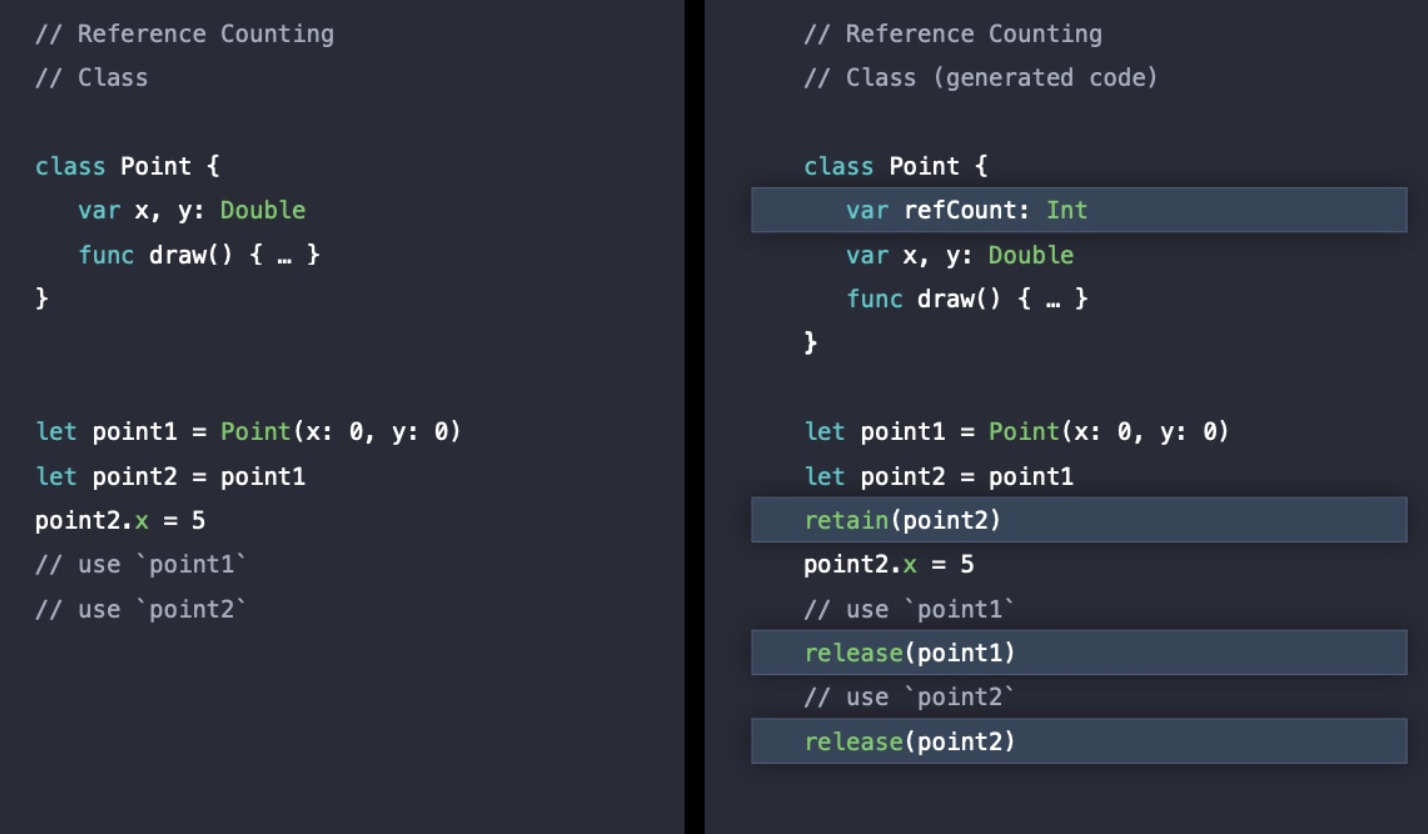
Point 객체를 Class 타입으로 정의되었기 때문에 Heap에 할당되고 참조가 발생하게 되는데, 현재 Swift는 ARC 덕분에 자동으로 Reference Count에 대해 관리할 수 있지만 ARC가 있기 이전에는 retain/release를 통해 Reference Count를 증가/감소시켜줬다고 한다.
-> 직접 작성하지 않아도 오른쪽과 같은 코드가 실행되고 있는 것!
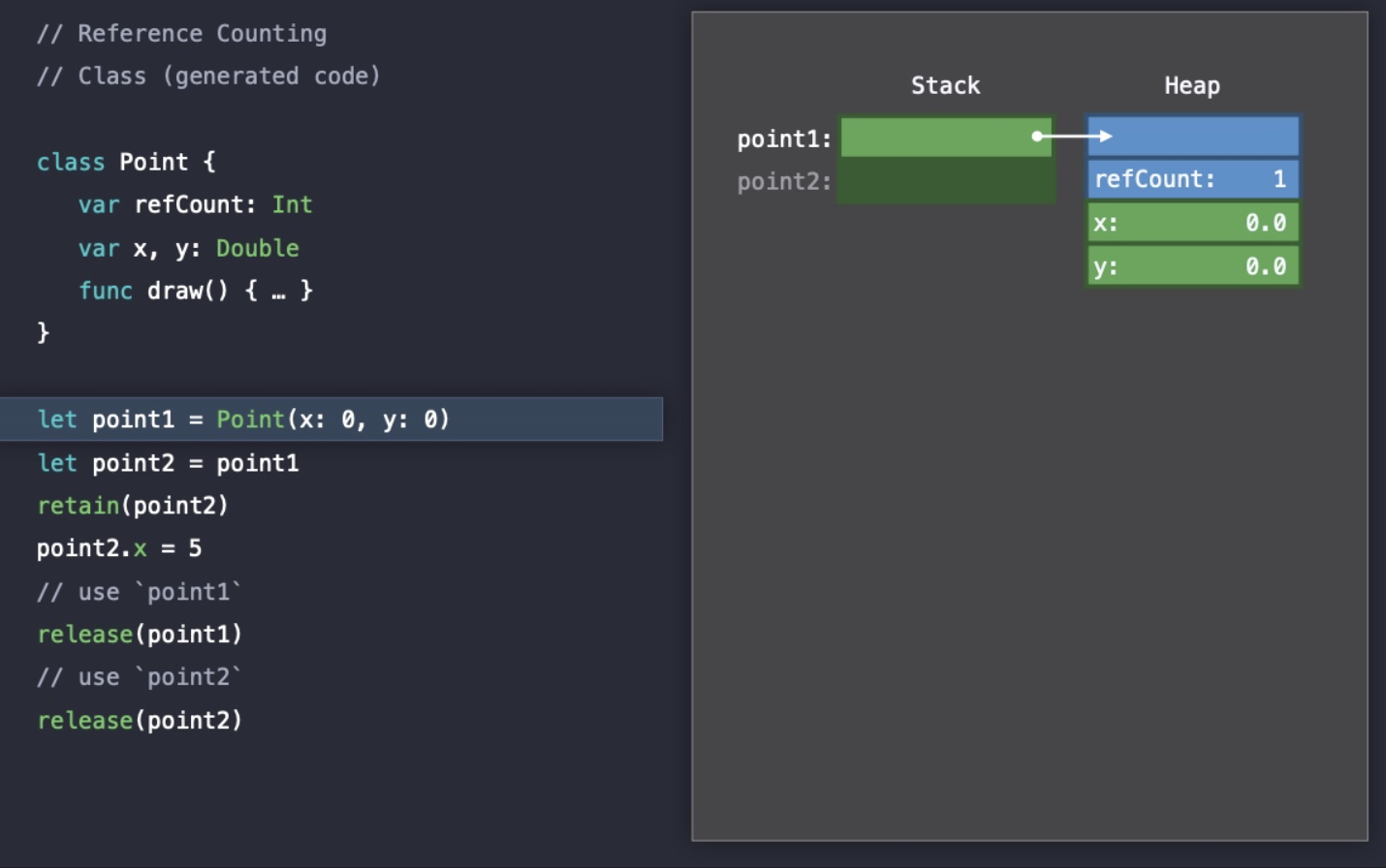
Point(x: 0, y: 0)을 통해 point1이 생성되는 순간 Heap 할당이 일어나고 참조가 발생했기 때문에 refCount가 1이 되었다.
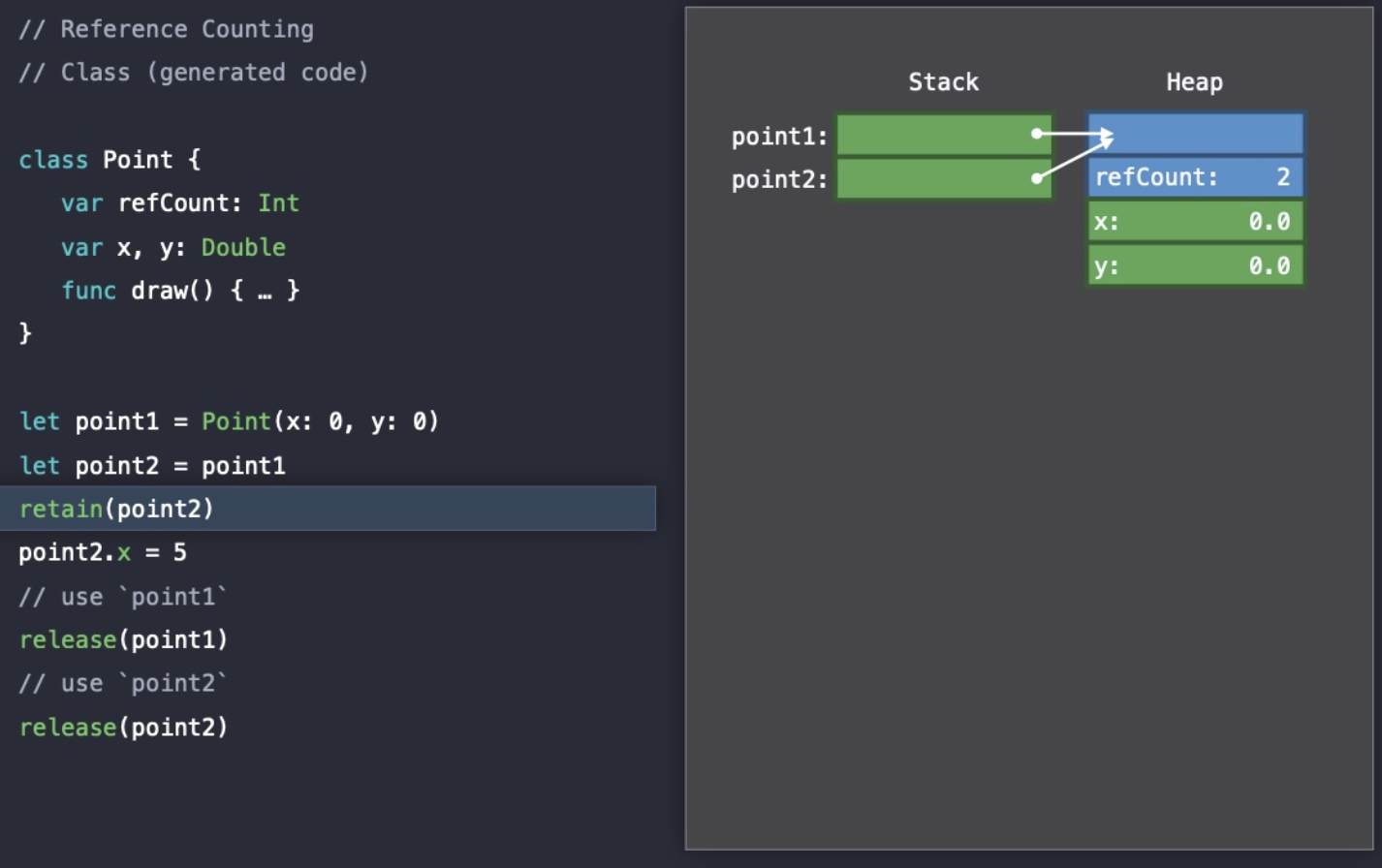
그리고 point2에 point1이 복사되었고 point2도 point1과 같은 Heap 영역을 참조하게 되었기 때문에 refCount가 2로 증가했다.
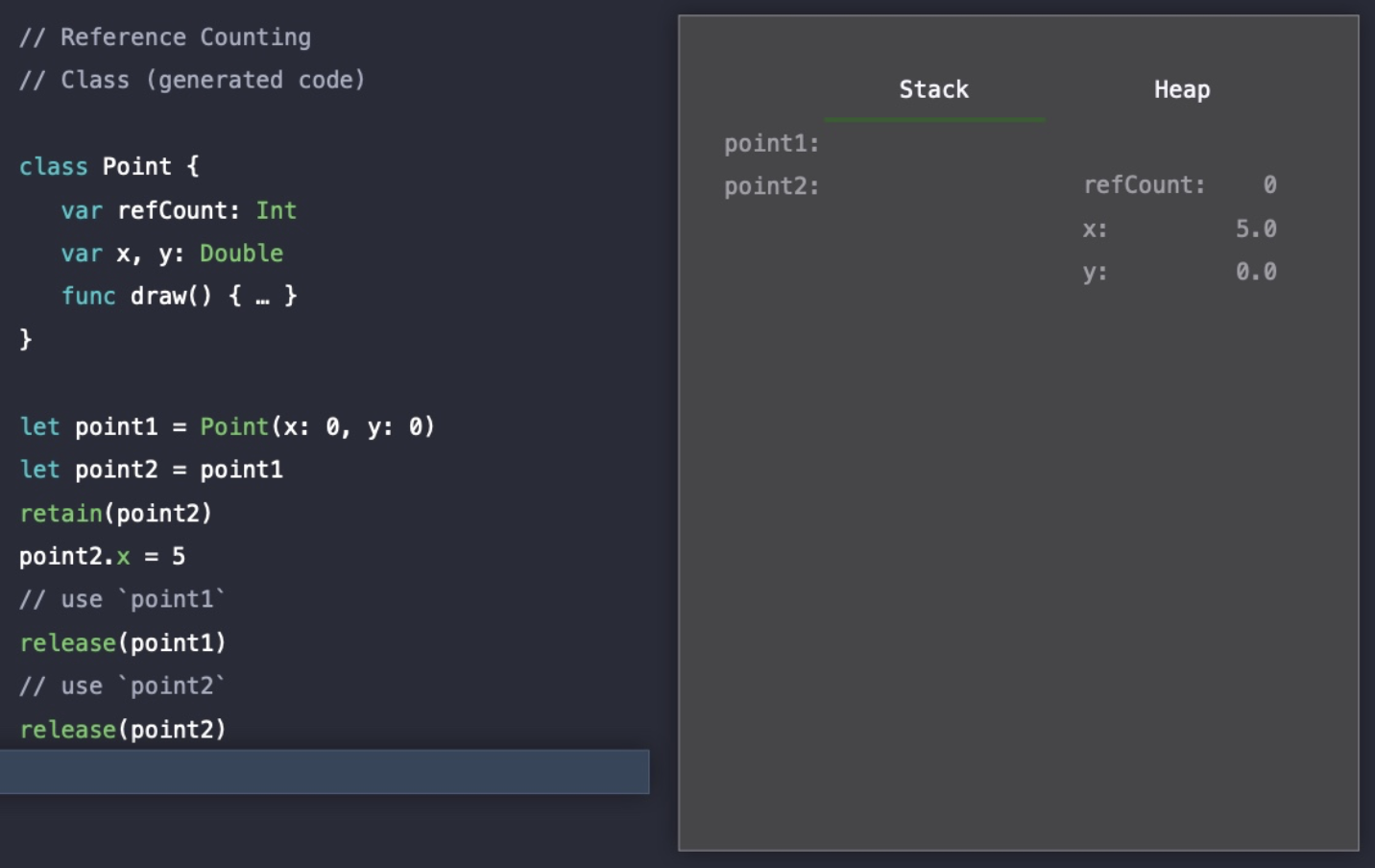
코드 실행이 끝나 point1과 point2에 대한 참조가 더 이상 없기 때문에, refCount도 0이 되었고 Stack과 Heap 할당도 모두 해제되었다.
Struct 타입인 경우
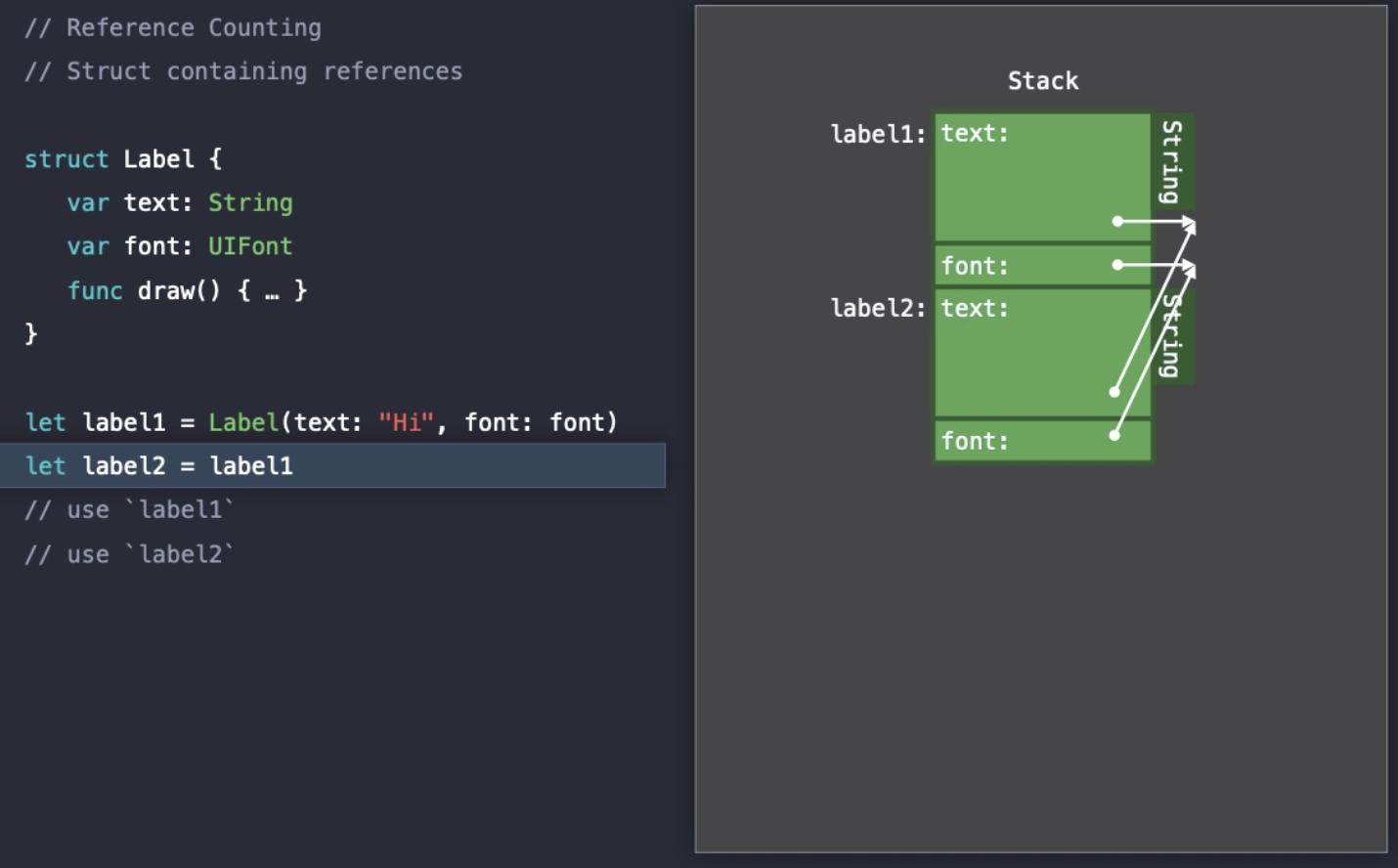
Struct 타입은 값 타입이기 때문에 label2에 label1을 복사했을 때 Stack에서도 값이 복사된다.
그러나 text와 font Heap에 할당되기 때문에 두 값은 같은 Heap 영역을 참조하게 된다.
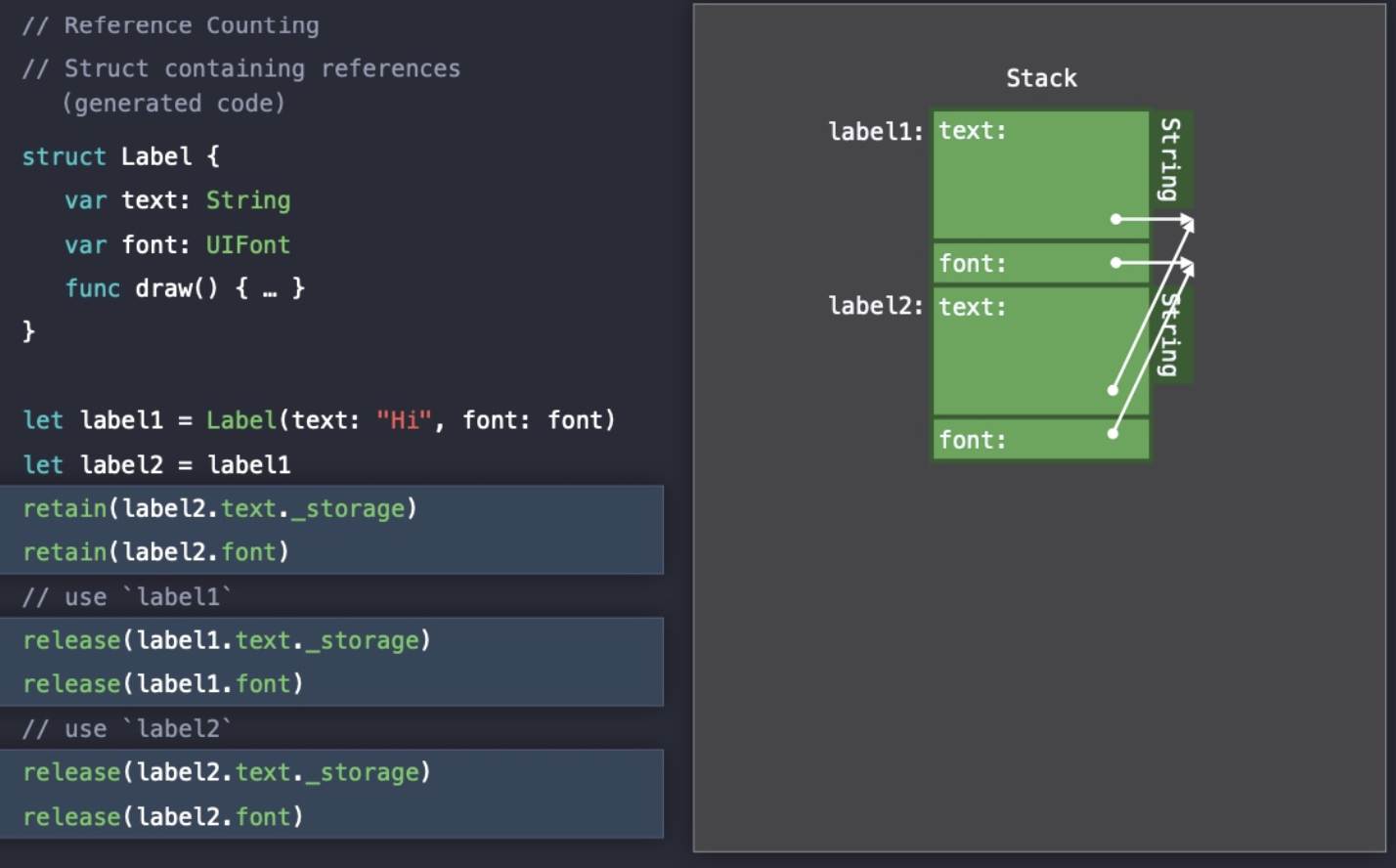
Struct 타입 내 Class 타입이 존재한다면, Stack 영역 내에서 값이 복사될 때 Reference Count도 같이 증가한다.
참조 해제 역시, 프로퍼티가 모두 Class 타입이기 때문에 release를 두번씩 해줘야 한다...😅
-
Class Type
-
Struct Type

-
Struct containing many referenes

이렇게 Struct 내에 참조 타입 혹은 Heap 영역에 저장될 값이 존재하는 경우 값을 복사할 때마다 매번 프로퍼티의 reference count가 증가/감소되기 때문에, Heap 영역에 저장될 프로퍼티가 둘 이상 존재하는 경우 Class 타입보다 레퍼런스 카운팅 오버헤드가 많아져 성능이 떨어질 것이다.
one more...
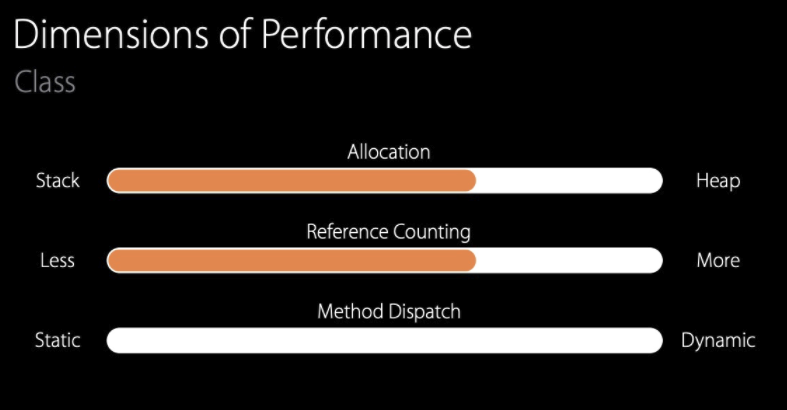
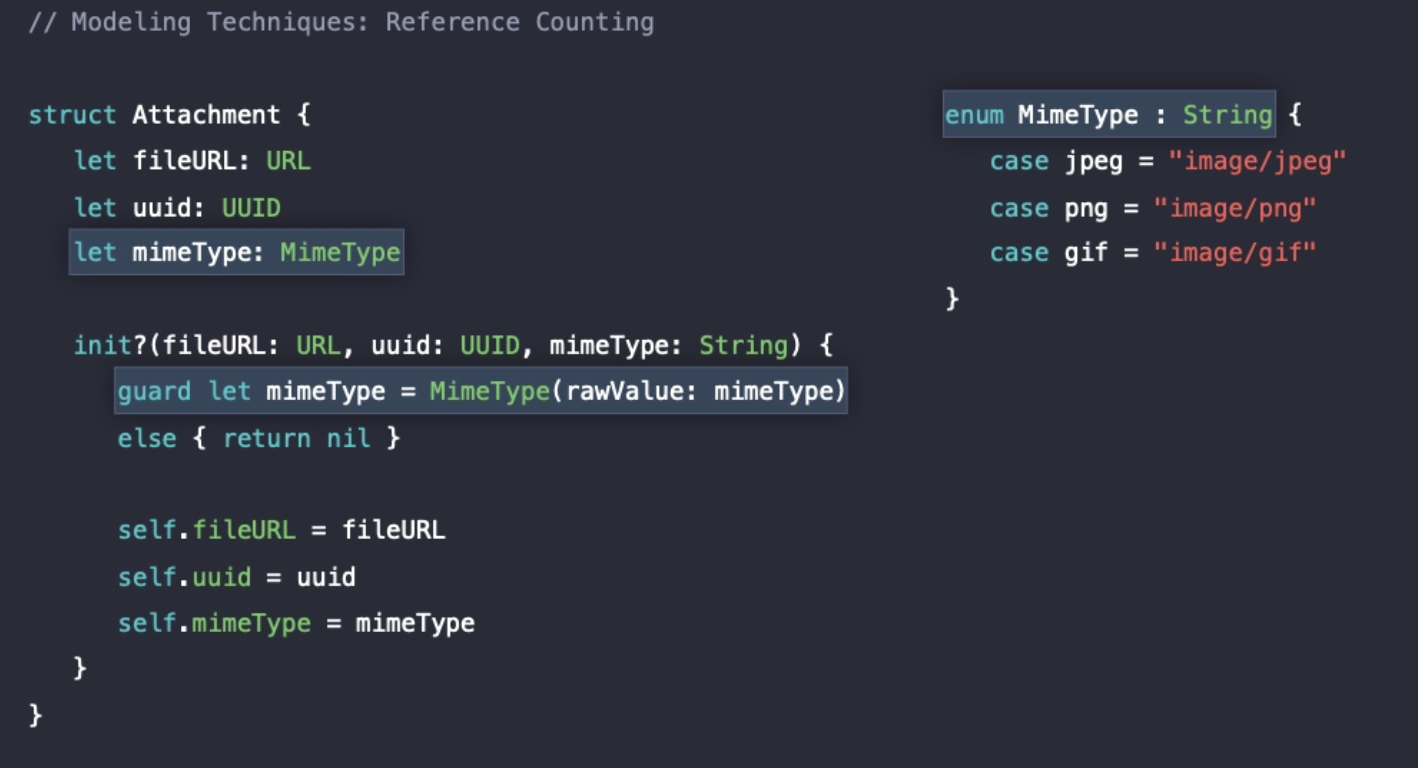
Attachment 내 프로퍼티에 String 타입이 존재하고 해당 프로퍼티가 Heap에 저장될 수 있으며, URL 타입 또한 init시 String 타입을 받기 때문에 모든 contents가 Heap에 저장될 수 있다.
결국, Attachment 내에 둘 이상의 reference가 존재하는 것이기 때문에 레퍼런스 카운팅 오버헤드를 개선해야 한다.
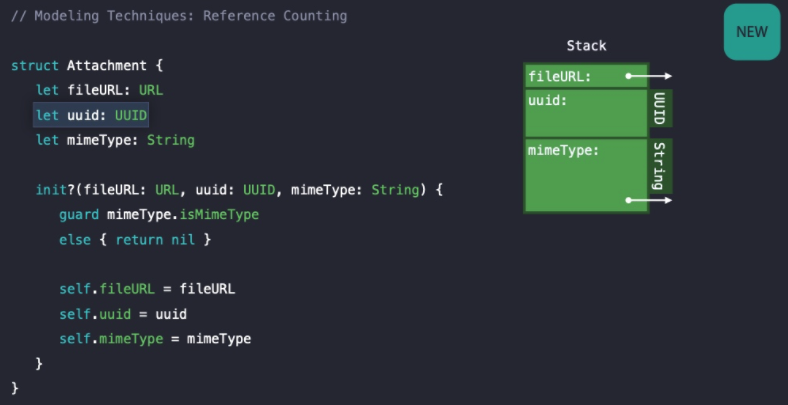
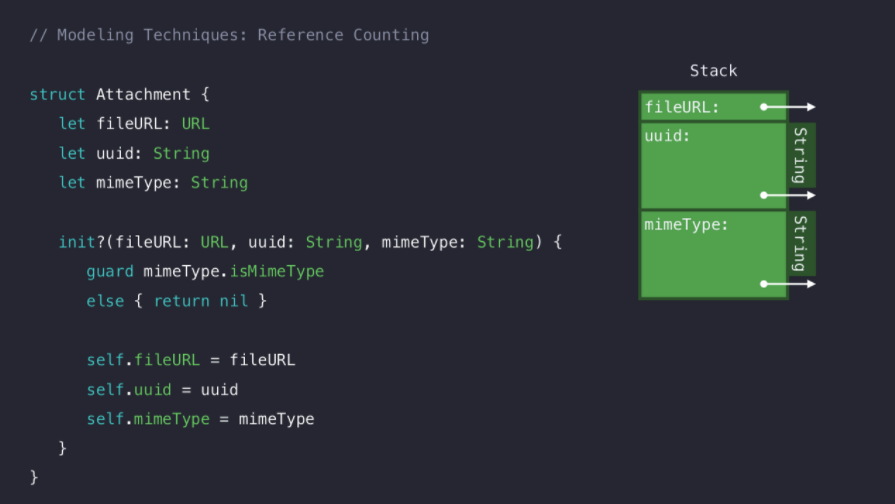
uuid와 같은 식별자 역할의 프로퍼티가 String 타입인 경우 안전하지 않고 String 타입이기 때문에 Heap 할당이 필요하다.
이러한 이슈를 해결하기 위해 UUID 타입으로 개선되었다👍
UUID 타입은 Struct 타입으로 36개의 문자로 이루어져 있어 고정된 길이를 갖는 String이고, 128 비트 식별자를 모두 Stack에 저장하기 때문에 Heap 할당이 필요없다.
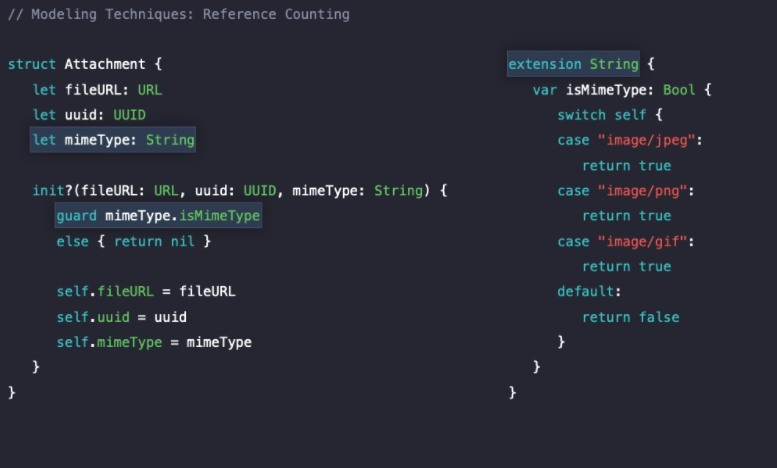
그리고 초기화 코드를 보면 mimeType 값이 지원하지 않는 타입의 값일 경우 초기화시 nil을 반환하는데, String 확장을 통해 정의한 isMimetype 값을 통해 String 값에 따라 일일이 Bool 값을 반환하고 있다.
String 타입은 Heap에 저장되기 때문에 개선해 볼 필요가 있다.
이렇게 String으로 선언되었던 mimeType이 Enum 타입으로 개선되었다👍
Method Dispatch
참조
https://zeddios.tistory.com/596
https://zeddios.tistory.com/1331
https://leechamin.tistory.com/557#----%--Stack
