Lexical Analysis: 어휘분석
예를 들어 다음과 같은 코드가 컴퓨터에 들어온다고 하자.
if(i == j)
Z = 0;
else
Z = 1;컴퓨터는 이 코드를 다음과 같이 받는다.
\tif(i==j)\n\t\tz=0;\n\telse\n\t\tz=1; (\t, \n 등을 White space라고 함)
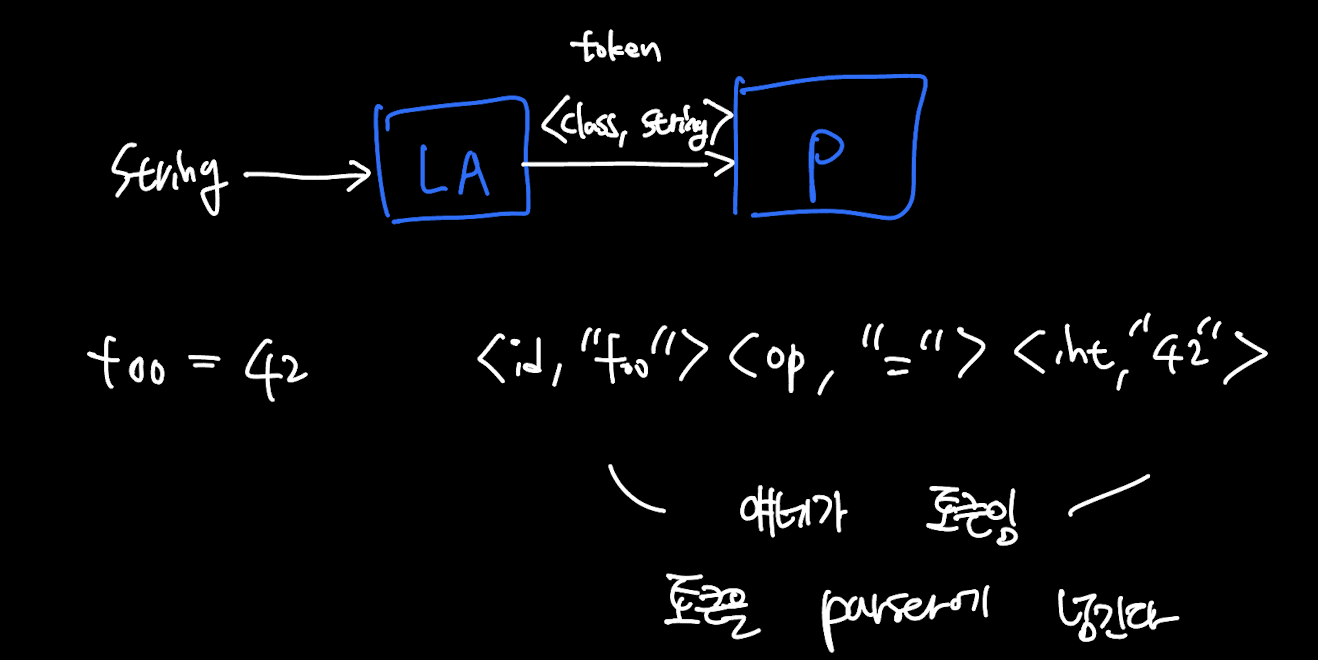
이제 "Token"을 식별해야 하는데 토큰이란 programming laguage에서
ex: identifier, keywords, '(',')', numbers, ... 등
- Token: set of strings
- Identifier: strings of letters or digits, starting with a letter
- Integer: a non-empty string of digits
- Keyword: "else" or "if" or "begin" or ...
- Whitespace: a non-empty sequence of blanks, newlines, and tabs
Lexical Analysis는 어떤 substrings를 합당한 role로 구분하는 것
-> 분류하는 과정 이라고 할 수 있겠다.
\tif(i==j)\n\t\tz=0;\n\telse\n\t\tz=1;
이 코드를 다시 보자.
여기서 Lexical Analysis는 입력을 읽고 이게 어떤 "token"인지, 이 "token"은 어떻게 구성되어 있는지 이런 분류를 한다.
결국 Lexical Analysis의 목적
-
Partition the input string into lexemes
-
Identify the token of each lexeme
++ Left-to-right scan => lookahead sometimes required
정규언어(Regular Languages)
-
Single character
'c' = {"c"} 등 -
Epsilon
ε은 어떤 문자도 포함하지 않는 문자열.
ex: A = {"A"} 일 때, A+ε = {"A", ""} -
Union
A = {"A"}, B = {"B"}
A+B = {"A", "B"} : A또는 B -
Concatenation
A = { "a", "b" }, B = { "c", "d" } 라면
AB = { "ac", "ad", "bc", "bd" }
즉, AB는 "A의 문자열을 먼저 읽고 이어서 B를 읽는다"는 뜻 -
Iteration
반복
(0+1)* : 0 또는 1로 이루어진 문자열이 0번 이상 반복된다"는 의미
** 빈 문자열도 허용Lexical Specification
-
Keyword: "if", "else", "then" or ... 등
-
Integer: a non-empty string of digits
digit = '0'+'1'+'2'+'3'+ ... +'9'
정수 -> digit digit* (0~9다음 0~9 반복하고 또 반복)
-
Identifier: string of letters or digits, starting with a letter
- letter: 'a'+'b'+'c'+...+z+'A'+'B"+...+'Z' = [a-zA-Z]
- identifier = letter(letter+digit)*
- whitespace = a non-empty sequence of blanks, newlines, and tabs = (''+'\n'+'\t')(''+'\n'+'\t')*
