
문자열 매칭
텍스트 문자열이 패턴 문자열을 포함하고 있는지 알아보는 것
1. 원시적인 비교
원시적인 비교는 일일히 하나씩 일치하는 지 비교하는 것이다.
실행시간이 오래 걸리며 비효율적이다.
2. 수치화 알고리즘
문자열 패턴을 수치로 바꿔서 수치를 비교해서 문자를 찾는 알고리즘이다.
문자 수에 대응하는 N진법을 사용한다.
예를 들어 a~e까지만 있는 문자열일 경우 사용하는 문자의 수는 5개 따라서 5진법을 사용한다.
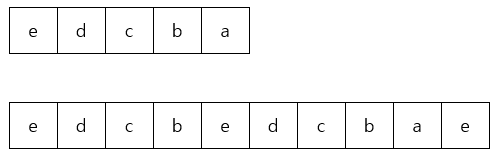
(1) 만약 위의 경우에 해당하는 edcba를 찾는다고 할 때
찾고자하는 문자열을 먼저 계산해서 결과값을 찾는다.
SUM=5⁴*4+5³*3+5²*2+5¹*1+5⁰ *0
(2) 전체 문자열에서도 문자열의 길이만큼 계산한다.
A₀의 값은5⁴*4+5³*3+5²*2+5¹*1+5⁰ *4
(3) 두 문자열의 값이 다르다면 다음칸으로 넘어간다.

(4) 새로운 칸의 값을 계산해야하는 데 이 경우에는 원시적 비교와 다를 바가 없다.
- 이전단계의 합에서 첫번째 문자의 값을 뺀 값을 사용한 N진법에 맞게 N배 해주고 마지막 문자의 값을 더해주면 일일히 계산할 필요 없이 빠르게 합을 구할 수 있다.
위의 경우
A₀의 값에서 e에 해당하는 5⁴*4를 빼준 나머지 합을 5배 해준다.
그 후 새롭게 추가된 d에 해당하는 값 1*3을 더해준다.
=> A₁= 5(A₀-5⁴*4)+3 이 된다.
뒤의 문자열들의 합은 앞의 문자열들의 합을 통해 쉽게 구할 수 있는 것이다.
3. 라빈-카프 알고리즘
수치화 알고리즘은 찾고자하는 문자열이 너무 길거나 찾아야하는 문자가 많을 경우 용량 문제가 발생할 수 있다.
라빈-카프 알고리즘은 수치화 알고리즘의 골격을 사용하면서 이 문제를 모듈러 연산(mod)를 통해 해결한 알고리즘이다.
소수 q를 이용해서 모듈러 연산을 실행한다.
이때 선택되는 소수 q는 사용하는 N진법에 따라 달라지게 된다.
N*q가 레지스터가 감당할 수 있는 수준을 만족하는 적당히 큰 소수를 선택해야한다.
(A+B) % p = ((A%p)+B%p)) %p의 모듈러 법칙이 성립되기 때문에 계속 중복해서 계산되는 부분에 적용해준다.
4. 오토마타를 이용한 매칭
여러 개의 상태로 표현되는 오토마타를 이용한 매칭
오토마타의 구성
Q : 상태 집합, N번째 문자까지 찾은 상태를 표현
q0 : 오토마타의 작동이 시작되는 상태
F : 목표 상태가 달성된 상태들의 집합
∑ : 입력 가능한 문자들의 집합
δ : 상태 전이 함수
예를 들어 a~z로 이루어진 문서에서 문자열 ababaca를 찾는 과정은 상태 전이 함수로 표현된다.
상태 전이 함수δ는 다음과 같은 테이블로 정의된다.
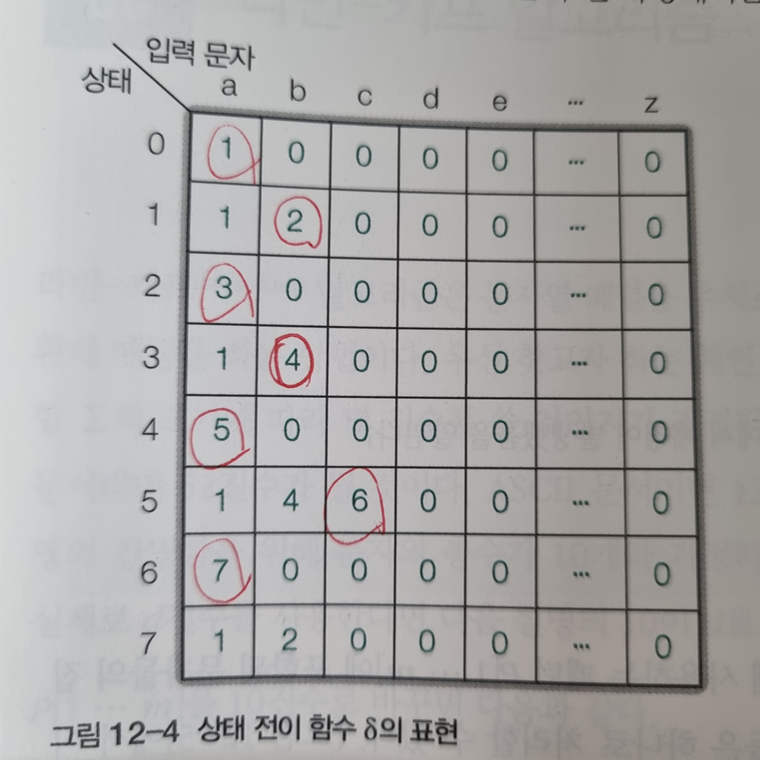
각 상태는 맞는 문자를 찾은 단계를 뜻한다.
상태가 0이면 일치하는 부분을 찾지 못했다는 것이고
상태가 1이면 일치하는 부분을 찾았다는 뜻이다.
상태와 입력문자가 만나는 부분은 현재 상태에서 해당 입력 문자가 들어올 시 어떤 상태로 이동하는 지를 표현한 것이다.
0인 상태에서 a가 들어오면 찾고자하는 문자열 ababaca 중 첫 문자를 찾은 것이기 때문에 1개를 찾은 1로 상태가 변화한다.
이런 방법을 통해 해당 상태에 어떤 문자가 들어오면 어떤 상태로 전이되는 지 테이블을 만들어 이용하는 방법이다.
단, 오토마타 매칭에선 상태 전이 함수를 만드는 전처리 과정이 필요하다.
5. KMP 알고리즘
오토마타 매칭과 같은 동기에서 출발했지만 전처리 비용을 줄인 알고리즘이다.
접두사와 접미사
접두사 : 앞에 있는 문자열
접미사 : 뒤에 있는 문자열
KMP에서는 접두사가 접미사의 최대 일치를 기록해서 일차원 배열에 저장해둔다.
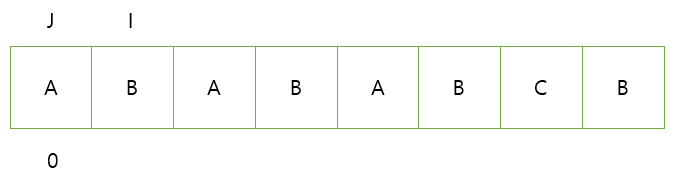
다음과 같은 상황에서 시작해서 J와 I의 문자를 비교한다.
비교 후에 할 행동은 다음과 같다.
J,I의 문자가 동일하다 - J, I를 앞으로 이동 J인덱스를 입력한다.
J,I의 문자가 동일하지 않다 - J를 뒤로 이동 시킨다.
J가 더 이상 뒤로 갈 수 없다면 J의 인덱스를 입력한다. 그 다음 I 값 증가다.
1. J, I의 문자가 다르다.
=> J는 뒤로 이동시킬 수 없다. J 인덱스를 입력하고 I를 증가 시킨다.
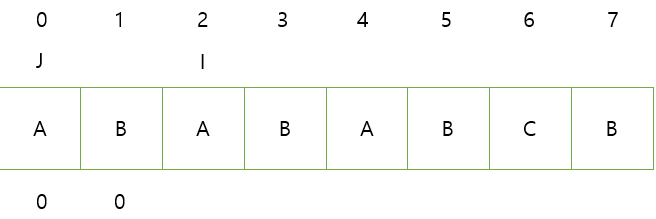
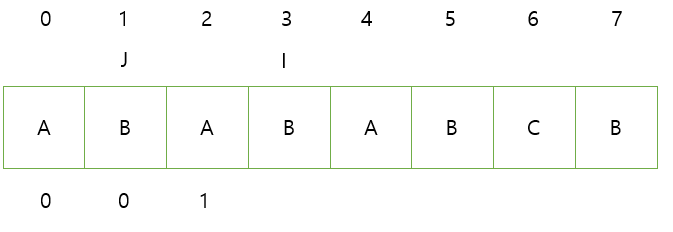
2. J,I의 문자가 동일하다
=> J,I를 증가시키고 J의 인덱스를 입력한다.
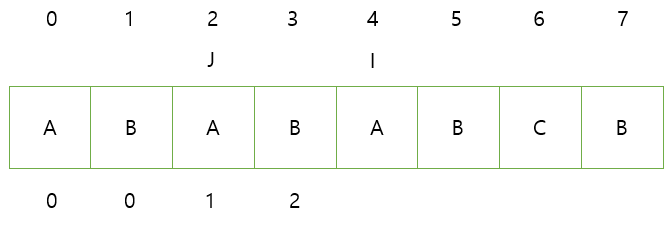
3. J,I의 문자가 동일하다
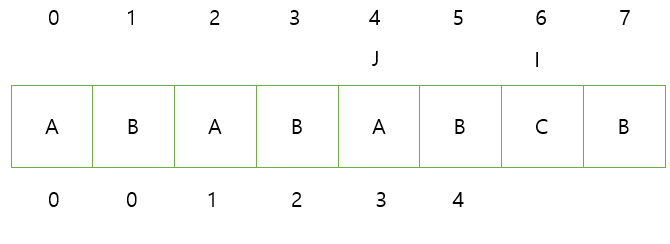
4. 이를 반복한다.
이 과정에서는 C와 같은 문자가 없기 때문에 J가 처음까지 이동하게 된다.
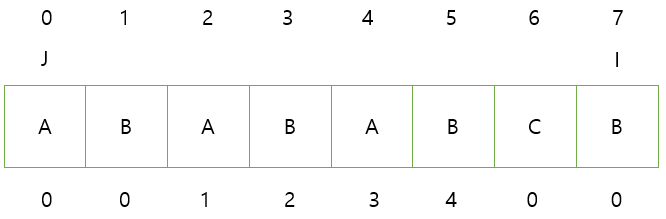
완성된 배열
KMP 알고리즘
위에서 완성된 배열을 이용해서 접두사와 접미사가 같은 부분을 이동한다.
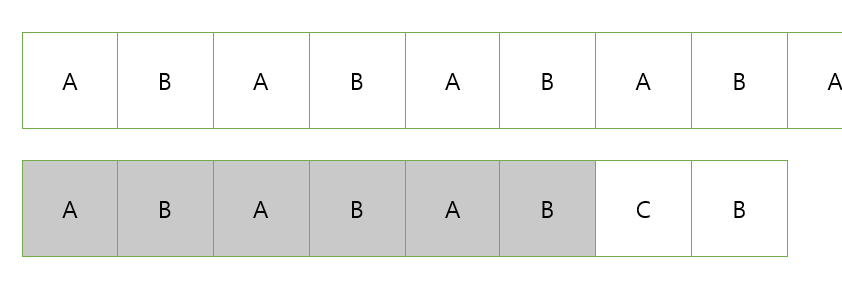
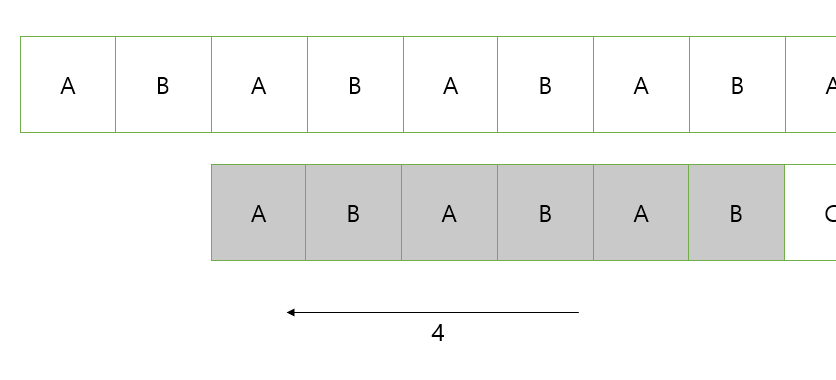
다음과 같은 상황에서 불일치가 일어났다면 6번째의 인덱스를 확인한다.
6번째까지 일치했고 해당 인덱스는 4기 때문에 뒤에서 4개만큼 겹치게 비교 문자열을 옮긴다.
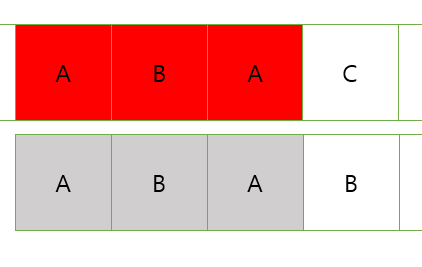
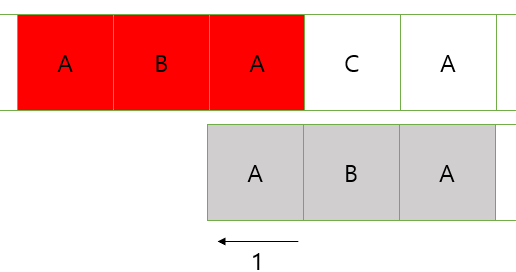
다음 상황에서는 3번째까지 일치했고 해당 인덱스는 1이기 때문에 1개만큼 겹치게 옮긴다.
6. 보이어-무어 알고리즘
보이어-무어 알고리즘을 앞에서 비교하던 위의 알고리즘과 달리 뒤에서 부터 문자열을 비교한다.
뒤에서 부터 비교를 했는데 찾고자하는 패턴 문자열에 포함되지 않은 문자가 발견 됐을 경우 그 문자의 뒤로 점프한다.
포함된 문자가 있다면 패턴과 찾고자하는 문자열의 위치를 맞춰준다.
