📚 프로세스와 쓰레드, 병렬 처리
프로세스
- 프로세스는 간단하게 말하면 CPU에서 자원을 할당받아 실제로 실행 중인 프로그램이다.
- 따라서 각 프로세스마다 CPU 자원을 각자 할당받고 사용한다.
쓰레드
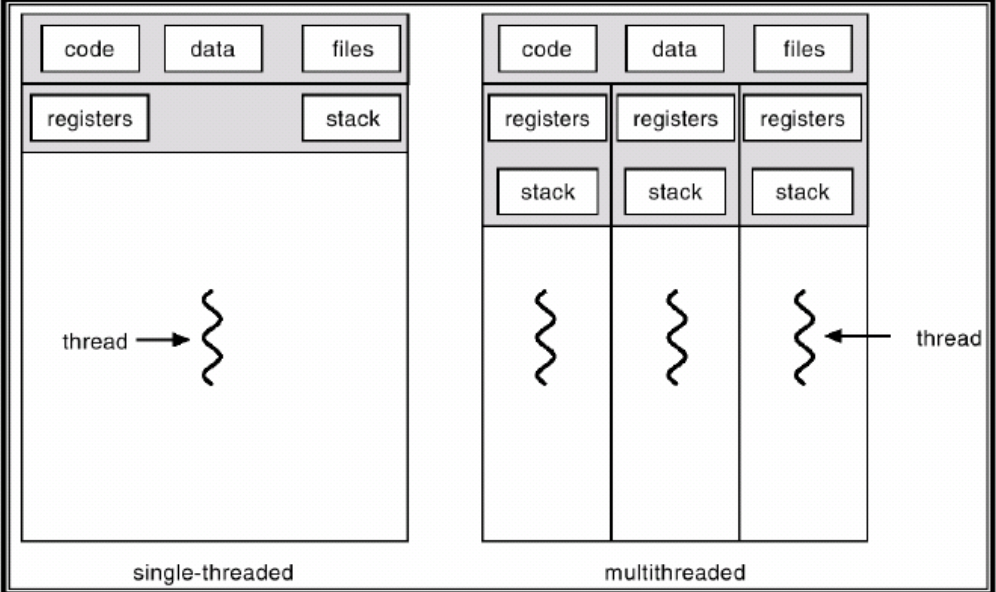
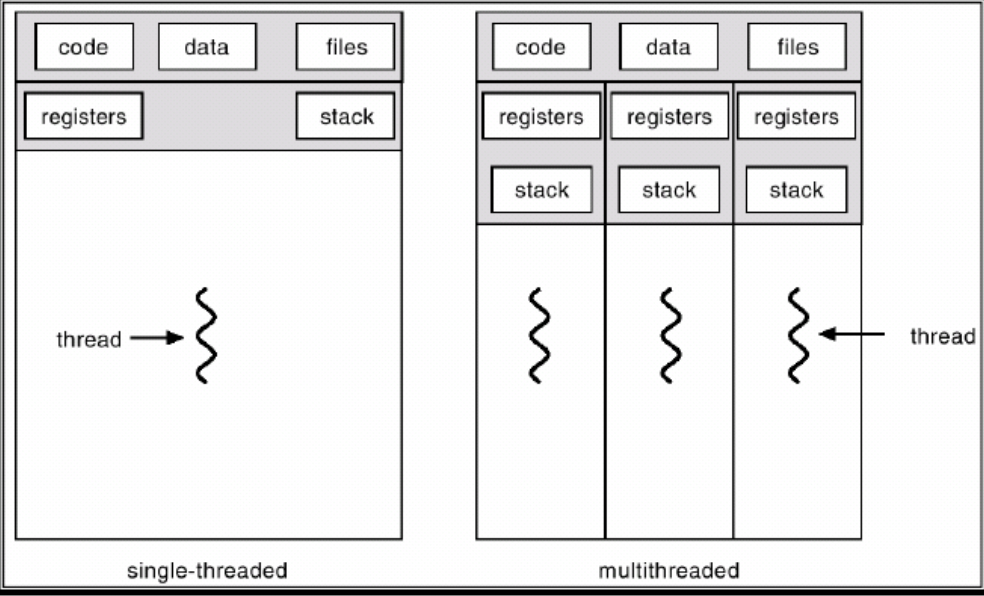
- 쓰레드(Thread) 는 프로세스 안에서 실제로 작업을 처리하는 흐름이다.
- 하나의 프로세스에는 최소 하나의 쓰레드가 있고, 프로그래밍 환경에 따라 두개 이상도 가질 수 있는데 이를 멀티쓰레드 프로세스 라고 한다.
- 프로세스 하위에 속하므로 프로세스의 자원을 각 쓰레드가 나눠가진다. 프로세스보다는 가볍다? 라고 볼 수 있을 것 같다.
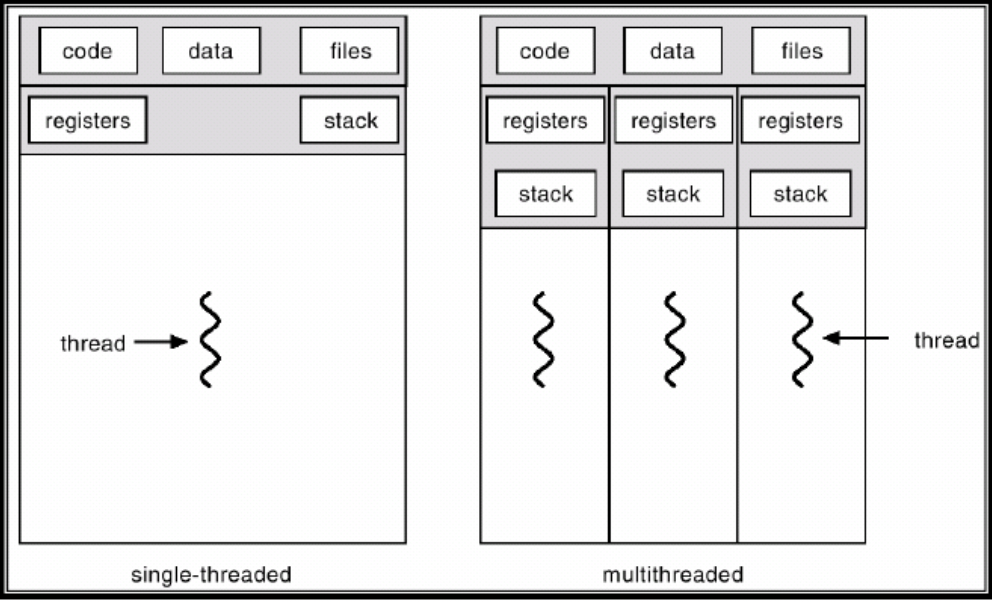
프로세스 안의 쓰레드, 그리고 멀티쓰레드를 잘 나타낸 사진.
병렬 처리
- 그럼 프로세스나 쓰레드를 여러 개 동시에 굴러가게 한다면 우리가 원하는 일을 더 빠르게 처리할 수 있지 않을까?
- 이를 병렬 처리라고 한다.
📚 Multi-Threading
파이썬에서는 threading 패키지의 Thread 클래스를 통해 멀티쓰레딩을 구현할 수 있다.
from threading import Thread
def func(rep):
j = 0
for i in range(rep):
j += i
import time
if __name__ == '__main__':
rep = 1000000
start = time.time()
t1 = Thread(target=func, args=(rep,))
# Start Thread
t1.start()
# main thread should Wait until t1 is done
t1.join()
end = time.time()
print("with one thread, elapsed time : {}".format(end - start))

단위가 초는 아니지만, 약 0.048 정도의 시간이 걸린 것을 볼 수 있다.
그럼 이제 두 개의 프로세스를 만들어서 실행시키면 결과가 더 빨리 나오겠지?!
from threading import Thread
def func(rep):
j = 0
for i in range(rep):
j += i
import time
if __name__ == '__main__':
rep = 1000000
start = time.time()
t1 = Thread(target=func, args=(rep,))
t2 = Thread(target=func, args=(rep,))
t1.start()
t2.start()
t1.join()
t2.join()
end = time.time()
print("with two thread, elapsed time : {}".format(end - start))🚨 if __name__ == '__main__' 이 필요한 이유는 윈도우즈의 쓰레드&프로세싱 방식과 연관이 있다고 한다. 쓰레드나 프로세스가 무한으로 호출될 가능성을 차단해주는 것.

이게 웬걸, 정직하게 시간이 두배 가까이 늘어났다. 이게 무슨 일일까?
🔒 GIL (Global Interpreter Lock)
-
언어에서는 컴퓨터 자원을 보호하기 위한 룰이 있다.
-
그 중 파이썬은 CPU 자원을 한 번에 한 쓰레드만 사용할 수 있게 락을 걸어두었다.
-
따라서 CPU 자원을 나눠가져 연산하는 행위가 소용이 없는 것.
-
그렇지만 파이썬의 GIL은 CPU 자원에 대해서만이고, I/O에 대해서는 상관 없으니 System IO가 많은 케이스에는 멀티쓰레딩이 효과적일 수 있다.
join() method
위에서 join 함수를 쓴 것을 볼 수 있는데, 뒤에 멀티프로세싱에도 나오겠지만 얘를 써줘야 main Thread가 우리가 만든 쓰레드가 끝날 때까지 기다린다.
예를 들어 join을 쓰지 말아보자.
from threading import Thread
def func(rep):
j = 0
for i in range(rep):
j += i
print("job done.")
import time
if __name__ == '__main__':
rep = 1000000
start = time.time()
t1 = Thread(target=func, args=(rep,))
t1.start()
# t1.join()
end = time.time()
print("with two thread, elapsed time : {}".format(end - start))

이렇게 main 쓰레드의 시간 출력이 먼저 나오고, 그 후에 쓰레드에 넘겨준 함수가 실행되는 것을 볼 수 있다.
대부분의 상황에서는 메인 쓰레드가 주축이 될테니 join()을 써주는 게 맞을 것 같다.
📚 Multi-Processing
그렇다면 멀티 프로세싱으로는 어떨까? 파이썬에도 프로세싱에 대한 룰은 없는 것 같고, 프로세스는 각자 고유의 자원을 사용하니 우리가 원하는 병렬처리가 가능할 것 같다.
사용 가능한 CPU 수 확인하기
import multiprocessing as mp
print(mp.cpu_count())

현재 내 컴퓨터에서 사용 가능한 CPU는 8개라고 한다.
병렬 처리를 통해 이론상으로는 기존의 8배 속도로 일을 처리할 수 있겠지만, 현실적으로는 그렇지 않다.
프로세스는 각각 독립이기 때문에 서로서로 데이터를 공유해야 하는데, (이 때 쓰이는 것을 IPC, Inter Process Communication이라 한다) 데이터량이 많으면 이 시간이 길어지기 때문.
번외로 동시에 일을 처리하기 때문에 데이터 오염 확률도 높다고 한다. 이를 위해서 Lock이나 세마포어를 잘 걸어야 한다.
실행
import multiprocessing as mp
# counting available cpu
# print(mp.cpu_count())
def f(n, rep):
j = 0
for i in range(rep):
j += i
import time
def main():
# set_start_method function creates fresh interpreter process, also calls the handler for resource handling after the process
rep = 10
mp.set_start_method('spawn')
start = time.time()
print("start process")
p1 = mp.Process(target=f, args=(1,rep))
p2 = mp.Process(target=f, args=(2,rep))
p1.start()
p2.start()
p1.join()
p2.join()
end = time.time()
print("time : {}".format(end-start))
pr = end-start
start = time.time()
print("start normal")
f(3, rep)
f(4, rep)
end = time.time()
print("time : {}".format(end-start))
npr = end-start
print('process time - normal time : {}'.format(pr - npr))
if __name__=='__main__':
main()
파이썬을 통한 멀티 프로세싱에는 Pool()을 통한 방법도 있지만, 그 경우에는 함수의 파라미터를 하나밖에 줄 수 없다고 하여 각각의 Process 객체를 이용하는 방법을 선택했다.
이렇게 실행해보면 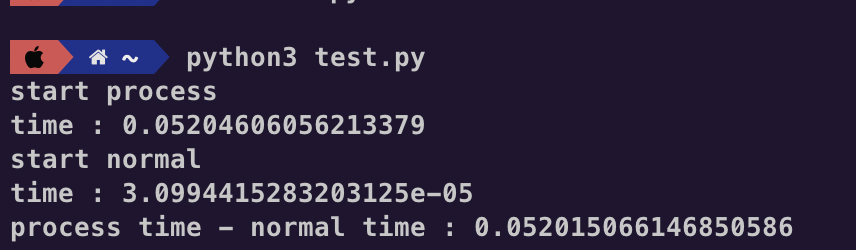
이런 결과가 나온다.
아니 멀티프로세싱 시간 - 일반 함수 시간을 뺐는데 양수면 멀티프로세싱이 더 오래 걸렸다는 말인데?
그래서 rep = 1000000 으로 반복 횟수를 더 늘리고 실험해보았다.
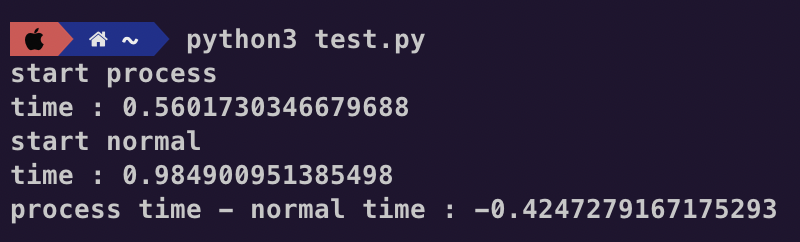
그랬더니 음수가 나오는 것을 확인할 수 있었다.
Multi-Processing 결론
그래서 왜 간단한 케이스에는 멀티 프로세싱이 더 오래 걸릴까 조금 생각하고 검색도 해봤다.
내가 내린 결론은 다음과 같다.
- 파이썬에서 프로세스를 키는 데 시간이 더 오래 걸린다.
- 본 케이스의 경우는 프로세스 간 데이터 전송이 없어 괜찮지만, 있었으면 더 오래 걸렸을 것이다.
따라서 처리할 연산이 엄청나게 많다면 멀티 프로세싱이 좋은 선택이겠지만, 간단한 연산이거나 프로세스끼리 대량의 데이터를 주고받아야 하는 경우에는 오히려 느릴 수도 있다는 결론을 내렸다.
참고
