Vocabulary
컴퓨터는 어떻게 우리가 보는 세상의 데이터를 숫자를 통해 인지한다.
그리고 컴퓨터는 vector를 통해 단어를 숫자로 표현한다.
컴퓨터의 단어들을 vector로 표현하기 위해서는 단어장(vocabulary)를 만들어야 한다.
단순하게 단어장이라고 하면,
vocab = [data, AI, book, Algorithms]이런 형식의 단어장을 만들 수 있다.
이런 단어장에 idx 번호가 붙여지는 것이고, 이런 idx 번호를 가지고 vector로서 단어를 표현할 수 있는 것이다.
One-hot vector
one-hot vector를 설명하기 전에, column vector에 대해 알아야할 필요성이 있다.
- column vector는 Nx1 matrix로 숫자 N개를 기둥처럼 세워둔 것이다.
위에서 본 idx를 어떻게 column vector로 표현할 수 있을까 ?
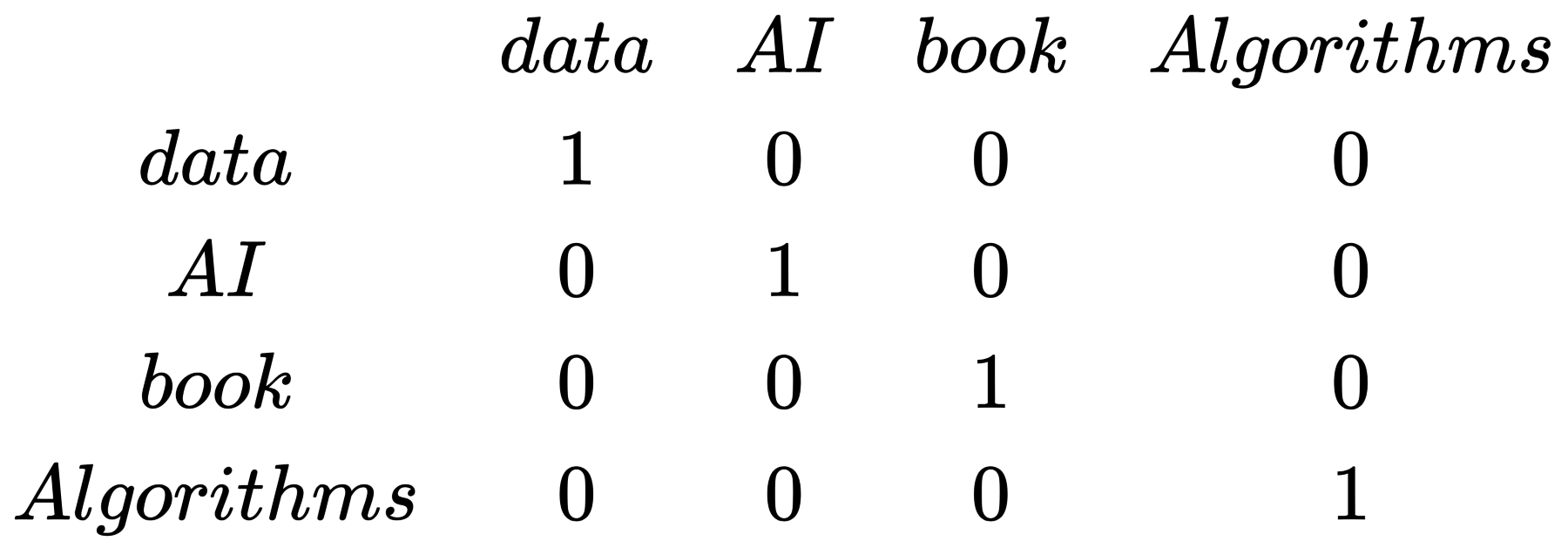
위의 그림처럼 id x번째 열을 1로 채우고 나머지는 0으로 채우면 만들어진다.
단어장에 없는 단어의 표현은 idx 0을 사용한다.
위의 사진처럼 모든 단어장의 단어를 vector화 시킨게 one-hot vector이다.
Using Word Frequency
자주 쓰이는 단어를 사용해 vocabulary를 구성합니다. 너무 빈도수가 적은 것은 사용하지 않는다던가 빈도수가 많은 단어만을 사용해 단어장을 구성하는 형식이죠.
- corpus : NLP에서 끌어모은 데이터
즉, corpus안에 단어 빈도수에 맞춰 단어장을 구성하는 방식들을 소개하고자 합니다.
BoW(Bag-of-Words)
Bow vector는 단어의 순서를 고려하지 않고 그냥 모아서 섞어 버리는 것을 말합니다.
단순히 여러 개의 단어를 합하여 문장을 표현한 것입니다.
- one-hot vector를 합쳐 한 문장을 한 개의 column vector로 표현한 것이 BoW vector.
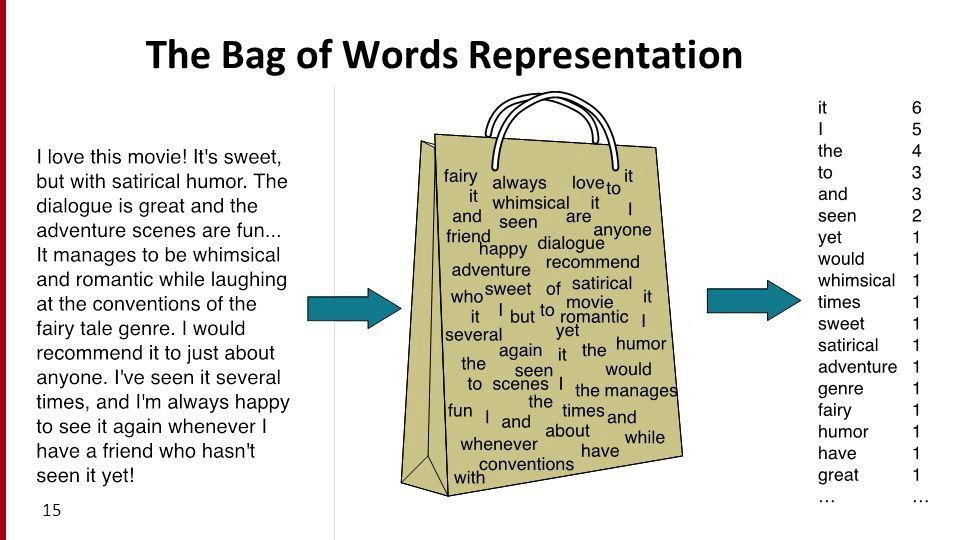
<출처 : https://web.stanford.edu/~jurafsky/slp3/4.pdf>
N-gram
- n-gram은 연속된 n개의 단어 뭉치를 뜻합니다.
"I will pray for you" 에서 나타나는 bi-gram(n=2)는 [I will, will pray, pay for, you]가 됩니다.
n-gram으로 BoW를 만든다고 생각해봅시다. 단순하게 생각하더라도 n의 갯수가 커지면 vocabulary 크기가 많이 커지겠죠?
그래서 보통 n은 2~3정도로 설정해서 사용합니다.
n-gram은 추후 더욱이 많이 설명할 예정입니다.
tf-idf vector
- term ferquency - inverse document frequency는 단어 간 빈도 수에 따라 중요도를 계산하는 방법입니다.
학습 데이터가 크면, 자주 쓰이는 단어가 많아집니다. 하지만 많이 쓰였다고 문장의 주제 파악에 중요한 것은 아닙니다.
- 주제 파악에 그리 중요하지 않은 관사나 대명사를 stopword라고 합니다.
그래서 tf-idf vector에는 tf-idf score가 있습니다.
- term frequency(tf) : 현재 문서(문장)에서 단어의 빈도수
- document frequency(df) : 해당 단어가 나오는 문서(문장) 총 개수
를 의미합니다.
이제 생각해봅시다.
stopword들은 tf와 df가 둘 다 굉장히 높게 나타날 것입니다.
반대로 주제 단어와 같은 것들은 tf가 높을 수는 있겠지만, df는 상대적으로 낮을 것입니다.
그래서 tf-idf score는 다음과 같이 계산됩니다.
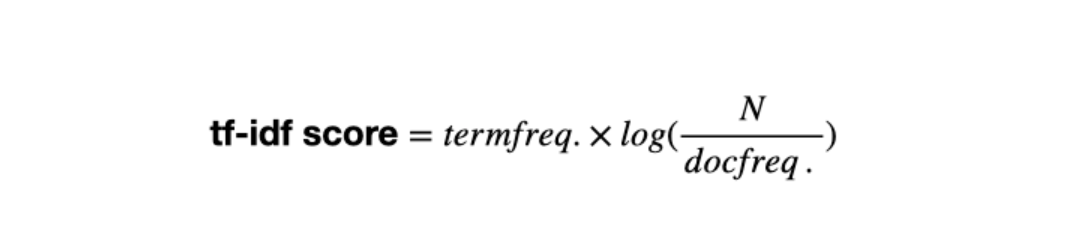
(N : 전체 문서(문장)의 개수)
- 즉, tf-idf vector는 Nx1 vector 모양의 BoW vector에서 tf score를 idf score로 nomalize한 것 입니다.
BoW, tf-idf vector의 단점
- 문장의 순서가 관계가 없는 topic classification이나 document retrieval같은 일에 강점을 보이지만, 번역과 같이 어순이 중요한 일에는 단점을 가집니다.
- vocabulary가 커지면, vector의 사이즈는 커집니다. one-hot vector부터 시작되는 고질적인 문제인데 Nx1 column vector로 표현하기 때문에, 크기가 어마어마 하게 커져 사용하기 힘듭니다. (이런 matrix를 sparse matrix라고 함.)
- 당연하게도 단어간의 관계를 표현하지 못합니다.
가벼운 NLP 문제들에서는 심플한 방식이 먹힐 때가 있습니다. 잘 알아둔 후 때에 맞게 선택하시길 바랍니다.


교수가 따로 없네. 대학원 가라.