
개요
프로그래밍에서 데이터를 효율적으로 관리하기 위해 다양한 자료구조가 사용된다. 그중 배열은 가장 기본적인 형태지만, 크기가 고정되어 유연성이 떨어지는 단점이 있다. 이러한 단점을 보완하기 위해 리스트가 등장했으며, 자바에서는
ArrayList,LinkedList등 다양한 형태로 제공된다.ArrayList를 직접 구현해 보며 그 특징을 살펴보자.
배열과 한계
배열이란
int a = 10;
int b = 20;int타입의 변수 a, b가 있다. 또 다른 int타입의 필요하다면 int b = 30과 같이 변수를 추가하고 값을 저장해야 될 것이다. 만약 필요한 int 타입의 100개 아니 1000개라면? 해당 개수에 맞게 변수를 추가해야 될 것이다.
위와 같은 단점을 해결하기 위해 배열의 탄생했다. 배열을 사용하면 int a, b, c...처럼 각각의 변수를 따로 선언하지 않고, 동일한 타입의 값을 하나의 묶음으로 관리할 수 있다. 이렇게 같은 타입의 데이터를 효율적으로 저장하고 관리하기 위한 자료구조가 바로 배열이다.
배열 사용 방법
배열의 사용 방법은 크게 선언, 생성, 초기화, 접근 4단계로 사용할 수 있다.
1. 선언
String[] strArr;
int[] intArr;배열을 사용하려면 배열이 담을 수 있는 타입과 배열의 변수명을 지정해 준다. 이때, 타입 뒤에는 []를 붙여 배열임을 명시해야 한다.
2. 생성
strArr = new String[10]; // 크기가 10인 String 배열
intArr = new int[10]; // 크기가 10인 int 배열배열을 선언한 뒤에는 배열을 생성하여 실제 메모리 공간을 할당해야 한다. 배열의 크기는 배열을 생성할 때 지정하며 [] 안에 원하는 크기만큼의 숫자를 넣어 지정한다.
3. 초기화
strArr[0] = "hello";
intArr[0] = 10;
intArr[0] = 10;
intArr[1] = 20;배열을 생성한 후에는 배열의 각 요소를 원하는 값으로 초기화할 수 있다. 만약 초기화를 하지 않으면 초기값을 넣어주는데 이때 기본형의 경우 0, false를 참조형의 경우 null을 초기값으로 사용한다.
4. 접근
String strValue1 = strArr[0];
String strValue2 = strArr[1];
int intValue1 = intArr[0];
int intValue2 = intArr[1];배열의 각 요소에 접근할 때는 인덱스를 사용한다. 배열의 인덱스는 0부터 시작한다. strArr와 intArr의 경우 크기가 10이므로 인텍스는 0 ~ 9까지이다.
배열의 특징
연속된 메모리 공간에 저장과 인덱스
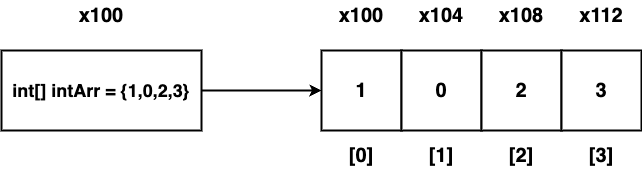
- 배열은 연속적인 메모리 공간에 순서대로 붙어서 저장된다.
- 따라서 인덱스를 통해 한 번에 접근이 가능하다.
- 특정 인덱스의 값을 가져올 때
배열의 시작 참조 + (자료의 크기 * 인덱스 위치)의 계산을 통해 한 번에 값을 조회할 수 있다. - 이를 통해 인덱스를 통한 조회는
O(1)의 빠른 속도를 낼 수 있다.
데이터 추가, 삭제의 어려움
배열의 마지막 index의 값을 추가하거나 삭제는 경우는 간단하고 O(1)의 빠른 속도를 내지만 배열의 처음 혹은 중간 index의 값을 추가, 삭제하는 경우는 간단하지 않고 속도 또한 느리다.

위 그림은 배열의 중간 위치의 값을 삭제하는 과정이다. 삽입 또한 위 그림과 비슷한 과정을 거친다.
- 특정 인덱스의 값을 지운다.
- 특정 인덱스의 뒤의 값을 앞으로 당긴다.
- 위 과정을 반복한다.
위와 같은 과정들로 인해 배열의 처음 혹은 중간에 값을 삽입, 삭제하는 속도는 O(n)이다.
고정된 크기의 한계
int[] intArr = new int[5];
intArr[0] = 0;
intArr[1] = 1;
intArr[2] = 2;
intArr[3] = 3;
intArr[4] = 4;
//intArr[5] = 5; // 저장 불가 저장 시 예외 발생
int[] newIntArr = new int[10]; // 새로운 배열을 만들어 사용
newIntArr[0] = 0;
newIntArr[1] = 1;
newIntArr[2] = 2;
newIntArr[3] = 3;
newIntArr[4] = 4;
newIntArr[5] = 4;배열은 고정된 크기를 가지고 있기 때문에 크기 이상을 저장하고 싶으면 새로운 배열을 생성 후 값을 복사해야 한다.
배열은 단순하고 기본적인 자료구조로 인덱스를 이용한 접근을 통해 빠르게 값을 조회할 수 있다는 장점이 있다. 그러나 배열은 생성 시 크기를 고정해야 한다는 단점이 있다. 만약 배열이 가득 찬 상태라면 기존 배열에 새로운 값을 추가할 수 없고, 이를 고려해 처음부터 큰 크기로 배열을 생성하면 메모리가 낭비될 수 있다.
이러한 문제를 해결하기 위해서는 배열처럼 데이터를 연속적으로 저장하면서도 크기를 유동적으로 늘릴 수 있는 자료구조가 필요하다.
직접 구현하는 ArrayList
List란
- 순서가 있고, 중복을 허용하는 자료 구조를 리스트라 한다.
- 배열과
List의 차이- 배열: 순서가 있고 중복을 허용하지만 크기가 정적으로 고정된다.
- 리스트: 순서가 있고 중복을 허용하지만 크기가 동적으로 변할 수 있다.
ArrayList는 배열을 사용하는 리스트를 의미한다.
MyArrayList 구현
1단계: 기본 구조 정의
public class MyArrayList<E> {
private static final int DEFAULT_CAPACITY = 10;
private Object[] elementData;
private int size = 0;
public MyArrayList() {
this.elementData = new Object[DEFAULT_CAPACITY];
}
public MyArrayList(int initialCapacity) {
this.elementData = new Object[initialCapacity];
}
//시간 복잡도: O(1)
public void add(E element) {
elementData[size] = element;
size++;
}
//시간 복잡도: O(1)
public E get(int index) {
return (E) elementData[index];
}
//시간 복잡도: O(1)
public E set(int index, E e) {
Object oldValue = elementData[index];
elementData[index] = e;
return (E) oldValue;
}
//시간 복잡도: O(n)
public int indexOf(E e) {
for (int i = 0; i < size; i++) {
if (elementData[i].equals(e)) {
return i;
}
}
return -1;
}
public int size() {
return size;
}
@Override
public String toString() {
return Arrays.toString(elementData);
}
}add(E e): 리스트에 값을 추가하며, 추가시size가 증가한다.get(int index): 특정 인덱스의 값을 반환한다.set(int index, E e): 특정 인덱스의 값을 수정하고, 수정전 값을 반환한다.size(): 현재 리스트의 크기를 반환한다.
MyArrayList는 제네릭 타입을 사용하여 어떤 타입의 데이터든 저장할 수 있도록 설계되었으며, 생성 시 initialCapacity를 통해 내부 배열의 초기 크기를 지정할 수 있다. 하지만 배열과 마찬가지로 한 번 정해진 크기는 자동으로 변경되지 않기 때문에, 요소가 추가되면서 공간이 부족해질 경우 문제가 발생할 수 있다.
이제 이러한 한계를 극복하기 위해 동적으로 배열의 크기를 늘릴 수 있는 로직을 추가해 보자.
2단계: 동적으로 크기 변경
//시간 복잡도: O(1)
public void add(E e) {
if (elementData.length == size) {
grow();
}
elementData[size] = e;
size++;
}
private void grow() {
int oldCapacity = elementData.length;
int newCapacity = (int) Math.ceil(oldCapacity * 1.5);
elementData = Arrays.copyOf(elementData, newCapacity);
}기존 코드에서 add(E e) 메서드를 수정하고 grow() 메서드를 새로 추가했다.
size가 배열의 크기와 같아지면 grow() 메서드를 호출하여, 기존 배열을 복사해 더 큰 배열로 확장한다. 이때 새로운 배열의 크기는 기존 크기보다 1.5배 증가하도록 설정했다. 이제 배열의 가장 큰 단점이었던 고정된 크기 할당 문제를 해결할 수 있게 되었다.
다음으로는 배열 중간에 데이터를 삽입하거나 삭제할 수 있는 메서드도 추가해 보자.
3단계: 중간 인덱스의 데이터 삽입, 삭제
//시간 복잡도: O(n)
public void add(int index, E e) {
if (elementData.length == size) {
grow();
}
for (int i = size; i > index; i--) {
elementData[i] = elementData[i - 1];
}
elementData[index] = e;
size++;
}
//시간복잡도 best: O(1), worst: O(n)
public E remove(int index) {
E removeValue = (E) elementData[index];
for (int i = index; i < size - 1; i++) {
elementData[i] = elementData[i + 1];
}
size--;
return removeValue;
}특정 index에 값을 추가하거나 제거하는 add(int index, E e)와 remove(int index) 추가하였다.
위 메서드들의 경우 중간 index에 요소를 삽입하거나 삭제해야 하기 때문에 해당 index 이후의 요소들을 한 칸씩 이동시켜야 한다. 따라서 이 두 메서드의 시간 복잡도는 O(n)이다.
4단계: 최종 코드
import java.util.Arrays;
public class MyArrayList<E> {
private static final int DEFAULT_CAPACITY = 10;
private Object[] elementData;
private int size = 0;
public MyArrayList() {
this.elementData = new Object[DEFAULT_CAPACITY];
}
public MyArrayList(int initialCapacity) {
this.elementData = new Object[initialCapacity];
}
public void add(E e) {
if (elementData.length == size) {
grow();
}
elementData[size] = e;
size++;
}
public void add(int index, E e) {
if (elementData.length == size) {
grow();
}
for (int i = size; i > index; i--) {
elementData[i] = elementData[i - 1];
}
elementData[index] = e;
size++;
}
public E set(int index, E e) {
Object oldValue = elementData[index];
elementData[index] = e;
return (E) oldValue;
}
public E remove(int index) {
E removeValue = (E) elementData[index];
for (int i = index; i < size - 1; i++) {
elementData[i] = elementData[i + 1];
}
size--;
return removeValue;
}
public E get(int index) {
return (E) elementData[index];
}
public int indexOf(E e) {
for (int i = 0; i < size; i++) {
if (elementData[i].equals(e)) {
return i;
}
}
return -1;
}
public int size() {
return size;
}
private void grow() {
int oldCapacity = elementData.length;
int newCapacity = (int) Math.ceil(oldCapacity * 1.5);
elementData = Arrays.copyOf(elementData, newCapacity);
}
@Override
public String toString() {
return Arrays.toString(Arrays.copyOf(elementData, size));
}
}
1단계부터 3단계의 과정을 거쳐서 MyArrayList를 완성했다. 위 코드는 컬렉션 프레임워크에서 제공하는 ArrayList와 매우 유사하다. 이를 통해 컬렉션 프레임워크에서 제공하는 ArrayList의 동작 방식을 학습할 수 있었다.
ArrayList의 경우 인덱스를 통한 조회는 O(1)이라는 빠른 속도를 자랑하지만 중간에 데이터를 삽입하거나 삭제할 경우 요소들을 한 칸씩 밀거나 당겨야 하므로 시간 복잡도는 O(n)이라는 비교적 느린 성능을 나타내는 것을 확인할 수 있었다.
마지막으로 각 메서드 별로 시간복잡도를 정리해보자.
메서드 별 시간복잡도
| 메서드 | 설명 | 시간복잡도 |
|---|---|---|
| add(E e) | 마지막 인덱스에 삽입 | O(1) |
| add(int index, E e) | 특정 인덱스에 삽입 | best: O(1), worst: O(n) |
| set(int index, E e) | 특정 인덱스의 값 변경 | O(1) |
| get(int index) | 특정 인덱스의 값 조회 | O(1) |
| remove(int i) | 특정 인덱스의 값 제거 | best: O(1), worst: O(n) |
| indexOf(E e) | 특정 값이 처음으로 확인되는 인덱스(위치) 반환 | O(n) |
정리
-
배열은 관련된 데이터를 효율적으로 관리하기 위해 사용하는 기본적인 자료구조이다.
-
배열은 생성 시 크기를 지정해야 하며, 이후 크기를 변경할 수 없어 정적인 구조를 가진다.
-
배열은 데이터의 중복이 가능하고, 저장 순서를 유지한다.
-
리스트는 중복이 허용되며, 저장 순서가 있는 자료구조이다.
-
배열과 리스트의 가장 큰 차이는 크기의 동적 할당 가능 여부이다. 배열은 고정 크기이고, 리스트는 크기를 동적으로 조절할 수 있다.
-
리스트는 내부적으로 배열을 사용하며, 인덱스를 통한 조회는 O(1)의 시간 복잡도를 가진다.
-
하지만 리스트에서 중간 인덱스에 데이터를 삽입하거나 삭제하는 경우, 요소들을 이동시켜야 하므로 시간 복잡도는 O(n)이 된다.
제가 공부한 내용을 정리한 것이라 틀린 내용이 있을 수 있습니다. 보시고 틀린 내용을 알려주시면 감사하겠습니다 😀
참고자료
김영한의 실전 자바 - 중급 2편
