
💡 리터럴(literal)?
자바에서의 리터럴은 그 자체로 값을 의미하는 것을 말한다.
- 기존의 상수와 같은 의미이다. 하지만 자바에서 상수(constant)를 '한번 만 값을 저장 가능한 변수' 라는 의미로 정의했기 때문에 구별하기 위해 따로 리터럴(literal)이라는 단어를 사용한다.
int A = 10; //자료형(정수형) 변수명 = 10(리터럴, int)
- '변수의 타입의 범위 < 리터럴 타입의 범위'인 경우 에러가 발생한다.
하지만 변수와 리터럴의 타입이 불일치해도 괜찮을 경우가 있다.
- 변수의 타입의 범위 > 리터럴 타입의 범위
- byte, short 변수에 int리터럴 저장
| 종류 | 리터럴 | 접미사 |
|---|---|---|
| 논리 | false, true | 없음 |
| 정수 | 123, 0b0101, 077, 0xFF, 100L | L |
| 실수 | 3.14, 3.0e8, 1.4f, 0x1, 0p-1 | f, d |
| 문자 | '가', 'A','\n' | 없음 |
| 문자열 | "가나다", "A", "true" | 없음 |
- 정수와 실수는 타입이 여러개이기 때문에 접미사를 붙혀 구분한다.
- 접미사는 대소문자를 구분하지 않는다.
💡 기본 자료형
🤔 논리 자료형
true(참)과 false(거짓)중 하나를 값으로 갖는 자료형 ,조건문과 논리적 계산에 사용된다.
| 논리형 타입 | 크기 | 표현범위 |
|---|---|---|
| boolean | 1 byte | true, false |
boolean bool = true;
연산의 결과
boolean bool = (1 > 2) // false boolean bool = (2 = 2) // true
💻조건문
if(2 = 2){ System.out.println("2는 2입니다."); }
🤔 정수 자료형
정수 자료형은 정수를 저장하는데 사용되는 자료형이다.
- 주로 사용하는 것은 int와 long이며 byte, short는 잘 쓰이지 않는다.
| 논리형 타입 | 크기 | 표현범위 |
|---|---|---|
| byte | 1 byte | -128 ~127 |
| short | 2 byte | -32,768 ~ 32,767 |
| int | 4 byte | -2,147,483,648~2,147,483,647 |
| long | 8 byte | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
long 타입의 리터럴에는 접미사 'L'을 추가하며 그외의 리터럴은 int 타입이다.
- byte는 이진 데이터를 다루는데 사용하고, short는 C언어와의 호환을 위해 추가되었다.
long 변수에 값을 저장 할때 int 자료형의 범위를 넘어간 값일 경우 접미사 'L'을 붙여야한다.
- 접미사는 대소문자를 구분하지 않지만 소문자 'L'사용사 숫자 '1'과 혼동할 우려가 있기 때문>에 대문자를 사용한다.
long A = 2,147,483,800L
-
변수의 타입의 범위 > 리터럴 타입의 범위
int A = 'a'; int > char long B = 13; long > int -
변수의 타입의 범위 < 리터럴 타입의 범위, 에러
int A = 2,147,483,800L // int의 범위를 넘어간다 long B = 3.14f // 정수의 범위는 보통 실수의 범위보다 작다. -
byte, short 변수에 int리터럴 저장
byte A = 100; // byte의 범위(-128 ~127)에 속함
10진수를 제외한 2진수/8진수/10진수는 접두사를 붙여 표현한다.
- int 타입의 리터럴을 사용하되, 약속된 접두사를 붙여 구분한다.
int binary = 0b0101; // 숫자 '0', 문자'b', "0b"을 붙여준다. int octal = 077; // 숫자 '0', "0"을 붙여준다. int decimal = 10; int hexadecimal = 0xFF; //자 '0', 문자'x', "0x"을 붙여준다.
💻 언더스코어 표기법(underscore)
- 언더스코어 표기법은 정수형 리터럴 중간에 구분자로'_'(언더바)를 사용하는 표기법이다.
큰 숫자에 ','(콤마)를 넣어 표현하듯이 사용한다.int A = 100_000_000; // 100,000,000
🤔 실수 자료형
실수 자료형은 실수 값을 저장하는데 사용되는 자료형이다.
| 논리형 타입 | 크기 | 표현범위 | 정밀도 |
|---|---|---|---|
| float | 4 byte | ±(1.40129846432481707e-45 ~ 3.40282346638528860e+38) | 7 |
| double | 8byte | ±(4.94065645841246544e-324d ~ 1.79769313486231570e+308d) | 15 |
- float, double 두가지가 있는데 실수형 리터럴에는 접미사를 붙여서 타입을 구분한다. float 리터럴에는 'f', double 타입 리터럴에는 'd'를 붙인다. (대소문자를 구분하지 않는다.)
float F = 3.14f; double D = 3.14d;
- double타입 리터럴은 기본 자료형이기 때문에 'd'는 생략할 수 있다.
double D = 3.14;
- float 타입 변수에 double 타입 리터럴을 저장할 경우, 에러
float F = 3.14; //float 타입의 범위에 속한 값이더라도 에러가 발생한다. float F = 3.14d;
🤔 실수의 표현 방식
실수를 컴퓨터에서 표현하는 방식으로는 대표적인 고정 소수점 방식과 부동소수점 방식으로 나눌 수 있다. 메모리는 한정적이기 때문에 컴퓨터는 소수를 이진법으로 표현할 떄 고정 소수점 방식이 아닌 부동 소수점 방식을 이용한다.
💻 고정 소수점 방식(Fixed-Point Number Representation)
- 고정 소수점 방식은 메모리를 정수부와 소수부로 고정으로 나누어 지정하여 처리하는 방식이다.
- 고정소수점 방식은 소수부의 자릿수를 미리 정하고 고정된 자릿수의 소수를 표현하기 떄문에 직관적이다.
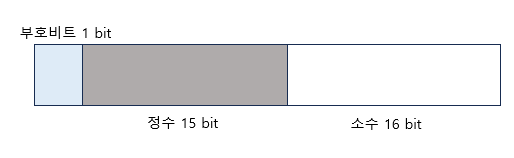
10진수로 표현된 실수를 이진수로 변환하고 결과 값을 각각 정수부, 소수부 메모리 비트에 넣어주기만 하면 표현이 된다.
직관적적으로 메모리에 실수를 표현할 수 있다는 장점이 있지만, 정수부가 큰 실수가 있을수도 있고 반대로 소수박 큰 실수다 있을수도 있기 때문에 표현 가능한 범위가 매우 적다는 단점이 있다.
💻 부동 소수점 방식(Floating-Point Number Representation)
- 부동 소수점 방식은 소수점(poing)이 떠다닌다(floating)라는 의미이다.
- 표현할 수 있는 값의 범위를 넓혀 오차를 줄이고자는 시도에서 탄생하였다.
- 정수부와 소수부로 나누던 고정 소수점 방식과는 달리 가수부와 지수부로 나눈다.

실수의 값 자체를 가수부(23bit)에 넣어서 표현한다.
- 정수부가 크든 소수부가 크든 상관없이 가수부에서 전체 실수를 표현하기 떄문에 공간 낭비 문제가 해결 되며 고정 소수점 방식에 비해 큰 범위 값을 값을 표현할 수 있다.
지수(e) 표기법?
- 지수 표기범은 아주 큰 숫자나 아주 작은 숫자를 간단하게 표기할 떄사용되는 표기법이다.
double D = 3.14e+10; // e(E)로 지수부 시작. 3.14 * 10^10 = 31,400,000,000 double D1 = 3.14e10; // +는 생략 가능. 31,400,000,000 double D = 3.14e-2; // 0.0314
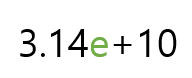
- 큰 범위의 값을 표현 가능하기 떄문에 자바에서 사용하는 정수 타입들의 범위 보다 범위가 훨씬크다.
- 변수의 타입의 범위 < 리터럴 타입의 범위에 포함 되므로 에러가 발생한다.
long L = 3.14f
부동 소수점 방식을 사용하면 매우 큰 범위의 실수까지도 표현할 수 있어 보다 정밀하게 소수를 표현할수는 있지만 그래도 완전히 정확하게 표현하는 것이 아니다. 이는 소수를 연산하는데 부정확한 결과값이 나오게 되고 오차가 발생한다는 것을 의미한다. 컴퓨터의 실수 연산은 소수점 단의 값을 정확히 표현하는 것이아니라 근사값으로 처리하기 떄문에 오차가 발생하는 것이다.
💻 부동 소수점 계산
자바는 IEEE 754 표준 방식을 따른다.
부동 소수점 방식은 하나의 실수를 가수부와 지수부로 나누어 표현한다.
±(1.가수부)×2^지수부-127
아래는 실수를 부동 소수점으로 변환하는 예시이다.
- 부호비트를 설정, 음수이면 1 양수이면 0이다.

- 10진수로 표현된 실수를 이진수로 변환
- 100.5 => 1100100.1
- 정규화를 통해 정수부가 한자리가 되도록 변환, 지수를 사용하여 표현(부동 소수점)
- 정규화 : 소수점을 이동 시키는 것
- 1.1001001 * 2^6
- 가수부 에 소수점 아래 부분의 실수 값 그대로 넣는다. 나머지는 0으로 채운다.

5.지수에 bias(127)을 더하고 이진수로 변환후, 지수부 비트에 넣는다.
- 6 + 127 = 133 => 10000101
- bias는 지수가 음수가 될 수 있기 때문에 사용한다.
- 10진수로 표현된 실수(0.625)를 이진수로 변환했을 때 0.101가 된다.
- 0.101를 정규화를 하게 되면 1.01 * 2^-1가 나오고 음수인 지수 -1이 나온다.
- 음수 지수를 8비트로 표현하기 위해 127을 더해준다. 이는
- 8bit로는 256 개의 수를 표현할 수 있는데, 양/음수를 표현하기위해 일단 지수에서 127을 더해 음수는 (0 ~ 127) 까지, 양수는 (128 ~ 155) 까지 구분하기 위해서이다. 따라서 지수에 bias 값을 더해 127보다 적으면 음수, 크면 양수로 구분할 수 있다.

💻 정밀도
자바에서 실수를 표현하는데 타입별로 정밀도가 있다. 정밀도가 결정나는 이유는 부동소수점 표현 방식에 따른 결과로, 가수부를 표현할 수 있는 크기에 따라 결정되기 떄문이다.
| 논리형 타입 | 크기 | 표현범위 | 정밀도 |
|---|---|---|---|
| float | 4 byte | ±(1.40129846432481707e-45 ~ 3.40282346638528860e+38) | 7 |
| double | 8byte | ±(4.94065645841246544e-324d ~ 1.79769313486231570e+308d) | 15 |
-
float형은 가수의 길이가 23 bit 이지만 정규화를 통해 실제로는 24자리 까지 저장할 수 있다. 2^24는 10^7보다 크고 10^8보다 작기 때문에 정밀도는 7이된다.
-
double형은 가수의 길이가 52 bit 이지만 정규화를 통해 실제로는 53자리 까지 저장할 수 있다. 2^53은 10^15보다 크고 10^16보다 작기 떄문에 정밀도가 15이다.
-
정밀도가 7이라는 것은 7자리의 10진수를 오차없이 정확하게 표현할 수 있다는 뜻이다. 마찬가지로 정밀도가 15이라는 것은 15자리의 10진수를 오차없이 정확하게 표현할 수 있다는 뜻이다.
float을 사용하여 연산속도 향상이나 메모리의 절약을 필요로 하는경우가 아니라면보다 높은 정확도를 필요로 할 경우 double 타입을 사용하면 된다는 것이다.

🤔 문자 자료형
문자 자료형은 문자를 저장하는데 사영되며, 변수 당 하나의 문자만을 저장할 수 있다.
| 논리형 타입 | 크기 | 표현범위 |
|---|---|---|
| char | 2 byte | 0~65,535 |
-
문자 자료형 char은 문자값을 '(작은 따옴표)로 감싸야한다.
char C = 'C'; -
위 문장은 'C'(문자)가 저장되는 것 같지만 실제로는 문자가 아니라 해당 문자의 '유니코드'(정수)가 저장된다. 컴퓨터는 숫자만을 알기 때문에 모든 데이터를 숫자로 변환하여 저장하는 것이다.
문자 'C'는 유니코드는 67이기 때문에 변수 C에는 정수 67이 저장된다.
문자 리터럴 대신 유니코드를 직접 저장할 수 있다.
- 문자'C'의 유니코드는 10진수로 이므로 동인한 결과를 얻는다.
char C = 'C'; char C1 = 67;
- 문자형 자료형은 문자를 저장할 변수를 선언하기 위한 것이지만, 실제로는 문자가 아닌 문자의 유니코드가 저장되고 정수형과 달리 음수를 나타낼 필요가 없으므로 같은 2byte인 short형과 표현할 수 있는 범위가 다르다.
변수의 타입이 정수형 일경우에는 저장된 값을 10진수로 해석하여 출력하고, 문자형이면 저장된 숫자에 해당하는 유니코드 문자를 출력한다.
short I = 67; // 67출력 char C = 67; // C출력이처럼 값을 어떻게 해석하느냐에 따라 결과가 달라지므로 값만으로는 값을 해석할 수 없다. 값의 타입까지 알아야 올바르게 해석할수 있다.
💻 특수문자 저장
영문자 이외에 특수문자를 저장하려먼 특수한 방법을 사용한다.
| 특수 문자 | 문자 리터럴 |
|---|---|
| tab | \f |
| backspace | \b |
| form feed | \f |
| new line | \n |
| carriage return | \r |
| 역슬래쉬() | \ |
| 작은따옴표 | \' |
| 큰따옴표 | \" |
| 유니코드(16진수)문자 | \u유니코드 (\u0041) |
char tab = '\tab'; char backspace = 'abc\b'; // ab char newline '\n'; // 개행 char quote = '\"\''; // "'
