Chapter 6
인덱스 Index는 데이터를 빠르게 찾을 수 있는 도구로, 실무에서는 현실적으로 인덱스 없이 DB운영이 불가능.
지금까지 우리는 데이터 양이 워낙 적어서 인덱스가 필요없는, 찾아보기가 없는 책과 마찬가지의 테이블을 사용. 데이터를 찾을 때, 인덱스의 사용 여부가 결과값에 차이를 가져오지 않지만, 시간이 오래 걸림.
하지만 인덱스에도 문제점이 존재. 필요없는 인덱스를 만들면 DB가 차지하는 공간만 늘어나고 경우에 따라 인덱스를 이용해서 찾는 것이 전체 테이블을 찾아보는 것보다 느려질수 있다.
인덱스의 장점
- 빠른 응답 속도
- 컴퓨터의 부담을 줄여 시스템 성능 향상
인덱스의 단점
- DB의 추가적 공간 차지.
- 인덱스를 만드는 작업 시간.
- 잦은 데이터 변경 작업(insert, update, delete)은 성능 저하 요인.
클러스터형 인덱스 Clustered Index : 기본 키 PK로 지정하면 자동 생성되며, 테이블에 1개만 만들 수 있고 기본 키로 지정한 컬럼을 기준으로 자동 정렬. like 영어사전.
보조 인덱스 Secondary Index : 고유 키 Unique로 지정하면 자동 생성되며, 여러 개를 만들 수도 있지만 자동 정렬되지는 않음. like 책 뒤에 찾아보기가 있는 일반적인 책.
인덱스는 컬럼 단위로 생성되고, 하나의 컬럼에는 하나의 인덱스를 생성 가능. 하나의 컬럼에 여러 인덱스를 생성할 수 있고, 여러 컬럼을 묶어서 하나의 인덱스를 생성할 수도 있음. 하지만 일반적으로는 하나의 열에 하나의 인덱스.
< 자동으로 생성되는 인덱스 >
테이블에서 PK를 지정하면, 자동으로 해당 컬럼에 클러스터형 인덱스가 생성됨. PK는 테이블에 하나만 가능하기에, 클러스터형인덱스도 테이블에 한 개만 만들 수 있음.
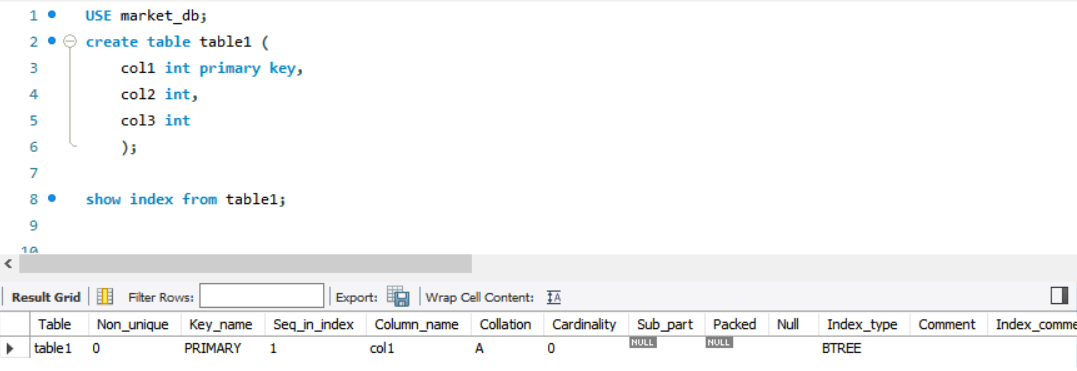
임의의 테이블을 만들고 col1을 PK로 지정하고, 테이블의 인덱스를 확인하는 SHOW INDEX문을 활용하면 인덱스 정보를 확인 가능.
key_name을 보면 primary로 기본 키로 설정해 자동으로 생성된 인덱스라는 의미. 이게 클러스터형 인덱스. Key_name에 PRIMARY라고 써 있으면 클러스터형 인덱스와 같은 걸로 생각해도 무방.
Column_name 이 col1로 설정되어있는건 col1 열에 인덱스가 만들어졌다는 의미. Non_Unique는 1이면 True, 0이면 False로 현재 이 인덱스는 중복이 허용되지 않는 인덱스라는 뜻.
Unique Index : 인덱스의 값이 중복 X.
Non-Unique Index : 인덱스의 값이 중복 가능.
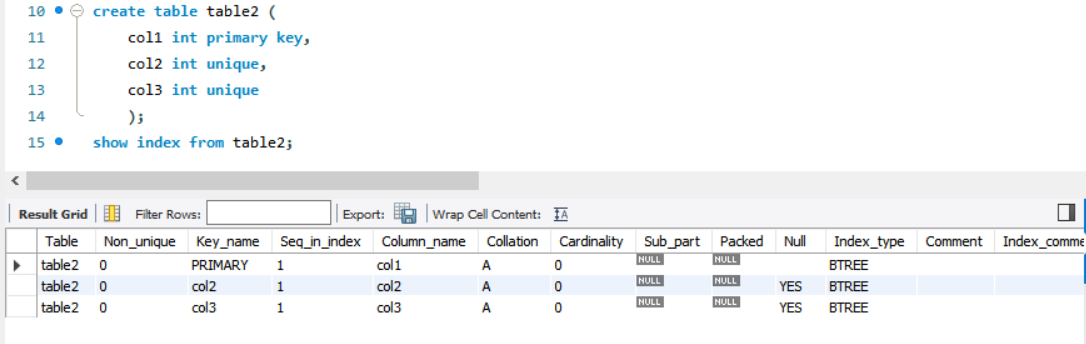
고유 키도 인덱스가 자동으로 생성. 고유 키로 생성되는 인덱스는 보조 인덱스. 위에 만든 table2를 보면 Key_name에 컬럼 이름이 써 있는 것은 보조 인덱스라고 보면 됨. 여기서도 Non_Unique가 0이니 고유 키 역시 중복값을 허용하지 않음.
< 자동으로 정렬되는 클러스터형 인덱스 >
클러스터형 인덱스를 영어사전과 비교했는데, 영어사전이 알파벳 순서로 정렬되어 있는 것처럼, 어떤 컬럼을 PK로 지정하면 ( = 클러스터형 인덱스가 생성되면 ) 그 컬럼을 기준으로 자동 정렬됨.
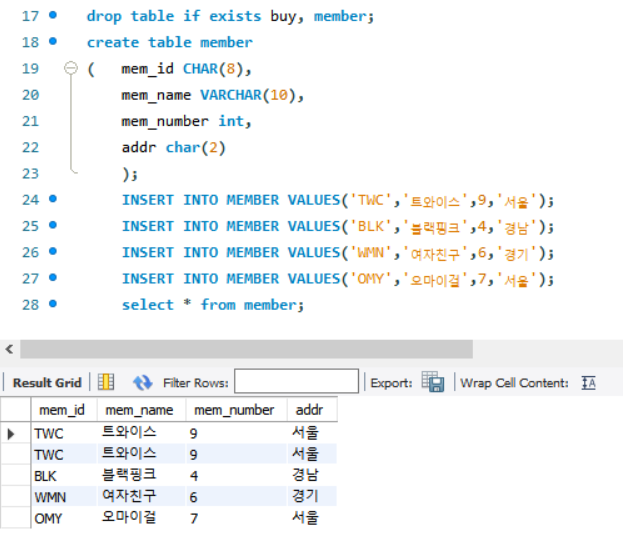
이렇게 만든 테이블에서 mem_id를 PK로 설정하는 것은 일반 노트를 영어사전으로 만드는 과정.
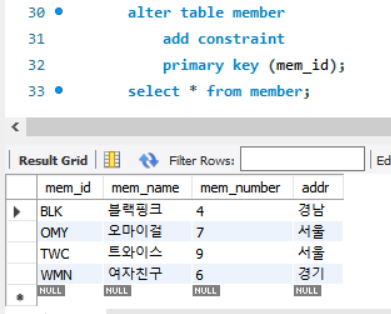
ALTER TABLE를 통해 mem_id를 PK로 지정하니 실행 결과에서 B->O->T->W로 알파벳 순으로 정렬된 것을 볼 수 있음.
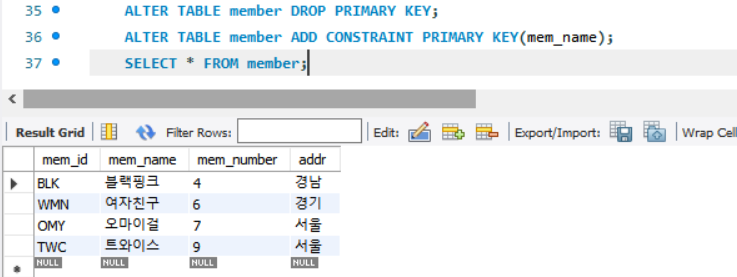
이번엔 mem_name을 PK로 지정시,
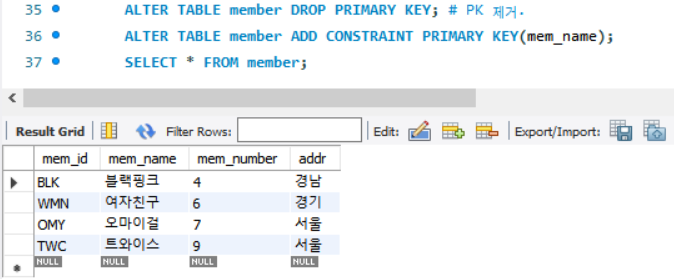
mem_name 컬럼을 기준으로 한글순으로 정렬된 것을 볼 수 있다.
insert into member values ('GRL','소녀시대',8,'서울');해당 라인을 추가 시 블랙핑크와 여자친구 ROW 사이에 들어오게 되는 것을 예상할 수 있다.
< 정렬되지 않는 보조 인덱스 >
고유 키로 지정하면 보조 인덱스가 생성. 보조 인덱스를 책 뒤쪽에 찾아보기(인덱스)가 있는 일반 책으로 비유했는데, 일반 책에 찾아보기를 만들면 책의 뒤쪽에 추가되며, 본문이 변하진 않는다.
해당 테이블에서 mem_id를 고유 키로 설정하고 내용을 확인해도,
ALTER TABLE member ADD CONSTRAINT UNIQUE (mem_id);
SELECT * FROM member;위 코드를 작성해도 실행결과는 순서까지 동일하다.
mem_name 열에 추가로 고유 키를 지정해도 결과는 변하지 않음. 한국의 동식물이라는 책이었다면, mem_id는 동물과 관련된 찾아보기를 만든거고 mem_name을 고유키로 지정하는 것은 추가적으로 식물과 관련된 찾아보기를 만든 것 뿐.
여기서 데이터를 추가하면 일반 책에 새 내용이 추가되면 본문의 제일 뒤에 추가되는 것과 동일하게 맨 뒤로, ROW 가장 하단으로 추가됨.
그렇다고 보조 인덱스를 다다익선으로 생각하고 만들기엔 DB의 공간을 많이 차지하게 되고 시스템에 악영향을 미치기에 꼭 필요한 컬럼에 적절히 보조 인덱스 Secondary Index를 생성하는 것을 권장.
클러스터형, 보조 인덱스 모두 균형 트리, Balanced tree = B-tree로 만들어짐. 인덱스의 내부 작동 원리를 이해하면 인덱스를 사용해야 할 경우와 그러지 말아야 할 경우를 선택할 때 도움을 줌.
< 균형 트리의 개념 >
노드 : B-tree구조에서 데이터가 저장되는 공간. ( = Page in MYSQL)
루트 노드 root node : 가장 상위 노드.
리프 노드 leaf node : 가장 마지막, 하위 단계 노드.
중간 노드 internal node : 루트와 리프 사이 노드.
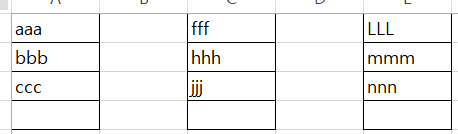
이 그림에서 mmm 데이터를 찾으려면 왼쪽부터, 위에서 아래로 aaa부터 찾아나가야 하며, 결국 페이지 3개를 검색해야 찾을 수 있다.
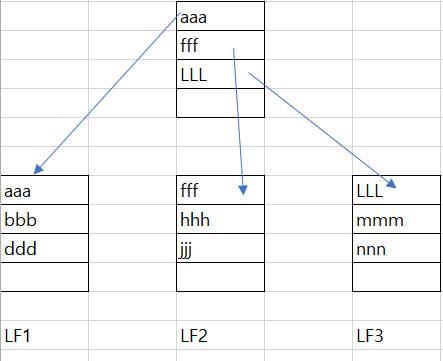
위 그림과 같이 B-tree로 되어있을 경우, 우선 균형트리는 무조건 루트 페이지부터 검색을 시작. 여기서 aaa,fff,LLL을 읽고 바로 LF3으로 이동하면 된다. 간단하게 검색하는 양만 생각하면 Leaf Page만 있는 경우는 8건, B-tree의 경우 5건만 검색하면 됐다. 효율을 보여주는 아주 가벼운 단적인 예시이며, 실제로 이후로는 중요한 것은 데이터의 건수가 아니라 몇 개의 페이지를 읽었느냐로 효율성을 판단한다.
페이지 분할 : 새로운 페이지를 준비해 데이터를 나누는 작업. 발생 시 MYSQL이 느려지며, 너무 자주 일어나면 성능에 큰 영향을 줌. 인덱스 구성 시 데이터 변경 작업 시 성능이 나빠지는 이유.
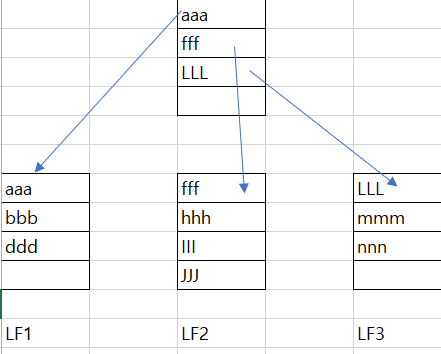
III 데이터가 새로 INSERT 시 LF2에서 jjj가 한 칸 내력고 그 자리에 삽입되면 끝.
여기서 ggg가 새로 입력 시?
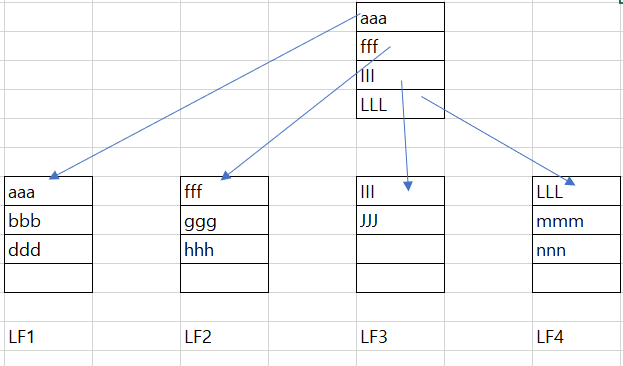
1. new page 확보.
2. 페이지 분할 작업 1회.
3. 루트 페이지에 new page의 제일 상단에 있는 III가 등록.
데이터가 1개 밖에 추가되지 않은 것에 비해 많은 과정을 거치기에 MySQL에 부담이 증가해 성능 저하를 유발. 여기서 ppp,qqq를 추가로 입력 시 총 페이지 수는 8개이며, 더 상위 단계의 루트 페이지와 더 많은 중간과 리프 페이지가 생성.
이런 단적인 예시들을 통해 인덱스를 구성 시 데이터 변경 작업이 느려지는지 확인이 가능.
< 인덱스 구조 - 클러스터형 인덱스 구성 >
인덱스 구조를 통해서 인덱스를 생성 시 왜 데이터가 정렬되며, 어떤 인덱스가 더 효율적인지 살펴보자.
1개의 페이지에 4개의 ROW가 입력된다고 가정하고, 아직 인덱스가 없는 상태로 각 페이지 위에 써진 숫자는 페이지 번호를 임의로 부여.
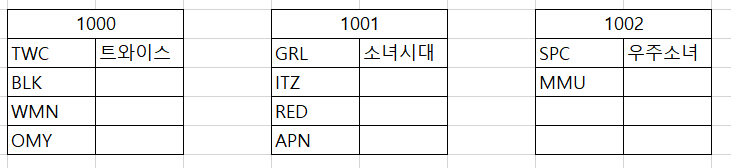
이와 같이 데이터 페이지가 이뤄질거고, 이는 입력된 순서와 동일한 순서.
ALTER TABLE cluster ADD CONSTRAINT PRIMARY KEY (mem_id);해당 라인 추가 시
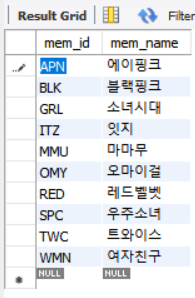
mem_id를 PK로 지정 시 클러스터형 인덱스가 구성되어 mem_id 컬럼을 기준으로 알파벳 순으로 위와 같이 정렬.
그렇다면 실제 데이터는? 데이터 페이지가 정렬되고 균형 트리 형태의 인덱스가 형성됨.
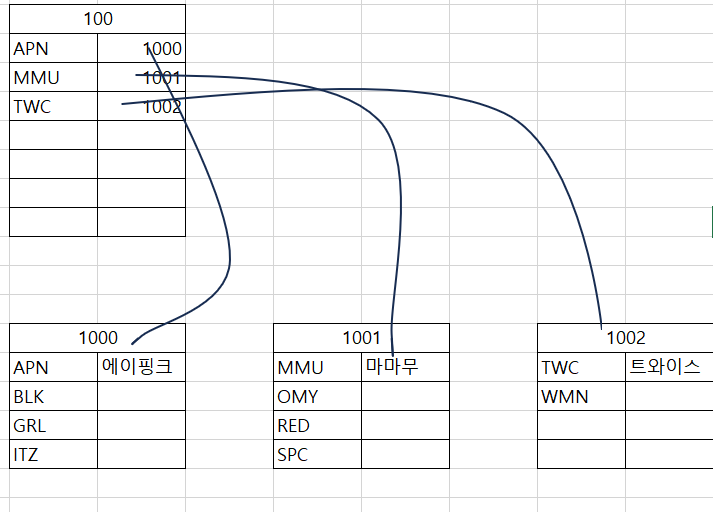
ROW 데이터를 우선 지정할 컬럼으로 정렬하고, 각 페이지의 인덱스로 지정된 컬럼의 첫 번째 값들로 루트 페이지를 만듬.
< 인덱스 구조 - 보조 인덱스 구성 >
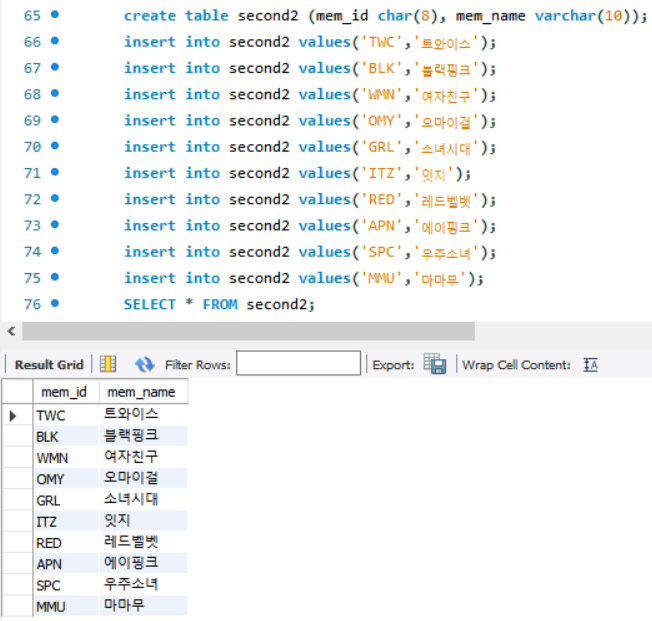
우선 인덱스가 없으니 앞서 본 것처럼 입력 순으로 데이터가 데이터 페이지에 입력됨.
alter table second2 add constraint unique (mem_id);
select * from second2;예상하다시피 보조 인덱스가 mem_id에 생성되어도 실행 결과는 입력 순서와 동일, 즉 변하지 않음. 보조 인덱스는 일반적인 책 처럼, 뒤에 찾아보기를 추가해도 본문은 바뀌지 않듯이 여기선 데이터 페이지를 건드리지 않음.
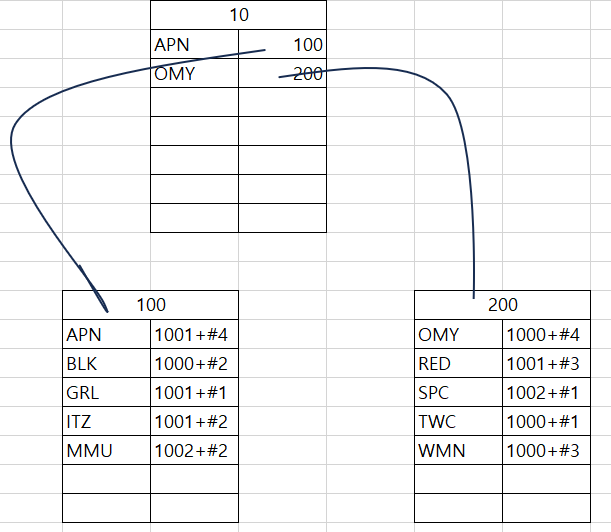
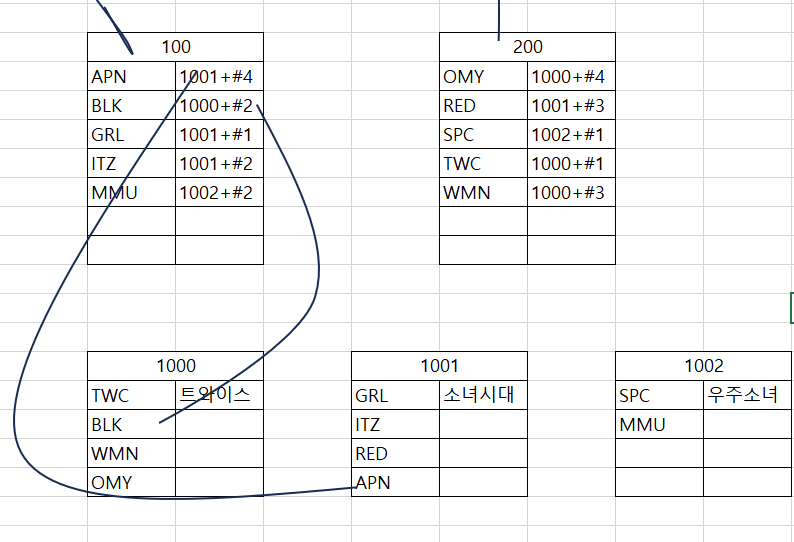
- 인덱스 페이지 ( = 루트 페이지 + 리프 페이지, 여기서는 10,100,200노드 )의 리프 페이지에 (100,200) 인덱스로 구성한 컬럼으로 정렬 (여기선 mem_id).
- 실제 데이터가 있는 위치를 준비하는데, 데이터의 위치는 페이지 번호+#위치로 기록. 예시로 번호 200 리프 페이지에 있는 OMY에 1000+#4는 데이터 페이지 (실제 데이터가 있는 페이지) 1000번의 4번째에 저장되어 있음을 의미.
여기서 데이터를 검색할 시 ( = SELECT 문 ) 다음과 같음. SPC인 회원의 이름을 찾으려면?
< 클러스터형 인덱스에서 검색 >
- 루트 페이지 (100번) 을 읽음.
- SPC는 알파벳 순서로 보면 MMU와 TWC 사이에 위치하니 MMU가 가리키는 리프 페이지 (1001번)으로 이동.
- 내려가면서 검색해서 네 번째에 찾고자 하는 SPC가 있고 이름은 '우주소녀'라는 것을 알아냄.
2개의 페이지를 읽어서 SPC의 이름을 알아냄.
< 보조 인덱스에서 검색>
- 인덱스 페이지의 루트 페이지 (10번) 읽고,
- 그 다음으로 리프 페이지 (200번)을 읽어냄.
- 이후 거기서 데이터 페이지 (1002번) 위치를 알아내서 (by 1002+#1) 해당 페이지에서 읽어내며 SPC를 찾고 그 이름을 알아낸다.
총 3개의 페이지를 읽어서 SPC 이름을 알아냄.
여기서 두 인덱스 모두 검색이 빠르지만 클러스터형 인덱스가 조금 더 빨랐음.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
CREATE [UNIQUE (고유 키)] INDEX name_of_index # 인덱스 생성
ON name_of_table (name_of_column) [ASC | DESC]
DROP INDEX name_of_index ON name_of_table # 인덱스 제거아주 간략한 인덱스 기본 형식.
< 인덱스 생성 >
PK기본 키, Unique고유 키를 설정하면 각각 자동적으로 클러스터형 인덱스, 보조 인덱스가 자동 생성되는 것은 공부했고, 그 외 인덱스를 직접 생성하려면 CREATE INDEX문 (only for 보조 인덱스) 사용.
실제 생성 시 key_part, index_option, index_type, algorithm_option, lock_option등 문법을 추가할 수 있지만, 간단한 내용부터 하나씩 진행하자.
UNIQUE는 중복이 안 되는 고유 인덱스를 만들고, 생략하면 중복이 허용. CREATE UNIQUE로 인덱스를 만드려면 기존 입력된 값들 중 중복이 있으면 안됨. 특성 상 주복될 수 없는 컬럼에 UNIQUE로 지정하는 것이 타당.
< 인덱스 제거 >
DROP INDEX name_of_index ON name_of_table;PK, UNIQUE로 자동 생성된 인덱스는 DROP이 불가. ALTER TABLE문으로 PK나 고유 키를 제거하면 자동 생성된 인덱스 제거 가능.
통상적으로 하나의 테이블에 클러스터형과 보조 인덱스가 모두 있는 경우, 클러스터형을 제거 시 내부적으로 데이터가 재구성되기에 보조 인덱스부터 제거.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ실습ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
데이터 셋은 혼공 자료실에서 가져온 market_db를 활용.
하는 김에 혼공SQL 5주차 기본 미션 수행 : p.310 인덱스 생성하고 key_name이 PRIMARY로 출력된 결과 화면 캡쳐하기
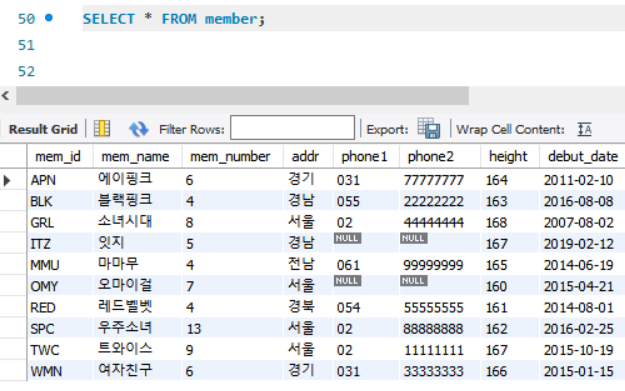

<5주차 기본 미션 수행 완료>
현재 key_name 이 PRIMARY로 자동 생성된 클러스터형 인덱스 1개만 설정되어있다. LIKE는 member라는 글자가 들어간 테이블의 정보를 보자는 의미로, 여기선 member 테이블 하나뿐이니 이 테이블만 추출됨.

SHOW TABLE STATUS문을 통해 인덱스의 크기 확인 가능.
결과 중 Data_length는 클러스터형 인덱스 (or 데이터)의 크기를 Byte 단위로 표기한 것. MySQL의 한 페이지 크기는 기본적으로 16KB로 클러스터형 인덱스는 16,384Byte가 1페이지에 할당.
Index_length는 보조 인덱스의 크기인데 현재 member테이블에 보조 인덱스가 없으니 표기되지 않음.
여기에 addr 컬럼에 중복을 허용하는 단순 보조 인덱스를 생성하고 인덱스의 이름을 idx_member_addr. idx는 Index의 약자로, 이름만 보고도 member 테이블의 addr 열에 지정된 인덱스라고 알 수 있게함.
CREATE INDEX idx_member_addr ON member (addr);결과는

로 Non_Unique = 1인, 중복 데이터를 허용하는 단순 보조 인덱스를 생성한 것을 확인할 수 있다.
단순 보조 인덱스 Simple Secondary Index : 중복 데이터를 허용하는 보조 인덱스. Non_unique = 1
고유 보조 인덱스 Unique Secondary Index : 중복 데이터를 허용하지 않는 보조 인덱스. Non_unique = 0

보조 인덱스가 추가되어도 전체 인덱스 크기인 Index_length는 0으로 나오는데, 이는 생성한 인덱스를 실제로 적용시켜야 나타난다. ANALYZE TABLE문으로 먼저 테이블을 분석 및 처리해야 한다.
ANALYZE TABLE member;
SHOW TABLE STATUS LIKE 'member';
보조 인덱스의 실제 크기는 16KB ( = 16384 Bytes) 보다 작지만 여기선 보조 인덱스가 1건이면 최소 1페이지는 필요하니 1페이지 크기가 표시.
CREATE UNIQUE INDEX idx_member_mem_name
ON member (mem_name);회원 이름 mem_name에 고유 보조 인덱스를 생성한 결과는 아래와 같다.
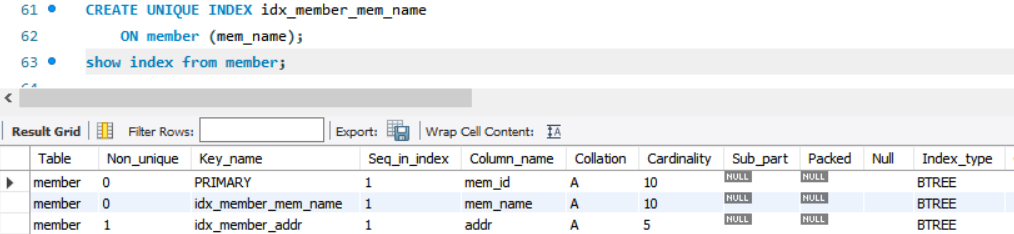
(참고로 mem_number 인원수 컬러에 대해선 고유 보조 인덱스 생성이 불가능하다. 이미 블랙핑크, 마마무, 레드벨벳의 인원수가 4로 중복된 값이 존재.)
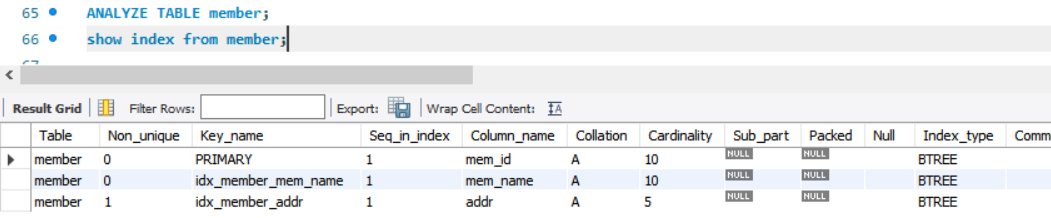
현재 까지 만든 인덱스를 analyze 문을 통해 모두 적용.
인덱스를 사용하려면 인덱스가 생성된 열 이름( 여기선 mem_id, mem_name, addr)이 SQL문에 있어야 함.
select * from member;코드 작성 시 10건의 회원이 조회되는데 여기서 인덱스 사용여부는 결과 중 Execution plan 창을 확인하면 됨.
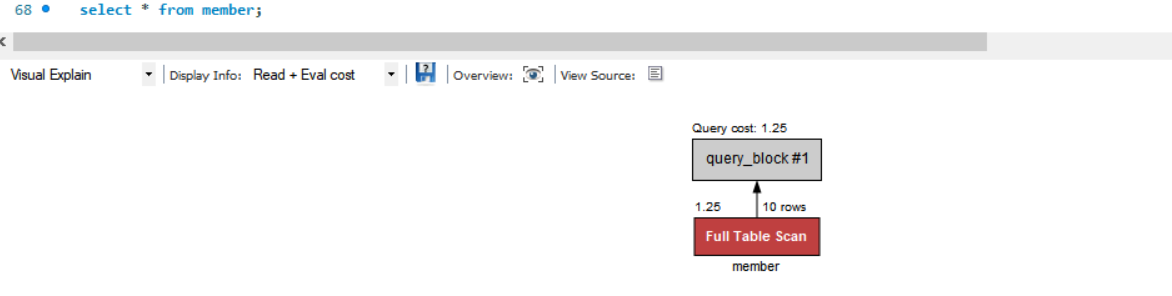
결과는 Full Table Scan, 즉 전체 테이블 검색을 한 것으로 판명. 처음부터 끝까지 다 확인해봤다는 뜻.
그렇다면 인덱스가 있는 열은??
select mem_id, mem_name, addr from member;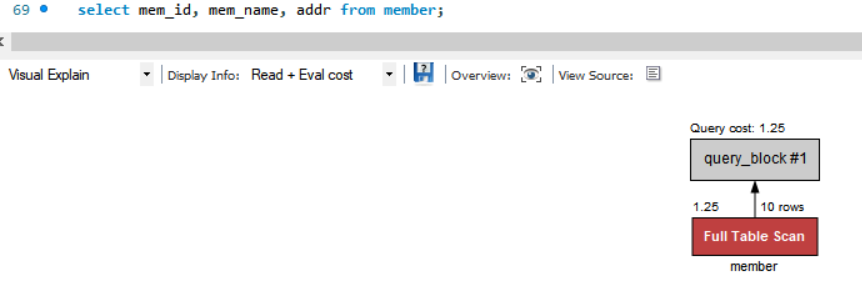
분명 열 이름이 SELECT 다음에 나왔는데 놀랍게도 인덱스를 사용하지 않은 모습..... ( 참고로 Result Grid는 PK인 mem_id에 대해 알파벳으로 정렬되어 나옴. 복습용 ㅎ )
SELECT mem_id, mem_name, addr
FROM member
WHERE mem_name = '에이핑크';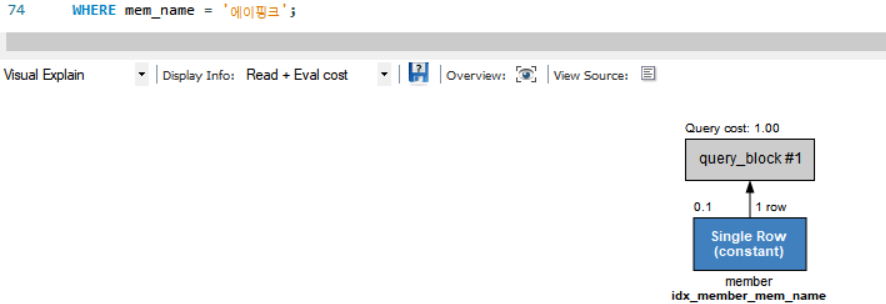
인덱스가 생성된 mem_name 값에 대해 에이핑크를 조회한 결과 당연히 결과는 잘 나오고, 사진으로 보다시피 Execution Plan 창에서 Single Row(constant)로 나와 인덱스를 사용해 결과를 얻었다는 것을 알 수 있다.
위 두 결과를 통해서 WHERE 절에 인덱스 컬럼 이름이 들어있어야 인덱스를 사용한다는 것을 알 수 있다.
CREATE INDEX idx_member_mem_number
ON member (mem_number); #숫자로 구성된 인원수로 단순보조인덱스
ANALYZE TABLE member; # 인덱스 적용
SELECT mem_name, mem_number FROM member WHERE mem_number >=7;
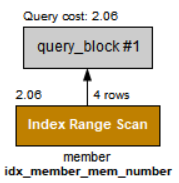
인덱스를 사용한 것을 확인할 수 있다.
어떤 경우에는 인덱스가 있어도 안쓴는데 어떤 이유일까??
SELECT mem_name, mem_number FROM member WHERE mem_number >=1;이 코드를 실행하면 인덱스를 쓴 것이 아닌 FULL TABLE SCAN으로 나오는데 이는 MySQL이 인덱스 검색보다 전체 테이블 검색이 낫겠다고 판단했기 때문.
SELECT mem_name, mem_number FROM member WHERE mem_number*2 >=14;이 코드는 앞에서 >=7과 같은 조건인데 여기서도 FULL TABLE SCAN의 결과로 인덱스를 쓰지 않은 것으로 나온다.
WHERE문에서 "컬럼에"연산이 가해지면 인덱스를 사용하지 않음.
SELECT mem_name, mem_number FROM member WHERE mem_number >=14/2;두 라인은 같은 것을 말하지만, 실행한 결과의 순서가 다름. 여기서는 WHERE절의 컬럼에 연산을 하지 않았기에 인덱스를 사용해 INDEX RANGE SCAN으로 나옴.

지금까지 활용한 인덱스를 제거할 때, 앞서 언급한 것처럼 보조 인덱스를 먼저 제거하는 것이 좋다. 보조 인덱스끼리는 제거 순서가 중요하지 않음.
DROP INDEX idx_member_mem_name ON member;
DROP INDEX idx_member_addr ON member;
DROP INDEX idx_member_mem_number ON member; #보조 인덱스들이후에 PK에 지정으로 자동 생성된 클러스터형 인덱스를 제거.
ALTER TABLE member DROP PRIMARY KEY;
# PK설정된 인덱스는 drop index문으로는 제거불가.이 경우 member 테이블의 mem_id 컬럼을 buy 테이블이 참조하고 있기에 오류가 발생하고 (Error Code : 1533) PK-FK 관계가 있는 경우엔 이 관계를 먼저 제거해야 함.
< PK-FK 관계 제거 >
1. 여러 개일 수 있는 외래 키FK 이름 알아내기
SELECT table_name, constraint_name
FROM information_schema.referential_constraints
WHERE constraint_schema = 'market_db';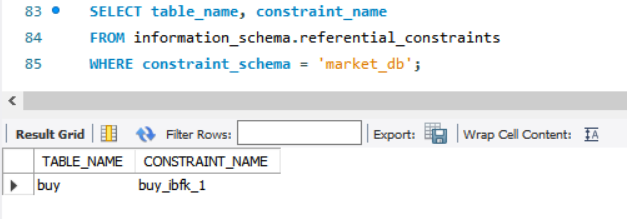
(여기서 information_schema DB 안의 referential_constraints 테이블은 MYSQL 안에 원래 포함되어있는 시스템DB와 테이블.)
- 외래 키 이름을 알았으니 (buy_ibfk_1) 외래 키를 먼저 제거하고 기본 키를 제거.
ALTER TABLE buy
DROP FOREIGN KEY buy_ibfk_1;
ALTER TABLE member
DROP PRIMARY KEY;인덱스의 효과적 사용법
- 열 단위 생성.
- WHERE 절에서 사용되는 열에 인덱스 생성 + 자주 사용하는 테이블 및 컬럼에 활용
- 데이터의 중복이 적은 컬럼에 활용. (ex. M or F 이런데 사용 X)
- 클러스터형 인덱스는 하나만 생성가능하니 조회 시 가장 많이 사용되는 컬럼에!
- 사용하지 않는 인덱스는 제거.
