Chapter 7
SQL은 DB에서 사용되는 언어이며, MySQL안에서 프로그래밍 언어의 기능을 해주는 스토어드 프로시저 Stored Procedure(이하 'SP')는 DB의 개체 중 한 가지로, 테이블처럼 각 DB내부에 저장됨.
SP의 필수 형식은 아래와 같다.
delimiter $$ #$$ 대신 ##,@@,&& 등 가능.
create procedure name_of_SP(In or Out 매개변수)
begin
SQL 프로그래밍 코드 작성
end $$
delimiter;CREATE PROCEDURE는 스토어드 프로시저를 만든 것뿐이며, 실행(호출)은 CALL name_of_SP(); 로 시작.
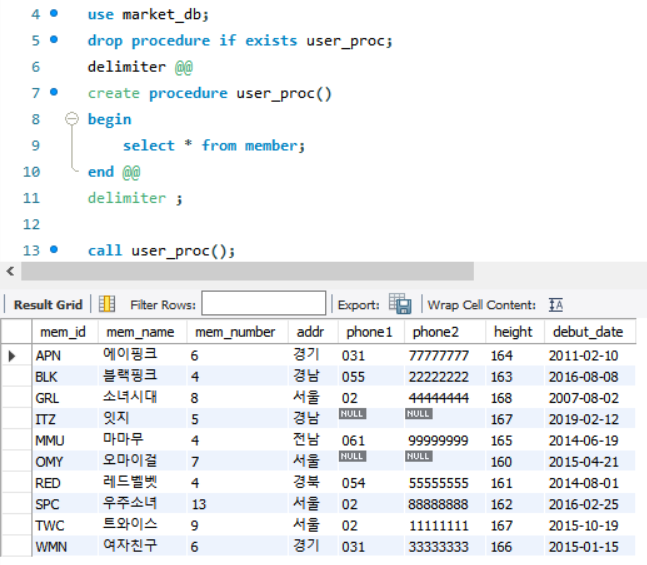
혼공S 예제파일인 market_db를 사용하고, SP를 생성한 모습.
SP의 삭제 : DROP PROCEDURE name_of_SP;
SP 실행 시 입력 매개변수(=파라미터) 지정이 가능하고, 입력 매개변수는 간단히 자판기를 사용할 때 '동전을 넣고 버튼을 누르는 동작'으로 생각하면 편함.
IN 입력_매개변수_이름 데이터_형식 #입력 매개변수 지정
CALL name_of_SP(전달_값); # 입력 매개변수있는 SP실행.SP를 커피 자판기이고, 입력 매개변수를 동전을 넣고 버튼을 누르는 동작이면, 출력 매개변수는 '커피 자판기에서 미리 준비하고 있는 컵'이라고 보면 되며 실행 시 이 비어있던 컵에 커피가 담겨져 돌아옴.
out 출력_매개변수_이름 데이터 형식 # 출력 매개변수의 형식 지정
CALL name_of_SP(@변수명);
SELECT @변수명; #출력 매개변수 값을 대입하기 위해선 주로 SELECT~INTO문을 활용.< 입력 매개변수 활용 >
use market_db;
drop procedure if exists user_proc1;
delimiter @@
create procedure user_proc1(IN userName VARCHAR(10))
BEGIN
SELECT * FROM member WHERE mem_name = userName;
END @@
delimiter ;
call user_proc1('에이핑크');
여기서 입력 매개변수 userName가 있고, 후에 SP 호출 시 '에이핑크'를 입력 매개변수에게 전달.
drop procedure if exists user_proc2;
delimiter @@
create procedure user_proc2(
IN userNumber INT,
IN userHeight INT )
BEGIN
SELECT * FROM member
WHERE mem_number > userNmber AND height > userHeight;
END @@
delimiter ;
CALL user_proc2(6,165);
입력 매개변수는 userNumber, userHeight로 2개.
간단히 파악할 수 있는 내용.
< 출력 매개변수의 활용 >
drop procedure if exists user_proc3;
delimiter @@
create procedure user_proc3(
IN txtValue CHAR(10),
OUT outValue INT # 출력 매개변수 )
begin
INSERT INTO noTable Values(NULL,txtValue);
SELECT Max(id) INTO outValue FROM noTable;
end @@
delimiter ;noTable라는 이름의 테이블에 넘겨 받은 값을 입력하고, id 컬럼의 최대 값을 알아내는 기능. 근데 갑자기 나온 noTable이 대체 뭐지라는 생각으로
desc noTable;실행 시 Error Code : 1146 에러가 발생한다. 당연하게도 noTable을 만든적이 없기 때문인데 그러면 SP user_proc3도 생성 시 오류가 나와야하는게 아닐까? --> SP를 만드는 시점엔 아직 존재하지 않는 테이블을 사용해도 되지만, CALL로 실행하는 시점엔 사용한 테이블이 있어야 함.
그래서 noTable을 만들고
CREATE TABLE IF NOT EXISTS noTable(
id INT AUTO_INCREMENT PRIMARY KEY,
txt CHAR(8)
);SP를 다시 호출하면

이와 같이 나온다.
출력 매개변수의 위치에 @변수명 형태로 변수를 전달하면 그 변수에 결과가 저장된다.
다시 정리해보자.
1. user_proc3라는 SP를 생성하고 입력 매개변수 txtValue, 출력 매개변수 outValue.
2. SP의 내용은 어떤 값(NULL, txtValue)을 입력하면 그 값을 id컬럼과 txt컬럼이 있는 noTable라는 테이블에 INSERT INTO 넣는다.
3. 그래서 noTable에 값이 실행시키거나 할 수록 저장이 될텐데, 여기서 id는 auto_increment이므로 숫자가 계속 커질텐데 그 id 컬럼에서 가장 큰 값을 INTO outValue 즉 출력 매개변수에 넣으라는 의미.
( noTable의 결과는 이 그림과 같다.
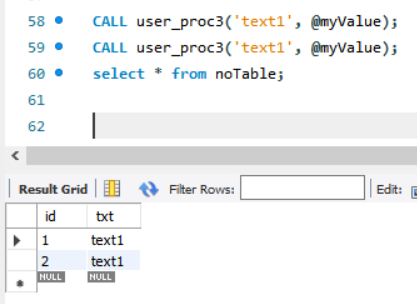
)
4. 그래서 위 그림과 같이 두 번 콜을 하면 Max(id)는 2일테고, 그 값을 @myValue에 넣게된다.
< IF~ELSE문 >
drop procedure if exists ifelse_proc;
delimiter @@
create procedure ifelse_proc(
IN memName VARCHAR(10)
)
begin
DECLARE debutYear INT;
SELECT YEAR(debut_date) into debutYear FROM member
WHERE mem_name = memName;
IF (debutYear >= 2015) THEN
SELECT '신인가수네요 화이팅' AS '메시지';
ELSE
SELECT '고참가수네요 화이팅' AS '메시지';
END IF;
end @@
delimiter ;
CALL ifelse_proc('오마이걸');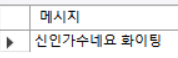
- 입력 매개변수는 memName 하나뿐.
- 내부적으로 잠깐 사용하는 변수 debutYear에 대해서, 입력 매개변수에 입력받은 값(memName)과 같은 mem_name을 member 테이블에서 찾아서 그 Row에서 debut_date 컬럼값을 YEAR()함수를 통해 연도만 추출해서 그 추출값을 debutYear에 저장.
- 그 다음 if ~ else문을 통해서 조건에 맞게 SELECT문이 실행.
drop procedure if exists while_proc;
delimiter @@
create procedure while_proc()
begin
declare hap int; #변수 선언
declare num int;
set hap = 0; #합계 초기화
set num = 1; #숫자 초기화
while (num <= 100) do
set hap = hap + num;
set num = num + 1;
end while;
select hap AS '1~100 합계';
end @@
delimiter ;
call while_proc();
1부터 100까지의 합을 보여주는 SP.
동적 SQL -> 다이나믹하게 SQL이 변경되는데, 아래 예제는 테이블의 조회 기능을 보여주고 그 테이블은 고정되어있는 것이 아니라 테이블의 이름을 매개변수로 전달받아 해당 테이블을 조회.
drop procedure if exists dynamic_proc;
delimiter @@
create procedure dynamic_proc(
IN tableName VARCHAR(20)
)
begin
SET @sqlQuery = CONCAT('select * from ', tableName);
PREPARE myQuery FROM @sqlQuery;
EXECUTE myQuery;
DEALLOCATE PREPARE myQuery;
end @@
delimiter ;
call dynamic_proc('noTable')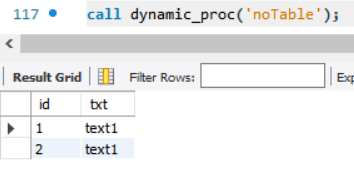
결과로 앞서 활용한 noTable를 입력 매개변수로 넣으면 noTable 테이블을 보여준다.
tableName라는 입력 매개변수를 받고, @sqlQuery라는 출력 매개변수에 CONCAT 내용, 즉 SELECT * FROM noTable(여기선) 를 저장한다.
(동적 SQL은 미리 쿼리문장을 준비한 후에 나중에 실행하는 것을 의미하는데, 여기서 PREPARE 쿼리이름 FROM '쿼리문' 은 쿼리문을 준비하고 실행하지는 않는 것이고, EXECUTE 쿼리이름 이때 쿼리문이 실행된다.)
여기선 동적으로 받을 @sqlQuery 변수에 쿼리문을 저장하고 이거를 myQuery라는 쿼리이름으로 생각하고 준비한 다음(prepare), execute에서 그 쿼리를 실행한다. 그리고 DEALLOCATE 문을 통해서 PREPARE된 Statement인 myQuery를 해제해서 끝낸다.
그래서 이 dynamic_proc는 입력 매개변수와 같은 이름의 테이블을 return 값으로 보여주는 SP이다.
스토어드 함수 (이하 SF) : MySQL에서 제공하는 내장 함수 외 직접 함수를 만드는 기능. 스토어드 프로시저와 비슷해보여도, 세부적으로 용도가 다르고 RETURNS 예약어를 통해서 하나의 값을 반환해야하는 특징이 있다.
커서는 SP 안에서 한 행씩 처리할 때 사용하는 프로그래밍 방식.
< 스토어드 함수 >
DELIMITER $$
CREATE FUNCTION name_of_SF(매개변수)
RETURNS 반환형식
BEGIN
프로그래밍 코딩
RETURN 반환값;
END $$
DELIMITER ;
SELECT name_of_SF();SF와 SP의 차이점
- SF는 RETURNS문으로 반환할 값의 데이터 형식을 정하고, 본문 안에서는 RETURN문으로 하나의 값을 반환해야 함.
- SF의 매개변수는 모두 입력 매개변수이고, IN을 붙이지 않음.
- SP는 CALL로 호출하지만, SF는 SELECT 문 안에서 호출.
- SP 안에서는 SELECT 문 사용 가능, SF 안에서는 SELECT 불가.
- SP는 여러 SQL문이나 계산 등 다용도로 쓰지만, SF는 계산을 통해 하나의 값을 반환하는데 주로 사용.
우선 SF 생성 권한 허용해야 하며, 해당 코드는 아래와 같다. (한 번만 설정하면 OK)
SET GLOBAL log_bin_trust_function_creators = 1;두 수의 합을 계산하는 SF를 만들면
USE market_db;
DROP FUNCTION IF EXISTS sumFunc;
delimiter @@
CREATE FUNCTION sumFunc(number1 INT, number2 INT)
RETURNS INT
BEGIN
RETURN number1 + number2;
END @@
delimiter ;
select sumFunc(100,250) AS '합계';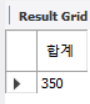
2개의 정수형 매개변수를 전달 받고, 이 함수가 반환할 데이터 형식을 정수로 지정하고 (RETURNS INT), RETURN 문으로 정수형 결과를 반환.
drop function if exists calcyearfunc;
delimiter @@
create function calcyearfunc(dYear INT)
RETURNS int
begin
declare runYear int;
set runYear = YEAR(curdate()) - dYear;
RETURN runYear;
end @@
delimiter ;
SELECT calcyearfunc(2010) as '활동 햇수';결과값은 '활동 햇수 : 13' 으로 나오는데, 분석하면 결과값 데이터타입은 정수형, runYear 변수 선언이후에 그 값을 오늘 날짜 CURDATE()의 YEAR()함수를 추가해 오늘의 연도를 dYear 매개변수 받을 값으로 빼게 하여 활동 햇수를 출력한다.
show create function 함수_이름; # 작성된 SF 내용 확인.
drop FUNCTION 함수_이름; # 해당 SF 삭제.< 커서 >
첫 번째 행을 처리한 후에 마지막 행까지 한 행씩 접근해서 값을 처리.
커서의 작동 순서
1. 커서 선언
2. 반복 조건 선언.
3. 커서 열기.
4. 데이터 가져오기.
5. 데이터 처리하기.
(4ㅡ5 반복)
6. 커서 닫기.
커서는 대부분 SP와 함께 사용하기에 세부 문법을 외우기보다는 사용하는 전반적 흐름을 아래 코드를 통해 살펴보자. 커서를 활용해 가수 그룹의 평균 인원수를 구하고 한 행씩 접근해 회원의 인원수를 누적시키는 방식으로 처리해볼 예정.
1. 사용할 변수 준비
declare memNumber INT; # member 인원수
declare cnt INT DEFAULT 0; # 읽은 행의 수
declare totNumber INT default 0; # 전체 인원 합계DEFAULT 문을 사용해 초기값을 0으로 설정.
declare endOfROW BOOLEAN DEFAULT FALSE;행의 끝을 파악하기 위한 변수 endOFROW를 준비. 처음은 당연히 행의 끝이 아닐텐 FALSE로 초기화.
2. 커서 선언하기
커서는 결국 SELECT문. memberCursor라는 커서는 회원 테이블 (member)을 조회하는 구문을 커서화 시킨 것.
DECLARE memberCursor CURSOR FOR
SELECT mem_number FROM member;3. 반복 조건 선언하기
declare CONTINUE HANDLER
FOR NOT FOUND SET endOFROW = TRUE;declare continue handler 는 반복 조건을 준비하는 예약어.
for not found는 더 이상 행이 없을 때 이어진 문장을 수행하니 행이 더 이상 존재하지 않게되면 endOFROW라는 변수에 TRUE를 SET한다.
4. 커서 열기
open memberCursor;5. 행 반복하기
커서의 끝까지 한 행씩 접근해 반복할 차례.
cursor_loop : LOOP
이 부분을 반복
END LOOP cursor_loopcursor_loop는 반복할 부분의 이름을 지정한 것. 이 반복문을 빠져나갈 조건이 필요하고 앞에서는 행의 끝에 다다르면 endOFROW를 TRUE로 변경하기로 설정했으니 LEAVE 코드가 필수.(하단)
IF endOFROW THEN # endOFROW가 TRUE가 되면, 간단히 이렇게 작성가능.
LEAVE cursor_loop; #cursor_loop라는 루푸를 벗어납니다.
END IF; #이 IF문도 끝낼게요.FETCH는 한 행씩 읽어오는 것. 커서를 선언 시 mem_number 행을 조회했으니 memNumber(하단) 변수에는 각 회원의 인원수가 한 번에 하나씩 저장.
cursor_loop: LOOP
FETCH memberCursor INTO memNumber;
IF endOFROW THEN
LEAVE cursor_loop;
END IF;
SET cnt = cnt + 1;
SET totNumber = totNumber + memNumber;
END LOOP cursor_loop;SET 부분에선 읽은 행의 수 cnt를 하나씩 루프가 돌때마다 증가시키고, 인원 수도 totNumber에 누적.
반복을 빠져나오면 최종 목표인 회원의 평균 인원수를 계산하니 누적된 총 인원수를 읽은 ROW의 수로 나누면 되니
select(totNumber / cnt ) AS '회원의 평균 인원 수';6. 커서 닫기
CLOSE memberCursor;이제 이 단계별 작성 코드를 합쳐 SP안에 작성해야함.
USE market_db;
DROP PROCEDURE IF EXISTS cursor_proc;
DELIMITER @@
CREATE PROCEDURE cursor_proc() #SP선언
BEGIN
DECLARE memNumber INT;
DECLARE cnt INT default 0;
DECLARE totNumber INT default 0;
DECLARE endOFROW BOOLEAN DEFAULT FALSE;
#-----------여기부터 커서시작
DECLARE memberCursor CURSOR FOR #memberCursor라는 커서 선언.
SELECT mem_number FROM member; #커서의 내용
DECLARE CONTINUE HANDLER #반복조건
FOR NOT FOUND SET endOFROW = TRUE; # 더 이상 행이 안보이면? SET이하.
#------------여기까지가 SP내 커서에 대한 정보
OPEN memberCursor; #정의한 커서를 열고
cursor_loop: LOOP # cursor_loop이라는 루푸를 시작.
FETCH memberCursor INTO memNumber; # memberCursor를 fetch를 통해 하나씩 읽어온다. 근데 그 커서는 멤버 테이블에서 멤버 수를 조회.
# 즉 여기서 그 멤버수를 루프를 돌면서 memNumber 변수에 넣는거야.
IF endOFROW THEN # 그러다 하나씩 내려가다 행의 끝에 가면 endOFROW가 FALSE->TRUE로 바뀌면 이제 IF문으로 들어가. 그러면 leave니까 루프를 끝내.
LEAVE cursor_loop; # 행의끝까지 가기 전까진 endOFROW가 계속 FALSE니까 IF문 안으로 못들어가고 SET 문으로 넘어가는거야.
END IF; # IF문을 갔으면 거기서 이제 루프 떠나고 IF문도 END IF로 끝내줘야지.
SET cnt = cnt + 1;
SET totNumber = totNumber + memNumber;
END LOOP cursor_loop; # 위에서 LEAVE 커서루프가 되면 루프를 벗어나고 그 루프문도 END LOOP로 끝내줘야지.
SELECT (totNumber / cnt) AS '회원의 평균 인원 수'; #루프돌며 totNumber와 cnt가 갱신되서 그 값을 나타낼거고.
CLOSE memberCursor; # 커서를 종료시킨다.
END @@
DELIMITER ;
CALL cursor_proc();근데 이건 AVG()와 동일한 기능이지만 단순한 학습용.
커서는 SP안에 코드를 작성하고, 한 행씩 처리하도록 하는 기능이며 그 내용은 SELECT. 그리고 행이 끝날 때까지 반복하고 행의 끝을 판단하기 위한 변수 endOFROW를 준비.
냉정하게는 커서에 대한 추가적인 공부가 필요해보인다.... 당장은 책만 읽어선 FETCH를 포함해 커서의 필요성을 느끼지 못한 한계가 있다.
트리거 Trigger는 자동으로 수행해 사용자가 추가 작업을 잊어버리는 실수를 방지해줌. 직원 테이블에서 사원을 삭제하면 해당 데이터를 '자동으로' 퇴사자 테이블에 들어가도록 설정하는 그런 느낌. 트리거는 데이터의 무결성에 도움을 줌.
트리거는 DML Data Manipulation Language문 (INSERT,UPDATE,DELETE etc)의 이벤트가 발생할 때 작동.
여기서 언급하는 트리거는 AFTER 트리거로, BEFORE 트리거와 작동 방식이 조금 다름.
- sp와 문법 비슷 BUT CALL문으로 직접 실행 불가.
- DML의 이벤트가 발생할 경우에만! 자동 실행.
- IN,OUT 매개변수 사용 불가.
예시)
use market_db;
create table if not exists trigger_table (id INT, txt VARCHAR(10));
insert into trigger_table values(1,'레드벨벳');
insert into trigger_table values(2,'잇지');
insert into trigger_table values(3,'블랙핑크');
DROP TRIGGER IF EXISTS myTrigger;
DELIMITER @@
CREATE TRIGGER myTrigger
AFTER DELETE
ON trigger_table
FOR EACH ROW
BEGIN
SET @msg = '가수 그룹이 삭제됨' ; # 트리거 실행 시 작동되는 코드
END @@
DELIMITER ;임시로 trigger_table을 만들고, myTrigger라는 트리거를 지정하고, AFTER DELETE는 이 트리거는 DELETE 문이 발생한 이후에 작동하라는 의미를 나타내며, ON trigger_table은 이 트리거를 부착할 테이블을 지정했으며, FOR EACH ROW 각 행마다 적용시킨다는 의미고 트리거에는 항상 쓴다고 생각하면 좋고, 트리거가 실제 작동하는건 BEGIN - END까지고 여기선 간단히 @msg 변수에 글자를 대입시킴.
SET @msg = '';
insert into trigger_table values(4,'마마무');
select @msg;
update trigger_table SET txt = '블핑' where id = 3;
select @msg;데이터를 넣든, 바꾸든 실행 결과는
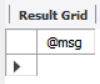
.
하지만 delete 문이 들어가면
delete from trigger_table where id= 4;
select @msg;@msg : 가수그룹이 삭제됨으로 뜸.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
USE market_db;
CREATE TABLE singer (SELECT mem_id, mem_name, mem_number, addr FROM member); # 테이블을 복사해 새로운 테이블 만들기.
#백업 테이블
CREATE TABLE backup_singer
( mem_id CHAR(8) NOT null,
mem_name varchar(10) not null,
mem_number int not null,
addr char(2) not null,
modtype char(2), # 변경된타입. '수정' or '삭제'
moddate date, # 변경된 날짜
moduser varchar(30) # 변경한 사용자
);트리거로 정보를 백업하는 용도로 활용해보려함. market_db에서 고객 테이블에 입력된 정보를 일부 가져와 singer 테이블을 만들고, 이 가수 테이블에서 데이터 변경이 생길 경우 변경되기 전 데이터를 저장할 백업 테이블을 생성하려한다.
drop trigger if exists singer_updateTrg;
delimiter @@
create trigger singer_updateTrg
after update
on singer
for each row
begin
insert into backup_singer values(OLD.mem_id, OLD.mem_name, OLD.mem_number, OLD.addr, '수정', CURDATE(), CURRENT_USER() );
end @@
delimiter ;update시 작동하는 singer_updateTrg 트리거 제작 완료.
OLD 테이블은 MySQL에서 내부적으로 제공하는 테이블로 UPDATE나 DELETE가 수행 시 변경 전 데이터가 잠깐 저장되는 임시 테이블. 하여 위 코드와 같이 UPDATE 문 작동 시 업데이트 되기 전 데이터가 백업 테이블 backup_singer에 입력. CURDATE()는 현재 날짜를, CURRENT_USER()는 현재 작업 중인 사용자를 알려줌.
drop trigger if exists singer_deleteTrg;
delimiter @@
create trigger singer_deleteTrg
after delete
on singer
for each row
begin
insert into backup_singer values( OLD.mem_id, OLD.mem_name, OLD.mem_number, OLD.addr, '삭제', CURDATE(), CURRENT_USER() );
end @@
delimiter ;이번엔 delete시 작동하는 singer_deleteTrg 트리거 제작.
update singer SET addr = '영국' where mem_id = 'BLK';
delete from singer where mem_number >= 7;mem_id가 BLK인 row에서 addr 값을 영국으로 바꾸고, mem_number가 7이상인 row전체를 singer 테이블에서 삭제.
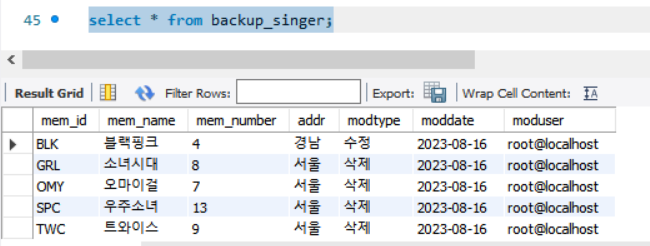
그 결과 백업 테이블에 1건이 수정 4건이 삭제로 알 수 있고 수정이나 삭제 전 데이터가 잘 보관되어있음을 확인할 수 있다.
TRUNCATE TABLE 테이블이름 = DELETE FROM 테이블이름 인데 TRUNCATE는 DELETE 트리거를 작동시키지 않음.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
6주차 기본 미션
혼공SQL 6주차 기본 미션 : p.363 market_db의 고객 테이블 member에 입력된 회원의 정보가 변경될 때 변경한 사용자, 시간, 변경 전의 데이터 등을 기록하는 트리거 작성하고 인증하기.
# 코드 전문
USE market_db;
select * from member;
#백업 테이블
drop table if exists backup_member;
CREATE TABLE backup_member
( mem_id CHAR(8) NOT null,
mem_name varchar(10) not null,
mem_number int not null,
addr char(2) not null,
phone1 CHAR(3),
phone2 CHAR(8),
height SMALLINT,
debut_date DATE,
modtype char(2), # 변경된타입. '수정' or '삭제' or '삽입'
moddate date, # 변경된 날짜
moduser varchar(30) # 변경한 사용자
);
select * from backup_member;
#update 트리거
drop trigger if exists member_updateTrg;
delimiter @@
create trigger member_updateTrg
after update
on member
for each row
begin
insert into backup_member values(OLD.mem_id, OLD.mem_name, OLD.mem_number, OLD.addr,
OLD.phone1, OLD.phone2, OLD.height, OLD.debut_date, '수정', CURDATE(), CURRENT_USER() );
end @@
delimiter ;
#delete 트리거
drop trigger if exists member_deleteTrg;
delimiter @@
create trigger member_deleteTrg
after delete
on member
for each row
begin
insert into backup_member values(OLD.mem_id, OLD.mem_name, OLD.mem_number, OLD.addr,
OLD.phone1, OLD.phone2, OLD.height, OLD.debut_date, '삭제', CURDATE(), CURRENT_USER() );
end @@
delimiter ;
# 데이터 수정 및 삭제
update member SET addr = '영국' where height >= 160;
select * from member;
select * from backup_member;
#PK-FK 관계 삭제.
ALTER TABLE buy
DROP FOREIGN KEY buy_ibfk_1;
ALTER TABLE member
DROP PRIMARY KEY;
delete from member where debut_date < '2010-03-05'; # 여기서 삭제는 PK-FK 관계를 삭제해야 가능.
select * from member;
select * from backup_member;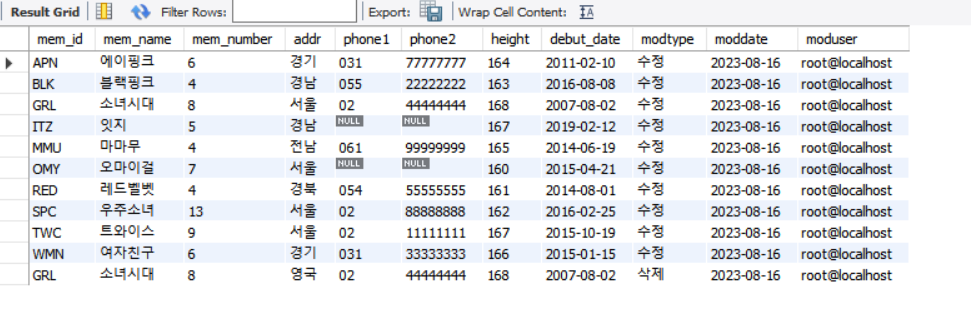
최종 Result Grid. 기본 미션 완료.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
완주 소감
혼공학습단 10기 활동 회고 페이지 링크를 남길 예정.
