Chpater 3
DB안에 Table 외 여러 개체가 필요. 모든 DB 개체들은 독립적인 것이 아닌 Table관 연관성을 지님.
-
인덱스 Index : 데이터 조회 시 속도 상승시켜줌.
'찾아보기'와 비슷한 개념으로 데이터가 정말 많을 때, 모든 데이터를 찾아보는 것이 아닌 사전처럼 앞자리르 확인하는 등의 방식으로 탐색의 속도를 높여줌.
(자세한 내용은 추후에 작성.) -
뷰 View : 테이블의 일부를 제한적으로 표현 시 사용.
가상의 테이블로서, 일반 사용자는 테이블과 뷰를 구분할 수 없다. 사용자는 동일하게 취급하면 되지만, 뷰는 실제 데이터를 갖고있지 않고 실제 테이블에 연결(Link)된 개념임. -
스토어드 프로시져 Stored Procedure : SQL에서 프로그래밍을 가능케 해줌.
일반 프로그래밍 언어처럼 코딩을 할 수 있게함. MySQL에서 제공하는 프로그래밍 기능으로, 여러 SQL문을 묶어 편리하게 사용 가능. (자세한 내용은 추후에 작성.) -
트리거 Trigger : 잘못된 데이터가 들어가는 것을 방지.
SELECT 문 : 테이블 내 데이터 추출 기능.
기본 형식 : SELECT 'column name' FROM 'table name' WHERE '조건식';
SQL문법을 공부하기 위해 혼공SQL 사이트 내 자료실에서 maket_db를 활용해 인터넷 마켓 DB을 구성한다.
DROP DATABASE IF EXISTS market_db; -- 만약 market_db가 존재하면 우선 삭제한다.
CREATE DATABASE market_db;
USE market_db;
CREATE TABLE member -- 회원 테이블
( mem_id CHAR(8) NOT NULL PRIMARY KEY, -- 사용자 아이디(PK)
mem_name VARCHAR(10) NOT NULL, -- 이름
mem_number INT NOT NULL, -- 인원수
addr CHAR(2) NOT NULL, -- 지역(경기,서울,경남 식으로 2글자만입력)
phone1 CHAR(3), -- 연락처의 국번(02, 031, 055 등)
phone2 CHAR(8), -- 연락처의 나머지 전화번호(하이픈제외)
height SMALLINT, -- 평균 키
debut_date DATE -- 데뷔 일자
);
CREATE TABLE buy -- 구매 테이블
( num INT AUTO_INCREMENT NOT NULL PRIMARY KEY, -- 순번(PK)
mem_id CHAR(8) NOT NULL, -- 아이디(FK)
prod_name CHAR(6) NOT NULL, -- 제품이름
group_name CHAR(4) , -- 분류
price INT NOT NULL, -- 가격
amount SMALLINT NOT NULL, -- 수량
FOREIGN KEY (mem_id) REFERENCES member(mem_id)
);
INSERT INTO member VALUES('TWC', '트와이스', 9, '서울', '02', '11111111', 167, '2015.10.19');
INSERT INTO member VALUES('BLK', '블랙핑크', 4, '경남', '055', '22222222', 163, '2016.08.08');
INSERT INTO member VALUES('WMN', '여자친구', 6, '경기', '031', '33333333', 166, '2015.01.15');
INSERT INTO member VALUES('OMY', '오마이걸', 7, '서울', NULL, NULL, 160, '2015.04.21');
INSERT INTO member VALUES('GRL', '소녀시대', 8, '서울', '02', '44444444', 168, '2007.08.02');
INSERT INTO member VALUES('ITZ', '잇지', 5, '경남', NULL, NULL, 167, '2019.02.12');
INSERT INTO member VALUES('RED', '레드벨벳', 4, '경북', '054', '55555555', 161, '2014.08.01');
INSERT INTO member VALUES('APN', '에이핑크', 6, '경기', '031', '77777777', 164, '2011.02.10');
INSERT INTO member VALUES('SPC', '우주소녀', 13, '서울', '02', '88888888', 162, '2016.02.25');
INSERT INTO member VALUES('MMU', '마마무', 4, '전남', '061', '99999999', 165, '2014.06.19');
INSERT INTO buy VALUES(NULL, 'BLK', '지갑', NULL, 30, 2);
INSERT INTO buy VALUES(NULL, 'BLK', '맥북프로', '디지털', 1000, 1);
INSERT INTO buy VALUES(NULL, 'APN', '아이폰', '디지털', 200, 1);
INSERT INTO buy VALUES(NULL, 'MMU', '아이폰', '디지털', 200, 5);
INSERT INTO buy VALUES(NULL, 'BLK', '청바지', '패션', 50, 3);
INSERT INTO buy VALUES(NULL, 'MMU', '에어팟', '디지털', 80, 10);
INSERT INTO buy VALUES(NULL, 'GRL', '혼공SQL', '서적', 15, 5);
INSERT INTO buy VALUES(NULL, 'APN', '혼공SQL', '서적', 15, 2);
INSERT INTO buy VALUES(NULL, 'APN', '청바지', '패션', 50, 1);
INSERT INTO buy VALUES(NULL, 'MMU', '지갑', NULL, 30, 1);
INSERT INTO buy VALUES(NULL, 'APN', '혼공SQL', '서적', 15, 1);
INSERT INTO buy VALUES(NULL, 'MMU', '지갑', NULL, 30, 4);
SELECT * FROM member;
SELECT * FROM buy;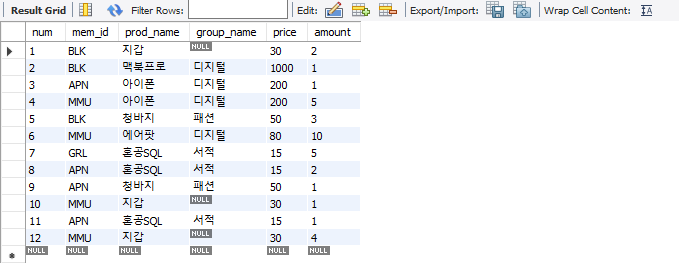
Result Grid로 결과를 보면 위와 같이 나온다.
<<market_db.sql 을 통해 내용 살피기>>
(1)
DROP DDATABSE IF EXISTS market_db;
CREATE DATABASE market_db;drop 라인은 만약에 사전에 market_db가 존재한다면, 지우고 두 번째 create 라인에서 market_db 데이터베이스를 생성한다.
(2)
회원 member 테이블 만들기.
USE market_db;
CREATE TABLE member -- 회원 테이블
( mem_id CHAR(8) NOT NULL PRIMARY KEY, -- 사용자 아이디(PK)
mem_name VARCHAR(10) NOT NULL, -- 이름
mem_number INT NOT NULL, -- 인원수
addr CHAR(2) NOT NULL, -- 지역(경기,서울,경남 식으로 2글자만입력)
phone1 CHAR(3), -- 연락처의 국번(02, 031, 055 등)
phone2 CHAR(8), -- 연락처의 나머지 전화번호(하이픈제외)
height SMALLINT, -- 평균 키
debut_date DATE -- 데뷔 일자
);Use 라인은 market_db라는 데이터베이스를 사용하겠다는 의미.
그 안에서 CREATE TABLE member 는 member라는 테이블명을 가진 테이블을 market_db 데이터베이스 안에 만들거라는 의미.
이후 괄호 안에 mem_id ~ debute_date 는 테이블 내 들어갈 column을 보여주며, 각각의 속성을 정의한다.
이어서 만들어지는 CREATE TABLE buy인 구매 테이블도 같은 방식으로 생성.
(3)
테이블을 생성 후 내부 column들을 정의하면 데이터를 입력하고 이때 INSERT 문을 활용한다.
상단에도 적었고 설명을 위해 하나의 라인을 가져와보자.
INSERT INTO member VALUES('TWC', '트와이스', 9, '서울', '02', '11111111', 167, '2015.10.19');INSERT INTO '데이터를 입력할 테이블 이름' VALUES('입력할 데이터');
의 형식을 보여준다. 상단 mem_id 부터 debut_date 까지 그 순서에 맞게 VALUES 괄호 안에 작성하면 된다.
이는 1회차에서 공부한 'Select Rows - Limit 1000'과 동일한 퍼포먼스를 보여주며, 1회차의 경우 워크벤치를 통해서 작성했다면 이번 방법은 SQL문을 활용해 데이터를 넣었다고 보면 된다.
(4)
입력하여 만들어진 DB에 대해 SQL문을 활용해 원하는 조건에 따라 데이터를 조회하면 되고, 앞으로 이에 대한 공부를 진행한다.
<< 기본 SQL문>>
- 먼저 사용할 DB를 정하고, 이는
USE DB이름;와 같이 입력. 이후 추가적인 use 문을 사용하기 전까진 동일한 DB에서 작업한다.
(번외) 『SQL문의 전체적 구조』
SELECT 열이름
FROM 테이블이름
WHERE 조건식
GROUP BY 열이름
HAVING 조건식
ORDER BY 열이름
LIMIT 숫자큰 틀은 이렇게 되며 중간중간 필요에 따라 생략이 가능하고, 이번 주차에서는 기본적인 형식을 공부한다.
SELECT * FROM member;'' 은 ALL, 즉 모든 것을 의미함. SELECT '' 은 select 이후 열이 나오므로 모든 column을 의미함.
from member은 member 테이블에서 가져온다는 뜻.
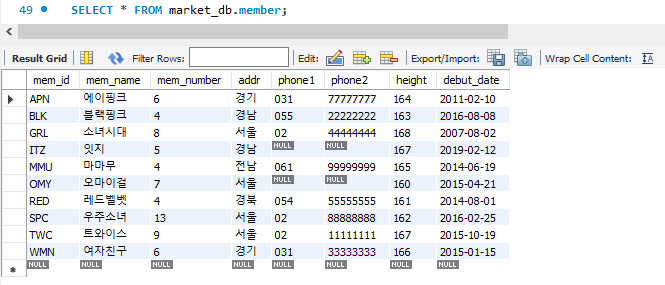
정확한 테이블의 이름은 'DB의 이름.Table의 이름' 으로 정의되기에 위처럼 market_db.member 로 작성해도 동일한 결과를 보여주는 것을 확인할 수 있다.
SELECT mem_name FROM member;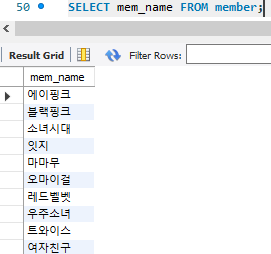
SELECT 이후 * 대신 column 이름을 쓰면 해당 컬럼 내용이 나온다.
SELECT mem_name, debut_date "데뷔 일자" FROM member;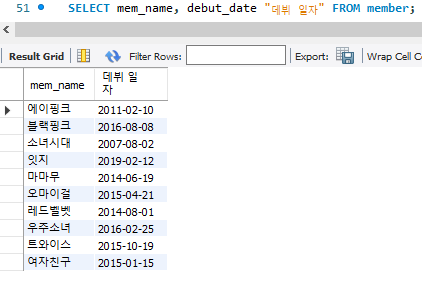
해당 코드에서 알 수 있는 점 : 추가적인 column 데이터를 알고 싶다면 , 을 쓰고 추가적으로 적으면 되며 / column 이름 이후에 "" 을 적으면 해당 column name(debut_name)에 대해 새 이름(데뷔 일자)로 데이터가 추출됨.
SELECT * FROM member WHERE mem_name = "블랙핑크";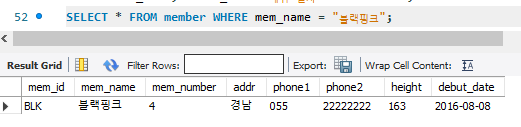
SELECT * FROM member WHERE mem_number = 5;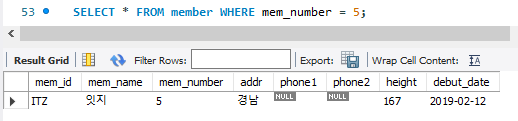
WHERE절은 조건식으로 해당 조건에 맞는 데이터를 보여준다. 위와 더불어 관계연산자( >,<,>=,<=,=,!= ), 논리연산자(not, and, or) 을 활용할 수도 있다.
SELECT mem_name, height, addr "어드레스" FROM member WHERE height >=150 OR mem_number <7;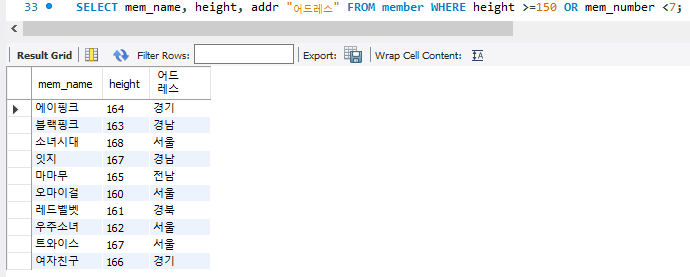
OR, AND, NOT 등 간단하게 위와 같이 작성할 수 있으며, OR을 여러 쓸 경우 IN() 을 쓰면 편리하다.
SELECT mem_name, addr FROM member WHERE addr IN('경기','전남','경남');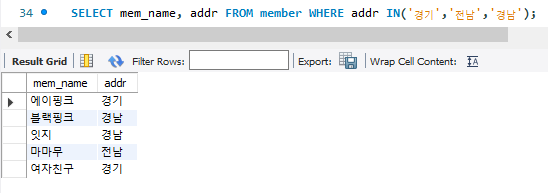
LIKE() 는 일부 글자 검색 기능.
% : 그 뒤는 무엇이든 허용한다는 의미.
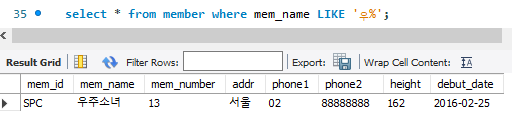
select * from member where mem_name LIKE '우%';해당 조건은 제일 앞 글자가 '우'이며 그 뒤는 상관없다(%)의 의미.
select * from member where mem_name LIKE '__이%';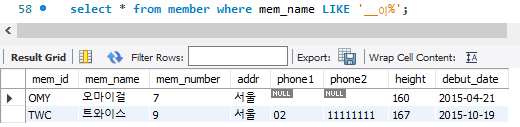
'이%' 의 경우 앞 두 글자는 상관없고 세 번째 글자가 '이' 이며 그 이후도 상관없다는 뜻. 따라서 '이'라고 바꿔서 출력 요청 시 어떤 데이터도 나오지 않는다.
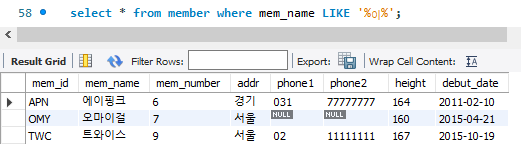
'%이%'로 작성시 단순히 '이'라는 글자만 들어가있으면 출력되게 된다는 것을 알 수 있다.
문자열 비교 시 모두 허용할 경우엔 %, 하나로 지정할 때는 _를 사용.
GROUP BY : 지정한 열의 데이터들을 같은 데이터끼리 묶어서 결과를 추출. GROUP BY절에서 HAVING 절을 통해 조건식 추가가 가능. 조건식이라는 점에서 WHERE절과 비슷하지만, group by절과 함께 사용된다는 것이 차이점.
ORDER BY절 : 결과의 값이나 개수에 영향을 주지는 않지만, 결과가 출력되는 순서를 조절한다.
SELECT mem_id, mem_name, debut_date FORM member ORDER BY debut_date DESC;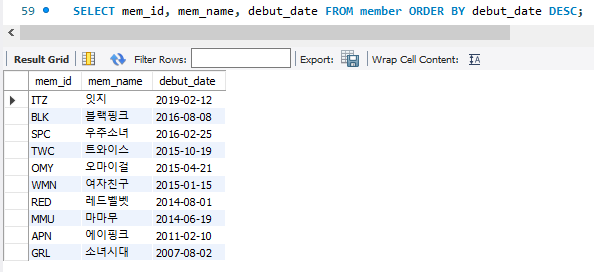
오름차순 ASC가 기본 Default이며, DESC는 내림차순을 의미. 위 사진에서 자료가 정리된 것을 보면 debut_date에서 2019년부터 2007년으로 내림차순으로 정리된 것을 볼 수 있다.
SELECT mem_id, mem_name, debut_date "데뷔날짜", height FROM member WHERE height>= 164 ORDER BY height DESC, debut_date;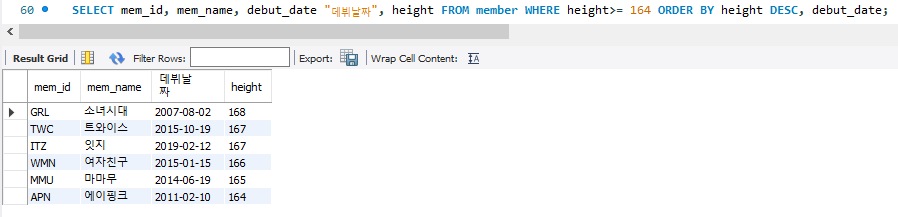
본 코드는 height가 164 이상인 mem_id, mem_name, debut_date, height를 보여주며 그 안에서 height에 대해 내림차순으로 우선 정리하고 같은 height 안에서 debut_date 에 대해 오름차순으로 정리 (2015-10-19 -> 2019-02-12).
LIMIT : 출력 개수 제한.
SELECT mem_name, height FROM member ORDER BY height DESC LIMIT 5,3;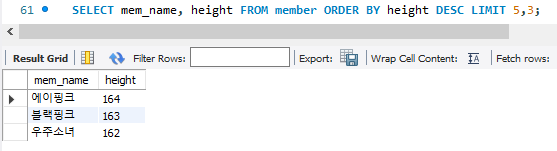
LIMIT 시작, 개수의 의미로 위에 코드에 경우 debut_date에 대해 내림차순으로 정리하고, 5번째부터 시작해서 3개를 보여주는 코드.
DISTINCT() : 중복된 데이터 1개만 남기고 제거.
SELECT DISTINCT addr FROM member;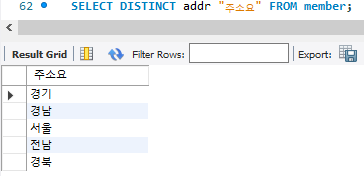
GROUP BY절 : 그룹으로 묶어주는 역할. 주로 그룹으로 묶어서 평균, 합계 등 처리를 진행하기에 집계함수와 같이 씀.
집계함수 : SUM() / AVG() / MIN() / MAX() / COUNT() Row 개수를 셈./ COUNT(DISTINCT) Row 개수를 셈 (중복은 1개만)
SELECT mem_id "회원 아이디", SUM(amount) "총 구매 개수" FROM buy GROUP BY mem_id;본 코드는 각 회원mem_id 별로 구매한 개수를 합쳐서 출력하기 위함. 이에 따라 회원별로 mem_id에 따라 묶고, amount에 대해 집계함수 AMOUNT를 활용. 이에 대한 결과는 아래와 같다.
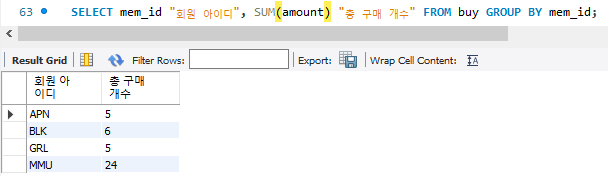
참고로 buy 테이블에 대한 정보는 아래와 같다.
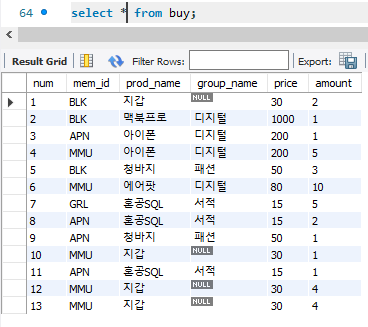
어떤 것을 중심으로 grouping 을 하고 싶은지 그것을 group by 이후에 쓰면 된다. 만약 구매한 금액의 총합을 알고 싶다면?
SELECT mem_id "회원 아이디", SUM(price * amount) "총 구매 금액" FORM buy GROUP BY mem_id;count(*) 는 모든 행의 개수를 세고, count(column_name)은 열 이름의 값이 NULL인 것을 제외한 행의 개수를 센다.
SELECT mem_id "회원 아이디", SUM(price * amount) "총 구매 금액" FROM buy GROUP BY mem_id HAVING SUM(price * amount) > 1000;
멤버 중에 총 구매금액이 1000이상인 회원을 추리는 SQL문. having은 where과 비슷한 개념으로 조건을 제한하지만, 집계 함수에 대해 조건을 제한한다. + having절은 꼭! group by절 다음에 나와야한다.
**혼공SQL 2주차 필수과제 : p.138 확인문제 인증.
SELECT * FROM member ORDER BY height;member 테이블에서 height에 대해 오름차순으로 정리해서 모든 컬럼을 보여주라는 SQL문.
SELECT * FROM member LIMIT 5.2;처음 5.2개의 행을 반환하라는 개념이지만, 해당 코드를 작성 시 정수 limit 이후 정수값이 아니기에 오류가 난다.
SELECT DISTINCT phone1 FROM member;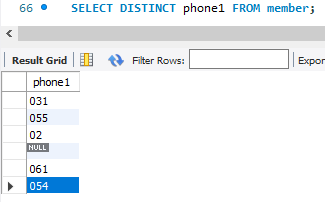
member 테이블에서 phone1 컬럼에 대해 해당 컬럼에서 중복값은 하나만 나오게 데이터를 추출하는 SQL문.
INSERT문 : 테이블에 데이터 삽입하는 명령어.
INSERT INTO 테이블 [(col1,col2,.......)] VALUES (값1, 값2,.....)테이블 이후 열은 생략이 가능하고, 이 경우에는 반드시 values 안에 나오는 값들의 순서 및 개수는 테이블의 열 순서 및 개수와 동일해야 함.
테이블 명 다음 입력을 원하는 컬럼을 () 안에 쓰고, values 안에 이에 해당하는 값만 쓸 수 있다. 이 경우 입력을 받지 않은 컬럼에 대해서는 NULL값이 들어감.
기본적으로 col1, col2,.....와 값1, 값2,....이 대응된다고 보면 되므로 sql문에서 순서가 맞게만 적으면 되서 굳이 테이블 컬럼 순이 아니여도 그에 맞게 값이 대응만 되면 문제가 없다.
AUTO_INCREMENT : 열을 정의 시 1부터 증가하는 값을 입력해줌. 이 auto increment로 지정하는 column은 꼭 Primary Key PK로 지정해줘야 함.
CREATE TABLE hg2 ( toy_id INT AUTO_INCREMENT PRIMARY KEY, toy_name CHAR(4), age INT);
INSERT INTO hg2 VALUES( NULL, 'aaa',25);
INSERT INTO hg2 VALUES( NULL, 'bbb',23);
INSERT INTO hg2 VALUES( NULL, 'ccc',26);
select * from hg2;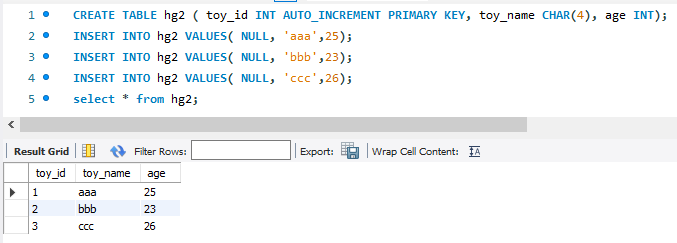
toy_id 컬럼을 자동 증가로 설정하고, 이 부분은 데이터를 입력시 NULL로 채워놓으면 된다.
CREATE TABle hg3 ( toy_id INT AUTO_INCREMENT PRIMARY KEY, toy_name CHAR(4), age INT);
ALTER TABLE hg3 AUTO_INCREMENT=1000;
SET @@auto_increment_increment=3;DB내 hg3라는 테이블을 만들고, 컬럼 지정. alter table은 테이블을 변경하라는 의미로, 컬럼 명 변경 / 새 컬럼 정의 / 컬럼 삭제 등 작업.
hg3 테이블에 대해 시작값을 1000으로 지정하고, 증가값은 3이라고 보여주는 코드.
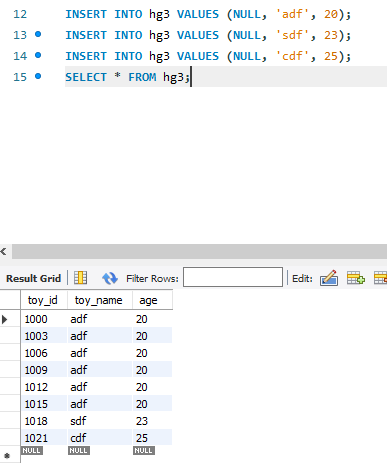
결과는 위와 같이 toy_id 에서 인덱스가 3씩 증가한다. Result Grid의 경우 line No.12 를 복수 실행한 결과로 결과적으로 코드는 제대로 나온 것을 알 수 있다.
INSERT INTO 테이블_이름 VALUES (값1, 값2,....), (값3, 값4, ......), (값5, 값6, .......);이렇게 1줄로 작성해도 데이터는 정상입력된다.
『데이터가 입력되어있는 타 테이블에서 가져오기』
INSERT INTO 테이블_이름 (col_name1, col_name2,...)
SELECT 문;
mysql 설치 시 자동 생성된 world DB의 city Table를 활용할 옞ㅇ.
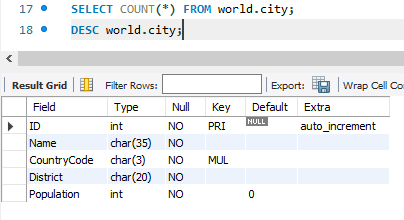
DESC : 테이블의 구조 파악.
city 테이블에서 Name과 Population 데이터를 가져오자.
CREATE TABLE city_popul (city_name CHAR(35), population INT);
INSERT INTO city_popul SELECT Name, Population FROM world.city;
SELECT * FROM city_popul limit 5;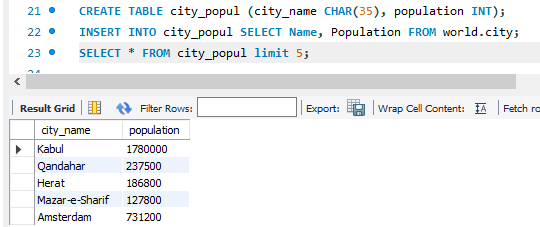
데이터를 받을 테이블 city_popul을 만들고, 그 다음 라인에서 데이터를 받고, 5Rows 를 표시하는 코드.
데이터 수정 (UPDATE)
UPDATE 테이블_이름 SET row1 = 값1, row2 = 값2,....
where 조건;기본적인 형식이며, 앞서 생성한 city_popul 에서 city_name 중 Seoul -> 서울 로 바꿔보자.
UPDATE city_popul SET city_name = '서울' WHERE city_name = 'Seoul';콤마로 분리해서 여러 열 변경도 가능 ex) SET city_name ='뉴욕', population = 0 where city_name = 'New York';
UPDATE city_popul SET population = population / 10000;
SELECT * FROM city_popul limit 10;UPDATE 문에서 WHERE 절이 없으면 테이블 내 모든 ROW의 값이 변경되니 조심해야 함. 위 코드는 모든 population column을 10,000을 나눠 만명 단위로 변경되어 볼 수 있게하는 코드.
데이터 삭제 DELETE
DELETE FROM Table_Name WHERE 조건;city_popul 테이블에서 'New'로 시작하는 도시를 삭제하려한다?
DELETE FROM city_popul WHERE city_name LIKE 'New%';

잘봤습니다.