
저번 시간에 우리는 데이터 타입에 따라 메모리 할당과 메모리 주소 포인터가 어떻게 변화하는지에 대해 알아보았다. 이번시간에는 JS엔진 런타임 환경과 관련하여 데이터가 구체적으로 어떻게 메모리에 할당되는지, 데이터 구조 등에 대해 알아보자.
Run Time
우리는 Run Time 환경을 살펴보며, 프로그램이 어떻게 동작하는지 알 수 있다.
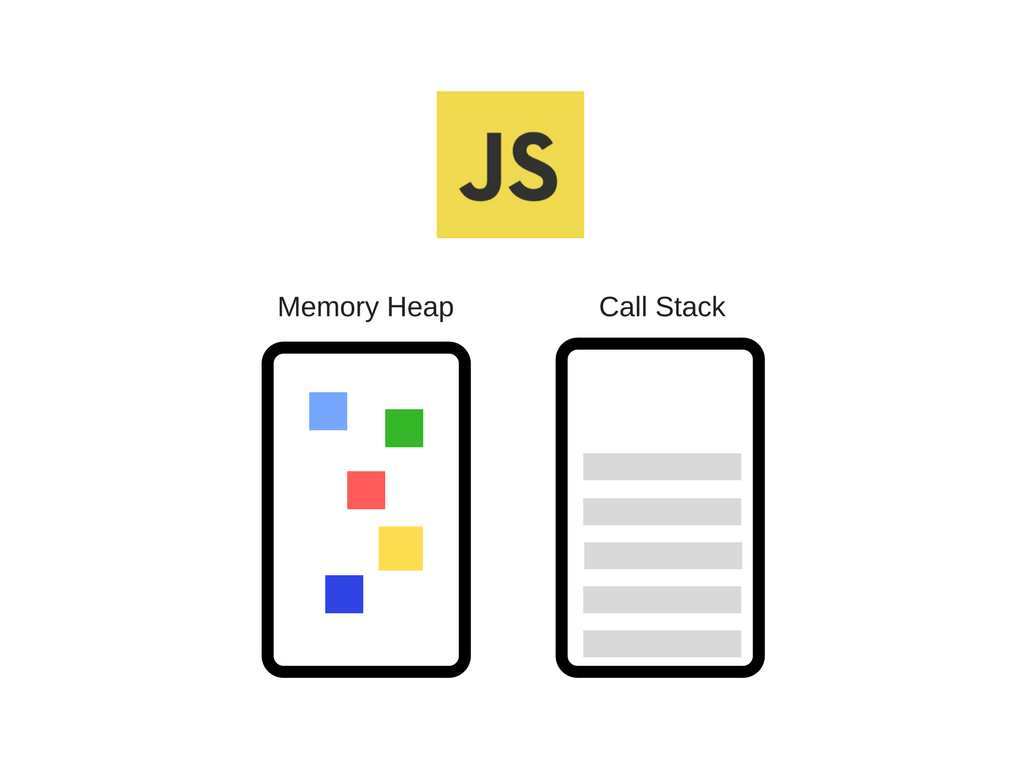
JS Run Time은 총 두가지의 메모리 영역을 가진다.
- Call Stack
- Memory Heap
여기서 Stack 과 Heap 은 각각 자료구조의 명칭인데
JS 는 해당 자료구조들을 사용하여 런타임 환경을 구축한다.
결과적으로 말하면, Call Stack에서는 JS 각 실행 컨텍스트들을 불러와 연산을 처리하고, Memory Heap에서는 동적인 데이터 할당을 가능하게끔 유연한 메모리 할당과 최적화, 정렬등을 담당한다.
즉 Call Stack에서는 연산에 필요한 데이터, 혹은 연산이 끝난 데이터들을 Memory Heap 에서 가져와 쓸 수도 있고, Memory Heap에 저장할 수도 있다.
Call Stack
Call Stack은 말 그대로 스택을 call 하는 부분이다.
그리고 JS에서 스택 하나하나는 모두 실행 컨텍스트이다.
Stack은 LIFO ( Last In First Out )구조를 가지는데, 제일 마지막에 들어간 데이터는 제일 처음에 나온다.
콜 스택은 위 3줄로 설명할 수 있지만, 말로만 들어선 이해하기 어려우니 예시를 한번 살펴보자.
ex)
foo = (a,b) => {
return a * b;
}
bar = (n) => {
return foo(n ,n);
}
baz = (n) => {
let result = bar(n);
console.log(result);
}
baz(3)

전역 실행 콘텍스트
먼저 기본적으로 JS파일이 실행될때,
main() 인 전역 실행 콘텍스트 ( Global Execution Context ) 가 스택에 자리하게 되며, 브라우저나 앱이 종료될 때 사라진다.
즉 전역 실행 콘텍스트는 가장 먼저 stack에 들어오고, 가장 나중에 stack에서 나간다.
이것이 바로 스택 자료구조의 기본 개념인 LIFO이며 Stack 즉 위로 쌓아 올리는 자료 구조이기 때문에, 위에 쌓아 올린 것을 다 빼야 가장 아래의 것을 뺄 수 있는 것이다.
마치 젠가를 무너뜨리지 않고 해체하려면 가장 위에것 부터 빼야 하듯이 말이다.
전역 실행 콘텍스트는 코드가 실행될때 단 한개만 정의된다.
이런 전역 실행 콘텍스트에는 무엇이 들어갈까?
바로 우리가 전역 환경에 선언한 변수나 함수등이 바로 전역 실행 콘텍스트에 들어갈 것이다.
그렇기에 전역 실행 콘텍스트는 코드가 실행될때 단 한개만 정의되며 전역 렉시컬 환경을 가진 유일한 실행 콘텍스트가 되는 것과 동시에 유일하게 전체 코드의 흐름을 가지고 있는 실행 콘텍스트가 될 것이다.
함수 실행 콘텍스트
JS에서 함수는 일종의 동작을 가르킨다. 즉 실행의 기초 단위이다.
전역 환경에서
baz(3)
가 호출 되었음으로

Call Stack에는 baz(3)이라는 실행 콘텍스트가 main() 전역 실행 콘텍스트 위에 스택구조로 쌓이게 된다.
이 후
baz = (3) => {
let result = bar(3); // 호출
// console.log(result); <- 이해를 돕기 위한 주석처리,
// baz(3)을 실행할때 result를 읽게되고 bar(3)을 먼저 호출하게 된다.
}
baz(3)는let result = bar(3);을 만나bar(3)를 호출하게되고,bar(3)은 Call Stack에 쌓이게 된다.
bar = (3) => {
return foo(3,3);
}
bar(3)은foo(3,3)을 리턴값으로 호출을 하고,foo(3,3)는 Call Stack에 추가된다.

foo = (3,3) => {
return 3 * 3; // return 9
}- 이때,
foo(3,3)은 파라 미터로 받은 3과 3을 곱하여 9를 반환하고, 자기 할 일을 다 끝마친foo(3,3)은 Call Stack에서 빠지게 된다.
bar = (3) => {
return foo(3,3); // 9
}
- 반환값으로
foo(3,3)즉 9를 반환하는bar(3)역시 Call Stack에서 빠지게 되며,

baz = (3) => {
let result = bar(3); // 9
console.log(result);
}- baz(3)은 값이
bar(3)-> 9 로 정해진let result를 가지고console.log(result)함수를 실행하게 된다.
(console.log 또한 함수이므로 자신의 실행 콘텍스트를 가진다)

console에 result값 -> 9 를 찍고 console.log(result)는 Call Stack에서 사라지며,
모든 실행을 끝낸 baz(3)역시 Call Stack에서 사라지게 된다.
- 만약 해당 JS 파일에 더 이상의 함수 호출이 없다면, 모든 할 일을 끝낸 전역 실행 콘텍스트 main()또한 Call Stack에서 빠지게 되며 해당 JS 파일을 기본으로하는 프로그램 역시 종료된다.
Memory Heap
메모리 힙은 동적으로 메모리를 할당하는 공간이다.
즉 JS 파일이 바이트 코드로 컴파일 될때, 결정되는 메모리 영역이 아닌, 런타임 환경 중 동적으로 할당되는 메모리 영역이다.
컴파일 과정 중 프로그램 운영체제가 자동으로 메모리로 할당하지 않는 공간이기 때문에,
코드를 작성하는 우리가 메모리 관리를 책임져야 하는 점이 가장 큰 특징이다.
(물론 JS는 자동으로 데이터 타입도 변환해주고...가비지 컬렉터가 자동으로 메모리 할당을 해제해주고... 등 이 과정에 꽤나 개입하는 언어이지만)
그럼에도 우리는 간략하게라도 이해하고 있음이 바람직하다고 생각한다.
JS는 매우 관대한 언어이기 때문에, 우리가 배열, 객체 등의 변수를 선언할때, 이 변수에 얼마만큼의 메모리 영역을 할당해야 하는지, 심지어 데이터 타입조차 정하지 않는다.
다만 우리가 배열이나 객체와 같이 데이터가 가변적일 수 있는 변수를 선언한다고 하였을때,
프로그램은 해당 변수의 데이터 총량이 얼마나 될 지 모르므로, 적당히 여유있는, 유연하게 대처할 수 있는 공간에 데이터를 할당할 것이다.
Memory Allocation with JS data type 이전 JS포스팅을 확인해보자.
이 부분이 Heap 메모리 영역이 아닐까 생각해보았었지만,
(구글링을 진행하다보니 요즘 엔진들은 참조 데이터 타입은 Heap! 원시 데이터 타입은 Stack! 이런식으로 딱딱하게 메모리 영역의 사용에 대해 정의하진 않는다고 한다...)
그럼에도 왜 JS엔진의 런타임 환경에 Heap 메모리 영역이 있는지 그 이유에 대해 한번 생각해보자.
Heap 자료구조
Memory Heap에 대해 이해하기 위해선 일단 Heap 자료구조가 어떠한 형식의 자료 구조인지부터 이해해야한다.
구글에 Heap / 완전 이진트리 등에 대해 검색하다보면 눈 돌아갈만큼 헷갈린다.
일단 완벽히 이해하진 못했지만 내가 이해한 만큼만 포스팅 해보려고한다.
- 힙은 완전 이진 트리(Complete binary tree)의 한 종류이다.

완전 이진 트리란 이진 트리 중에서도 , 마지막 레벨의 노드를 제외하고 모든 레벨이 완전히 채워져 있으며, 위 그림 처럼 마지막 노드는 빈값을 가진다.
💡 완전 이진 트리이여야 하는 이유? -> 개인적인 의견으로는 heap 메모리 영역에 쉽게 새로운 메모리 공간을 할당하거나 삭제하기 용이하려고 완전 이진 트리 방식을 사용하는 것이 아닌가 싶다.
힙에서 가장 낮은 레벨의 가장 오른쪽 값은
arr[arr.length-1]와 같이 배열의 끝의 인덱스에 라고 생각되기 때문.
- 힙은 루트 노드가 그 트리의 최댓값 혹은 최솟값을 가진다.

힙은 크게 최대 힙과 최소 힙으로 나뉜다.
최대 힙은 루트 노드 ( 가장 상위의 노드 -> 위 도표 상 21 /2)가 언제나 가장 큰수가 오며
최소 힙은 그 반대이다.
💡 최대 힙과 최소 힙의 특징
힙은 기본적으로 느슨한 정렬 구조를 가진다.
느슨한 정렬이란 위 도표에서 보다시피 최대 힙에서 10이 8보다 크지만, 더 낮은 레벨의 노드에 존재할 수도 있는 정렬을 뜻한다.
느슨한 정렬을 하는 이유는 힙의 목적은 삭제, 혹은 추가 연산이 수행될 때마다 가장 큰 값, 혹은 작은 값(루트 노드)을 찾아내기만 하면 되는 것이므로 전체를 엄격하게 정렬할 필요는 없기 때문
우리는 이런 힙 자료구조를 사용하여, 어떠한 크기의 데이터가 들어오거나 나가더라도, 손쉽게 메모리 영역들을 최적화시킬 수 있다.
이는 얼마만한 사이즈의 데이터가 들어올지 모르는 객체나 배열 형태의 데이터에게 메모리 영역을 할당하고, 그 메모리 영역들을 관리하기에 괜찮은 자료구조이다.
(힙 자체가 배열형식으로 정리될 수 있기 때문)


