
1-6 정규화
모델링 시 최대한 중복 데이터를 허용하지 않아야 저장공간의 효율적 사용과 업무 프로세스의 성능을 기대할 수 있다. 이러한 중복 데이터를 허용하지 않는 방식으로 테이블을 설계하는 방법을 정규화라고 한다.
정규화의 개념
하나의 엔터티에 많은 속성을 넣게 되면, 해당 엔터티를 조회할 때 마다 많은 양의 데이터가 조회돌 것이므로 최소한의 데이터만을 하나의 엔터티에 넣는식으로 데이터를 분해하는 과정을 정규화라고 한다.
데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성 위한 과정이라고 볼 수 있음.
데이터의 중복을 제거하고 데이터 모델의 독립성을 확보
데이터 이상현상을 줄이기 위한 데이터 베이스 설계 기법
엔터티를 상세화하는 과정으로 논리 데이터 모델링 수행 시점에서 고려됨.
제 1정규화부터 제 5정규화까지 존재, 실질적으로는 제 3정규화까지만 수행
이상현상
정규화를 하지 않아 발생하는 현상(삽입이상, 갱신이상, 삭제이상)
특정 인스턴스가 삽입 될 때 정의되지 않아도 될 속성까지도 반드시 입력되어야 하는(삽입이상) 현상이 발생함
ex) 만약 사원 + 부서 엔터티를 합쳐 놓고 사원번호, 사원이름, 전화번호, 부서번호, 부서명, 부서위치의 속성이 존재할 때 새로운 사원 값이 추가될 때 정해지지 않은 부서정보(부서번호, 부서명, 부서위치) 모두 임의값 또는 NULL 삽입되어야 함. 반대로 부서가 새로 추가될 경우 소속 사원이 없어도 사원과 관련된 모든 속성이 불필요하게 값이 입력되어야 함
불필요한 값까지 입력해야 되는 현상을 삽입이상, 그 외 갱신이상, 삭제이상이 발생할 수 있음
ex) 부서 정보만 삭제하면 되는데 관련된 사원 정보까지도 함께 삭제되는 현상(삭제이상)
정규화 단계
1. 제 1 정규화
테이블이 컬럼이 원자성(한 속성이 하나의 값을 갖는 특성)을 갖도록 테이블을 분해하는 단계
쉽게 말해 하나의 행과 컬럼의 값이 반드시 한 값만 입력되도록 행을 분리하는 단계
ex) 구매 테이블의 제 1정규화
상품에 여러 값이 있으므로 이를 여러 인스턴스로 분해
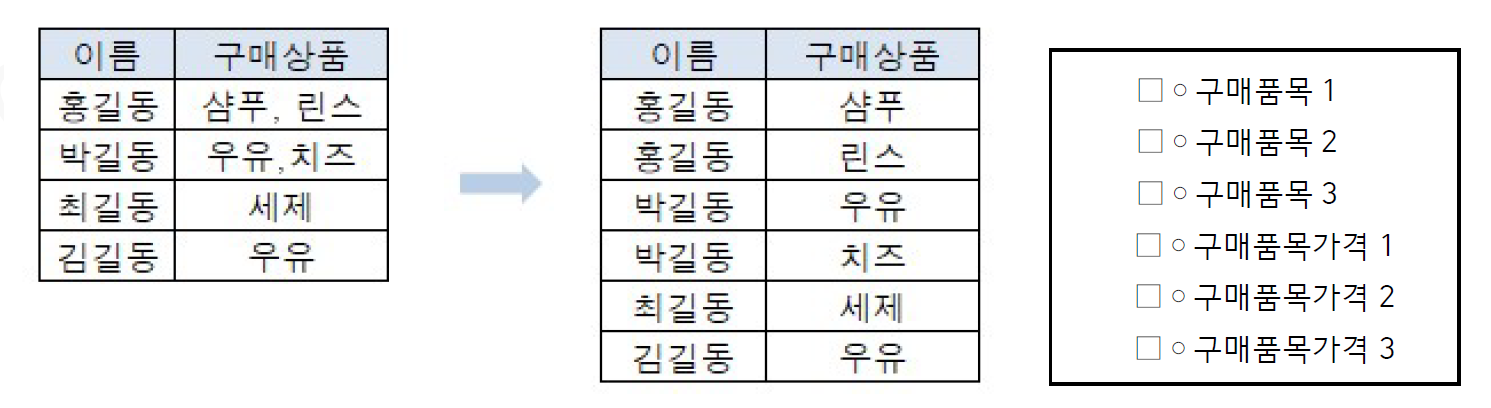
=> 홍길동과 박길동은 구매상품이 두 값이 입력되어 있으므로 이를 각각 두 행으로 분리하는 작업을 거쳐야 함
2. 제 2 정규화
제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만들도록 테이블을 분해
완전 함수 종속이란, 기본키를 구성하는 모든 컬럼의 값이 다른 컬럼을 결정짓는 상태
기본키의 부분 집합이 다른 컬럼과 1:1 대응 관계를 갖지 않는 상태를 의미
즉, PK(Primary Key)가 2개 이상일 때 발생하며 PK의 일부와 종속되는 관계가 있다면 분리한다.
ex) 수강이력 테이블의 제 2 정규화
기본키(학생번호 + 강의명)중, 강의명에 의해 강의실이 결정 -> 완전 함수 종속성 위배
(부분 함수 종속성을 가짐)
-> PK와 부분 함수 종속성을 갖는 컬럼을 각각 다른 테이블로 분해!
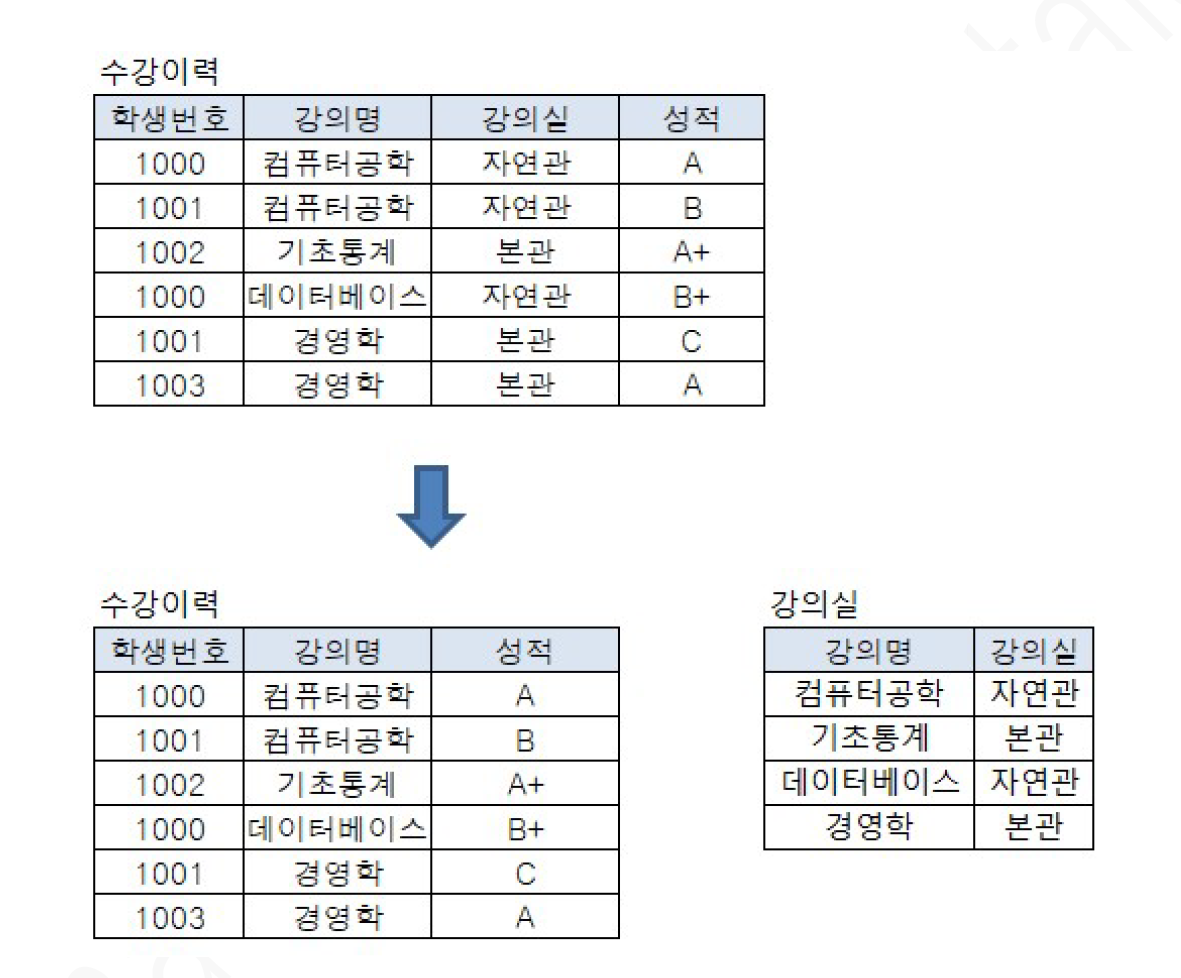
=> 수강이력에서는 한 학생이 여러 강의를 수강할 수 있기 때문에 주식별자는 학생번호로만 불가능(유일성 불만족 때문) 따라서 학생번호와 강의명과 결합되어 주식별자가 되어야 한다(한 학생이 같은 강의는 수강할 수 없다고 가정) 이 때, 주식별자의 부분집합인 강의명에 의해 강의실이 달라지는 1대1 대응관계를 갖는것을 완전 함수 종속성 위배, 같은 말로 부분 함수 종속 관계라고 하는데, 제 2정규화는 이러한 부분 함수 종속성을 깨는 것을 목표로 한다. 따라서 주식별자를 분리할 수 없으니 주 식별자는 수강 이력에 그대로 있고, 문제가 되는 강의실 컬럼을 주식별자와 분리
3. 제 3 정규화
제 2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분리
이행적 종속성이란 A->B, B->C의 관계가 성립할 때, A->C가 성립되는 것을 말함
(A,B)와 (B,C)로 분리하는 것이 제 3 정규화
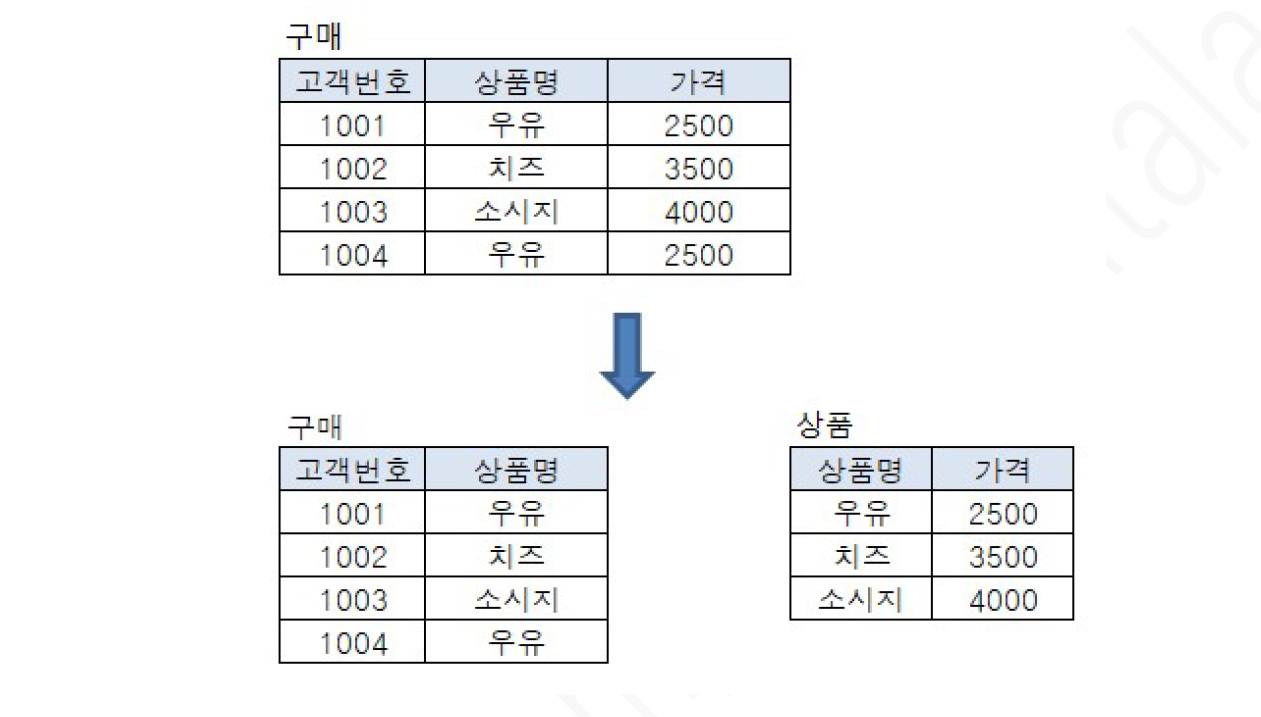
ex) 구매 테이블 제 3 정규화
고객번호에 의해 상품명이 결정, 상품명에 의해 가격이 결정되는데
고객번호에 의해서도 구매가격이 결정됨(고객이 상품을 결정하면 그에 매칭되는 가격이 결정되는 구조이므로)
따라서 (고객번호 + 상품명)과 (상품명 + 가격)으로 분리하는 것이 제 3정규화!
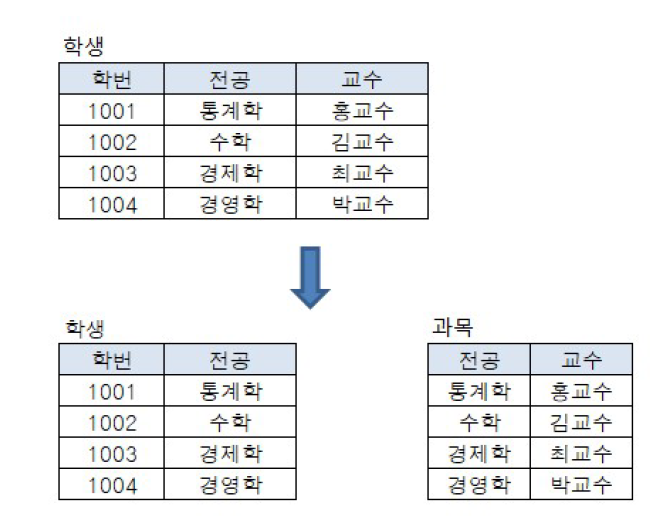
ex) 학생 테이블의 제 3 정규화
학번은 과목의 결정자이며, 과목은 교수의 결정자이다. 이 때, 학번이 달라지면 그 학번에 의한 교수가 달라지므로 학번 역시 교수의 결정자라고 얘기 할 수 있다. 따라서 전공과 교수 컬럼을 분리해야 함. 학생 테이블에서 교수정보가 삭제되고, 따로 과목 테이블이 생기면서 교수의 결정자인 전공과 함께 들어간다.
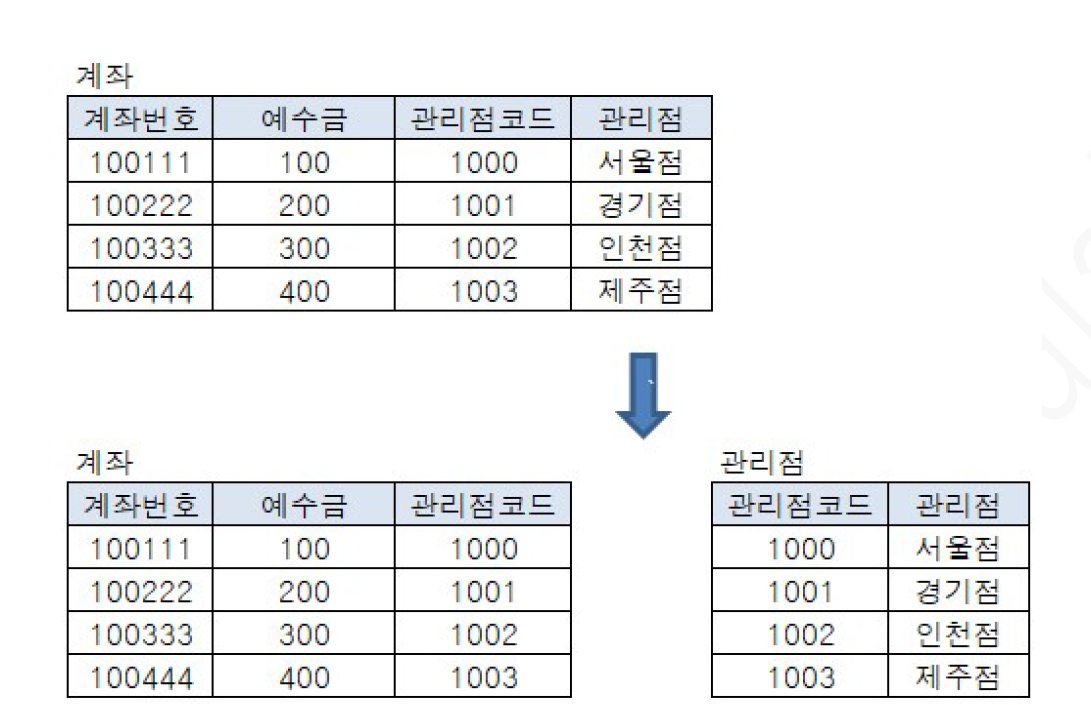
ex) 계좌번호 제 3 정규화
계좌 테이블(분리전)에서 계좌번호가 관리점코드의 결정자이며, 관리점코드 역시 관리점의 결정자인 상태에서 계좌번호에 의해 관리점도 달라지므로 계좌번호 역시 관리점에 대한 결정자이다. 이 때는 PK외 두 속성을 분리, 따라서 관리점이 계좌 테이블에서 삭제되고, 따로 관리점 테이블로 분리되면서 이의 결정자인 관리점코드가 따라감
※ 결정자와 종속관계
만약 A 속성이 B 속성의 값을 결정하게 되면, 이 때 A는 B의 결정자라고 하며, 반대로 B는 A에 종속된다 표현함. 따라서 위 예제에서는 고객번호가 상품명의 결정자이며, 상품명 역시 가격의 결정자이다.
4. BCNF 정규화
모든 결정자가 후보키가 되도록 테이블을 분해하는 것(결정자가 후보키가 아닌 다른 컬럼에 종속되면 안됨)
5. 제 4 정규화
여러 컬럼들이 하나의 컬럼을 종속시키는 경우 분해하여 다중값 종속성을 제거
6. 제 5 정규화
조인에 의해서 종속성이 발생되는 경우 분해
반정규화=역정규화의 개념
데이터베이스의 성능 향상을 위해 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법
시스템의 성능 향상, 개발 및 운영의 단순화를 위해 정규화된 데이터 모델을 중복, 통합, 분리하는 데이터 모델링 기법
조회(SELECT)속도를 향상시키지만, 데이터 모델의 유연성은 낮아짐
※ 비정규화는 정규화를 수행하지 않음을 의미
반정규화 수행 케이스
정규화에 충실하여 종속성, 활용성은 향상되지만 수행 속도가 느려지는 경우
다량의 범위를 자주 처리해야 하는 경우
특정 범위의 데이터만 자주 처리하는 경우
요약/집계 정보가 자주 요구되는 경우
1-7 관계와 조인의 이해
관계의 개념
엔터티의 인스턴스 사이의 논리적인 연관성
엔터티의 정의, 속성 정의 및 관계 정의에 따라서도 다양하게 변할 수 있음
관계를 맺는다는 의미는 부모의 식별자를 자식에 상속하고, 상속된 속성을 매핑키(조인키)로 활용
=> 부모, 자식을 연결함
관계의 분류
관계는 존재에 의한 관계와 행위에 의한 관계로 분류
존재 관계는 엔터티 간의 상태를 의미
ex) 사원 엔터티는 부서 엔터티에 소속
행위 관계는 엔터티 간의 어떤 행위가 있는 것을 의미
ex) 주문은 고객이 주문할 때 발생
조인의 의미
결국 데이터의 중복을 피하기 위해 테이블은 정규화에 의해 분리된다. 분리되면서 두 테이블은 서로 관계를 맺게 되고, 다시 이 두 테이블의 데이터를 동시에 출력하거나 관계가 있는 테이블을 참조하기 위해서는 데이터를 연결해야 하는데 이 과정을 조인이라고 함
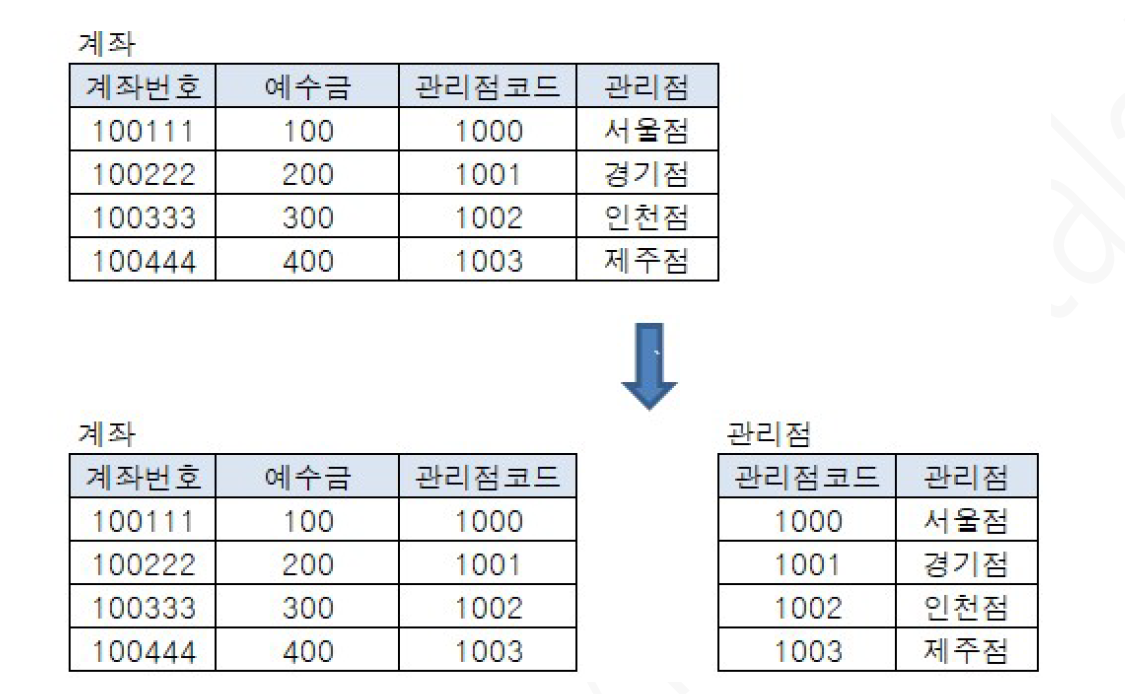
=> 계좌 테이블은 제 3 정규화에 의해 계좌 + 관리점으로 분리됨. 이때 관리점 코드를 같이 공유함. 만약 계좌 정보와 함께 관리점 정보를 함께 출력할 경우 두 데이터를 조인하여 출력함. 즉, 양 테이블의 데이터를 함께 출력하거나 참조하기 위해 두 데이터를 연결하는 과정을 조인, 연결키를 조인키라고 함
조인 ex) 계좌번호 100111의 관리점이 어딘지를 찾으려면?
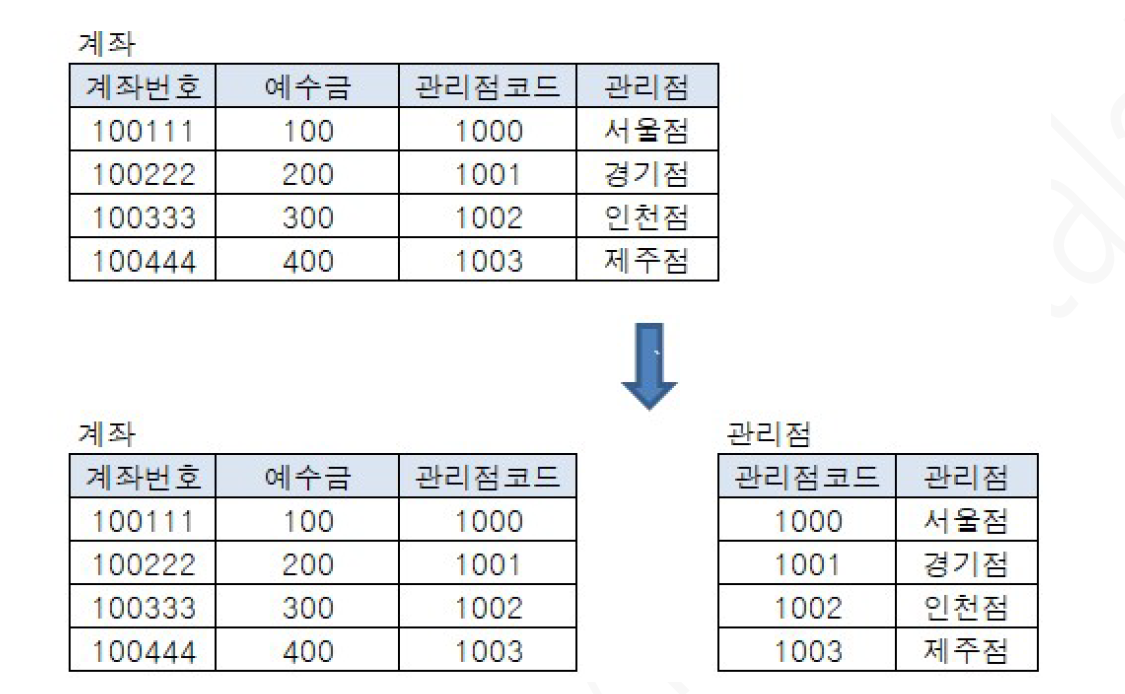
1) 계좌번호 테이블에서 계좌번호가 10111 데이터 확인
2) 계좌번호 테이블에서 계좌번호가 10111 데이터의 관리점코드(1000)를 확인
3) 관리점코드(1000)를 관리점 테이블에 전달하여 관리점 확인(서울점)
SQL 작성)
SELECT A.계좌번호, B.관리점
FROM 계좌 A, 관리점 B
WHERE A.관리점코드 = B.관리점코드
AND A.계좌번호 = '100111'
계층형 데이터 모델
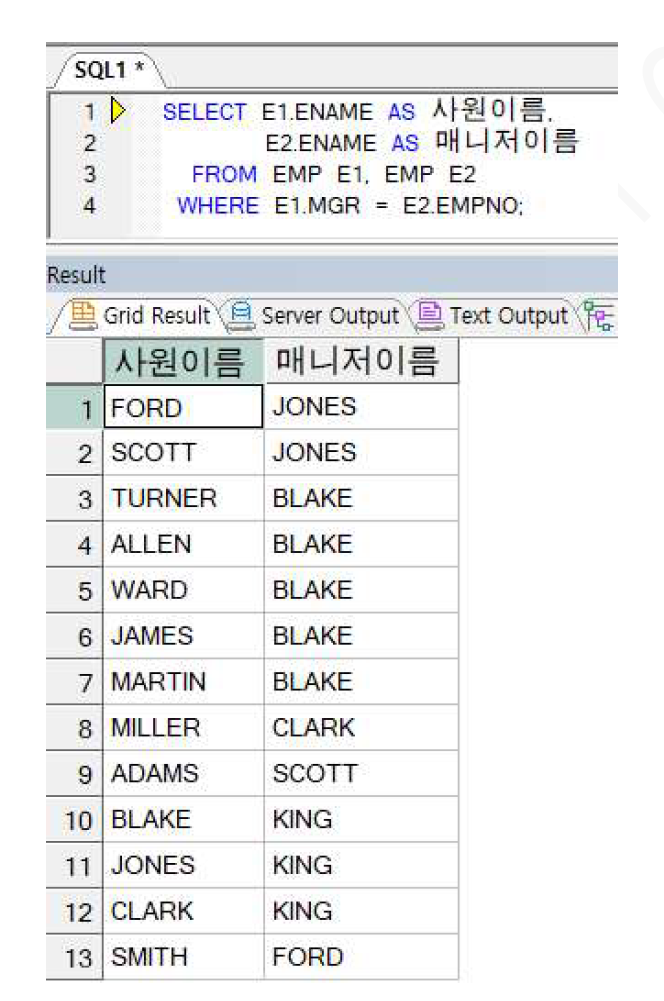
자기 자신끼리 관계가 발생. 즉, 하나의 엔터티 내의 인스턴스끼리 계층 구조를 가지는 경우를 말함
계층 구조를 갖는 인스턴스끼리 연결하는 조인을 셀프조인이라함(같은 테이블을 여러 번 조인)
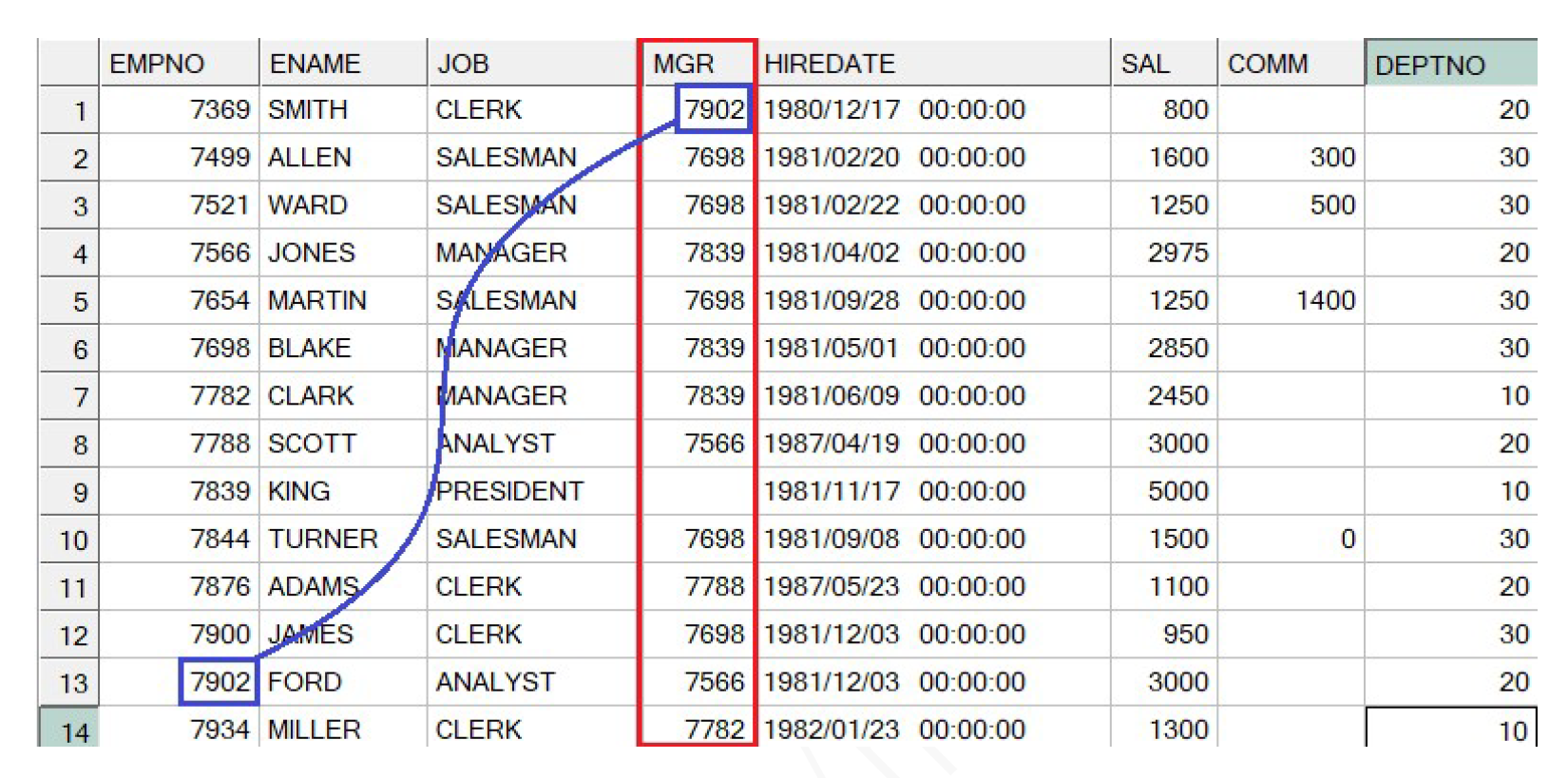
아래 EMP 테이블은 직원테이블 순서대로 사번, 이름, 직무, 매니저번호, 입사일, 급여, 보너스, 부서번호 컬럼으로 구성. 이 때, 매니저번호(MGR)는 매니저의 사원번호를 의미하므로 사원번호(EMPNO) 컬럼과 관련이 있다.
즉, SMITH 의 매니저 이름을 확인하는 과정을 보면, SMITH의 매니저 번호를 확인(7902)
해당 번호의 사번을 갖는 데이터를 찾으면 FORD 라는것을 확일할 수 있음.
SQL로 표현
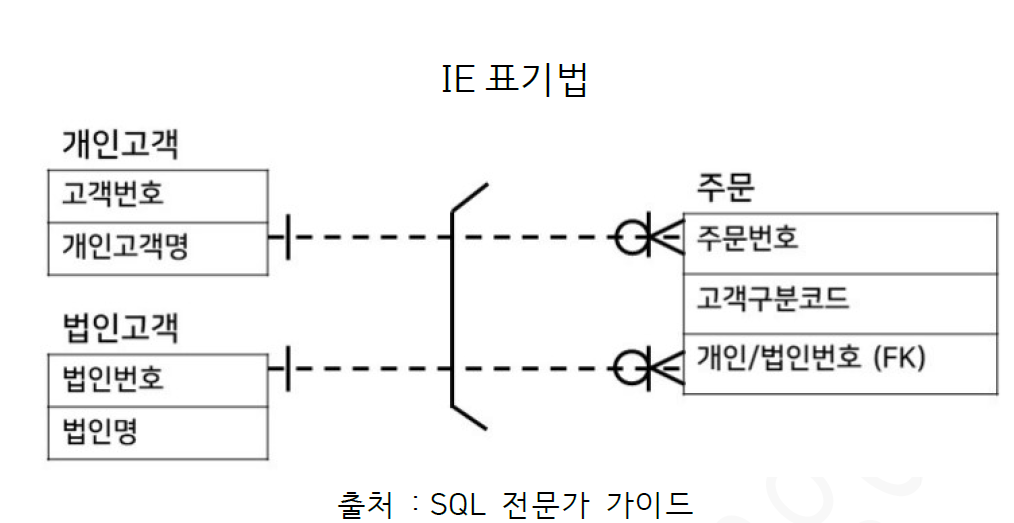
상호배타적 관계
두 테이블 중 하나만 가능한 관계를 말함
ex) 주문 엔터티에는 개인 또는 법인번호 둘 중 하나만 상속될 수 있음 => 상호배타적 관계
즉, 주문은 개인고객이거나 법인고객 둘 중 하나의 고객만이 가능
1-8 모델이 표현하는 트랜잭션의 이해
트랜잭션이란
하나의 연속적인 업무 단위를 말함
트랜잭션에 의한 관계는 필수적인 관계 형태를 가짐
하나의 트랜잭션에는 여러 SELECT,INSERT,DELETE,UPDATE 등이 포함될 수 있음
※ 계좌이체를 예를 들면)
A 고객이 B 고객에게 100 만원을 이체하려고 한다고 가정하자
STEP1) A 고객의 잔액이 100만원 이상인지 확인
STEP2) 이상이면, A 고객 잔액을 -100 UPDATE
STEP3) B 고객 잔액에 +100 UPDATE
이 때, 2번과 3번 과정이 동시에 수행되어야 한다. 즉 모두 성공하거나 모두 취소돼야 함(All or Nothing)
=> 이런 특성을 갖는 연속적인 업무 단위를 트랜잭션이라고 한다.
※ 주의
1. A 고객 잔액 차감과 B 고객 잔액 자산이 서로 독립적으로 발생하면 안됨
-> 각각의 INSERT 문으로 개발되면 안됨
2. 부분 COMMIT 불가
-> 동시 COMMIT 또는 ROLLBACK 처리
필수적, 선택적 관계와 ERD
두 엔터티의 관계가 서로 필수적일 때 하나의 트랜잭션을 형성
두 엔터티가 서로 독립적 수행이 가능하다면 선택적 관계로 표현
IE 표기법)
원을 사용하여 필수적 관계와 선택적 관계를 구분
필수적 관계에는 원을 그리지 않는다
선택적 관계에는 관계선 끝에 원을 그린다
바커표기법)
실선과 점선으로 구분
필수적 관계는 관계선을 실선으로 표기
선택적 관계는 관계선을 점선으로 표기
1-9 null 속성의 이해
NULL이란
DBMS에서 아직 정해지지 않은 값을 의미
0과 빈문자열('')과는 다른 개념
모델 설계 시 각 컬럼별로 NULL을 허용할 지를 결정(Nullable Column)
NULL의 특성
1. NULL을 포함한 연산 결과는 항상 NULL
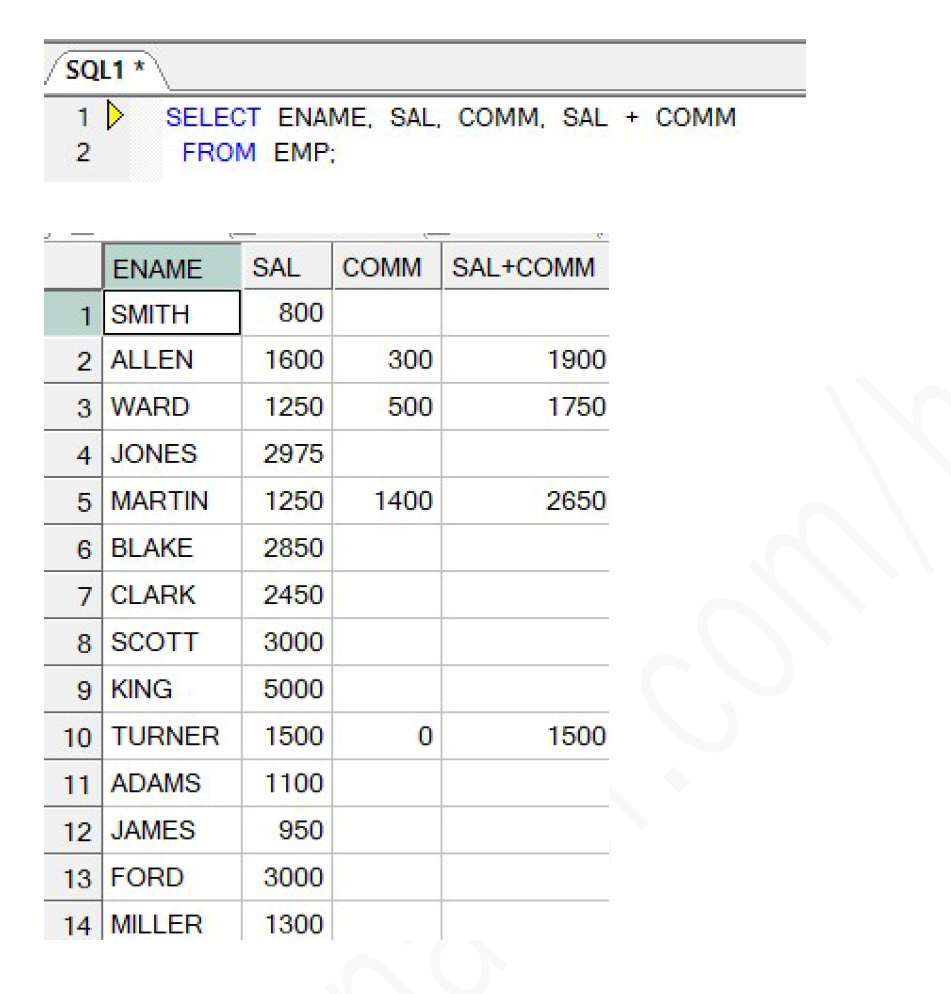
=> COMM 컬럼에 공백으로 보이는것들이 NULL이다 (물론 빈 문자열일 수 있지만 해당 데이터에서는 NULL 임)
이 때, NULL을 포함한 COMM과 SAL과의 연산결과는 NULL이 리턴된다.
=> NULL을 사전에 치환한 후 연산필요
NULL 치환 후 연산 결과
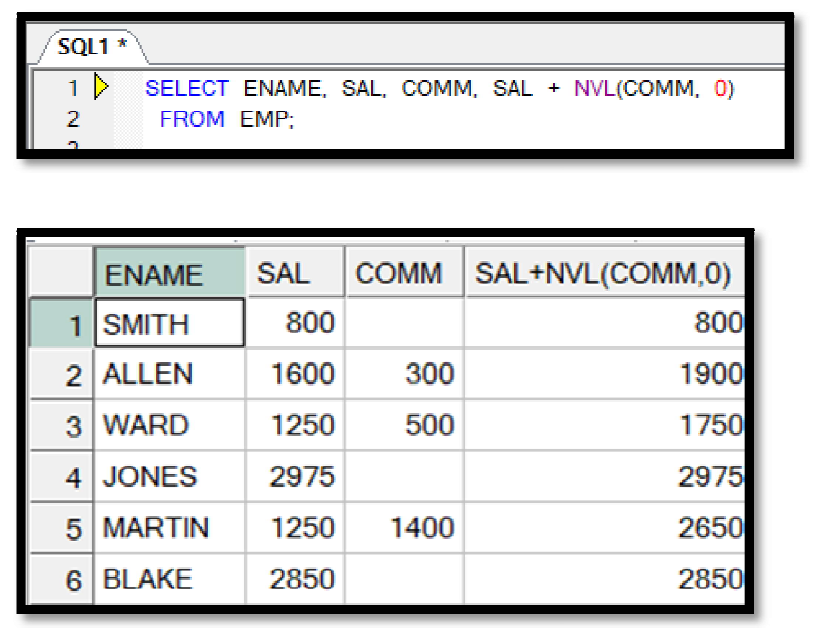
2. 집계함수는 NULL을 제외한 연산 결과 리턴
※ sum, avg, min, max 등의 함수는 항상 NULL을 무시한다.
ex) NULL을 포함한 컬럼의 집계함수 결과 1
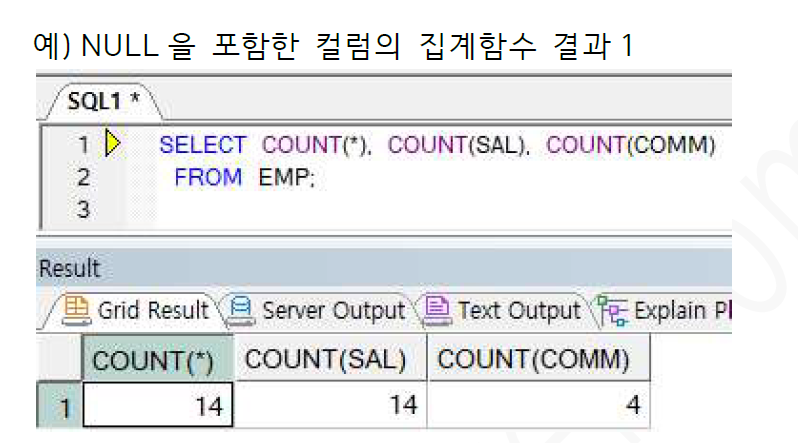
=> COUNT는 행의 수를 리턴하는 함수인데, COUNT에 *전달 시 모든 컬럼을 체크하여 NULL일 경우는 COUNT 제외. COMM의 경우 NULL이 다수 포함되어 있는데, COUNT시 NULL을 제외. 즉 NOT NULL인 행만 세어 리턴하므로 전체 행의 수보다 적은 4의 값이 출력됨
ex) NULL을 포함한 컬럼의 집계함수 결과 2
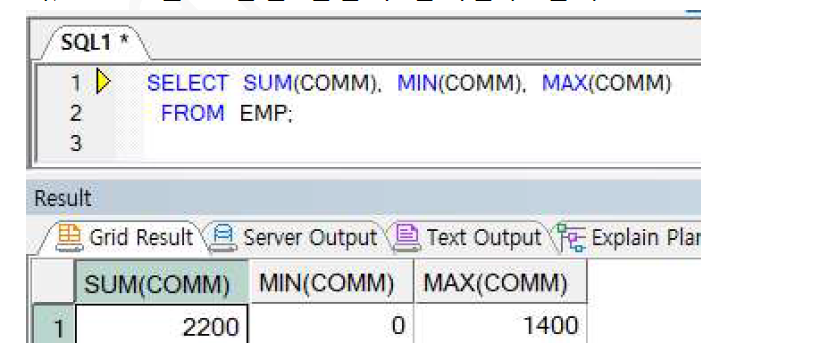
=> SUM,MIN,MAX 연산 결과도 모두 NULL을 무시하며 연산된다.
ex) NULL을 포함한 컬럼 평균연산
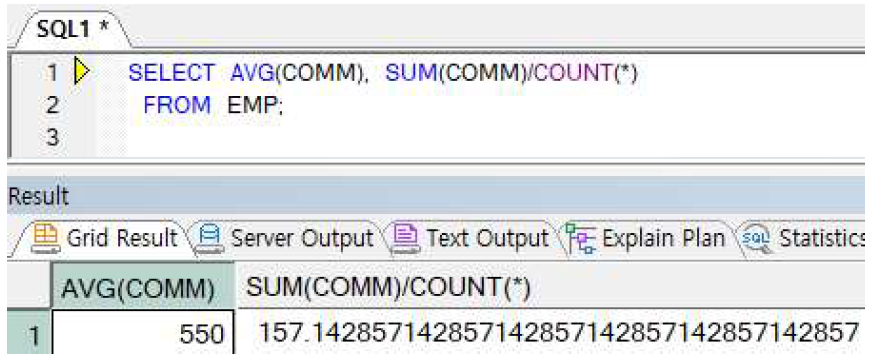
=> AVG 연산 결과는 NULL을 무시한 평균을 리턴하므로, NULL 아닌 4개의 데이터들의 평균을 리턴, 두 번째 수식은 평균을 직접 구한 것으로, COMM의 총 합을 총 행이 수인 14로 나눈 값이다. 따라서 이 두 연산결과는
COMM이 NULL을 포함할 경우 항상 다르게 리턴된다. NULL을 무시한 평균을 얻고자 함인지, 전체 14명에 대한 평균을 계산하고자 함인지에 따라 적절히 선택하여 사용!
NULL의 ERD 표기법
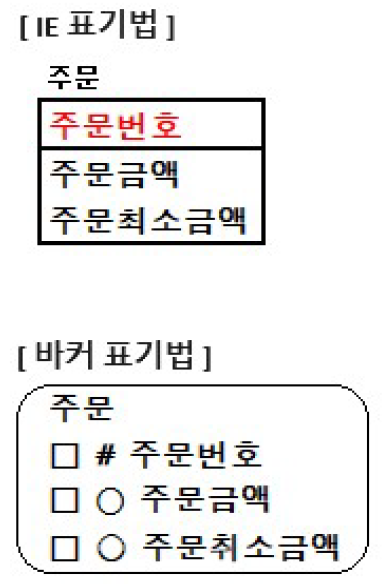
IE 표기법에서는 NULL 허용여부를 알 수 없음
바커 표기법에서는 속성 앞에 동그라미가 NULL 허용 속성을 의미함
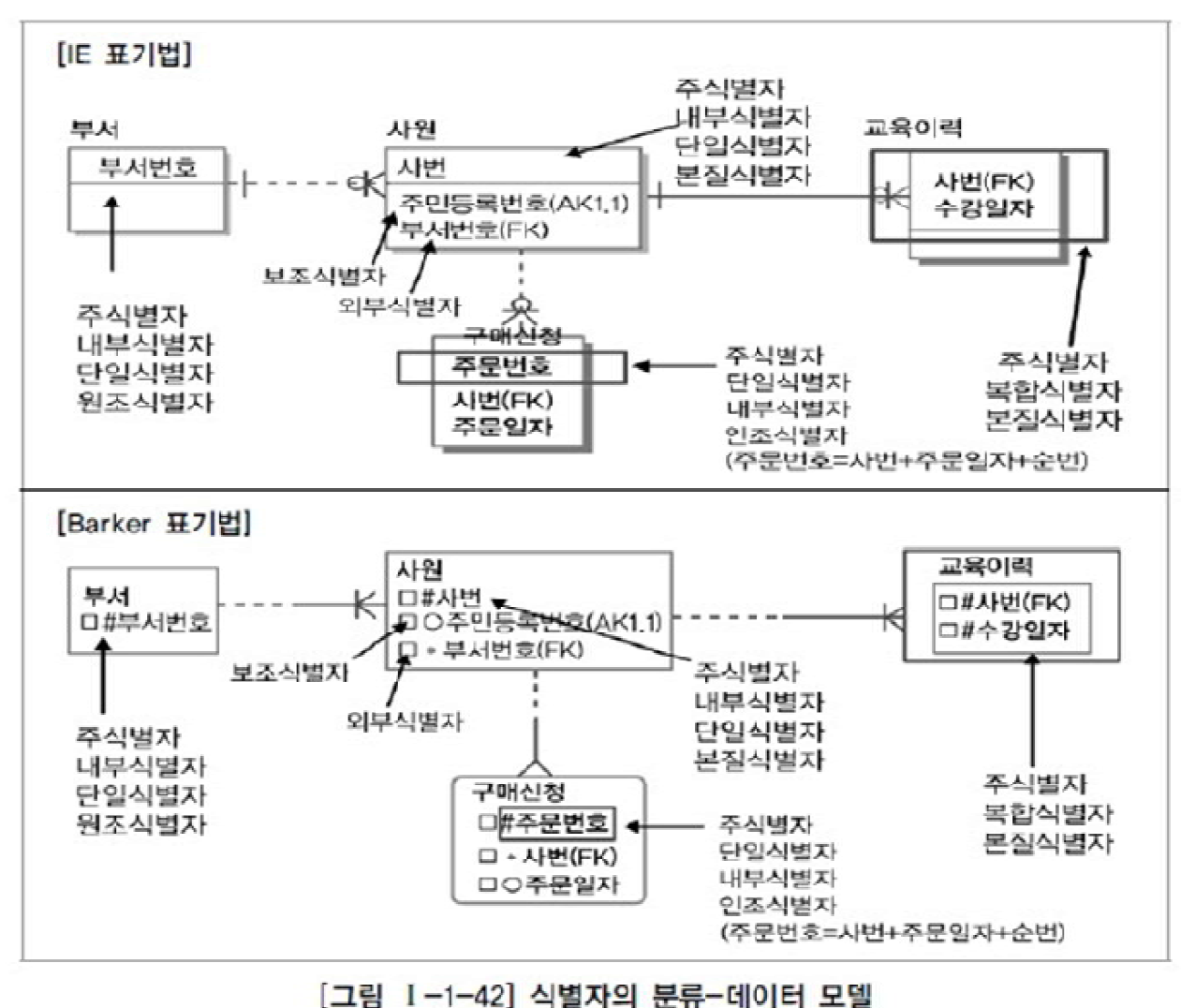
1-10 본질식별자
식별자 구분(대체 여부에 따른)
1) 본질식별자
업무에 의해 만들어지는 식별자(꼭 필요한 식별자)
2) 인조식별자
인위적으로 만들어지는 식별자(꼭 필요하지 않지만 관리의 편이성 등의 이유로 인위적으로 만들어지는 식별자)
본질식별자가 복잡한 구성을 가질 때 인위적으로 생성
주로 각 행을 구분하기 위한 기본키로 사용되며 자동으로 증가하는 일련번호 같은 형태임
ex) 주문과 주문상세에 대한 엔터티 설계 과정을 예를 들어보자.
주문이 들어오면 주문 엔터티에는 (주문번호 + 고객번호)를 저장, 이 때 PK는 주문번호이다.
주문이력에는 각 주문별로 어떤 상품이, 언제, 몇 개 주문됐는지 등을 기록한다.

※ 주문이력 테이블 설계 시 다음과 같은 식별자를 고려할 수 있다.
1. PK : 주문번호 + 상품번호로 설계
주문을 하면 주문번호와 상품번호가 필요하므로 본질식별자(주문번호 + 상품번호)가 된다.
하지만 PK가 주문번호 + 상품번호이면 하나의 주문번호로 같은 상품의 주문 결과를 저장할 수 없게 된다

=> 실제로 쇼핑을 하다보면 동일한 장바구니에 A 상품을 5개 주문했는데,
뒤에 또 다시 A 상품을 3개 추가로 주문하기도 함
2. PK : 주문번호 + 주문순번 (주문순번이라는 컬럼을 생성)
하나의 주문에 여러 상품에 대한 주문 결과 저장 가능 -> 주문순번으로 인해 구분함
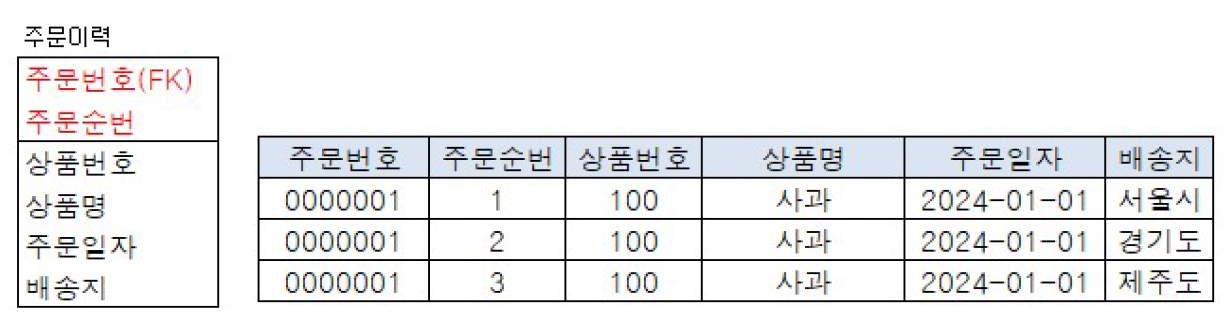
=> 매 주문마다 동일한 상품 주문 시 주문순번을 정하기 위해 상품의 주문 횟수를 세야한다는 점이 매우 불편!
즉, 사과를 총 3번 구매하였으나 주문순번은 1,2,3 순서대로 입력돼야 함
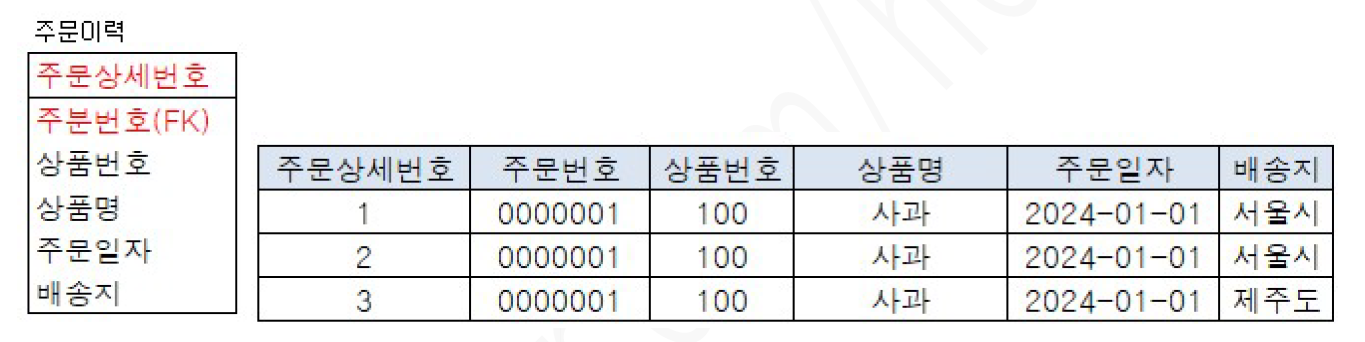
3. PK : 주문상세번호(인조식별자 생성)
주문상세번호 각 주문이력을 구분하기 때문에 같은 주문의 같은 상품이력이 저장될 수 있음.
주문 상세번호만이 주식별자이므로 나머지 정보들이 불필요하게 중복 저장될 위험 발생
실제 업무와 상관없는 주문상세번호를 주식별자로 생성하면 쓸모없는 index가 생성됨(PK 생성 시 자동 unique index 생성)
※ 따라서 인조식별자는 다음의 단점을 가지게 된다.
1. 중복 데이터 발생 가능성 -> 데이터 품질 저하
2. 불필요한 인덱스 생성 -> 저장공간 낭비 및 DML 성능 저하
** 인덱스는 원래 조회 성능을 향상시키기 위한 객체이며,
인덱스는 DML(INSERT/UPDATE/DELETE)시 INDEX SPLIT 현상으로 인해 성능이 저하된다.
참조
해당 글은 홍쌤의 데이터랩의 영상강의를 기반으로 작성되었습니다.

