알고리즘
937. Reorder Data in Log Files (leetcode)
정답코드
def reorderLogFiles(self, logs: List[str]) -> List[str]:
digits,letters=[], []
for log in logs:
if log.split()[1].isdigit():
digits.append(log)
else:
letters.append(log)
letters.sort(key=lambda x:(x.split()[1:], x.split()[0]))
return letters + digitssplit()
split()이면 띄어쓰기를 기준으로 split한다.
sort()
sort(key=lambda x: (x.split()[1:], x.split[0]))
여기서 (x.split()[1:], x.split[0]) 부분이 중요하다. 정렬할때 만약 [1:]부분을 통해 정렬할 부분이 일치하다면, 후순위로 [0]부분을 기준으로 정렬하라는 것이다.
s = ['2 a', '1 b', '4 c', '1 a']
s.sort(key=lambda x: (x.split()[1]))
print(s)
s = ['2 a', '4 b', '1 b', '1 a']
s.sort(key=lambda x: (x.split()[1], x.split()[0]))
print(s)
--> ['1 a', '2 a', '1 b', '4 b']
['2 a', '1 a', '1 b', '4 c']위 코드를 보면 다시볼때 이해가 더 빨리될듯하다.
819. Most Common Word (leetcode)
전처리단계: "데이터 클렌징"
입력값에 대소문자뿐 아니라 쉼표등이 존재한다. 여기서 banned의 단어들을 제외하고 대소문자만 남기고, 대문자들도 소문자들로 바꾸는 과정을 리스트 컴프리헨션을 통해 한줄로 구현한다.
words=[word for word in re.sub(r'[^\w]', ' ', paragraph).lower().split() if word not in banned]\w는 단어 문자를 뜻한다. 즉, paragraph안에서 단어문자를 제외한 것들은 공백으로 치환하고 이 값을 소문자로 바꾼 후 공백을 단위로 split하여 banned단어가 아닌 것들을 리스트로 만든다.
1번방법. defaultdict(int)
collections.defaultdict(int) 는 딕셔너리의 int기본값인 0을 부여하게 된다.
defaultdict를 사용한다면
letters_dict = defaultdict(int)
for k in letters:
letters_dict[k] += 1 딕셔너리에 키가 있는지(해당 알파벳) 확인 절차를 거칠 필요없이 바로 값을 1증가시켜주면 된다.
없으면 그 키를 만들어주고 초깃값을 0으로 설정한다.
defaultdict()를 사용하지않으면
letters_dict = {}
for k in letters:
if not k in letters_dict:
letters_dict[k] = 0
letters_dict[k] += 1이렇게 해야한다. (출처: https://dongdongfather.tistory.com/69)
정답코드
words=[word for word in re.sub(r'[^\w]', ' ', paragraph).lower().split() if word not in banned]
counts=collections.defaultdict(int)
for word in words:
counts[word]+=1
return max(counts,key=counts.get)2번방법. Counter, most_common 이용
Counter 을 이용하면 빈도수를 정렬해서 만들어준다.
이후에 most_common에서 (1): 첫번째순서, [0][0]: 맨 앞의 앞쪽(여기서는 (단어, 숫자)순서로 리스트되어있기때문에 단어가 선택됨.
정답코드
words=[word for word in re.sub(r'[^\w]', ' ', paragraph).lower().split() if word not in banned]
counts=collections.Counter(words)
return counts.most_common(1)[0][0]49. Group Anagrams (leetcode)
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
lis=collections.defaultdict(list)
for word in strs:
lis[''.join(sorted(word))].append(word)
return list(lis.values())sorted(word)해서 순서가 뒤바뀐 것을 join을 통해 한 문장으로 다시 만들고 이렇게되면 애너그램들 사이에서는 key값은 똑같아지게된다. 그런 후 apeend를 통해 애너그램들을 넣어주면 된다.
join()
s = ['a', 'b', 'c', 'd']
print(' '.join((s)))
---> a b c d
s = ['a', 'b', 'c', 'd']
print('123 '.join((s)))
---> a123 b123 c123 d이처럼 join()은 괄호안의 리스트를 한개씩 꺼내고 '123 '을 뒤에 붙인다. 하지만 맨 뒤에는 붙이지 않는 점을 주의해야할꺼같다.
sorted()는 값을 저장할 새로운 변수가 필요하지만, .sort()는 "제자리 정렬"이라고하며 입력을 출력으로 덮어쓰기에 별도의 추가 공간이 필요하지않고, 리턴값도 없다.
그리고 sorted(c, key=len)을 이용하면 리스트 c를 길이순으로 정렬하는 것도 가능하다.
5. Longest Palindromic Substring (leetcode)
def longestPalindrome(self, s: str) -> str:
def expand(left: int, right: int)->str:
while left>=0 and right<len(s) and s[left]==s[right]:
left -= 1
right += 1
return s[left+1:right]
if len(s)< 2 or s==s[::-1]:
return s
result = ''
for i in range(0, len(s)-1):
result = max(result, expand(i, i + 1), expand(i, i + 2), key=len)
return result코드를 설명하자면, def expend의 코드를 보면 투포인터를 슬라이딩 윈도우(정해진 너비가 고정된채 이동하는 것)처럼 이용한다. 어떤 위치에 있을때 양 값이 같으면 while문을 이용해 양쪽으로 확장해가면서 팰린드롬이 지속될때까지 늘린다.
유니코드와 UTF-8
유니코드
2~4바이트의 공간에 여유있게 문자를 할당하는 방식.
UTF-8 바이트 순서의 이진 포맷
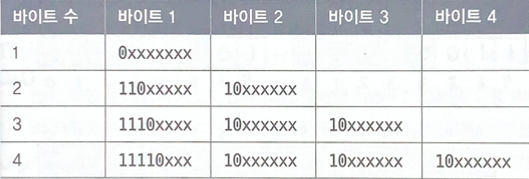
1바이트 내에 담을 수 있으면 첫번째 바이트 맨앞에 0 표시
2바이트 내에 담을 수 있으면 첫번째 바이트 맨앞에 110 표시, 두번째 바이트 맨앞에 10 표시
3바이트 내에 담을 수 있으면 첫번째 바이트 맨앞에 1110 표시, 두번째 바이트 맨앞에 110 표시, 세번째 바이트 맨앞에 10 표시.
하는 방법으로 가변 인코딩을 하여 메모리 낭비를 줄인다.
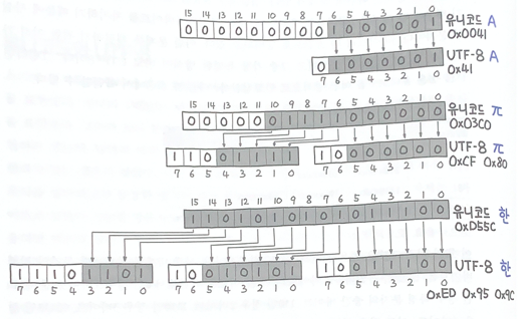
실제로는 위의 그림처럼 구현한다.
숫자가 커질수록 한 바이트안에 담는 이진수가 적어지더라도 이게 더 효율적인가보다.
결론적으로는 파이썬내부에선 UTF-8을 쓰지않는다. 동적이기때문에 각문자마다 바이트 길이가 달라지게 되어 원하는 인덱스에 빠르게 접근할 수 없다고한다. 그렇기에 문자열에 따라 정해진 규칙을 달리하는 고정 인코딩 방식을 사용한다.
클라우드
도커 배운것 필기.
cpu와 메모리를 제한하는 명령어를 학습했는데, 명령어 전체를 적을 필요는 없을 거 같다.
cpu는 4코어가 있으면 0~3번까지로 칭하고 코어를 0.5씩도 할당해줄 수 있다.
메모리의 경우 일반 메모리와 swap 메모리 두개를 컨트롤할 수 있다.
swap메모리를 따로 설정하지않으면 일반 메모리 할당한 값의 2배로 자동으로 설정되도록 하는데, 이때 스왑에 할당되는 값은 우리가 기재하는 값이나 기본으로 설정되는 2배의 값에서 일반 메모리에 할당한 값을 빼야 정말로 swap메모리에 할당되는 값이 된다.
각 컨테이너마다 cpu에 얼마나 리소스를 쓸 수 있는지도 할당해줄수 있다. 이는 상대적인 값으로 디폴트값은 1024이고 두개 또는 1/2배등 다양하게 설정이 가능하다.
