Intro
CTR 데이터는 매우 sparse하기 때문에 기존 ML 모델이나 단순한 형태의 MLP로는 복잡한 변수의 관계(feature interaction)을 캐치하기 어렵다.
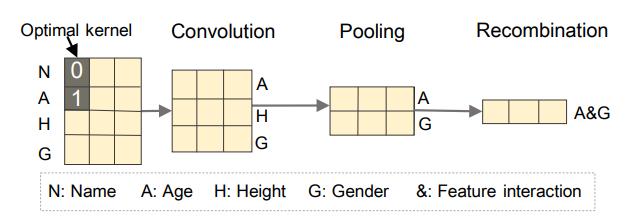
FGCNN은 CNN과 MLP를 결합한 모델로 CNN을 통해 국소적인 변수들의 관계(local neighbor feature interaction)를 학습한 후 MLP로 관계를 재결합하여 변수들의 전체 관계(global featur interaction)를 추출한다. 간단한 아이디어는 아래 그림과 같으며, 그림을 통해 두 변수가 이웃이 아니더라도 [Convolution - Pooling - Recombination] 과정을 통해 근접한 변수가 아니어도 변수 관계를 추출하는 모습을 확인할 수 있다.
Model
FGCNN 과정을 그림으로 알아본다. (수식은 논문을 통해 확인할 수 있다.)
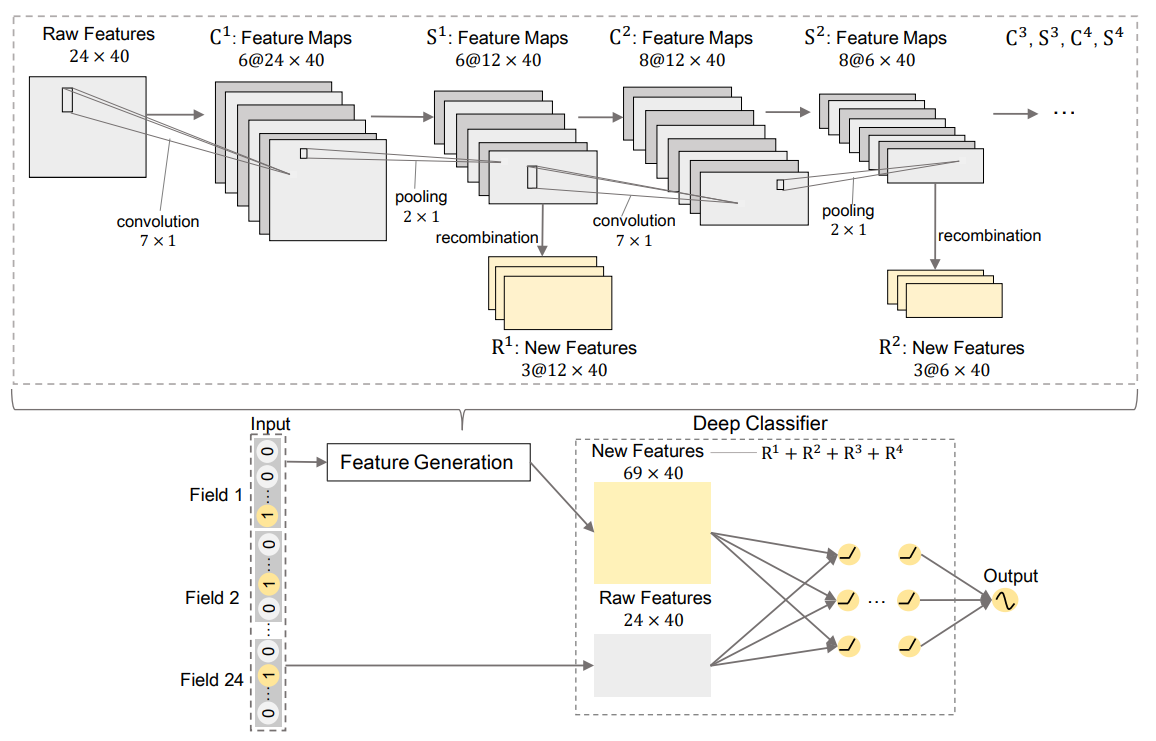
- 처음
Raw Feature는 임베딩 행렬로 24는 필드(field)의 수, 40은 임베딩 크기(embedding size)를 의미한다. feature map을 생성하기 위해 7x1 크기의 커널(kernel) 6개로 convolution을 수행하며, 패딩(padding)을 통해 사이즈는 유지한다. 이 과정은 변수의 조합만 고려하기 때문에 커널의 높이만 변화시키고 너비는 1로 고정되어 있다.feature map은 2x1 max pooling을 통해 생성된다. 여기서도 커널의 너비는 고정된다.- 새로운 관계 변수(interaction feature) 은
recombination을 통해 생성된다. Recombination은 tanh을 활성화함수(activation function)로 갖는 단층 레이어(1-layer) 모델이며, 생성할 변수의 수는 hyperparameter이다. - 위의 과정을 반복하여 를 생성한다.
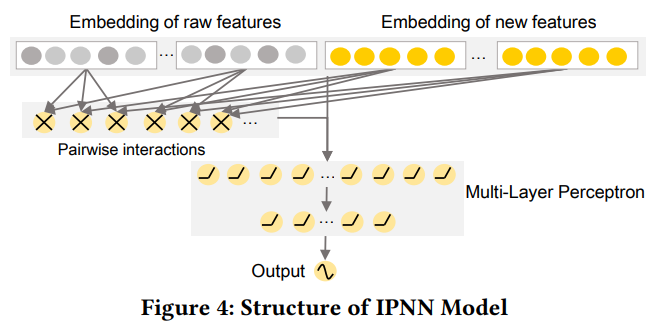
이후 기존 변수(raw feature)와 위의 과정을 통해 생성된 관계 변수를 IPNN 모델에 넣어 예측값을 생성한다. IPNN의 모델 구조는 위 그림과 같다. 앞에서 다룬 DeepFM이 FM과 DNN 각각의 예측값을 생성 후 결합한 모델이었다면, IPNN은 FM의 아웃풋(output)을 DNN의 인풋(input)으로 넣는 구조이다.
Note
FGCNN의 키포인트는 재결합(recombination) 과정으로 지역적인 변수 관계를 전역적으로(globally) 다룰 수 있게 만든 점이다.- 논문에서 밝혔듯 효율적인 학습을 위해 activation function 이전에 BN(Batch Normalization)을 사용한다.
xDeepFM만 하더라도 파라미터 CIN, H에 대한 튜닝이 필요했는데(그나마 CIN의 수는 2~3으로 어느정도 제시되어있다.), FGCNN은 각 레이어의 channel 수, kernel의 크기 등 튜닝해야 할 파라미터들이 더 많다. 그래도(?) 논문의 예시와 데이터를 적절히 조합하여 간략하게 돌려봤는데 우연인지 성능은 가장 좋게 나왔다.
Code
※ CTR 시리즈의 모든 코드는
FuxiCTR을 참고했으며 함수 구조와 이름 등은 개인적으로 수정하여 사용하였다.
-
feature_dict은 각 변수의 설명이 들어있는 dict()이다. (ex, Dict[str, Dict[str, int]])EmbeddingDict()은 각 필드의 임베딩 벡터(embedding vector)를 반환하는ModuleDict()으로 아웃풋은 [배치(batch) 크기, 필드 수, 임베딩 크기] 형태이다. -
FGCNN 전체 모델을 구성하기에 앞서 관계 변수를 생성한다.
Convolution단계인 conv_list는Conv-BN-Activation-Pooling으로,Recombinatnio단계인 recomb_list는Linear-Activation의 과정으로 이루어져있다.
class FGCNNLayer(nn.Module):
def __init__(self,
conv_channels,
kernel_heights,
pooling_sizes,
recombine_channels,
feature_dict,
embed_dim,
):
super(FGCNNLayer, self).__init__()
self.embed_dim = embed_dim
self.conv_channels = [1] + conv_channels
conv_list = []
recombine_list = []
input_height = len(feature_dict)
for i in range(1, len(self.conv_channels)):
in_ch = self.conv_channels[i-1]
out_ch = self.conv_channels[i]
kernel_height = kernel_heights[i-1]
pooling_size = pooling_sizes[i-1]
recombine_channel = recombine_channels[i-1]
conv_list.append(
nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=(kernel_height, 1), padding=((kernel_height-1)//2, 0)),
nn.BatchNorm2d(out_ch),
nn.Tanh(),
nn.MaxPool2d((pooling_size, 1), padding=(input_height % pooling_size, 0))
)
)
input_height = int(np.ceil(input_height / pooling_size))
input_dim = input_height * embed_dim * out_ch
output_dim = input_height * embed_dim * recombine_channel
recombine_list.append(
nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.Tanh()
)
)
self.conv_layers = nn.ModuleList(conv_list)
self.recombine_layers = nn.ModuleList(recombine_list)
def forward(self, X):
conv_out = X
new_feature_list = []
for i in range(len(self.conv_channels)-1):
conv_out = self.conv_layers[i](conv_out)
flat_conv_out = conv_out.flatten(start_dim=1)
recombine_out = self.recombine_layers[i](flat_conv_out)
new_feature_list.append(recombine_out.reshape(X.size(0), -1, self.embed_dim))
return torch.cat(new_feature_list, dim=1)- 기존 변수와 생성 변수를 결합(concat)한 후
IPNN모델(Inner product - DNN)을 통해 아웃풋을 생성한다. 아래compute_input_dim은 inner_product_layer와 DNNLayer 두 레이어의 입력 크기인 input_dim을 계산하는 메서드이다.
class FGCNN(BaseModel):
def __init__(self,
conv_channels,
kernel_heights,
pooling_sizes,
recombine_channels,
hidden_dim_list,
feature_dict,
embed_dim,
):
super(FGCNN, self).__init__()
self.embedding = EmbeddingDict(feature_dict=feature_dict, embed_dim=embed_dim)
self.fgcnn_layer = FGCNNLayer(conv_channels=conv_channels,
kernel_heights=kernel_heights,
pooling_sizes=pooling_sizes,
recombine_channels=recombine_channels,
feature_dict=feature_dict,
embed_dim=embed_dim)
input_dim, total_features = self.compute_input_dim(conv_channels=conv_channels,
pooling_sizes=pooling_sizes,
recombine_channels=recombine_channels,
feature_dict=feature_dict,
embed_dim=embed_dim)
self.inner_product_layer = InnerProduct(model='FGCNN',
X_dim=total_features,
feature_dict=feature_dict)
self.dnn = DNNLayer(input_dim=input_dim,
hidden_dim_list=hidden_dim_list)
# tunning method
# self.compile(CFG.optimizer, CFG.loss, CFG.learning_rate)
# self.init_params()
# self.model_to_device()
def forward(self, inputs):
X, y = self.inputs_to_device(inputs)
X_emb = self.embedding(X)
conv_in = X_emb.unsqueeze(1)
conv_out = self.fgcnn_layer(conv_in)
concat_out = torch.cat([X_emb, conv_out], dim=1)
inner_product_out = self.inner_product_layer(concat_out)
dense_in = torch.cat([concat_out.flatten(start_dim=1), inner_product_out], dim=1)
y_pred = self.dnn(dense_in)
return {'y_true': y, 'y_pred': y_pred}
def compute_input_dim(self,
conv_channels,
pooling_sizes,
recombine_channels,
feature_dict,
embed_dim):
input_height = len(feature_dict)
num_fields = len(feature_dict)
for i in range(len(conv_channels)):
input_height = int(np.ceil(input_height / pooling_sizes[i]))
num_fields += input_height * recombine_channels[i]
input_dim = int(num_fields * (num_fields-1) / 2) + num_fields * embed_dim
return input_dim, num_fieldsFeature Generation by Convolutional Neural Network for
Click-Through Rate Prediction
FuxiCTR Github
