Intro
지금까지 이어져온 CTR 모델들의 핵심은 cross-product transformation을 통해 좋은 feature interaction을 생성하는 것이다. 기존 CTR 모델은 다음 세 가지 문제점을 가지고 있다. (1) feature engineering으로 시간이 오래 걸리고 (2) Training set에서 관측되지 않은 interaction에 대해서는 일반화(generalization)가 불가능하며 (3) 모델 성능 저하에 영향을 주는 불필요한 interaction도 포함한다. DNN에서는 implicit하게 higher-order interaction을 학습하기 때문에, interaction의 maximum degree와 같은 정보 또한 알 수 없다. xDeepFM은 DCN(Deep&Cross Network)과 같이 explicit한 방법으로 위의 문제를 해결한 모델을 제시한다.
논문에서 bit-wise란 용어가 등장하는데 여기서 bit는 latent vector의 element를 의미한다. (ex, )
Model
DCN에서 생성되는 interaction output 은 feature emedding 의 상수배이다. 번째 layer에 대한 증명은 아래와 같다.
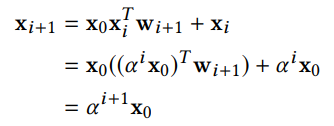
따라서 DCN의 interaction output은 특정 형태로 제한되어 있다(같은 크기). 이에 xDeepFM은 CIN(Compressed Interaction Network) 방법을 제안한다.
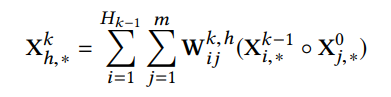
- : embedding output
- : k번째 CIN output, 처음에는 으로 시작 (: # feature vector, )
- : paramter matrkx (weight)
- ㅇ는 Hadamard product로 element-wise product이다.
수식만 보면 복잡해 보이지만 CNN 구조로 보면 훨씬 이해하기 쉽다.
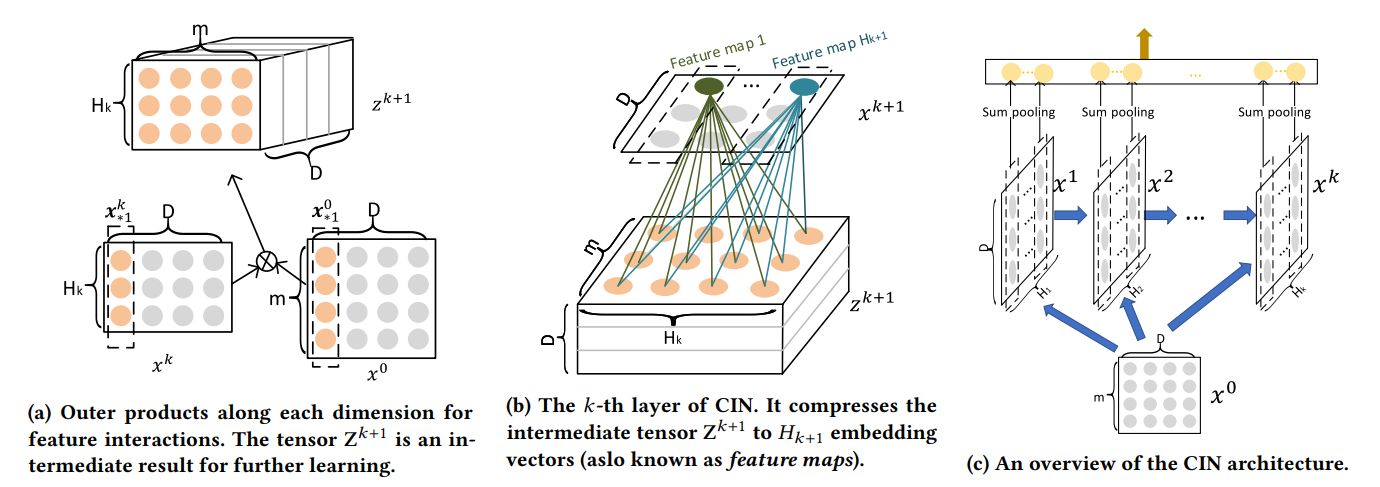
(a) 두 벡터 의 외적(Outer porudct)를 통해 을 생성한다. (는 개 channel을 가지는 image처럼 생각할 수 있다)
(b) (kenel로 생각할 수 있다)를 통해 feature map을 생성한다. 주어진 에 대해 개의 filter를 사용한다.
(c) 이 과정을 번 반복한다. 각 반복 과정에서 마다 개의 Feature map이 생성되고 Sum pooling을 통해 interaction feature을 생성한다.(따라서, 생성된 feature 수의 합은 다.)
xDeepFM의 전체 구조는 아래 그림과 같이 Linear, CIN, DNN의 조합으로 되어있다.
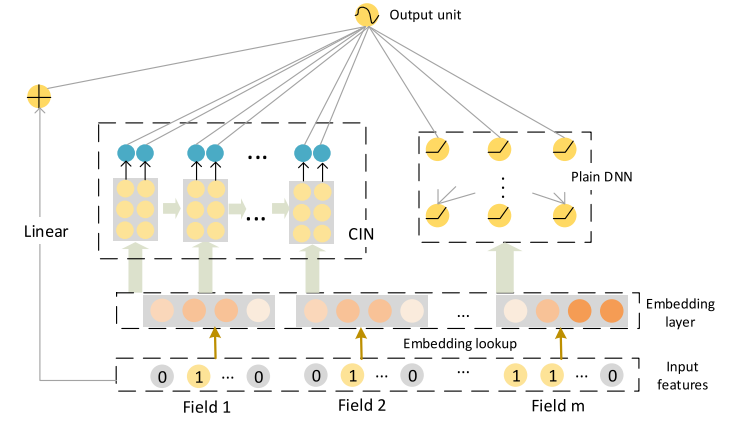
Note
- CIN에서 activation function이 없는 것을 확인할 수 있는데 이는 sigmoid, tanh, relu보다 identity function을 사용했을 때 성능이 가장 좋았기 때문이다.
- CIN의 layer 수는 2~3개부터 시작해보자. 4개 이상에서는 성능이 저하된다. (overfitting으로 추정)
Code
※ CTR 시리즈의 모든 코드는
FuxiCTR을 참고했으며 함수 구조와 이름 등은 개인적으로 수정하여 사용하였다.
-
feature_dict은 각 feature의 설명을 dictionary 형태로 담고 있는 dictionary이고,EmbeddingDict()은 각 field의 embedding vector를 반환하는ModuleDict()이다. ([batch_size, num_fields, embed_dim]의 stack 형태로 반환한다.) -
위의 그림에서처럼 torch.einsum과 torch.view를 통해 outer_product를 구하고 nn.Conv1d를 통해 CIN의 out을 생성한다. 마지막에 생성된 interaction을 nn.Linear를 통해 output을 리턴한다.
class CompressedInteractionNet(nn.Module):
def __init__(self, num_fields, H_size_list, output_dim=1):
super(CompressedInteractionNet, self).__init__()
self.H_size_list = H_size_list
self.cin_layers = nn.ModuleDict()
for i, unit in enumerate(self.H_size_list):
in_ch = num_fields * self.H_size_list[i-1] if (i > 0) else (num_fields ** 2)
out_ch = unit
self.cin_layers['layer_' + str(i+1)] = nn.Conv1d(in_ch, out_ch, kernel_size=1)
self.linear = nn.Linear(sum(H_size_list), output_dim)
def forward(self, X_emb):
X_0 = X_emb
batch_size = X_0.shape[0]
embed_dim = X_0.shape[-1]
X_i = X_0
pooling_outputs = []
for i in range(len(self.H_size_list)):
outer_product = torch.einsum('bhd,bmd->bhmd', X_0, X_i)
outer_product = outer_product.view(batch_size, -1, embed_dim)
X_i = self.cin_layers['layer_' + str(i+1)](outer_product).view(batch_size, -1, embed_dim)
pooling_outputs.append(X_i.sum(dim=-1))
concat_out = torch.cat(pooling_outputs, dim=-1)
return self.linear(concat_out)- LR(Linear), CIN, DNN을 각각 계산 후 더해준다. (필요에 따라 lr과 dnn은 넣거나 뺄 수도 있는데 개인적인 용도로 사용했을 땐 둘 다 포함했을 때 성능이 제일 좋았다.)
class xDeepFM(BaseModel):
def __init__(self, feature_dict, hidden_dim_list, H_size_list, embed_dim=CFG.embed_dim):
super(xDeepFM, self).__init__()
self._num_fields = len(feature_dict)
self.embedding = EmbeddingDict(feature_dict=feature_dict)
self.lr = LR(feature_dict)
self.cin = CompressedInteractionNet(self._num_fields, H_size_list, output_dim=1)
self.dnn = DNNLayer(input_dim=self._num_fields * embed_dim,
hidden_dim_list=hidden_dim_list)
# training method
# self.compile(CFG.optimizer, CFG.loss, CFG.learning_rate)
# self.init_params()
# self.model_to_device()
def forward(self, inputs):
X, y = self.inputs_to_device(inputs)
X_emb = self.embedding(X)
y_pred = self.lr(X) + self.cin(X_emb) + self.dnn(X_emb.flatten(start_dim=1))
return {'y_true': y, 'y_pred': y_pred}xDeepFM: Combining Explicit and Implicit Feature Interactions
for Recommender Systems
FuxiCTR Github
