🚩로컬에 S3구축, log 데이터 넣어보기
https://velog.io/@kidae92/%EB%8F%84%EC%BB%A4%EB%A1%9C-Spark-Zepplein-%EC%84%B8%ED%8C%85%ED%95%98%EA%B8%B0 에서는 Zeppelin과 spark를 도커로 띄워보았다.
원래는 아래 그림과 같이 kafka connector를 구축하는 공부를 하고 있었는데, localstack이라는 AWS 환경을 구축할 수 있는 것을 알게 되어서, 공부하는 김에 S3 구축을 진행 해보았다.
아래코드는 원래 공부하던 것이어서 kafka, zookeeper 등 여기서는 안쓰는 코드가 있긴하다.. 👓
아래 코드를 docker-compose를 이용하여 컨테이를 띄우면 된다.
kafka에 대한 오류가 발생할지 모르나, 여기서는 무시해도 무관하다!

version: '3'
services:
zookeeper-1:
hostname: zookeeper1
image: confluentinc/cp-zookeeper:6.2.0
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 12181
ZOOKEEPER_DATA_DIR: /zookeeper/data
ZOOKEEPER_SERVERS: zookeeper1:22888:23888;zookeeper2:32888:33888;zookeeper3:42888:43888
ports:
- 12181:12181
- 22888:22888
- 23888:23888
volumes:
- ./zookeeper/data/1:/zookeeper/data
zookeeper-2:
hostname: zookeeper2
image: confluentinc/cp-zookeeper:6.2.0
environment:
ZOOKEEPER_SERVER_ID: 2
ZOOKEEPER_CLIENT_PORT: 22181
ZOOKEEPER_DATA_DIR: /zookeeper/data
ZOOKEEPER_SERVERS: zookeeper1:22888:23888;zookeeper2:32888:33888;zookeeper3:42888:43888
ports:
- 22181:22181
- 32888:32888
- 33888:33888
volumes:
- ./zookeeper/data/2:/zookeeper/data
zookeeper-3:
hostname: zookeeper3
image: confluentinc/cp-zookeeper:6.2.0
environment:
ZOOKEEPER_SERVER_ID: 3
ZOOKEEPER_CLIENT_PORT: 32181
ZOOKEEPER_DATA_DIR: /zookeeper/data
ZOOKEEPER_SERVERS: zookeeper1:22888:23888;zookeeper2:32888:33888;zookeeper3:42888:43888
ports:
- 32181:32181
- 42888:42888
- 43888:43888
volumes:
- ./zookeeper/data/3:/zookeeper/data
kafka-1:
image: confluentinc/cp-kafka:6.2.0
hostname: kafka1
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper1:12181,zookeeper2:22181,zookeeper3:32181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka1:19092
KAFKA_LOG_DIRS: /kafka
ports:
- 19092:19092
volumes:
- ./kafka/logs/1:/kafka
kafka-2:
image: confluentinc/cp-kafka:6.2.0
hostname: kafka2
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper1:12181,zookeeper2:22181,zookeeper3:32181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka2:29092
KAFKA_LOG_DIRS: /kafka
ports:
- 29092:29092
volumes:
- ./kafka/logs/2:/kafka
kafka-3:
image: confluentinc/cp-kafka:6.2.0
hostname: kafka3
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper1:12181,zookeeper2:22181,zookeeper3:32181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka3:39092
KAFKA_LOG_DIRS: /kafka
ports:
- 39092:39092
volumes:
- ./kafka/logs/3:/kafka
connect-1:
hostname: connect1
image: confluentinc/cp-kafka-connect:6.2.0
depends_on:
- kafka-1
- kafka-2
- kafka-3
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka1:19092,kafka2:29092,kafka3:39092
CONNECT_REST_ADVERTISED_HOST_NAME: connect1
CONNECT_GROUP_ID: default-connect-group
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_CONFIG_STORAGE_TOPIC: config
CONNECT_OFFSET_STORAGE_TOPIC: offset
CONNECT_STATUS_STORAGE_TOPIC: status
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-components
CONNECT_REST_PORT: 8083
ports:
- 18083:8083
volumes:
- ./connectors/1:/usr/share/confluent-hub-components
command:
- bash
- -c
- |
confluent-hub install --no-prompt confluentinc/kafka-connect-s3:10.0.3
confluent-hub install --no-prompt debezium/debezium-connector-mysql:1.7.0
/etc/confluent/docker/run &
sleep infinity
localstack-1:
hostname: localstack1
image: localstack/localstack:latest
environment:
AWS_DEFAULT_REGION: us-east-2
EDGE_PORT: 4566
SERVICES: s3
AWS_ACCESS_KEY_ID: test
AWS_SECRET_ACCESS_KEY: test
ports:
- 4566:4566
volumes:
- ./localstack:/tmp/localstack
mysql-1:
hostname: mysql1
image: mysql/mysql-server:5.7
ports:
- 3306:3306
environment:
MYSQL_USER: root
MYSQL_ROOT_HOST: "%%"
MYSQL_DATABASE: test
MYSQL_ROOT_PASSWORD: test
command: mysqld
--server-id=1234
--max-binlog-size=4096
--binlog-format=ROW
--log-bin=bin-log
--sync-binlog=1
--binlog-rows-query-log-events=ON
volumes:
- ./mysql:/var/lib/mysql🚩 localstack S3 사용해보기
docker-compose 후 아래 그림과 같이 localstack 컨테이너가 뜨게 된다.

1. CentOS8에서 진행을 했으며, localstack을 사용하기 위해서는 aws-cli를 설치해야 한다.
https://docs.aws.amazon.com/ko_kr/cli/latest/userguide/install-cliv2-mac.html#cliv2-mac-install-cmd
공식홈페이지를 참고하여 설치를 진행했다.
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install2. 그리고 환경변수 설정을 해야하는 경우에는
vi ~/.bash_profile # 여기서 export PATH=$PATH:/usr/local/bin 를 추가해준다.
source ~/.bash_profile
aws --version # 출력이 잘 되면 성공한 것이다.3. aws cli 설정 및 bucket 생성, object 넣기
aws configure #를 입력하면 AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY ,AWS_DEFAULT_REGION를 입력하라고 나오는데 docker-compose.yml에 localstack의 enviroment에 있는것을 작성해줬다.
# bucket 생성
aws s3api create-bucket --bucket test --endpoint-url=http://localhost:4566
# bucket 확인
aws s3 --endpoint-url=http://localhost:4566 ls
# object 업로드
aws s3api put-object --bucket honglog --body ./hello.txt --key test --endpoint-url=http://localhost:4566 # body쪽은 경로가 들어갸야한다. 나는 임의의 hello.txt라는 파일을 만들어서 넣어보았다.
# bucket 내 object list up
aws s3api list-objects --endpoint-url=http://localhost:4566 --bucket test
# object 다운로드
aws s3api get-object --endpoint-url=http://localhost:4566 --bucket test --key test output.txt # test key를 가진 hello.txt 파일을 output.txt로 다운 받는다💡 test라는 bucket 생성 
💡 bucket 확인 
💡 test.txt라는 object 업로드 
💡 bucket 내 object list up 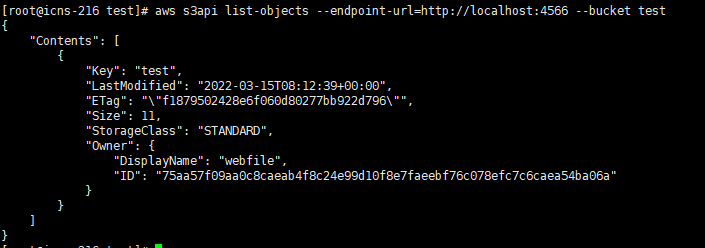
💡 object 다운로드 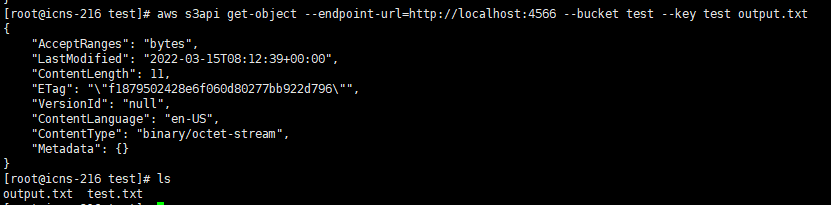
🚩S3에 다량의 Log-Data 넣기
csv.gz 형식을 가진 로그데이터가 있어서 이를 localstack 내 S3에 넣어보았다.
위의 명령어처럼 put-object에서 --body쪽에 *.csv.gz 식으로 넣겠다고 하면 옳지 않은 명령어라고 뜬다.
# 다중 업로드(현재 디렉토리에서 ./logs 폴더 내 위 데이터들을 한번에 넣기)
aws --endpoint-url=http://localhost:4566 s3 cp --recursive ./logs/ s3://bucketname
# 내용물 들어있는 bucket 강제 삭제
aws --endpoint-url=http://localhost:4566 s3 rb s3://bucketname --force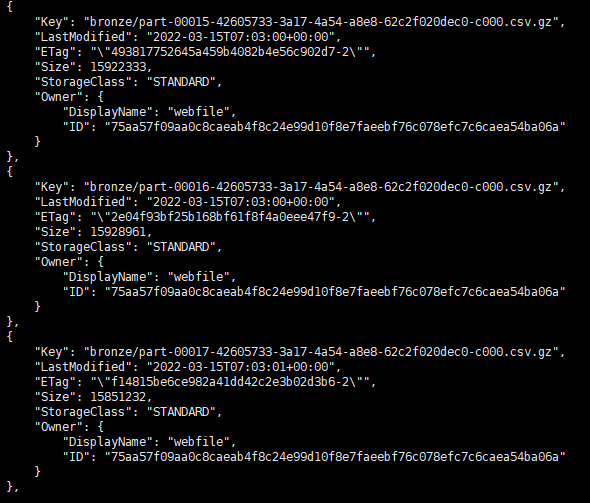
이런식으로 잘 들어 간것을 볼 수 있다. 키를 bronze라고 주고 그 아래에 로그파일들을 넣어놨는데, 데이터에도 급이 있는 것을 본거 같다.(브론즈, 실버, 골드 ??) 이런식으로 똑같이 데이터를 정제시켜 볼 예정이다.
눈치 챘을지는 몰라도 위 명령어들 중에는 aws s3가 있고 aws s3api가 있는데  사진에서 보다 시피 상위 수준의 s3명령이 있고 API수준의 s3 API명령이 있었다; (https://docs.aws.amazon.com/ko_kr/cli/latest/userguide/cli-services-s3-apicommands.html) 상위수준의 s3 명령어가 확실히 더 많은 기능을 제공해준다..
사진에서 보다 시피 상위 수준의 s3명령이 있고 API수준의 s3 API명령이 있었다; (https://docs.aws.amazon.com/ko_kr/cli/latest/userguide/cli-services-s3-apicommands.html) 상위수준의 s3 명령어가 확실히 더 많은 기능을 제공해준다..
지금 로컬 스택에서 파일 불러오는 과정에서 오류가 발생하여.. 추후 추가할 예정이다.
