연산함수
COUNT(칼럼명) : 갯수
SUM(칼럼명) : 합
AVG(칼럼명) : 평균
MIN(칼럼명) : 최솟값
MAX(칼럼명) : 최댓값
ABS(칼럼명) : 절댓값
문자열 함수
CONCAT("문자열1","문자열2") => 문자열1문자열2 : 문자열을 합치는 함수
LEFT : 문자에 왼쪽을 기준으로 일정 갯수를 가져오는 함수.
=> LEFT(문자, 가져올 갯수)
MID : 문자에 지정한 시작 위치를 기준으로 일정 갯수를 가져오는 함수. = SUBSTRING,SUBSTR
=> MID(문자, 시작 위치, 가져올 갯수)
RIGHT : 문자에 오른쪽을 기준으로 일정 갯수를 가져오는 함수.
=> RIGHT(문자, 가져올 갯수)
집계함수
ABS(숫자) : 절대값
CEIL(숫자) : 소수점 이하 올림
FLOOR(숫자) : 소수점 이하 버림
ROUND(숫자, 자릿수) : 자릿수를 기준으로 반올림 => 자연수는 0
TRUNCATE(숫자, 자릿수) : 자릿수를 기준으로 버림
날짜 함수
YEAR(날짜) : 범위 1000~9999까지에 대한 년을 반환합니다.
MONTH(날짜) : 범위 1~12까지에 대한 월을 반환합니다.
DATE(날짜) : 주어진 날짜, 시간의 날짜 부분을 반환합니다. => -> 2011-10-09
날짜 포맷함수
- DATE_FORMAT('날짜데이터', '출력날짜형식지정')
%Y 년도 (2021)
%y 년도 (21)
%M 월 (January, August)
%m 월 (01, 02, 11)
%c 월 (1, 8)
%b 월(Jan, Aug)
%D 일 (1st,2nd,3rd)
%d 일(01, 19)
%e 일(1, 19)
%W 요일(Wednesday, friday)
%a 요일(Wed, Fri)
%T 시간 (12:30:00)
%r 시간 (12:30:00 AM)
%H 24시간 시간(01, 14, 18)
%l 12시간 시간 (01, 02, 06)
%i 분 (00)
%S 초 (00)
JOIN
SELECT A.column1, B.column2
FROM TableA A JOIN TableB B
ON A.common_column = B.common_column;- INNER JOIN
두 테이블에서 공통된 값을 기준으로 데이터가 결합됩니다. 일치하는 값이 있는 행만 반환 - LEFT JOIN (또는 LEFT OUTER JOIN)
- RIGHT JOIN
오른쪽 테이블의 모든 행을 반환하고, 왼쪽 테이블에서 일치하는 값이 없으면 NULL을 반환 - FULL OUTER JOIN (MySQL에서 직접 지원하지 않음)
두 테이블의 모든 행을 반환하고, 일치하지 않는 값이 있는 경우 NULL을 반환합니다.
MySQL에서는 FULL OUTER JOIN을 직접 지원하지 않지만, UNION을 사용하여 구현할 수 있습니다. - CROSS JOIN
두 테이블의 모든 가능한 조합을 반환 - UNION
여러 개의 SELECT 문의 결과를 단일 결과 세트로 연결 표현할떄 사용
- 합친 결과에서 중복되는 행은 하나만 표시 => DISTINCT 키워드를 따로 명시하지 않아도 기본적으로 중복되는 레코드를 제거
- UNION 내의 각 SELECT 문은 같은 수의 열을 가져야 한다.
- 각각 SELECT 문의 열은 또한 동일한 순서로 있어야 한다.
- 열은 호환되는 데이터 형식을 가져야 한다
SELECT * FROM A
UNION (ALL)
SELECT * FROM B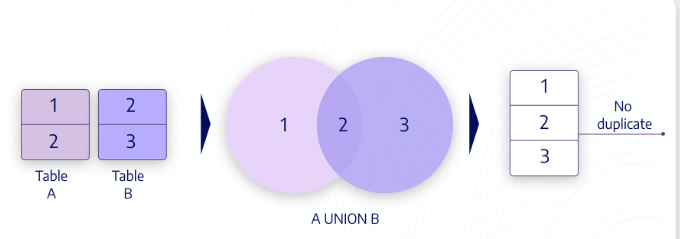
LIKE
문자열을 비교할 때 패턴 매칭을 사용하여 부분적인 일치 여부를 확인하는 데 사용
와일드카드 문자
%: 0개 이상의 임의의 문자와 일치.
_: 정확히 1개의 임의의 문자와 일치.
NULL 함수
- IFNULL : 해당 Column의 값이 NULL을 반환할 때, 다른 값으로 출력할 수 있도록 하는 함수
=> IFNULL(Column명, "Null일 경우 대체 값") - ISNULL : 표현식1 의 결과값이 NULL 이면 표현식2의 값을 출력
=> ISNULL(표현식1, "Null일 경우 대체 값") - IS NULL : NULL 값은 WHERE 절에서 찾을 수 없다, NULL 값을 찾을 때 사용
GROUP BY, HAVING
GROUP BY와 함께 사용되며, WHERE 절과 유사하지만, 중요한 차이점은 HAVING은 집계 함수에 대한 조건을 필터링이 가능하다.
GROUP BY USER_ID, PRODUCT_ID
HAVING COUNT(*) >= 2ORDER BY, LIMIT
- ORDER BY : 특정 열(컬럼)을 기준으로 결과 집합을 정렬합니다.
=> 기본적으로 오름차순(ASC)으로 정렬됩니다. 내림차순 정렬을 원할 경우 DESC 키워드를 사용 - LIMIT : 결과 집합의 최대 행 수를 제한합니다. 주로 페이지네이션이나 대량 데이터 처리 시 사용
SELECT name, age FROM users
ORDER BY age DESC
LIMIT 5;→ age 기준으로 내림차순으로 정렬된 결과에서 상위 5개의 행만 반환- OFFSET : LIMIT와 함께 자주 사용되는 절로, 결과 집합에서 몇 개의 행을 건너뛸지를 지정
SELECT name, age
FROM users
ORDER BY age ASC
LIMIT 5 OFFSET 10;→ age 기준으로 오름차순으로 정렬된 결과에서 10개의 행을 건너뛰고 그 다음 5개의 행만 반환NULL 처리
- NULL AS : 특정 칼럼이나 표현식의 결과가 없을 때 NULL 값을 할당하기 위해 사용
SELECT column1, NULL AS column2 FROM table_name;