-
데이터에 편리하게 접근하고, 변경하기 위해서 데이터를 저장하거나 조직하는 방법 을 말합니다.
-
모든 목적에 맞는 자료구조는 없다 => 데이터를 알맞은 구조 에 넣는것이 중요.
자료구조의 분류
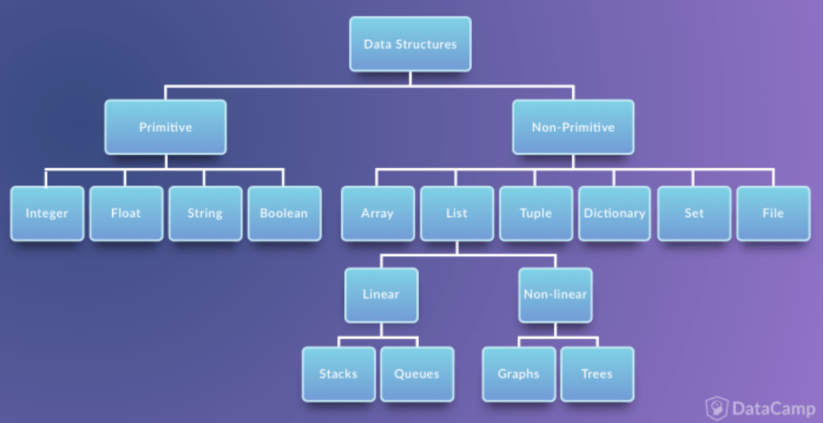
일반적으로 자료구조라 하면, Non-Primitive를 자료구조라 한다.
일반적으로 가장 자주 사용되는 자료구조들
-
Array(파이썬에서는 List)
-
Tuple
-
Set
-
Dictionary
-
Stack & Queue
-
Tree
=> 이중 내가 쓸 데이터에 적용하였을때, 가장 효과적인 데이터구조를 써야한다.
Array
Array의 내부 구조
Array가 순차적으로 데이터를 저장할 수 밖에 없는 이유가 있습니다. 그건 바로 실제 메모리 상에서 순차적(물리적으로 바로 옆)으로 저장되기 때문입니다.
=> 순서가 있기 때문에 index가 있다
=> 때문에 특정 요소를 array(list)로 부터 읽어들일 수 있습니다.
=>특정요소를 빠르게 잃어야할 때
=> 순차적인 내용을 저장할 때
단점:삭제할 때 단점 => 중간에 뭔가를 변경해야하는 데이터 유형이면 맞지않다.
=>resizing(메모리 재할당) -> 애초에 메모리를 확보한 상태로 array가 만들어진다.(default size) 따라서 메모리보다 클 경우 새로운 메모리를 다시 만들고 거기에 원래의 array를 붙여넣은 다음 새롭게 추가되는 배열의 index를 추가한다.
Tuple
List와 마찬가지로 데이터를 순차적으로 저장할 수 있는 순열 자료구조.
하지만 list와 틀리게 수정 할 수 없다 (immutable)
주로 2나 5개 정도의 소규모 데이터를 저정할 때 쓰입니다,
함수에서 리턴 값을 한개 이상 리턴 하고 싶을때 자주 쓰입니다.
=> 간단한 값들을 빨리 표현하고 싶을때 쓴다.
=> 좌표에서 많이 사용한다.
=>
List Set의 차이
=> set는 순서가 없다.
=> 중복된 값을 허용되지 않는다.
=> A가 들어왔다면 hash 값이 나오고 그걸 버켓(berket?)에 저장된다.
똑같은 A가 들어왔다면 같은 hash 값이 나와서 버켓에 저장(치환)된다.
=> 밑단에..... array
Dictionary / HashMap / HashTable
=>set는 값 자체가 헤시로 저장 따라서 중복된 값 저장이 되지 않는다.
=> Dictionary는 키를 헤시로 저장 => 중복된 키는 저장되지않고 치환한다.
When To Use Dictionary
마치 데이터베이스 처럼 키와 값을 묶어서 데이터를 표현해야 할때 유용하다. 실제로 데이터베이스 에서 읽어들인 값을 dictionary로 변환해서 사용 자주 함.
해당 데이터에 대한 필드를 주기 위해서
=> 그렇다면 왜 치환할까????
1==1 -> true
"A" == "A" -> true
ex1)
Cord(1,2) == Cord(1,2) -> false
->why???? 메모리 주소가 다르다.
이건 = 을 어떻게 정의하느냐에 따라서 다르다.
내가 나의 class에서 주소값이 아닌 실제 x,y값을 비교하는 로직을 짜면 true!
ex2)
객체...가 새로들어오면 완벽히 같다고는 할 수 없기에-> 치환한다~!
stack
first in last out => filo
밑단에는 array를 사용한다 Y? 메모리에 바로 접근하기 때문
함수(함수(함수))는 stack에 저장된다. 함수를 로드할 때 쓰임
Y? A(B(C())) -> C->B->A 순으로 실행되어야하니까! 순서!
- 브라우저-> 뒤로가기
Queue
삼각지 몽탄 (줄서기)
first in first out => fifo
밑단에는 array~ + 로직
항상 순서대로 처리하기에는 무리가 있을 수 있따.
priority queue
우선순위가 들어간 queue
항상 순서대로 처리하기에는 무리가 있을 수 있다.
OS 프로세스 스케쥴링 시스템 (priority queue 사용)
->1개의 cpu에서 여러개의 프로그램을 돌릴때, 사용/ 필수적인 프로그램을 먼저 구동하는 곳에 쓰이는 자료구조!
tree
작은값은 왼쪽 큰값은 오른쪽
=> 정렬이 안된 상태로 저장해여함
정렬이 되면 그건 array이다
이진트리
검색을 효율적으로 할 수 있습니다.
list( O(N))였다면 최악의 경우 array.length 만큼 해야할 수도 있기때문이다.
tree(O(log N))

set(O(1)) set에 몇개가 있던지 바로 찾을 수 이싿.
N으로 검색의 속도를 표시(그래프)
set는 아예 순서가 없음, tree는 어느정도 순서가 있다.
그럼 문자는 어떻게 tree로 구분하나?
"A" < "C" 는 t or f?
true가 나온다 => 시스템은 2진법이기 때문에 A의 값과 C의 값을 비교한 것이다.
Linked list
list는 물리적으로 순차적으로 저장해야함
따라서 애초에 메모리 공간을 확보해야한다, 이런 제약을 없앤것이
Linked list 이다.
<A --어딘가의 메모리를 참조 --> B --어딘가의 메모리를 참조 --> C>
이런식으로 저장
=> 메모리 리사이징의 문제는 없다 효율성이 좋아진다.
but 단점은 메모리 비용이 늘어남 Y? 한 값이 클래스로 저장되기 때문에
