연산코드와 오퍼랜드
명령어는 '무엇을 대상으로, 어떤 작동을 수행하라'는 구조로 되어 있다.
아래 그림을 보면 색 배경 필드는 명령어의 '작동', 달리 말해 '연산'을 담고 있고 흰색 배경 필드는 '연산에 사용할 데이터' 또는 '연산에 사용할 데이터가 저장된 위치'를 담고 있다.

명령어는 연산 코드와 오퍼랜드로 구성되어 있다. 색 배경 필드 값, 즉 '명령어가 수행할 연산'을 연산 코드라 하고, 흰색 배경 필드 값, 즉 '연산에 사용할 데이터'또는 '연산에 사용할 데이터가 저장된 위치'를 오퍼랜드라고 한다. 연산 코드는 연산자. 오퍼랜드는 피연산자라고도 부른다.
이를 간단한 그림으로 표현하면 명령어는 아래처럼 그릴 수 있다. 색칠한 부분 = 연산 코드가 담기는 영역 연산 코드 필드라고 부른다. 그리고 색칠되지 않는 부분 = 오퍼랜드가 담기는 영역오퍼랜드 필드이다.

기계어와 어셈블러이 또한 명령어이기 때문에 연산 코드와 오퍼랜드로 구성되어 있다. 붉은 글씨가 연산코드, 검은 글씨가 오퍼랜드이다.

오퍼랜드
'연산에 사용할 데이터'또는 '연산에 사용할 데이터가 저장된 위치'를 의한다고 했다. 그래서 오퍼랜드 필드에는 숫자와 문자 등을 나타내는 데이터 또는 메모리나 레지스터 주소가 올 수 있다. 다만 오퍼랜드 필드에는 숫자나 문자와 같이 연산에 사용할 데이터를 직접 명시하기보다는, 많은 경우 연산에 사용할 데이터가 저장된 위치, 즉 메모리 주소나 레지스터 이름이 담긴다. 그래서 오퍼랜드 필드를 주소 필드라고 부르기도 한다.
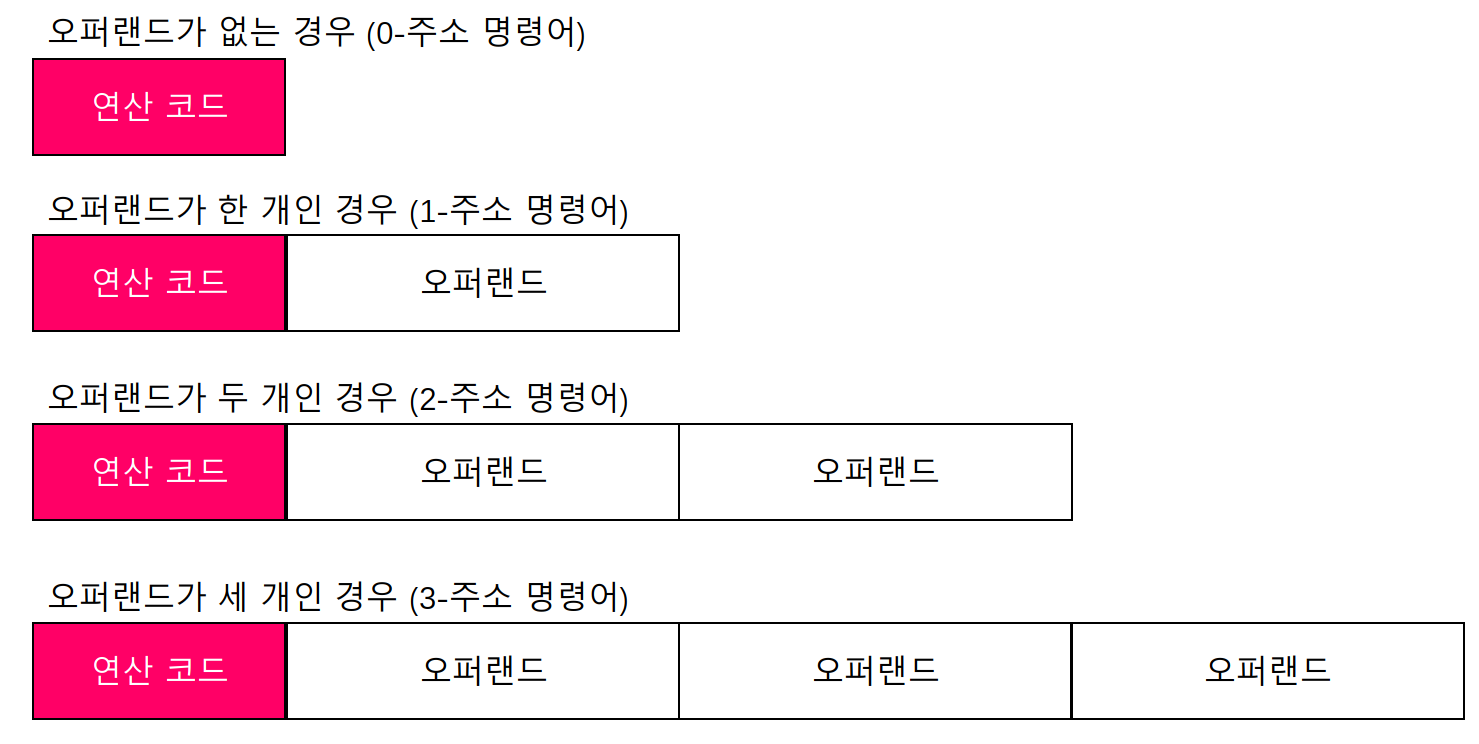
오퍼랜드는 명령어 안에 하나도 없을 수도 있고, 한 개만 있을 수도 있고, 두개 또는 세 개 등 여러개가 있을 수도 있다.
mov eax, 0 -> 오퍼랜드가 두 개인 경우
pop rbp -> 오퍼랜드가 한 개인 경우
ret -> 오퍼랜드가 없는 경우여기서 오퍼랜드가 하나도 없는 명령어를 0-주소 명령어라고 하고, 오퍼랜드가 하나인 명령어를 1-주소 명령어, 두 개인 명령어를 3-주소 명령어라고 한다.
연산 코드
연산 코드는 명령어가 수행할 연산을 의미한다. 연산 코드 종류는 매우 많지만, 가장 기본적인 연산 코드 유형은 크게 네 가지로 나눌 수 있다.
1. 데이터 전송
2. 산술/논리 연산
3. 제어 흐름 변경
4. 입출력 제어
이 네 가지 유형 각각에 해당하는 대표적인 연산 코드를 알아보자. 명령어의 종류와 생김새는 CPU마다 다르기 떄문에 연산 코드의 종류와 생김새 또한 CPU마다 다르다. 이 설명은 CPU가 공통으로 이해하는 대표적인 연산 코드의 종류 정도로만 이해 해도 무방하다.
데이터 전송
- MOVE : 데이터를 옮긴다.
- STORE : 메모리에 저장하라.
- LOAD(FETCH) : 메모리에서 CPU로 데이터를 가져와라
- PUSH : 스택에 데이터를 저장하라
- POP : 스택의 최상단 데이터를 가져와라
산술/논리 연산
- ADD / SUBTRACT / MULTIPLY / DIVIDE : 덧셈 / 뺄셈 / 곱셈 / 나눗셈을 수행하라
- INCREMENT / DECREMENT : 오퍼랜드에 1을 더하라 / 오퍼랜드에 1을 빼라
- AND / OR / NOT : AND/OR/NOT 연산을 수행하라
- COMPARE : 두 개의 숫자 또는 TRUE/FALSE 값을 비교하라
제어 흐름 변경
- JUMP : 특정 주소로 실행 순서를 옮겨라
- CONDITIONAL JUMP : 조건에 부함할 때 특정 주소로 실행 순서를 옮겨라
- HALT : 프로그램의 실행을 멈춰라
- CALL : 되돌아올 주소를 저장한 채 특정 주소로 실행 순서를 옮겨라
- RETURN : CALL을 호출할 때 저장했던 주소로 돌아가라
입출력 제어
- READ(INPUT) : 특정 입출력 장치로부터 데이터를 읽어라
- WRITE(OUTPUT) : 특정 입출력 장치로 데이터를 써라
- START IO : 입출력 장치를 시작하라
- TEST IO : 입출력 장치의 상태를 확인하라
주소 지정 방식
왜 오퍼랜드 필드에 메모리나 레지스터의 주소를 담는 걸까? 그냥 연산 코드나 연산 코드에 사용될 데이터 형식으로 명령어를 구성하면 되지 않을까라는 의문이 든다면 이는 명령어의 길이 때문이다.
하나의 명령어가 n비트로 구성되어 있고, 그중 연산 코드 필드가 m비트라고 가정해 본다면 이때 오퍼랜드 필드에 가장 많은 공간을 할당할 수 있는 1-주소 명령어라 할지라도 오퍼랜드 필드의 길이는 연산 코드만큼의 길이를 뺀 n-m비트가 된다. 2주소,3주소 명령어라면 크기는 더욱 작아진다.
가령 명령어의 크기가 16비트, 연산 코드 필드가 4비트인 2-주소 명령어에서는 오퍼랜드 필드당 6비트 정도밖에 남지 않는다. 즉, 하나의 오퍼랜드 필드로 표현할 수 있는 정보의 가짓수는 2^6개 밖에 되지 않는다.
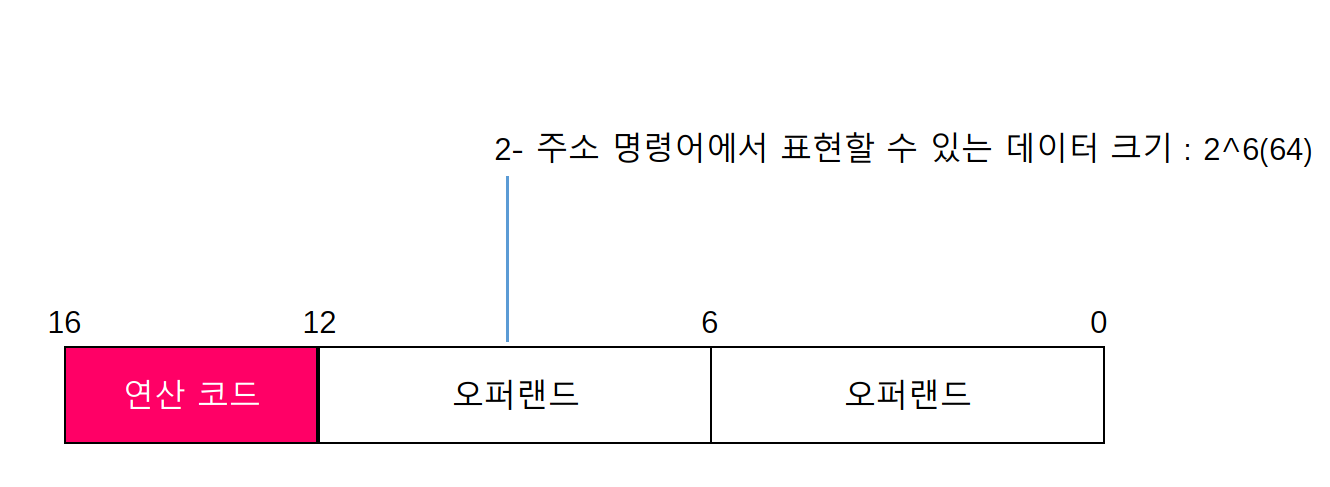 그리고 명령어의 크기가 16비트, 연산 코드 필드가 4비트인 3-주소명령어에서는 오퍼랜드 필드당 4비트 정도밖에 남지 않는다. 이 경우 하나의 오퍼랜드 필드로 표현할 수 있는 정보의 가짓수는 2^4개밖에 없다.
그리고 명령어의 크기가 16비트, 연산 코드 필드가 4비트인 3-주소명령어에서는 오퍼랜드 필드당 4비트 정도밖에 남지 않는다. 이 경우 하나의 오퍼랜드 필드로 표현할 수 있는 정보의 가짓수는 2^4개밖에 없다.

하지만 만약 오퍼랜드 필드 안에 메모리 주소가 담긴다면 표현할 수 있는 데이터의 크기는 하나의 메모리 주소에 저장할 수 있는 공간만큼 커진다.
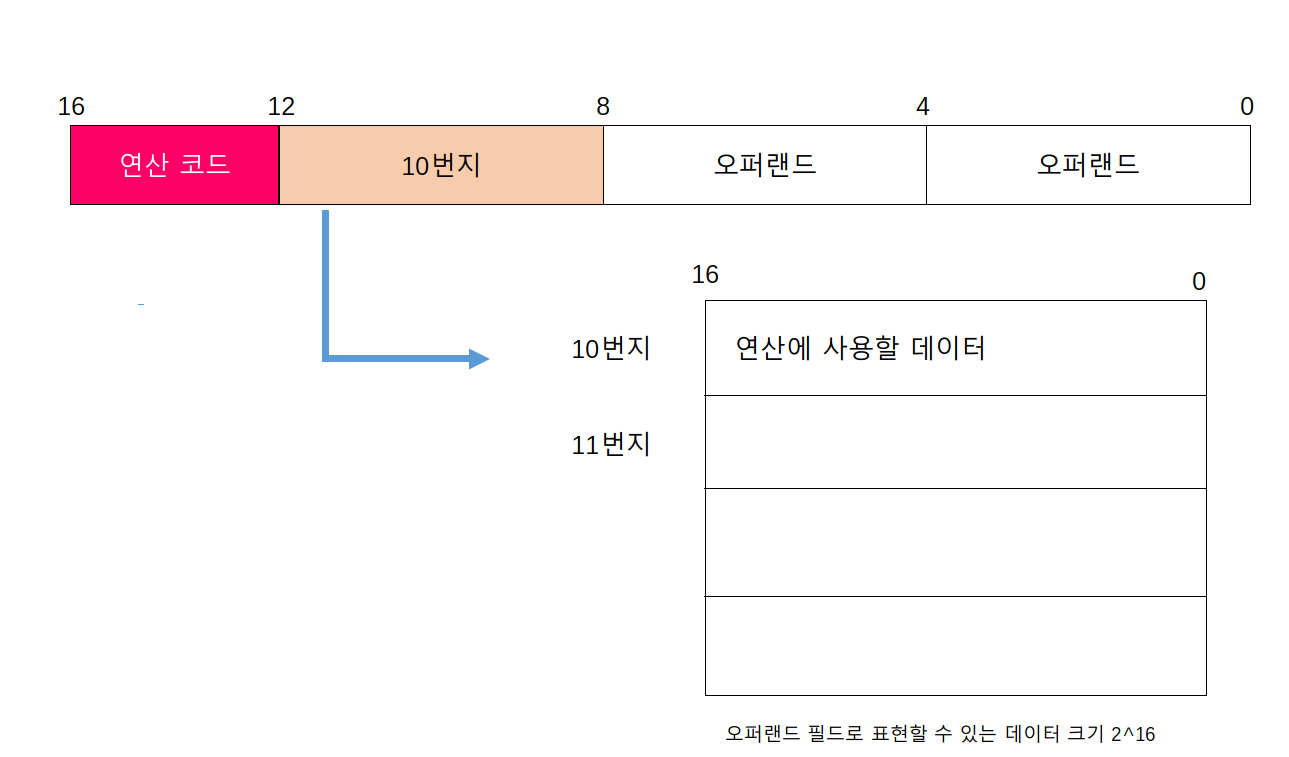
예를 들어 한 주소에 16비트를 저장할 수 있는 메모리가 있다고 가정하고 이 메모리 안에 데이터를 저장하고, 오퍼랜드 필드 안에 해당 메모리 주소를 명시한다고 표현할 수 있는 정보의 가짓수가 2^16으로 확 커질수 있다.
오퍼랜드 필드에 메모리 주소가 아닌 레지스터 이름을 명시할 때도 마찬가지다.이 경우 표현할 수 있는 정보의 가짓수는 해당 레지스터가 저장할 수 있는 공간만큼 커진다.
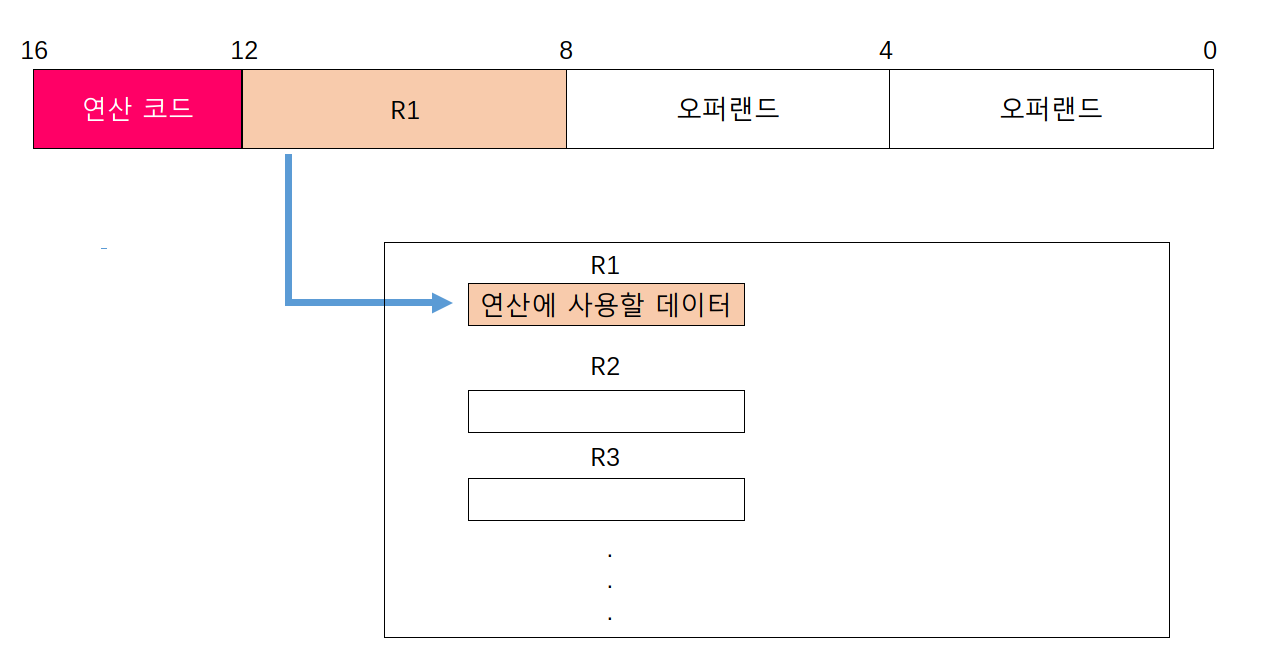
연산 코드에 사용할 데이터가 저장된 위치, 즉 연산의 대상이 되는 데이터가 저장된 위치를 유효 주소라고 한다. 첫 번째 그림의 경우 유효 주소는 10번지, 두 번째 그림의 경유 유효 주소는 레지스터 R1이다.
이렇듯 오퍼랜드 필드에 데이터가 저장된 위치를 명시할 때 연산에 사용할 데이터 위치를 찾는 방법을 주소 지정 방식이라고 한다. 다시 말해, 주소 지정 방식은 유효 주소를 찾는 방법이다.
현대 CPU는 다양한 주소 지정 방식을 사용한다. 대표적인 주소 지정 방식은 다섯 가지가 있다.
즉시 주소 지정 방식
연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식. 가장 간단한 형태의 주소 지정 방식. 표현할 수 있는 데이터의 크기가 작아지는 단점이 있다. 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없기 때문에 다른 주소 지정 방식들보다 빠르다.

직접 주소 지정 방식
오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식이다. 오퍼랜드 필드에서 표현할 수 있는 데이터의 크기는 즉시 주소 지정 방식보다 더 커졌지만, 여전히 유효 주소를 표현할 수 있는 범위가 연산 코드의 비트 수만큼 줄어들었다. 다시 말해 표현할수 있는 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아져 표현할 수 있는 유효 주소에 제한이 생길 수 있다.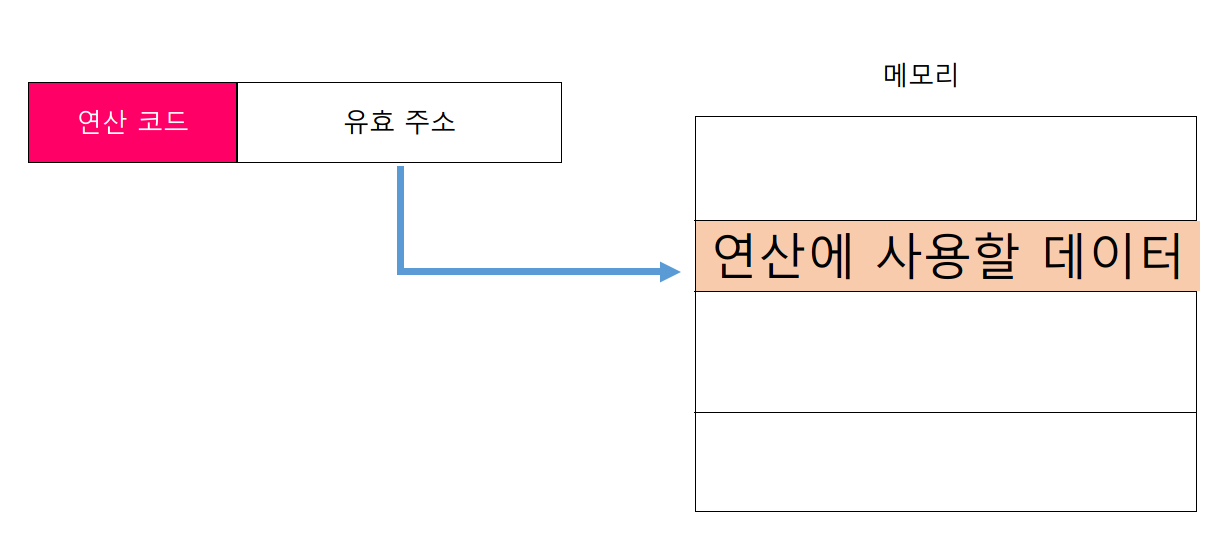
간접 주소 지정 방식
유효 주소의 주소를 오퍼랜드 필드에 명시한다. 직접 주소 지정 방식보다 표현할 수 있는 유효 주소의 범위가 더 넓다. 다만 두 번의 메모리 접근이 필요하기 때문에 앞서 설명한 주소 지정 방식들 보다 일반적으로 느린 방식이다.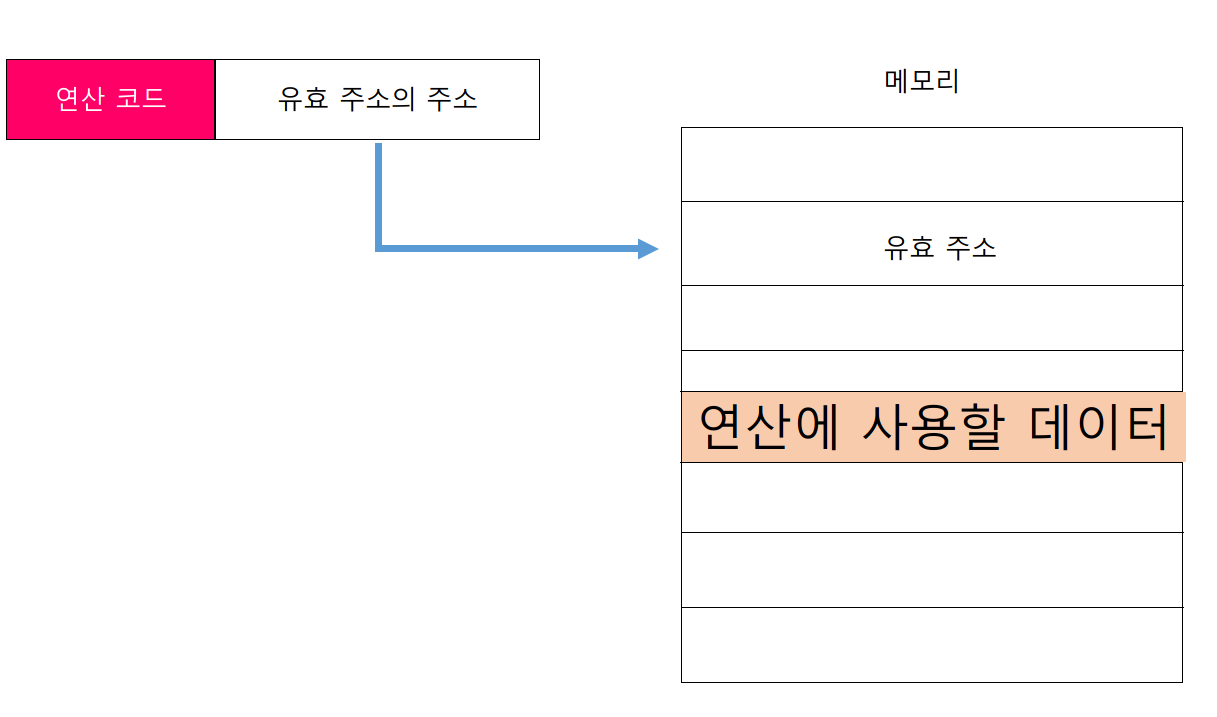
때때로 연산에 사용할 데이터가 레지스터에 저장된 경우도 있다. 이 경우 레지스터 주소 지정 방식 또는 레지스터 간접 주소 지정 방식을 사용할 수 있다.
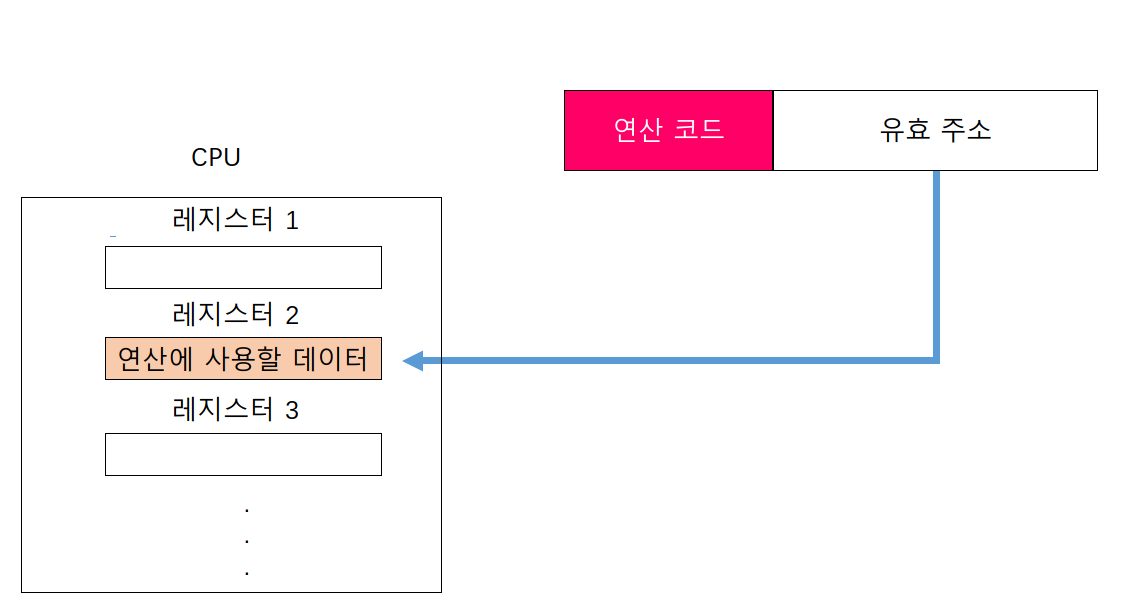
레지스터 주소 지정 방식
직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방법이다.
일반적으로 CPU 외부에 있는 메모리에 접근하는 것보다 CPU 내부에 있는 레지스터에 접근하는 것이 더 빠르다. 그러므로 레지스터 주소 지정 방식은 직접 주소 지정방식보다 빠르게 데이터에 접근할 수 있다. 다만, 레지스터 주소 지정 방식은 직접 주소 지정 방식과 비슷한 문제를 공유한다. 표현할 수 있는 레지스터 크기에 제한이 생길 수 있다는 것.
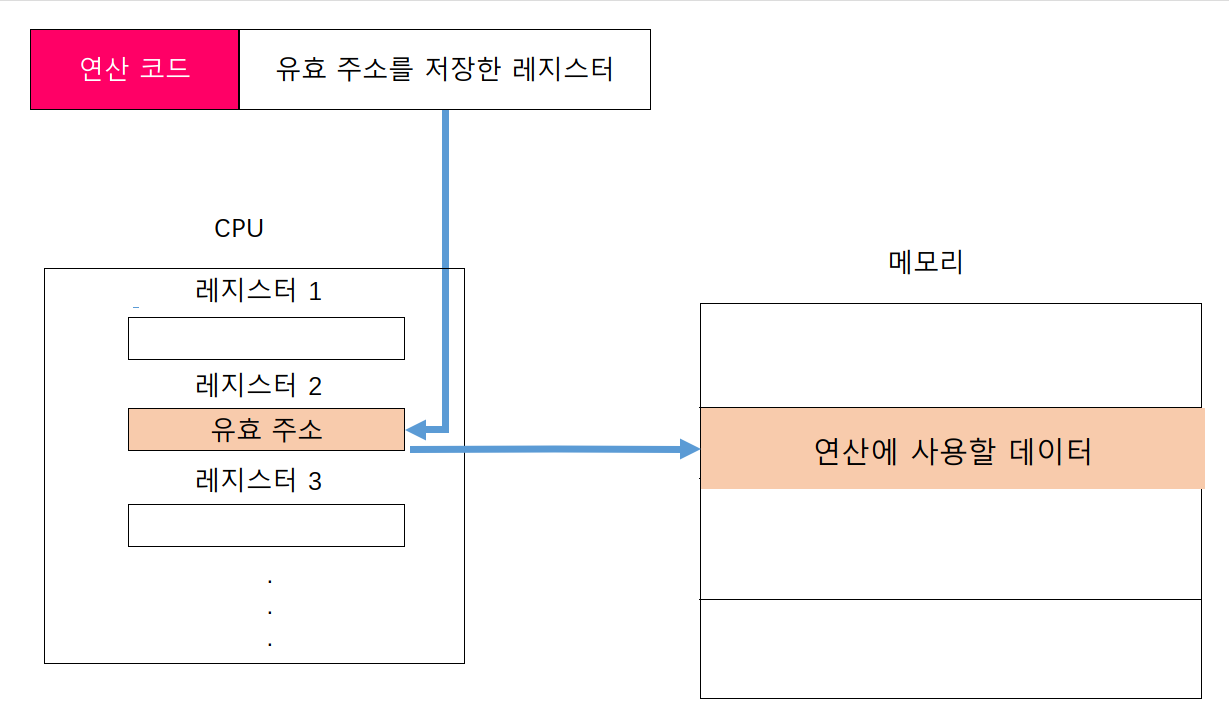
레지스터 간접 주소 지정 방식
연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법이다.
유효 주소를 찾는 과정이 간접 주소 지정 방식과 비슷하지만, 메모리에 접근하는 횟수가 한번으로 줄어든다는 차이이자 장점이 있다. 메모리에 접근하는 것이 레지스터에 접근하는 것보다 더 느리다 그래서 레지스터 간접 주소 지정 방식은 간접 주소 지정 방식보다 빠르다.
정리하자면
연산에 사용할 데이터를 찾는 방법을 주소 지정 방식이라고 한다. 연산에 사용할 데이터가 저장된 위치를 유효 주소라고 한다. 그리고 대표적인 주소 방식으로는 다섯가지가 있다.
- 즉시 주소 지정 방식 : 연산에 사용할 데이터
- 직접 주소 지정 방식 : 유효 주소(메모리 주소)
- 간접 주소 지정 방식 : 유효 주소의 주소
- 레지스터 주소 지정 방식 : 유효 주소 (레지스터 이름)
- 레지스터 간접 주소 지정 방식 : 요휴 주소를 저장한 레지스터
스택과 큐
스택이란 한쪽 끝이 막혀있는 통과 같은 저장 공간이다. 한쪽 끝이 막혀 있어서 막혀있지 않은 쪽으로 데이터를 차곡차곡 저장하고, 저장한 자료를 빼낼 때는 마지막으로 저장한 데이터부터 빼낸다. 스택은 '나중에 저장ㅇ한 데이터를 가장 먼저 빼내는 데이터 관리 방식(후입선출)'이라는 점에서 LIFO(Last In First Out) 자료 구조라고 부른다.
스택에 새로운 데이터를 저장하는 명령어가 PUSH, 스택에 저장된 데이터를 꺼내는 명령어가 POP이다. 당연히 POP명령어를 수행하면 마지막에 저장된 데이터부터 꺼내게 된다.
스택과는 달리 양쪽이 뚫려 있는 통과 같은 저장 공간을 큐(queue)라고 한다. 큐는 한쪽으로는 데이터를 저장하고, 다른 한쪽으로는 먼저 저장한 순서대로 데이터를 빼낸다. 큐는 '가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식(선입선출)'이라는 점에서 FIFO(First In First Out)자료 구조라고 부른다.
마무리
명령어는 연산 코드와 오퍼랜드로 구성된다.연산 코드는 명령어가 수행할 연산을 의미한다.오퍼랜드는 연산에 사용할 데이터 또는 연산에 사용할 데이터가 저장된 위치를 의미한다.주소 지정 방식은 연산에 사용할 데이터 위치를 찾는 방법이다.
