
💛오늘 배운것들
분산은 왜 중요할까?
ex1) 주식투자
안정적 -> 변동성(분산)이 작다
risky -> 변동성(분산)이 크다
평균은 같을 수 있다.
ex2) 영화추천
x 별점 5 / 5 / 5
y 별점 1 / 7 / 7
데이터분석에서 분산을 통해 "상대적인" 의미를 도출할 수 있다!
분산의 과정
실제값과 예측값의 차이를 제곱해준다.
스케일이 커졌기 때문에 루트를 씌워 표준편차로 만들어준다.
중심극한 정리
샘플의 평균들은 정규분포를 따른다.
Non-Parametric Methods
모집단이 특정 확률 분포 (normal과 같은)를 따른다는 전제를 하지 않는 방식. parameter estimation이 필요하지 않기 때문에 non-parametric이라고 부름
- Categorical 데이터를 위한 모델링 혹은 극단적 outlier가 있는 경우 매우매우 유효한 방식
- distribution free method라고 부르기도 함.
Chisquare
Spearman correlation
Run test
Kolmogorov Smirnov
Mann-Whitney U
Wilcoxon
Kruskal-Wallis 등
Type casting
numerical 이지만, continuous하지 않아 바로 category로 사용 할 수 있는 경우.
ex) 1, 2, 3 -> 1, 2, 3
Binning
numerical 이지만, continuous 해서 구간별로 나누어 사용 할 수 있는 경우.
ex) 1.4, 2, 3.1, 2.8, 1.1, 2.5 -> A : 1 ~ 2, B : 2 ~ 3, C : 3 ~ 4
ex) 나이대별 핸드폰 사용량
12,15살 -> 10대
22,23 -> 20대
41,49 -> 40대
T검정, 아노바, 카이제곱검정, F검정 비교 & 자료의 형태
Chi-squared test
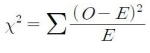
카이제곱 검정: 관찰된 빈도가 기대되는 빈도와 의미있게 다른지의 여부를 검정하기 위해 사용되는 검정방법
1) one sample Chi-squared test
- 귀무가설: 데이터의 분포는 같다.
- 대립가설: 데이터의 분포는 같지 않다.
stats.chisquare(f_obs=obs)[output]
Power_divergenceResult(statistic=1564.4572376818994, pvalue=0.0)p-value가 0.05보다 작으므로 귀무가설 기각, 데이터의 분포는 같지 않다.
2) two sample Chi-squared test
- 귀무가설: 두 집단의 분포가 연관이 없다.
- 대립가설: 두 집단의 분포가 연관이 있다.
chi2, p, dof, ex= chi2_contingency(df, correction = False)[output]
print(chi2, p)
87.31907263740848 0.0006241824968915799p-value < 0.05 작으므로 귀무가설 기각, 두 분포는 연관이 있다.
one-sample vs two-sample 의미 예시
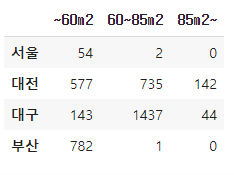
-
one-sample chi-squared test
서울 관측값과 기댓값의 차이
대전
대구 (이하 같음)
부산 -
two-sample chi-squared test
서울-~60m2 관측값과 기댓값의 차이
서울-60~85m2 관측값과 기댓값의 차이
서울-85m2~ 관측값과 기댓값의 차이
대전
대구 (이하 같음)
부산
Chi-squared 계산법

stats 사용법
-
one sample
stats.chisquare(f_obs=obs)
output = statistic, p-value -
two sample
chi2_contingency(df, correction = False)
output = statistic, p-value , degrees of freedom, expected frequencies
위키백과 - 카이제곱 검정
카이제곱 검정 예제
데이터 분석 초보자를 위한 T-test & Chi-squared test: 이해하기 쉽게 정리되어 있음
stack overflow - scipy chi to pvalue
📎 document
scipy.stats.chi2
scipy.stats.chi2_contingency
scipy.stats.chisquare
