AXI4-Lite to APB Bridge Design Project
1. Introduction
이번 글에서는 AXI4-Lite to APB Bridge IP를 직접 설계하고 검증한 개인 프로젝트를 정리한다.
AMBA 프로토콜은 수업이나 교재에서 자주 등장하지만 실제로 RTL로 구현해보지 않으면 감이 잘 오지 않는다. 특히 AXI와 APB처럼 성격이 다른 두 버스를 연결하는 브릿지는 블록 다이어그램만 봐서는 이해가 한계가 있었다.
그래서 AMBA 프로토콜을 책으로만 보는 대신 직접 설계를 하기로 결심했다. 우선 AXI, APB, AHB 등 AMBA 프로토콜엔 다양한 종류가 있는데 그 중 실무에서 자주 사용되는 AXI4-Lite Slave 인터페이스와 APB Master 인터페이스 사이를 연결하는 AXI2APB Bridge를 설계했다. 이를 통해 버스 핸드셰이크, 상태머신, 클록 도메인 분리, CDC, STA, Power 분석까지 한 번에 경험해보는 것을 목표로 했다.
이 글은 왜 이런 구조를 선택했고 어떤 설계 철학을 가지고 모듈을 나눴는지와 툴 결과와 검증 과정을 어떻게 해석했는지를 중심으로 정리한다.
2. AMBA AXI4-Lite와 APB 프로토콜 개요
2.1 AXI4-Lite 프로토콜
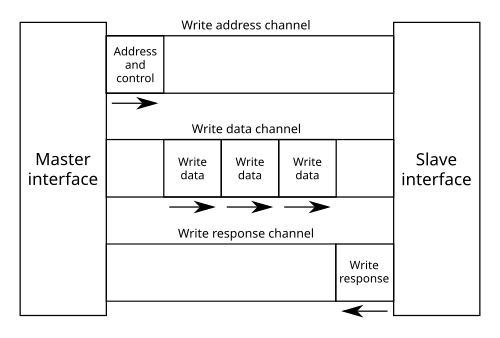
AXI4-Lite는 ARM AMBA AXI 프로토콜의 경량 버전으로 단순한 레지스터 접근을 위해 사용된다.
- 독립적인 다섯 개의 채널을 사용한다.
- AW (Write Address)
- W (Write Data)
- B (Write Response)
- AR (Read Address)
- R (Read Data/Response)
- 각 채널은 VALID/READY 핸드셰이크로 동작한다.
- Burst, ID, Out-of-order와 같은 복잡한 기능은 빠져 있고 단일 beat 위주의 단순한 구조이다.
- 주로 메모리 맵 레지스터 접근에 사용되며 SoC 내부의 고속 버스 역할을 한다.
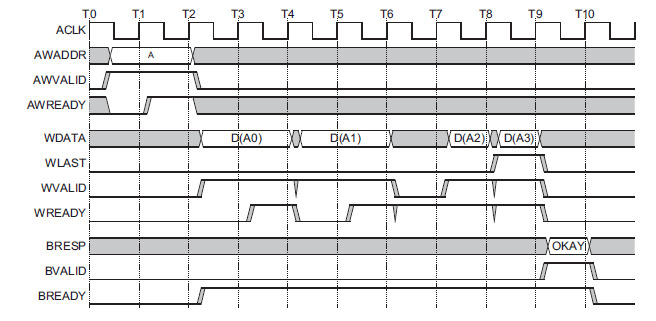
AXI4-Lite의 핵심 특징은 다음 두 가지다.
1) 채널이 완전히 분리되어 있다는 점
2) 주소(AW/AR)와 데이터(W/R)가 서로 다른 타이밍에 들어올 수 있다는 점
따라서 이를 다른 버스 규격으로 변환하려면 채널 간 정렬과 버퍼링이 필수다.
2.2 APB 프로토콜
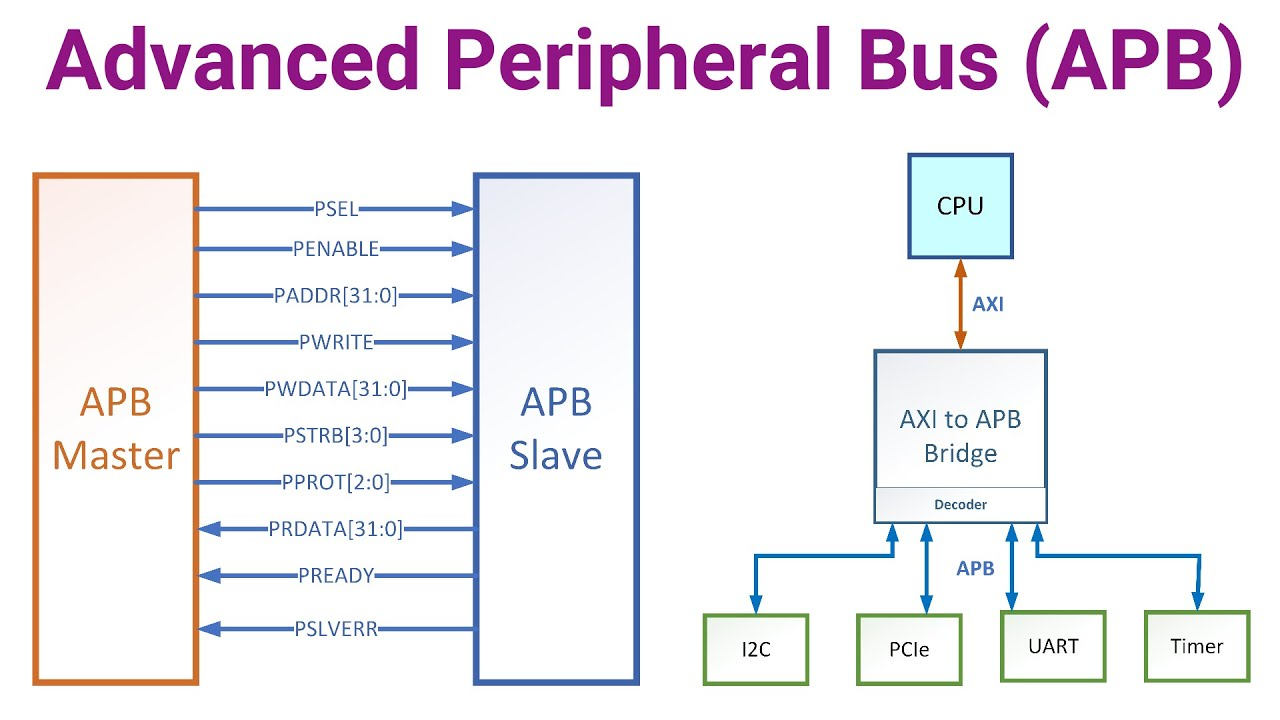
APB(Advanced Peripheral Bus)는 AMBA 계열에서 저속 주변장치를 위한 버스이다.
- 간단한 인터페이스 신호로 구성된다.
- PSEL, PENABLE, PADDR, PWRITE, PWDATA, PRDATA, PREADY, PSLVERR 등
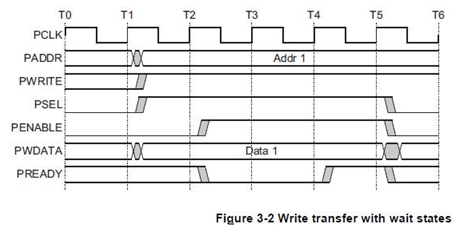
- 동작은 크게 두 단계로 나뉜다.
- SETUP 단계: PSEL=1, PENABLE=0, 주소와 제어 신호를 셋업
- ACCESS 단계: PSEL=1, PENABLE=1, PREADY가 올라올 때까지 대기
- Burst 개념 없이 단일 트랜잭션 위주로 동작하며 타이밍이 단순하고 구현이 쉽다.
- 타이머, GPIO, UART 같은 주변장치 레지스터 접근에 많이 사용된다.
2.3 AXI와 APB가 함께 쓰이는 이유
현실적인 SoC 구조를 보면 코어와 고속 주변은 AXI 기반으로 저속 주변은 APB 기반으로 연결되는 경우가 많다. 코어는 AXI 인터페이스를 갖고 있고 APB 기반 레지스터 블록들을 접근하기 위해 중간에 AXI to APB Bridge가 위치한다.
따라서 AMBA 전체 구조를 이해하려면 AXI와 APB 각 프로토콜뿐 아니라 이 둘을 연결해주는 브릿지의 동작을 이해하는 것이 중요하다. 이번 프로젝트는 바로 이 부분을 직접 구현해보기 위한 시도이다.
3. 왜 AXI2APB Bridge를 설계했는가
이번 프로젝트를 시작한 이유는 단순하다. 버스 프로토콜을 눈으로만 보면 잘 와닿지 않기 때문에 직접 설계하며 이해해보고 싶었기 때문이다.
특히 다음과 같은 지점을 몸으로 체험해보고 싶었다.
- AXI의 다섯 개 채널이 실제 RTL에서 어떻게 표현되는지
- APB의 두 단계 트랜잭션이 상태머신으로 어떻게 구현되는지
- 서로 다른 클록 도메인에서 데이터를 어떻게 안전하게 주고받는지
- 합성 이후 타이밍과 전력, 자원 사용 결과를 어떻게 해석해야 하는지
또한, 향후 SoC 설계나 인터커넥트, 버스 아키텍처 관련 직무를 준비할 때 단순히 버스 규격을 안다고 말하는 것이 아니라 실제로 브릿지 IP를 설계하고 검증해본 경험을 갖고 싶었다. AXI와 APB는 실무에서도 매우 자주 등장하는 조합이기 때문에 이 프로젝트는 개인적으로도 의미 있는 훈련이라고 생각했다.
이번 프로젝트에서 구현한 범위는 다음과 같다.
- AXI4-Lite Slave 인터페이스를 제공하는 브릿지
- APB Master 인터페이스를 통해 단일 APB 슬레이브(예: SRAM)에 접근
- aclk, pclk 두 개의 독립적인 클록 도메인
- Read/Write 트랜잭션과 SLVERR 응답 처리
- async FIFO를 이용한 클록 도메인 크로싱(CDC)
4. Architecture Overview
이 장에서는 AXI2APB Bridge의 전체 구조와 각 모듈이 어떤 역할을 하는지 정리한다.
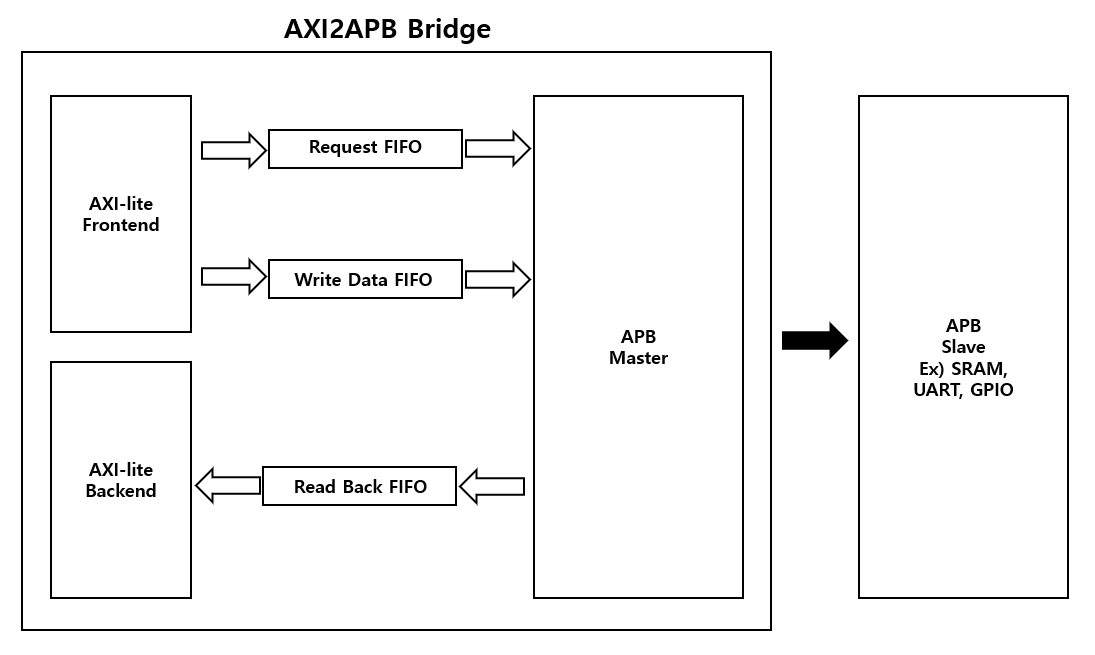
4.1 전체 블록 다이어그램
전체 구조는 크게 네 개의 주요 블록으로 나눌 수 있다.
- AXI4-Lite Frontend (ACLK 도메인)
- async FIFO 그룹 (Req, WData, Readback)
- APB Master FSM (PCLK 도메인)
- AXI4-Lite Backend (ACLK 도메인)
추가로 브릿지의 동작을 검증하기 위해 APB SRAM 슬레이브를 하나 연결한 top 모듈을 구성했다.
4.2 설계 철학
이 구조는 다음과 같은 설계 철학을 바탕으로 구성했다.
1) AXI 복잡도 단순화
AXI의 5개 채널 구조를 그대로 APB FSM에 연결하면 상태머신이 불필요하게 복잡해진다. 따라서 ACLK 도메인에서 AXI 트랜잭션을 받아 헤더(주소, read/write 플래그)와 데이터(strb, data)를 분리하고 이를 Req FIFO와 WData FIFO에 담아 PCLK 도메인으로 넘긴다. APB FSM은 이 패킷만 보고 트랜잭션을 처리하면 된다.
2) CDC는 async FIFO로만 처리
aclk와 pclk는 완전히 독립적인 클록이라고 가정했다. 두 도메인 사이의 신호 교차는 오직 async FIFO를 통해서만 이루어지도록 설계했다. 이를 통해 CDC 경로를 명확히 관리할 수 있고 STA에서 inter-clock path를 적절히 제약하기가 쉽다.
3) APB FSM 상태 최소화
APB 트랜잭션은 본질적으로 IDLE → SETUP → ACCESS 세 단계로 표현할 수 있다. 상태를 더 세분화할 수도 있지만 필요 이상의 상태 분리는 디버깅과 타이밍 이해를 어렵게 만든다. 따라서 상태는 세 개로 최소화하고 각 상태의 역할을 명확히 분리했다.
5. Module Description
이 장에서는 AXI2APB Bridge를 구성하는 각 모듈의 역할과 설계 포인트를 설명한다.
5.1 axi_lite_frontend (ACLK 도메인)
axi_lite_frontend는 AXI4-Lite Slave 인터페이스 중 AW, W, AR 채널을 처리하는 프런트엔드 모듈이다. 이 모듈의 목표는 복잡한 AXI 핸드셰이크를 단순한 Req/WData 패킷 형태로 정규화하는 것이다.

핵심 역할은 다음과 같다.
- Write Address(AW)와 Write Data(W)를 각각 버퍼에 저장
- 주소와 데이터가 서로 다른 사이클에 들어와도 안정적으로 수신
- AW 버퍼와 W 버퍼가 모두 채워지고, Req/WData FIFO에 여유가 있을 때 하나의 Write 트랜잭션으로 패킷 생성
- Read Address(AR)를 Req FIFO 패킷으로 변환
- Req FIFO에는
[is_write][addr]형식으로 헤더 정보를 저장 - WData FIFO에는
[wstrb][wdata]를 저장
write 트랜잭션의 경우 일반적으로 다음과 같은 순서로 처리된다.
1) AW 채널에서 주소 수신, 내부 버퍼에 저장
2) W 채널에서 데이터 수신, 내부 버퍼에 저장
3) 두 버퍼가 모두 유효하고 FIFO가 full이 아니면 Req FIFO, WData FIFO에 동시에 push
이러한 구조를 통해 APB FSM은 AXI 채널을 몰라도 Req/WData FIFO에서 정리된 패킷을 가져와 처리할 수 있다.
5.2 async_fifo (Req / WData / Readback 공통 구조)
클록 도메인 크로싱은 async_fifo 모듈을 이용해 처리한다. Req FIFO, WData FIFO, Readback FIFO는 모두 동일한 async_fifo 구조를 파라미터만 다르게 하여 인스턴스한다.
설계 포인트는 다음과 같다.
- Gray code 기반 read/write 포인터 사용
- 다중 비트가 동시에 변하는 경우를 피하고, CDC 시 글리치를 줄이기 위함
- full/empty 판정
- write 도메인에서는 read 포인터를 Gray code로 받아 full 판정을 수행
- read 도메인에서는 write 포인터를 Gray code로 받아 empty 판정을 수행
- DEPTH는 8로 설정
- 너무 깊게 설정하면 자원 낭비와 타이밍 경로 길어짐
- 너무 얕으면 burst-like 패턴에서 금방 full이 되어 back-pressure가 심해짐
- 실습 및 시뮬레이션 관점에서 8은 적당한 절충점이라 판단
또한, dout은 read 클록 도메인에서 레지스터에 한 번 저장한 값을 출력하도록 구성하여 combinational path를 줄이고 타이밍 마진을 확보했다.
5.3 apb_master_fsm (PCLK 도메인)
apb_master_fsm은 Req FIFO와 WData FIFO에서 트랜잭션 정보를 가져와 APB 버스를 구동하는 상태머신이다. 상태는 IDLE, SETUP, ACCESS 세 가지로 구성했다.
동작 흐름은 다음과 같다.
1) IDLE 상태
- Req FIFO가 비어 있지 않고(Read가 대기 중), Readback FIFO에 여유가 있을 때만 새로운 트랜잭션을 시작
- Write인 경우 WData FIFO도 비어 있지 않은지 확인
- 조건을 만족하면 Req/WData FIFO에서 정보를 pop하고, 내부 레지스터에 주소, write 플래그, 데이터 등을 저장한 뒤 SETUP 상태로 이동
2) SETUP 상태
- APB 신호: PSEL=1, PENABLE=0, PADDR/PWRITE/PWDATA 유효
- 한 사이클 동안 유지한 후 ACCESS 상태로 전환
3) ACCESS 상태
- APB 신호: PSEL=1, PENABLE=1
- PREADY가 1이 될 때까지 기다린다
- PREADY가 1이 되는 순간 트랜잭션 완료
- write 트랜잭션: 응답 코드(resp)만 생성
- read 트랜잭션: PRDATA를 캡처하여 응답 데이터로 사용
- is_write, resp, rdata를 묶어 Readback FIFO에 push하고, 다시 IDLE 상태로 돌아간다
응답 코드는 PSLVERR 신호를 확인하여 정상일 때 OKAY(00), 에러일 때 SLVERR(10) 형태로 매핑한다.
5.4 axi_lite_backend (ACLK 도메인)
axi_lite_backend는 Readback FIFO에서 패킷을 읽어 AXI4-Lite의 B 및 R 채널로 응답을 생성하는 역할을 한다.
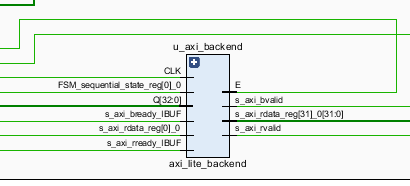
패킷 포맷은 다음과 같이 가정한다.
[is_write][resp][rdata]
동작 방식은 다음과 같다.
1) IDLE 상태에서 Readback FIFO가 비어 있지 않으면 하나를 pop
2) is_write 플래그를 확인
- is_write가 1이면 Write Response 경로로
- is_write가 0이면 Read Response 경로로
3) Write Response - B 채널의 BRESP에 resp를 세팅하고 BVALID를 올린다
- AXI Master로부터 BREADY를 받으면 트랜잭션 완료, 다시 IDLE로
4) Read Response - R 채널의 RDATA에 rdata를, RRESP에 resp를 세팅하고 RVALID와 RLAST를 1로 올린다
- AXI Master로부터 RREADY를 받으면 트랜잭션 완료, 다시 IDLE로
AXI4-Lite는 항상 단일 beat 응답이기 때문에 RLAST는 1 사이클만 1로 사용한다.
5.5 axi2apb_with_sram (Top-level 예제)
axi2apb_with_sram은 AXI2APB Bridge를 실제로 사용하기 위한 예제 top 모듈이다. 이 모듈에서는 다음 구성을 포함한다.
- AXI4-Lite Slave 인터페이스
- AXI2APB Bridge
- APB 인터페이스를 가지는 SRAM 슬레이브
SRAM 슬레이브는 비교적 단순한 APB 슬레이브 예제이기 때문에, 브릿지 동작과 데이터 일치 여부를 검증하기에 적합하다. 또한 이 구조는 실제 SoC 환경에서 브릿지 IP를 어떻게 배치할지에 대한 하나의 레퍼런스를 제공한다.
6. Implementation Results (Timing / Power / Utilization)
이 장에서는 합성 및 구현 결과를 분석하고, 어떻게 개선할 수 있는지 간단히 정리한다. 실제 수치는 Vivado 리포트를 기준으로 하였다.
6.1 타이밍 분석
- 합성 및 구현 툴: Vivado
- aclk 도메인 목표 주파수: 200 MHz
- pclk 도메인 목표 주파수: 150 MHz
결과 캡처:
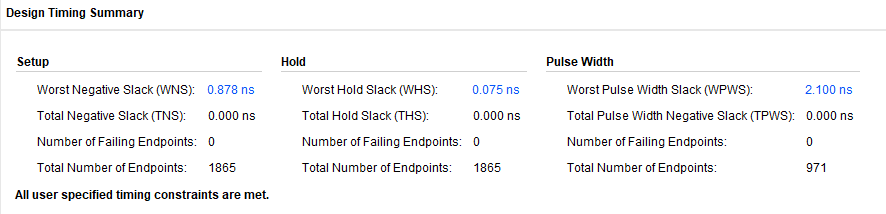
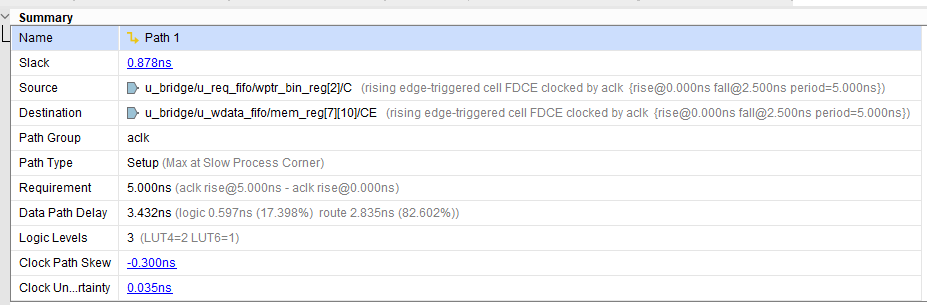
- aclk 도메인 최소 slack: 약 0.878 ns
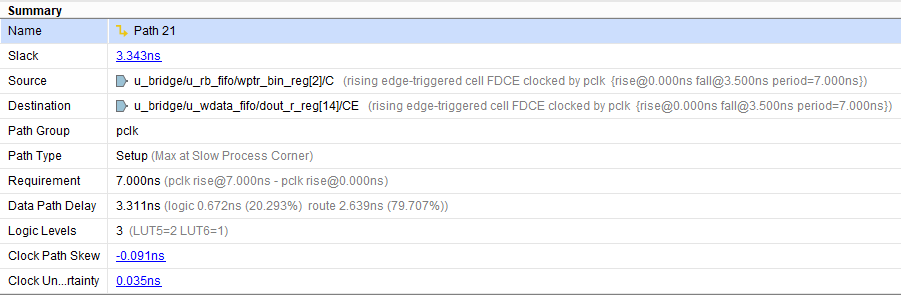
- pclk 도메인 최소 slack: 약 3.343 ns
inter-clock path 제약:
- async_fifo 내부의 메타플롭을 제외한 모든 aclk ↔ pclk 경로는 false path로 제약
- CDC 경로를 FIFO 경계로 한정하여 STA 해석이 단순해짐
6.2 자원 사용(Utilization)
자원 사용은 사용한 디바이스에 따라 다르지만 구조적으로는 다음과 같이 구성된다.
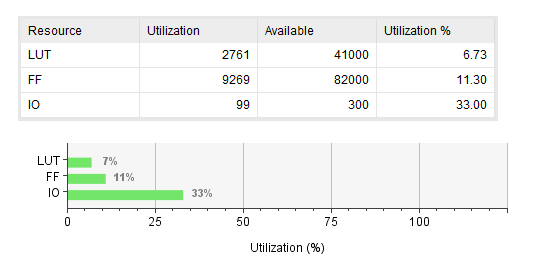
BRAM을 사용하지 않았을 때
BRAM을 사용했을 때
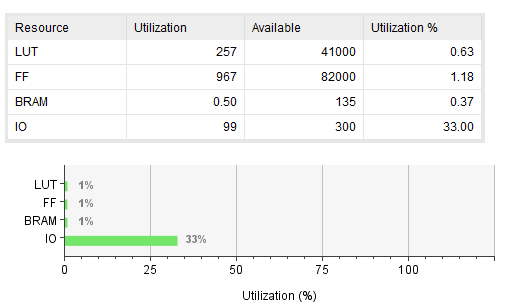
- LUT: AXI 핸드셰이크 로직, FSM, FIFO 컨트롤
- FF: 버퍼 레지스터, 상태 레지스터, FIFO 포인터
- BRAM 또는 LUTRAM: Req/WData/Readback FIFO 저장소
표로 정리하면 다음과 같다.
| 구성 방식 | LUT | FF | BRAM | ACLK Slack | PCLK Slack |
|---|---|---|---|---|---|
| 순수 로직 RAM (LUT/FF 기반) | 2761 | 9269 | 0 | 1.21 ns | 1.0 ns |
| BRAM 기반 RAM | 257 | 967 | 0.5 | 0.80 ns | 3.3 ns |
요약하면 다음과 같다.
-
순수 로직 RAM
- 장점: 타이밍(특히 ACLK) 여유가 상대적으로 크고 작은 규모에서는 구조가 직관적이다.
- 단점: LUT/FF 자원 소모가 지나치게 크고 전력 비효율적이다. PCLK 도메인 타이밍도 BRAM 대비 여유가 적다.
-
BRAM 기반 RAM
- 장점: LUT/FF를 대폭 절감하면서 PCLK 도메인 slack이 크게 향상된다. 구조적 일관성과 확장성이 좋고 실무적인 선택이다.
- 단점: BRAM 위치 제약으로 인해 ACLK 크리티컬 경로가 다소 길어질 수 있다. 필요 시 파이프라인이나 floorplan으로 개선 가능하다.
6.3 Power 분석
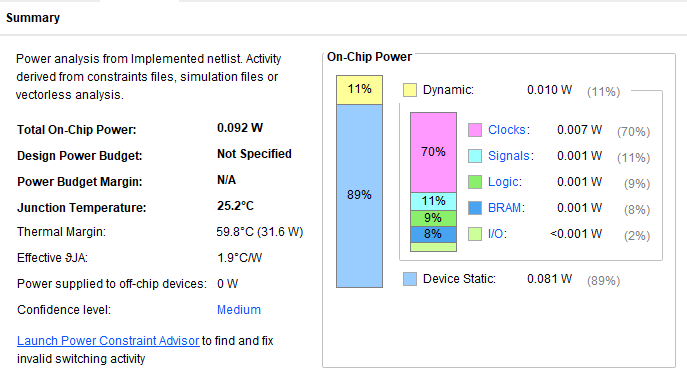
Power 분석은 Vivado Power Analyzer를 사용하였고 시뮬레이션에서 SAIF를 생성하여 구현 이후의 실제 스위칭 활동을 반영했다.
- 전체 온칩 소비 전력: 약 0.092 W
- Device Static: 약 89%
- Dynamic Power: 약 11%
AXI2APB 구조 특성상 연산 블록이 크지 않고, 대부분 Control + 인터페이스 로직으로 구성되어 있기 때문에 동적 전력 자체는 작고 정적 전력이 비중을 크게 차지한다.
Dynamic Power 상세 구조:
-
Clock Power (약 0.007 W, 70%)
- ACLK/PCLK 두 개의 클럭 도메인에 걸친 플롭들을 계속 토글해야 하기 때문에 Clock Tree가 동적 전력 대부분을 먹는다.
-
Logic Power (약 0.001 W, 9%)
- Frontend/Backend, APB FSM 등 Control 중심 경로라 토글 빈도가 낮다.
-
Signal Power (약 0.001 W, 11%)
- FIFO 입출력, Ready/Valid 및 상태 전이 등으로 인한 신호 토글이 일부 존재한다.
-
BRAM Power (약 0.001 W, 8%)
- BRAM 기반 메모리 사용량이 적어 기여도는 크지 않다.
-
I/O Power (<0.001 W, 약 2%)
- 대부분 내부 연결이고 외부 핀 출력이 많지 않아 I/O 전력은 사실상 무시 가능하다.
정리하면, 전체 전력은 매우 작은 수준이며 두 클록 도메인을 유지하기 위한 Clock 전력 비중이 상대적으로 높은 IP 구조라고 볼 수 있다. 인터페이스 IP로서 전력 오버헤드는 거의 없는 편이다.
7. Verification – Testbench 설계 및 검증 결과
이번 프로젝트에서는 단순히 RTL만 작성하는 것이 아니라 모듈 단위 검증부터 top-level 검증까지 단계적으로 진행했다. 이 장에서는 모듈별 Testbench 템플릿을 통일된 형식으로 정리한다.
- 7.1 검증 전략
- 7.2 모듈별 단위 검증 결과
- 7.3 전체 브릿지 Testbench 결과
- 7.4 검증 결과 요약 및 향후 확장
7.1 검증 전략
검증 전략은 다음과 같은 순서를 따른다.
1) 유닛 테스트(Unit Test)
- async_fifo
- axi_lite_frontend
- apb_master_fsm
- axi_lite_backend
2) 시스템 테스트(System Test)
- axi2apb_bridge 전체 경로에 대한 검증
- axi2apb_with_sram을 이용한 end-to-end 검증
각 단계에서 Directed 테스트와 Random 요소를 적절히 섞어 다음 항목을 최대한 커버하도록 했다.
- 정상 Read/Write 시나리오
- FIFO full/empty, backpressure
- PREADY wait-cycle, SLVERR 응답
- Reset, 비동기 클록 관계(aclk ≠ pclk)
7.2 모듈별 Testbench
이 절에서는 각 모듈에 대해 동일한 템플릿으로 검증 결과를 정리한다.
- Test 목표
- Testbench 구성
- 주요 파형 분석
- Corner / CDC 포인트
- 검증 결과 요약
7.2.1 Async FIFO Testbench 검증 결과
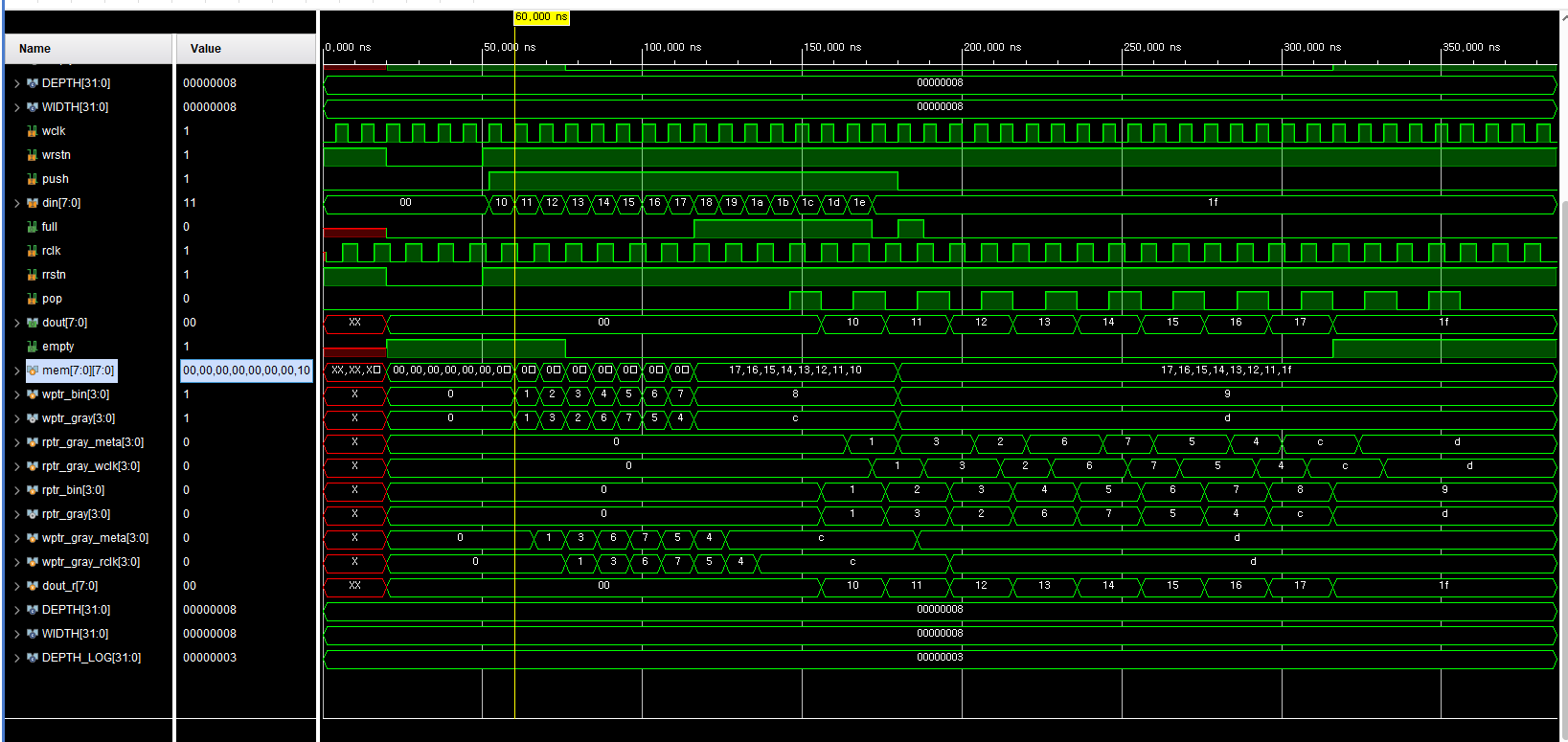
1) Test 목표
- 비동기 클록(wclk ≠ rclk) 환경에서
- push / pop / full / empty / dout 동작이 안정적으로 동작하는지
- Gray code 포인터와 2단 동기화 구조가 의도한 대로 동작하는지
- full/empty 경계에서 데이터 손실 또는 중복이 없는지 확인
2) Testbench 구성
-
클럭 및 리셋
- wclk: 8 ns (125 MHz)
- rclk: 10 ns (100 MHz)
- wrstn, rrstn: 초기 20 ns 동안 0, 이후 1로 상승
-
Stimulus 시나리오
- 리셋 해제 직후 write 전용 구간
- DEPTH=8 기준으로 2×DEPTH = 16개의 데이터를 연속 push
- din: 0x10 ~ 0x1F
- full 상태에서도 push가 들어가도록 만들어 full 보호 로직 확인
- 이후 read 구간
- pop 펄스를 1클럭 on / 1클럭 off 패턴으로 DEPTH+3번 발생
- empty 상태에서 pop이 들어와도 포인터가 움직이지 않는지 확인
- 리셋 해제 직후 write 전용 구간
-
Self-check 포인트
- dout가 0x10 ~ 0x17 순서로 정확히 출력되는지
- full=1 구간에서 mem[]이 더 이상 변경되지 않는지
- empty=1 이후 pop이 무시되는지
3) 주요 파형 분석
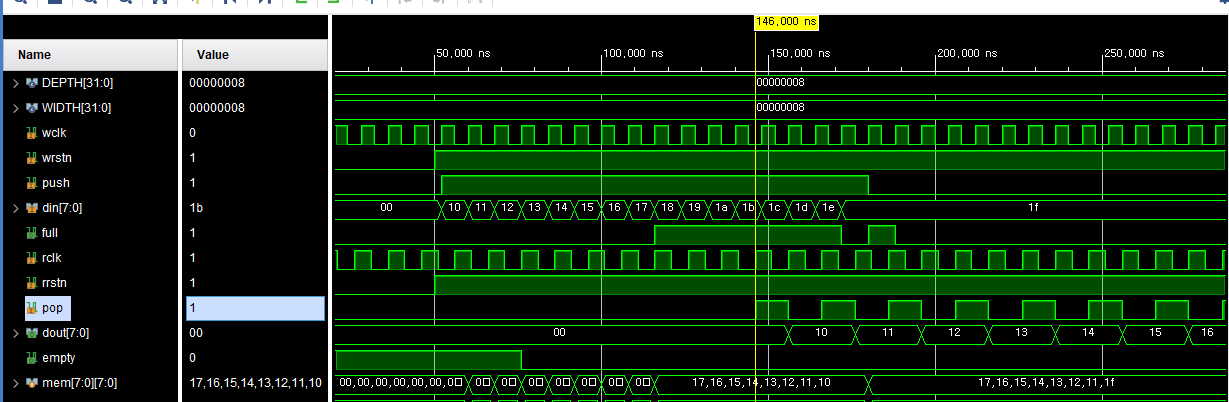
-
0 ~ 50 ns
- wrstn, rrstn이 0 → 1로 전환
- wptr_bin, rptr_bin, wptr_gray, rptr_gray, mem[] 모두 0으로 초기화
- empty=1, full=0
-
write-only 구간
- push=1, pop=0
- din=0x10 ~ 0x17이 mem[0] ~ mem[7]에 순서대로 기록
- wptr_bin: 0 → 8까지 증가
- Gray code 포인터가 0→1→3→2→6→7→5→4→c로 정상 전이
-
full 구간
- wptr_bin=8 시점에 full=1로 assert
- 이후 push가 계속 들어와도 push && !full 조건 때문에 mem[]은 더 이상 변경되지 않음
-
read 구간
- pop=1일 때마다 rptr_bin이 증가
- dout는 0x10, 0x11, …, 0x17 순으로 출력
- empty=1이 되는 순간 더 이상 rptr_bin과 dout가 변화하지 않음
4) Corner / CDC 포인트 – "0x1E vs 0x1F" 이슈 분석
테스트 중 다음과 같은 현상을 일부러 만들었다.
- pop이 발생하며 FIFO에 한 칸 여유가 생기는 순간
- wclk 도메인에서는 이 변화를 2단 동기화된 rptr_gray_wclk를 통해 늦게 인지
- 따라서 pop 직후 한두 클럭 동안은 write 쪽에서는 여전히 full=1로 보일 수 있다.
이 구간에서 push(0x1E)가 들어오면,
CDC 지연 때문에 full이 아직 1이므로 해당 push는 차단되고,
동기화가 끝난 다음 들어오는 0x1F만 FIFO에 들어가는 현상이 발생한다.
이는 설계 버그가 아니라, Gray code + 2단 동기화 구조에서 필연적으로 발생하는 정상적인 동작이다. 대가로 메타스테이블리티 위험을 줄이고 안전한 CDC를 보장한다.
5) 발생했던 문제와 해결 과정
Async FIFO는 ACLK와 PCLK처럼 서로 다른 클럭 도메인 사이에서 데이터를 교환하는 핵심 모듈이다.
검증 과정에서 CDC 타이밍, full/empty 업데이트 지연, pop/write 타이밍 문제 등 여러 특성이 발견되었고
이를 분석하며 정상 동작 여부를 확인하였다.
- 테스트 중 발생했던 문제 요약
| 번호 | 문제 내용 | 원인 | 해결 방법 |
|---|---|---|---|
| 1 | pop 이후 push가 바로 FIFO에 기록되지 않는 현상 (예: 0x1E가 건너뛰어짐) | read pointer가 rclk에서 즉시 변해도, write domain에서는 2단 동기화된 rptr_gray_wclk를 사용하여 full을 판단하므로, full=1이 두 wclk 동안 유지됨 | full이 CDC 특성상 두 클럭 지연 후 정상적으로 해제됨을 확인. 이는 비동기 FIFO 정상 동작이며 push 조건이 push && !full임을 기준으로 정상으로 판단 |
| 2 | pop을 해도 mem[] 값이 00으로 지워지지 않는 현상 | async FIFO는 shift 구조가 아닌 pointer 기반 구조. pop은 데이터를 삭제하지 않고 rptr_bin만 증가 | pointer-based FIFO 구조가 산업 표준이며 mem 지우지 않음이 정상 동작임을 검증 |
| 3 | full 상태에서 push가 지속되었을 때 write pointer(wptr_bin)가 증가하지 않는 현상 | push && !full 조건 때문에 push가 무시됨 | backpressure 정상 동작. full 상태에서 write 차단이 의도된 구조임을 파형으로 확인 |
| 4 | empty 상태에서 pop을 반복해도 rptr_bin이 증가하지 않는 현상 | pop && !empty 조건 때문에 empty 구간에서는 pop이 무시됨 | empty 보호 로직이 정상 동작함을 확인 |
| 5 | full/empty 신호가 즉시 변하지 않고 한두 클럭 지연됨 | 클럭 도메인 간 2단 동기화로 인해 포인터 전달이 늦게 반영됨 | CDC 특성으로 인한 정상 동작임을 파형으로 확인. empty/full 지연은 설계 의도와 일치 |
-
핵심 해결 포인트
A. CDC 동기화 구조에 대한 이해
- read 포인터는 rclk에서 즉시 증가하지만, write 도메인은 rptr_gray_wclk(2단 동기화된 값)를 기준으로 full을 판단한다.
- 따라서 pop이 일어나도 write가 이를 알기까지 두 번의 wclk 지연이 존재한다.
- 이 때문에 pop 직후 push된 데이터(예: 0x1E)는 full=1인 구간에 포함되어 무시되며,
full이 해제된 뒤 최초 push 값(예: 0x1F)부터 FIFO에 기록된다.
B. pointer-based FIFO 동작 재확인
- mem[]은 pop 이후에도 데이터를 삭제하지 않으며 pointer만 이동한다.
- 유효 데이터 여부는 mem 값이 아니라 포인터 비교(rptr_bin vs wptr_bin) 기반으로 판단한다.
C. full/empty 지연 현상 분석
- 두 클럭 도메인 사이의 2FF 동기화로 인해 empty/full 신호는 한두 사이클 늦게 변한다.
- 이는 비동기 FIFO의 본질적인 특성이며 파형에서도 정확히 드러난다.
D. pop/write 타이밍 검증
- pop은 rclk posedge에서만 rptr_bin을 증가시키며, dout는 레지스터(dout_r)에 저장되어 한 클럭 지연되며 출력된다.
- write 역시 wclk posedge에서 push && !full 조건을 충족할 때만 수행된다.
- 두 도메인의 타이밍이 의도된 구조대로 작동함을 파형으로 검증하였다.
-
요약
- pop 직후 write가 허용되지 않은 이유는 CDC 동기화 지연 때문이며, 이는 정상 동작이다.
- mem 값이 pop 후에도 변하지 않는 것은 pointer-based FIFO 구조의 표준 동작이다.
- full/empty 신호가 지연되어 업데이트되는 현상은 Gray 코드 + 두 클럭 동기화 구조의 자연스러운 결과다.
- empty/full 보호 로직이 의도대로 동작하며, push/pop 타이밍 또한 명확하게 검증되었다.
- 전체 검증을 통해 async FIFO가 비동기 환경에서도 안전하게 동작함을 확인하였다.
6) 검증 결과 요약
- reset 후 포인터 및 메모리 초기화 정상
- DEPTH 이상 push 시 full이 정확히 assert되고, 추가 write 차단
- 입력 순서대로 데이터가 정확히 출력되고, empty 이후 pop이 무시됨
- full/empty 판정이 Gray code 포인터 비교를 기준으로 안정적으로 동작
- pop 이후 push 구간에서의 "지연된 full 해제" 시나리오를 분석하여 CDC 구조가 의도대로 작동함을 확인함
→ async_fifo 모듈은 비동기 클록 환경에서 안전하게 동작하는 것을 검증했다.
7.2.2 AXI4-Lite Frontend Testbench 검증 결과
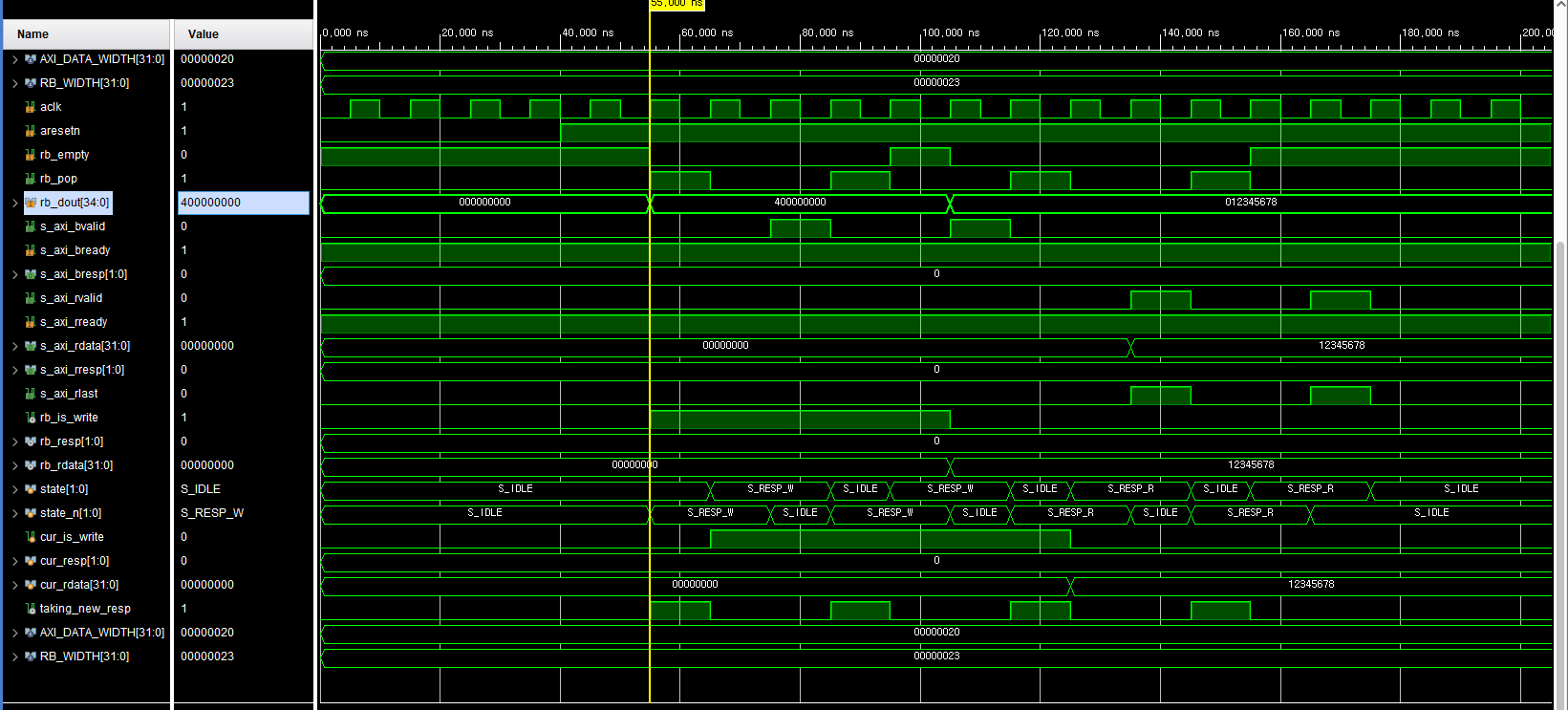
1) Test 목표
- AXI4-Lite AW/W/AR 채널을 받아 내부 AW/W 버퍼로 저장한 뒤
Req/WData FIFO에 패킷 형태로 변환하는 기능 검증 - Write 트랜잭션 페어링(AW/W) 로직과 Read 트랜잭션(AR) 처리 로직 검증
- Write > Read 우선순위, READY 제어, FIFO full 상태에서의 backpressure 동작 검증
2) Testbench 구성
-
클럭 및 리셋
- aclk: 10 ns (100 MHz)
- aresetn: 일정 시간 후 0 → 1 전환
-
Stimulus 시나리오
- Write 1건
- AWVALID, AWADDR 입력
- WVALID, WDATA, WSTRB 입력 (AW와 시점 차이를 일부러 줘서 out-of-order 수신 상황 포함)
- Read 1건
- ARVALID, ARADDR 입력
- AW/W 반복 상황, AR 동시 입력
- Write 버퍼가 채워진 상태에서 ARVALID를 같이 주어 우선순위 확인
- Req/WData FIFO를 full 근처까지 채워 READY가 내려가는지 확인
- Write 1건
-
Self-check 포인트
- 첫 write에서 Req FIFO에는 [is_write=1, addr]가, WData FIFO에는 [WSTRB, WDATA]가 동시에 들어가는지
- read에서는 Req FIFO에 [is_write=0, addr]만 들어가는지
- aw_buf / w_buf valid 비트가 push 이후 정상적으로 clear되는지
- READY 신호가 internal 상태에 따라 적절히 0/1 토글되는지
3) 주요 파형 분석
-
초기 상태
- aw_buf_valid=0, w_buf_valid=0
- req_full=0, wdata_full=0
- s_axi_awready=1, s_axi_wready=1, s_axi_arready=1
→ 세 채널 모두 수신 가능한 IDLE 상태
-
Write Address 수신
- s_axi_awvalid=1, s_axi_awready=1 조건 만족
- aw_buf_valid=1, aw_buf_addr에 주소 래치
-
Write Data 수신
- s_axi_wvalid=1, s_axi_wready=1
- w_buf_valid=1, w_buf_data / w_buf_strb 래치
-
Write 트랜잭션 push
- aw_buf_valid, w_buf_valid, fifo_ready가 모두 1일 때 can_push_write=1
- 같은 사이클에
- req_push=1, req_din = {is_write=1, aw_buf_addr}
- wdata_push=1, wdata_din = {w_buf_strb, w_buf_data}
- 이후 aw_buf_valid, w_buf_valid가 0으로 clear
-
Read 트랜잭션 push
- s_axi_arvalid=1, s_axi_arready=1일 때 ar_fire=1
- write push가 없는 사이클이면 req_push=1, req_din = {is_write=0, araddr}
- wdata_push는 0 유지
4) Corner / 우선순위 및 READY 동작
-
Write > Read 우선순위
- aw_buf_valid=1, w_buf_valid=1인 상황에서 ARVALID가 동시에 들어와도
can_push_write 조건이 먼저 만족되기 때문에 해당 사이클에는 write만 Req/WData FIFO에 push된다. - 다음 사이클 이후에 read가 순차적으로 처리되는 것이 파형에서 확인된다.
- aw_buf_valid=1, w_buf_valid=1인 상황에서 ARVALID가 동시에 들어와도
-
READY 생성 규칙
- s_axi_awready / s_axi_wready
- wr_slot_available & ~aw_buf_valid / ~w_buf_valid 조합으로 생성
- 내부 버퍼가 차 있거나 FIFO가 full인 경우 READY가 0으로 내려가 backpressure를 건다.
- s_axi_arready
- ~req_full 조건으로 생성
- Req FIFO가 full인 경우 read 요청을 받지 않는다.
- s_axi_awready / s_axi_wready
5) 발생했던 문제와 해결 과정
AXI4-Lite Backend 모듈을 단위 테스트하는 과정에서, Vivado Simulator(XSim)의 SystemVerilog 기능 제약과
Readback FIFO empty 처리 방식이 맞지 않아 여러 가지 이슈가 발생하였다.
본 절에서는 테스트 중 실제로 마주친 문제와 그 해결 과정을 정리한다.
- 테스트 중 발생했던 문제 요약
| 번호 | 문제 내용 | 원인 | 해결 방법 |
|---|---|---|---|
| 1 | $urandom() 호출 시 Elaborate 에러 발생 | Vivado XSim은 $urandom 미지원 | $random 기반 pseudo-random 함수로 교체 |
| 2 | function 인자 관련 warning 출력 | XSim은 SV에서 input 생략을 허용하지 않음 | 모든 function 파라미터에 input 명시 |
| 3 | struct 지역 변수 사용 시 warning | always 블록 내 지역 변수 lifetime 규칙과 충돌 | automatic rb_item_t exp; 형태로 선언 |
| 4 | Backend가 RESP 값을 잘못 래치 (예: exp=2, got=0) | TB에서 rb_pop 직후 즉시 rb_empty=1로 올려 latch 사이클이 손실됨 | pop 발생 후 1클럭 유지 후 empty=1로 지연 |
| 5 | ready=0 구간에서 valid/ready 타이밍이 불명확 | backpressure 상황에서 FSM 오해석 가능성 | ready 패턴 삽입 및 assertion 기반 검증 추가 |
-
핵심 해결 포인트 정리
A. 시뮬레이터(Vivado XSim) 호환성 조정
Vivado XSim은 SystemVerilog 지원 범위가 제한적이므로 다음 조치가 필요했다.$urandom미지원 →$random기반 난수 발생 함수로 치환- function 인자에는 반드시
input키워드 명시 - always 블록 내 구조체는
automatic으로 선언하여 lifetime 충돌 방지
이 수정 후 TB Compile/Elaborate warning이 모두 제거됨.
B. 가장 치명적 이슈: Readback FIFO empty 신호 타이밍 문제
초기 TB에서는 다음과 같은 패턴을 사용하였다.wait (rb_pop); rb_empty = 1;이 방식은 rb_pop 직후 즉시 empty=1이 되어 Backend가 cur_resp, cur_rdata를 래치할 타이밍을 잃어버리는 문제를 발생시켰다.
결과적으로 Backend는 첫 응답만 정상 처리하고, 두 번째 응답부터 잘못된 resp 값을 가져오게 되었다.- 해결 방법 (정석 방식)
wait (rb_pop == 1); @(posedge aclk); // 이 사이클에서 cur_* 래치가 발생 rb_empty = 1;이 한 줄 수정으로 Backend FSM은 모든 응답을 정확하게 래치하기 시작하였다.
C. AXI valid/ready 타이밍 해석 보정
테스트벤치는 초기에는 valid drop이 즉시 발생해야 한다고 가정하고 있었다.
그러나 AXI 규칙상 valid→0 전환은 “다음 클럭 엣지”에서만 일어난다.이를 고려해 TB 체크 타이밍을 1클럭 뒤로 조정하여 모든 handshake가 정상적으로 분석되었다.
- 요약
- Vivado XSim의 SV 기능 제약을 반영해
$urandom, function 인자, automatic 변수 문제 해결 - Readback FIFO empty 타이밍을 1클럭 지연하는 방식으로 Backend 래치 오류 해결
- AXI B/R valid-ready handshake 구간을 정확히 재해석하여 검사 로직 보정
- ready=0(backpressure) 구간에서도 FSM이 정상적으로 동작함을 assertion으로 검증
- 수정 이후 Backend FSM은 모든 테스트 시나리오에서 정상 동작함을 완전히 확인하였다.
- Vivado XSim의 SV 기능 제약을 반영해
6) 검증 결과 요약
- AW/W 독립 수신 및 버퍼링, 페어링 후 atomic push 구조가 파형에서 명확히 확인되었다.
- Read 트랜잭션은 WData 없이 Req FIFO만 사용하는 형태로 정상 동작한다.
- Write 트랜잭션이 존재할 때 Read보다 우선 처리되는 우선순위 정책이 정확하게 구현되었다.
- READY 신호가 FIFO 상태와 내부 버퍼 상태에 따라 적절히 제어되며 AXI4-Lite 프로토콜을 만족한다.
→ Frontend는 AXI4-Lite의 Read/Write 요청을 ACLK 도메인 FIFO로 정확히 변환하는 인터페이스로 동작함을 검증했다.
7.2.3 AXI4-Lite Backend Testbench 검증 결과
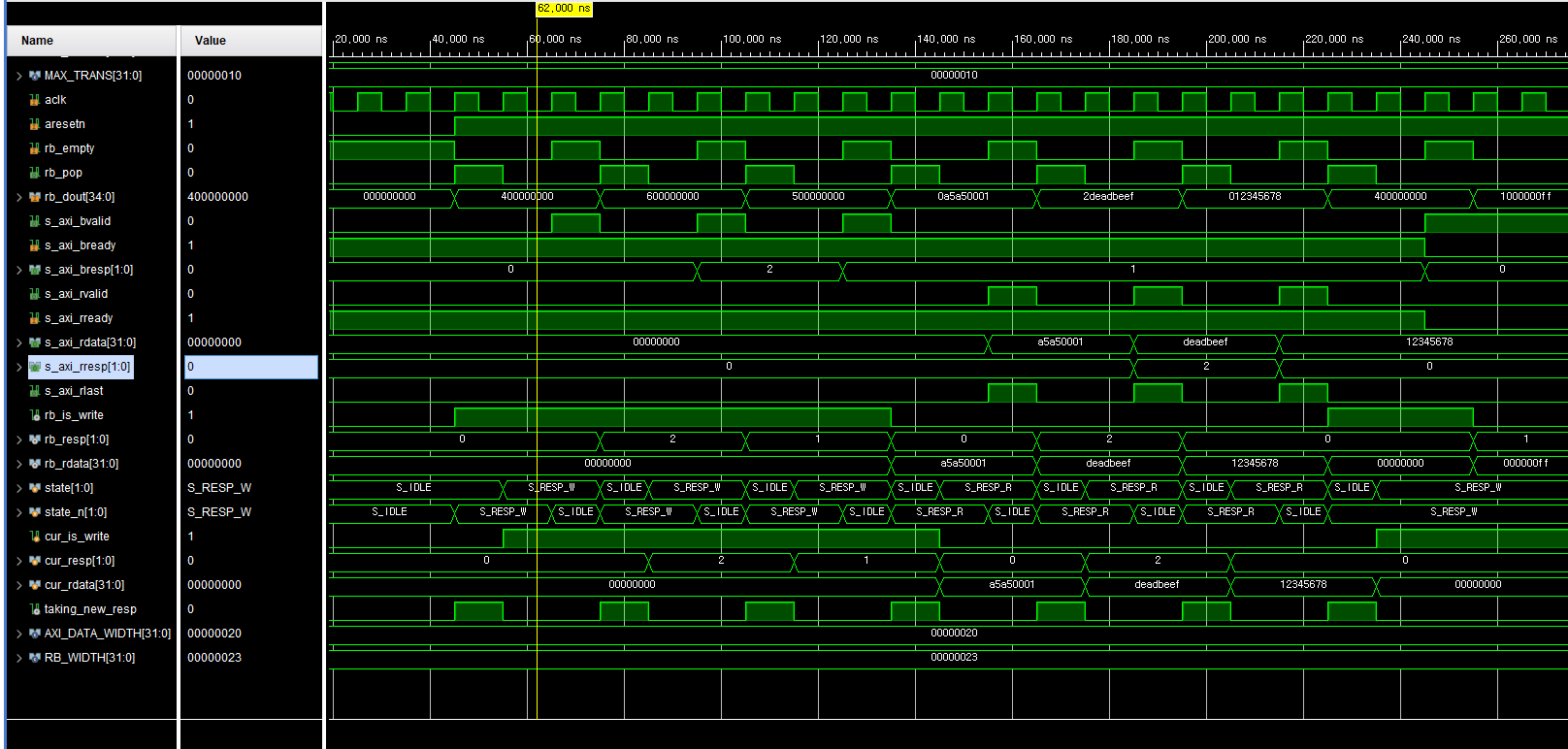
1) Test 목표
- Readback FIFO에서 응답 패킷
{is_write, resp, rdata}를 읽어
AXI4-Lite B/R 채널로 올바른 시퀀스로 전달하는지 검증 - Write/Read 응답 분기, BRESP/RRESP/RDATA/RLAST 생성, VALID/READY 핸드셰이크 동작 확인
- 여러 응답이 연속 들어왔을 때 순서 보장 여부 검증
2) Testbench 구성
-
클럭 및 리셋
- aclk: 10 ns (100 MHz)
- aresetn: 초기 구간에서 0 → 1 전환
-
Stimulus 시나리오
- Readback FIFO 모델에 다음 10개 응답을 순차적으로 주입
- Write OKAY, Write SLVERR, Write custom resp
- Read OKAY with data, Read SLVERR with data
- 기타 조합 몇 가지
- 각 응답은
{is_write, resp, rdata}형태- Write: rdata는 0으로 둠
- Read: data 패턴(A5A5..., DEADBEEF 등)을 미리 scoreboard에서 기대값으로 등록
- Readback FIFO 모델에 다음 10개 응답을 순차적으로 주입
-
Self-check 방식
- 응답 하나가 처리될 때마다 콘솔에 결과 로그 출력
- B 채널: resp만 비교
- R 채널: resp, data 모두 비교
- mismatch 발생 시 즉시 에러 출력
3) 주요 파형 및 로그 분석
-
Write 응답 예
- rb_dout = {1, 2'b00, 32'h0000_0000}
- Backend가 이를 pop하여
- s_axi_bvalid=1, s_axi_bresp=0 출력
- s_axi_bready=1과 handshake 후 S_IDLE 복귀
-
Read 응답 예
- rb_dout = {0, 2'b10, 32'hDEAD_BEEF}
- Backend는
- s_axi_rvalid=1
- s_axi_rresp=2'b10
- s_axi_rdata=32'hDEAD_BEEF
- s_axi_rlast=1
- s_axi_rready=1과 handshake 후 S_IDLE 복귀
-
실제 로그 예시
- [75000] B: resp OK. idx=0 resp=0
- [105000] B: resp OK. idx=1 resp=2
- [165000] R: resp/data OK. idx=0 resp=0 data=A5A50001
- …
- [2395000] TEST PASSED
4) Corner 포인트
- Backend는 S_IDLE 상태에서 rb_empty=0일 때만 새로운 응답을 하나씩 처리한다.
- takingnew_resp 신호를 통해 IDLE → RESP*로 넘어갈 때 rb_pop=1을 1사이클 생성하고, 이때 패킷 전체를 내부 레지스터에 래치한다.
- 따라서 Readback FIFO 측에서는 한 응답이 두 번 pop되는 일이 없고,
AXI 측에서는 한 응답이 두 번 전송되는 일이 없다.
5) 발생했던 문제와 해결 과정
AXI4-Lite Backend 모듈을 단위 테스트하는 과정에서, Vivado Simulator(XSim)의 제약과 FIFO 타이밍 처리 문제 등 몇 가지 이슈가 발생하였다. 아래 표는 검증 과정에서 실제로 마주친 문제와 그 해결 방법을 정리한 것이다.
- 테스트 중 발생했던 문제 요약
| 번호 | 문제 내용 | 원인 | 해결 방법 |
|---|---|---|---|
| 1 | $urandom() 호출 시 Elaborate 에러 | Vivado XSim은 $urandom 미지원 | $random 기반 pseudo-random 함수로 치환 |
| 2 | function 인자 warning 발생 | XSim은 인자 방향 생략(input) 불허 | 모든 function 파라미터에 input 명시 |
| 3 | struct 지역 변수 warning | always 블록 내부 변수는 lifetime 지정 필요 | automatic rb_item_t exp; 형태로 수정 |
| 4 | Backend가 RESP 값을 잘못 가져오는 문제 (예: exp=2, got=0) | TB가 rb_pop 직후 즉시 rb_empty=1로 올려 latch 사이클이 깨짐 | pop 직후 1클럭 유지 후 rb_empty=1로 딜레이 |
| 5 | ready=0 구간에서 valid/ready 타이밍 불명확 | backpressure 구간에서 FSM 오동작 가능성 | assertions 및 ready 패턴 삽입하여 정확성 검증 |
-
핵심 해결 포인트
A. 시뮬레이터 호환성 정리
Vivado XSim의 SystemVerilog 기능 제한으로 인해 아래 조정이 필요했다.- $urandom → $random 대체
- 모든 function argument에 input 명시
- automatic 변수 선언
B. 가장 치명적 문제: FIFO empty 타이밍 이슈
초기 테스트에서는 Backend가 두 번째 응답 이후부터 cur_resp를 갱신하지 못하는 문제 발생.
원인: 테스트벤치에서 rb_pop 직후 rb_empty를 바로 1로 올림 → latch 타이밍이 깨짐.해결 방법:
while (!rb_pop) @(posedge aclk);
@(posedge aclk); // 이 클럭에서 latch 수행
rb_empty = 1;- 요약
- Vivado XSim의 SV 지원 범위 보완
- FIFO empty/popup 타이밍 수정
- AXI B/R valid-ready handshake 검증
- backpressure 상황에서 FSM 정상동작 확인
- Scoreboard 기반 자동 매칭
문제 해결 이후 Backend FSM은 모든 테스트 시나리오에서 정상적으로 동작함이 입증되었다.
6) 검증 결과 요약
- Write/Read 응답 변환 로직이 설계 의도대로 동작하며,
응답 순서가 뒤바뀌거나 누락되는 현상 없이 모든 테스트 케이스가 PASS 되었다. - 단일 beat 규격인 AXI4-Lite에 맞게 RLAST=1 한 사이클 구조가 정확히 구현되었다.
- Scoreboard 기반 self-check에서 mismatch 없이 최종 TEST PASSED 로그를 확인했다.
→ Backend는 Readback FIFO 패킷을 AXI B/R 채널로 안정적으로 전달하는 응답 인터페이스로서 요구사항을 만족한다.
7.2.4 APB Master FSM Testbench 검증 결과
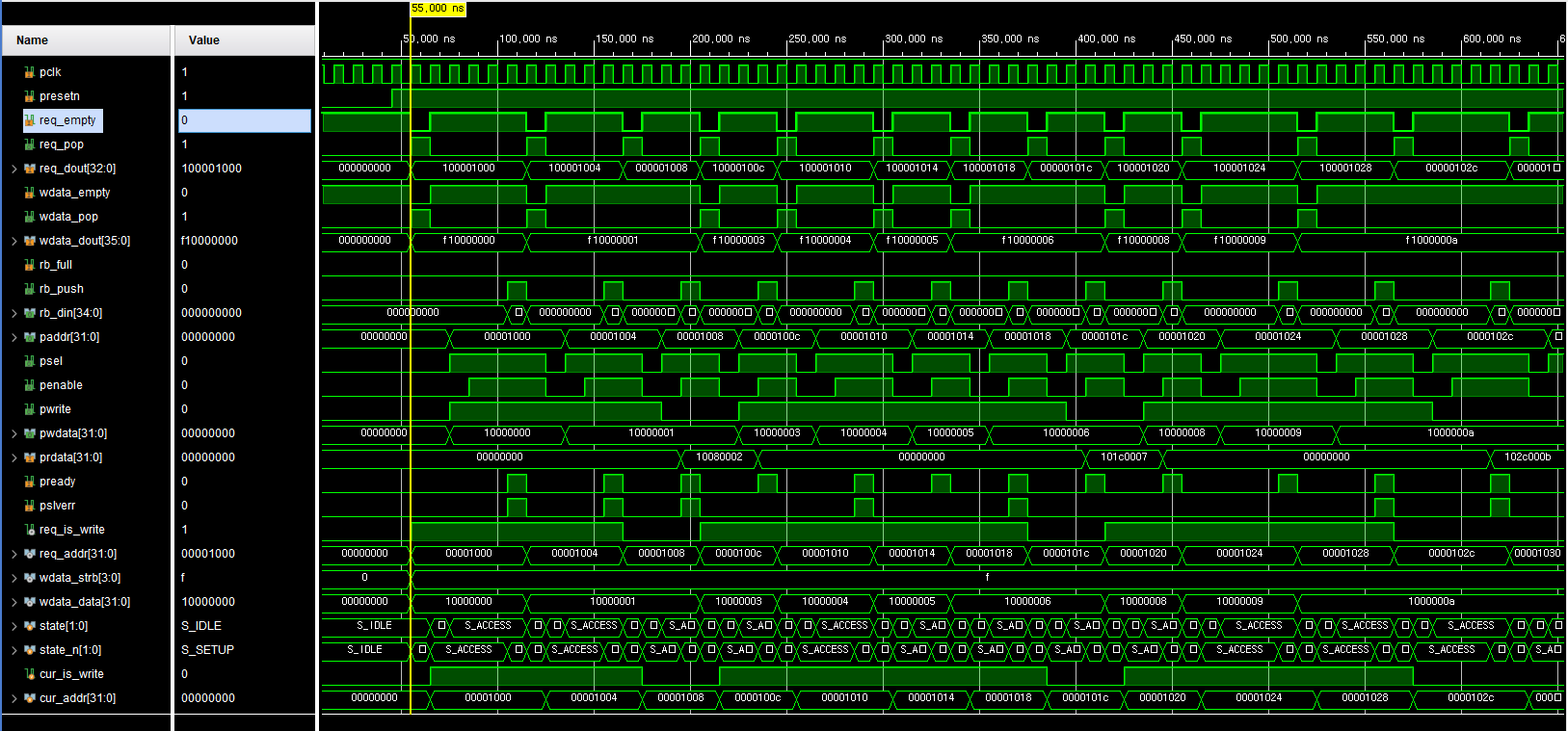
1) Test 목표
- Req/WData FIFO로부터 트랜잭션을 수신해 APB 2-Phase 프로토콜(SETUP/ACCESS)을 정확히 생성하는지 검증
- PREADY wait-state, PSLVERR → SLVERR 매핑, Read/Write 분기, Readback FIFO push 동작 확인
- 랜덤 트랜잭션 스트레스 상황에서 FSM이 안정적으로 동작하는지 검증
2) Testbench 구성
-
클럭 및 리셋
- pclk: 10 ns
- presetn: 초기 구간 0 → 1
-
Stimulus 시나리오
- 총 20개의 트랜잭션을 랜덤 생성
- 트랜잭션 타입: READ / WRITE
- addr: 0x00001000 + i*4
- wdata: 0x10000000 + i
- wait-cycle: 0 ~ 3 사이 랜덤 PREADY 지연
- resp: OKAY / SLVERR 랜덤
- Req FIFO / WData FIFO 는 TB에서 직접 구동하는 모델로 구성
- APB 슬레이브 모델은 다음 역할 수행
- PSEL/PENABLE/PWRITE/PADDR/PWDATA에 반응
- wait-cycle만큼 PREADY=0 유지 후 1로 전환
- READ의 경우 prdata 패턴 생성
- PSLVERR는 resp 필드에 따라 0/1 발생
- 총 20개의 트랜잭션을 랜덤 생성
-
Self-check 방식
- 각 트랜잭션에 대해 기대 응답을 미리 기록
- FSM이 Readback FIFO에 생성한
{is_write, resp, rdata}를 scoreboard로 비교 - mismatch 발생 시 해당 트랜잭션 index, addr, 기대값/실제값 출력 후 시뮬레이션 종료
3) 주요 파형 분석
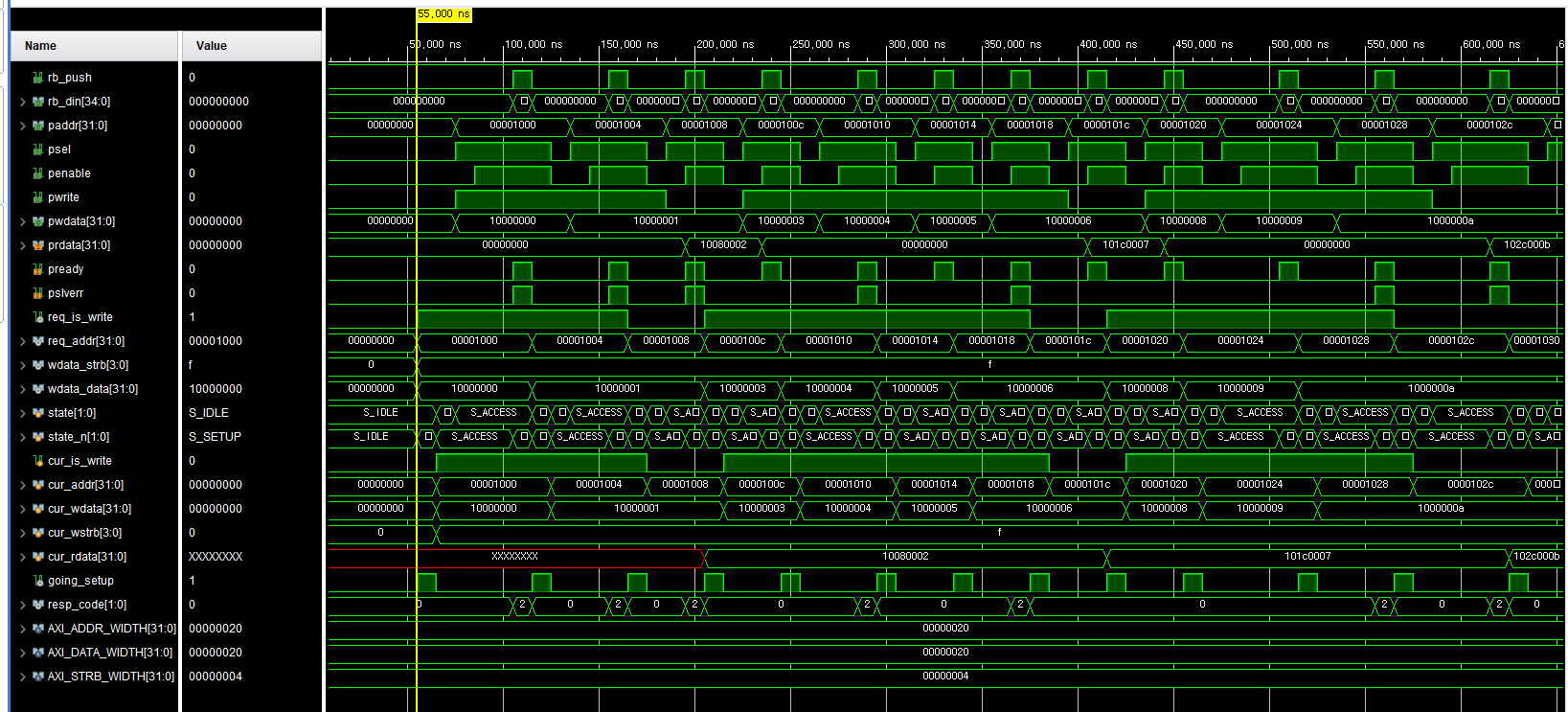
-
IDLE → SETUP 진입
- req_empty=0, rb_full=0인 상태에서 going_setup=1
- 이때 req_pop=1, (write면) wdata_pop=1이 1사이클 발생
- cur_is_write, cur_addr, cur_wdata 등이 래치됨
-
SETUP 상태
- psel=1, penable=0
- paddr, pwrite, pwdata가 cur_* 값으로 셋업
-
ACCESS 상태
- psel=1, penable=1
- pready=0인 동안 해당 상태 유지
- pready=1 되는 클럭에서
- rb_push=1, rb_din={cur_is_write, resp_code, rdata}
- state_n=IDLE로 전환
-
Read 트랜잭션
- state==S_ACCESS && pready && !cur_is_write 조건에서 prdata를 cur_rdata에 래치
- rb_din의 rdata 필드로 전달
4) Corner 포인트
- Read/Write 공통으로 Req FIFO에 항목이 있고 Readback FIFO가 full이 아닐 때만 새 트랜잭션을 시작한다.
- Write인 경우 WData FIFO까지 empty가 아니어야 SETUP으로 진입한다.
- pready가 계속 0이면 ACCESS 상태에서 대기하며 timeout 로직은 현재 추가하지 않았지만 확장 여지가 있다.
- PSLVERR=1이면 resp_code=SLVERR(2'b10), 아니면 OKAY(2'b00)로 정확히 매핑된다.
5) 발생했던 문제와 해결 과정
APB Master FSM 모듈을 단위 테스트하는 과정에서 APB 2-Phase timing, rb_din 패킹 구조, Testbench 타이밍 오류 등 여러 문제가 발견되었다. 아래 표는 실제 검증 과정에서 확인된 문제들과 그 해결책을 정리한 것이다.
- 테스트 중 발생했던 문제 요약
| 번호 | 문제 내용 | 원인 | 해결 방법 |
|---|---|---|---|
| 1 | ACCESS 단계에서 psel/penable 조건 FAIL | TB가 penable=1 되기 전 ACCESS 체크 | wait(psel && penable) 레벨 기반 체크로 수정 |
| 2 | rb_din 패킷에서 is_write/resp mismatch | 슬라이스 인덱싱 오류로 resp_code가 is_write 비트 덮음 | concat 기반 {is_write, resp, rdata} 패킹으로 수정 |
| 3 | READ rdata mismatch | TB에서 prdata & pready를 같은 사이클에 올려 race 발생 | prdata 세팅 후 pready 상승하도록 순서 조정 |
| 4 | read/write 교차 시 is_write 틀림 | going_setup 래치 타이밍 미세 오프셋 | 래치 조건 정교화 및 동기화 확인 |
| 5 | run 1000ns로 인해 테스트 중단 | TCL 시간 제한으로 시뮬레이션 조기 종료 | run all 또는 충분한 run time 설정 |
-
핵심 해결 포인트
A. APB 2-Phase Timing 보완
TB가 ACCESS를 너무 일찍 검사하여 매번 FAIL 발생.
wait(psel && !penable) → wait(psel && penable) 구조로 변경해 정확한 SETUP/ACCESS 검증.B. rb_din 비트 패킹 오류 해결
슬라이스 접근으로 비트가 뒤엉킴.
rb_din = {cur_is_write, resp_code, rdata}; 로 안전하게 해결.C. prdata race condition 해결
TB에서 pready & prdata를 동시에 올리면 FSM 타이밍이 깨짐.
prdata → pready 순서로 조정하여 READ mismatch 해결. -
요약
- APB 2-Phase 타이밍 문제 해결
- rb_din 패킹 구조 개선
- READ race condition 제거
- 시뮬레이션 시간 제한 문제 해결
모든 수정 후 20개의 랜덤 트랜잭션 스트레스 테스트가 100% 통과되었으며
APB Master FSM은 정상 동작을 보였다.
6) 검증 결과 요약
- APB 2-Phase 프로토콜(SETUP/ACCESS)이 모든 트랜잭션에서 정확히 생성된다.
- wait-state가 존재해도 FSM은 pready=1까지 ACCESS 상태를 유지하며 정상 동작한다.
- Readback FIFO 패킷이 기대값과 정확히 일치하며, 20개 랜덤 트랜잭션 모두 mismatch 없이 종료된다.
→ APB Master FSM은 Req/WData FIFO → APB bus → Readback FIFO까지의 데이터 경로를 안정적으로 제어하는 블록으로 검증되었다.
7.3 전체 브릿지 Testbench (axi2apb_with_sram)
top-level TB에서는 AXI 인터페이스를 통해 실제로 write와 read를 수행하고, APB SRAM에 저장된 데이터와 일치하는지 확인한다.
1) Test 목표
- AXI → Frontend → Req/WData FIFO → APB FSM → SRAM → Readback FIFO → Backend → AXI
전체 경로(end-to-end)가 데이터 손실 없이 동작하는지 검증 - write/read 데이터 일치, SLVERR 전파, FIFO backpressure 등 시스템 레벨 동작 확인
2) Testbench 구성
-
AXI Master 역할을 하는 TB에서 다음 시퀀스를 수행
- 특정 주소에 write
- 같은 주소에 read
- 읽어온 값과 write 값 비교
- 여러 주소에 대해 연속 write/read 반복
- APB 슬레이브에서 특정 주소 범위에 대해 PSLVERR 발생시키고 AXI 응답이 SLVERR로 전달되는지 확인
-
SRAM 슬레이브 모델
- APB 프로토콜에 따라 write 시 메모리에 저장, read 시 해당 주소 값을 반환
- 일부 주소 범위에서 PSLVERR=1을 강제로 발생시켜 에러 핸들링을 검증
3) 파형 관찰 포인트
-
AXI 측
- AW/W/AR/B/R 채널의 VALID/READY가 규격대로 동작하는지
- write 후 read에서 데이터 일치 여부
- SLVERR 시 B/R 채널의 RESP 값이 2'b10으로 올라오는지
-
내부 FIFO / FSM
- Req/WData/Readback FIFO 포인터가 정상적으로 증가/감소하는지
- full/empty 경계 상황에서 backpressure가 제대로 걸리는지
- APB FSM의 상태 전이가 IDLE → SETUP → ACCESS 순으로 반복되는지
4) System-level 검증 결과 요약
- 단일 트랜잭션뿐 아니라 연속 트랜잭션에서도 데이터 일치 검증 PASS
- PSLVERR 발생 시 AXI 슬레이브 응답이 SLVERR로 전달되는 것 확인
- aclk ≠ pclk 환경에서 CDC 관련 문제 없이 모든 시나리오가 정상 동작
→ 단위 모듈 검증 결과와 합쳐 전체 AXI4-Lite to APB 브릿지가 시스템 관점에서도 안정적으로 동작함을 확인했다.
7.4 검증 결과 종합 및 향후 개선
- 모듈 단위에서는 async FIFO, Frontend, APB FSM, Backend 네 블록 모두 Directed + Random 환경에서 정상 동작을 확인했다.
- top-level에서는 실제 AXI 트랜잭션을 통해 SRAM 접근을 수행하며 데이터 일치, SLVERR 전파, wait-state 처리 등을 모두 검증했다.
- 현 단계에서 스펙 범위 내 기능은 충분히 커버되었으며 기능적 이슈는 발견되지 않았다.
향후 확장 아이디어:
- UVM 기반 환경으로 확장하여 커버리지 기반 검증 강화
- 포멀 검증(Formal)을 통해 FIFO 안전성, FSM deadlock 부재 등을 수학적으로 증명
- 다양한 버스 마스터 시나리오(연속 read/write, address pattern 등)를 자동 생성하는 랜덤 시퀀스 추가
8. Conclusion
이번 AXI4-Lite to APB Bridge 설계 프로젝트는 단순히 버스 변환 IP를 하나 만든 것 이상으로 의미가 있었다.
- AXI와 APB 프로토콜을 문서로만 보는 것이 아니라, 실제 RTL 신호와 상태머신으로 구현해보면서 프로토콜에 대한 감각을 얻었다.
- 서로 다른 클록 도메인을 async FIFO로 연결하는 CDC 구조를 직접 설계하고 검증하면서, 클록 도메인 분리와 타이밍 제약의 중요성을 체감했다.
- 합성 결과와 타이밍 리포트, 자원 사용, Power 분석을 해석하는 연습을 할 수 있었다.
- 무엇보다도, 버스 IP를 설계하고 검증하는 엔지니어의 관점에서 프로젝트를 바라보게 된 것이 큰 수확이었다.
앞으로는 이 브릿지를 기반으로 다음과 같은 확장을 해보고 싶다.
- APB 슬레이브를 여러 개 연결하는 APB 디코더 추가
- AXI4 Full 버전을 지원하는 브릿지로 확장
- Register map 자동 생성 스크립트 및 통합 테스트 환경 구축
이번 경험을 바탕으로 AMBA 기반 SoC 설계와 버스 아키텍처에 대한 이해를 한 단계 더 끌어올릴 수 있었다고 생각한다.
