1. 알고리즘이란?
어떤 문제가 있을 때, 그것을 해결하기 위한 여러 동작들의 모임
2. 알고리즘과 친해지기
최댓값 찾기
Q. 다음과 같이 숫자로 이루어진 배열이 있을 때, 이 배열 내에서 가장 큰 수를 반환하시오
[3, 5, 6, 1, 2, 4]
첫번째 방법
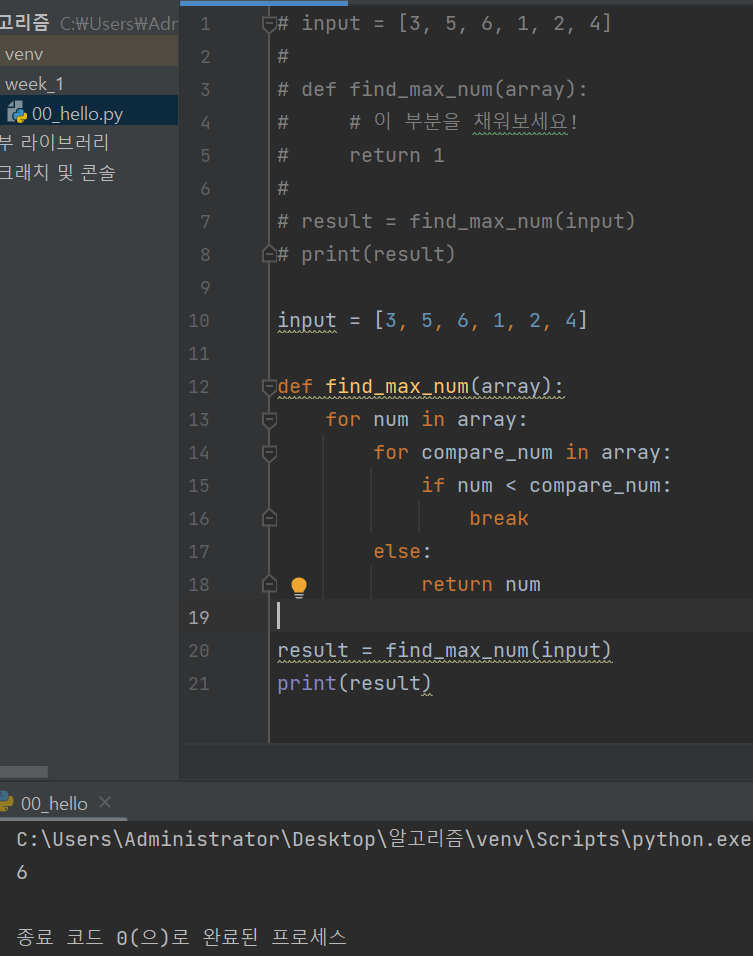
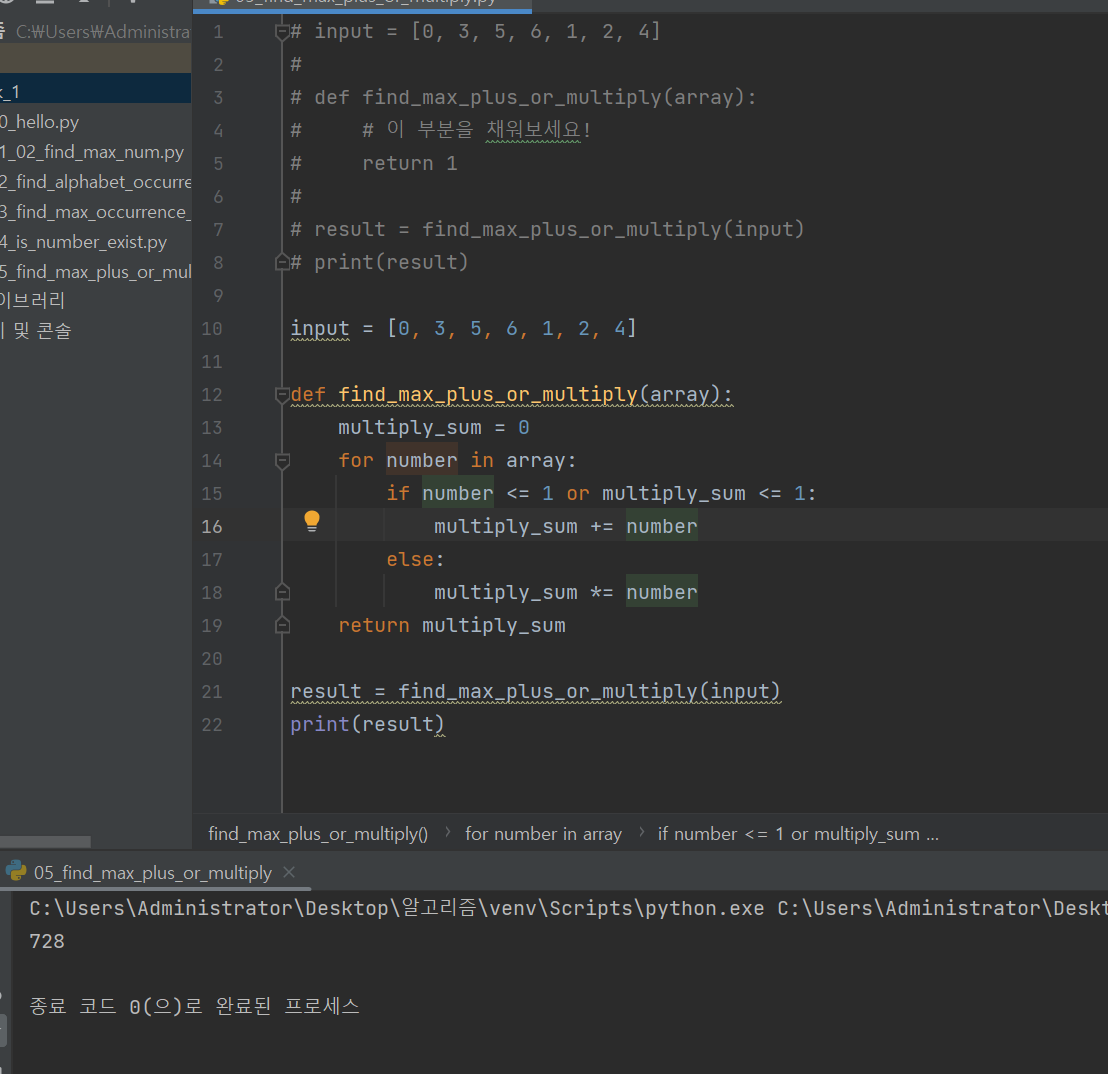
두번째 방법

어떤게 더 효율적일까?? 생각해보자!!!
최빈값 찾기
Q. 다음과 같은 문자열을 입력받았을 때, 어떤 알파벳이 가장 많이 포함되어 있는지 반환하시오
"hello my name is sparta"
문자인지 확인하는 방법은 str.isalpha()를 사용해 해당 문자열이 알파벳인지 확인 가능하다.
먼저 알파벳 별로 빈도수를 리스트에 저장한다.
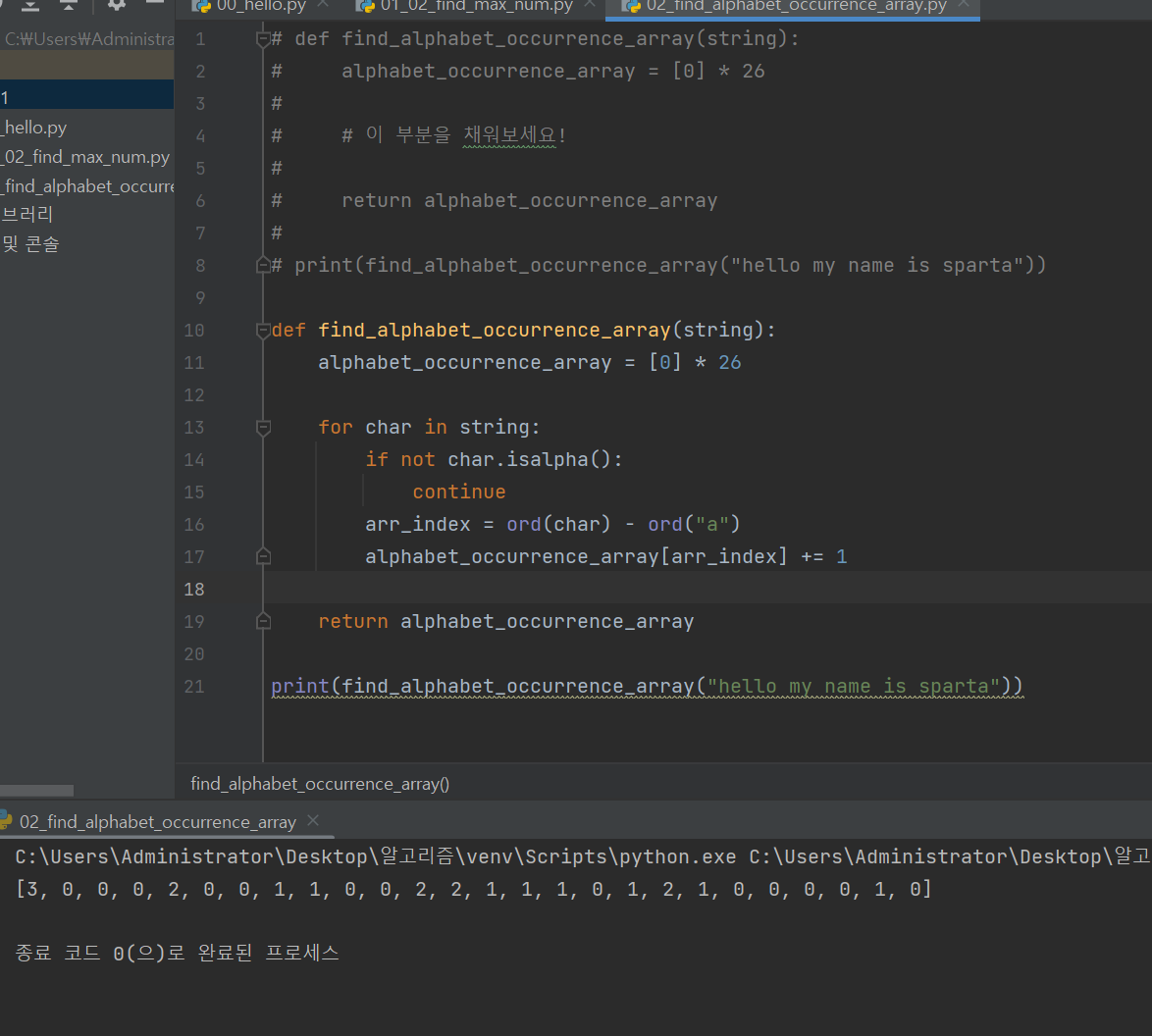
일단 길이가 26인 0으로 초기화된 배열을 만들어준다.
alphabet_occurrence_array = [0] * 26이제 알파벳마다 이 배열의 원소에 빈도수를 추가해줘야 한다.
(a일때는 0번째원소에 1추가, b는 1번째 원소에 1추가....)
이는 아스키 (ASCII) 코드를 사용해야 한다.
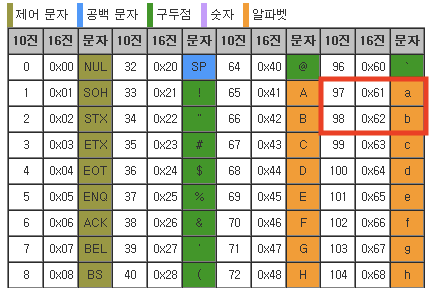
# 내장 함수 ord() 이용해서 아스키 값 받기
print(ord('a')) # 97
print(ord('a') - ord('a')) # 97-97 -> 0
print(ord('b') - ord('a')) # 98-97 -> 1이걸 이용해서 arr_index = ord(char) - ord('a')로 arr.index의 값을 만들어준다
예를들어 char가 'a'라면 0, 'c'라면 2가 나올것이다.
이 값을 alphabet_occurrence_array[여기 넣고] +1씩 증가시켜주면 된다.
이렇게 하면 결과로 알파벳별 빈도수가 배열로 나타난다.
이제 아까 위에서 최댓값을 구하는 방식을 사용해서 해본다.
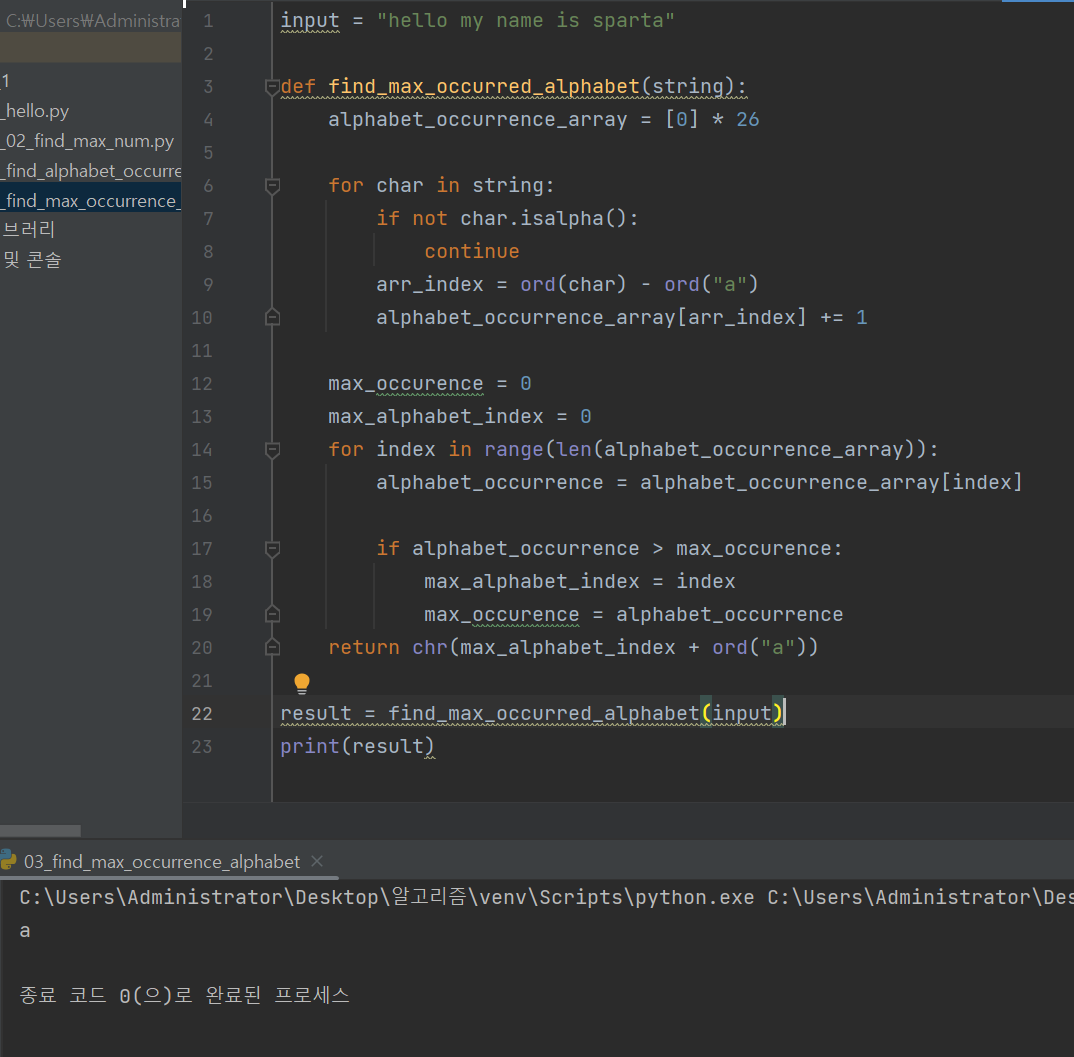
여기서 주의할 점은 그냥하면 0이 나오기 때문에 인덱스를 문자로 다시 변경해줘야한다.
아스키 코드 번호"를 "실제 문자"로 변환하려면 chr() 함수를 사용
chr(97) == 'a'
chr(0 + ord('a')) == 'a'
chr(0 + 97) == 'a'
chr(1 + 97) == 'b'3. 시간 복잡도 판단하기
시간 복잡도란?
입력값과 문제를 해결하는 데 걸리는 시간과의 상관관계
최댓값 찾기 알고리즘에서 시간 복잡도 판단해보기
- 첫번째 방법에서
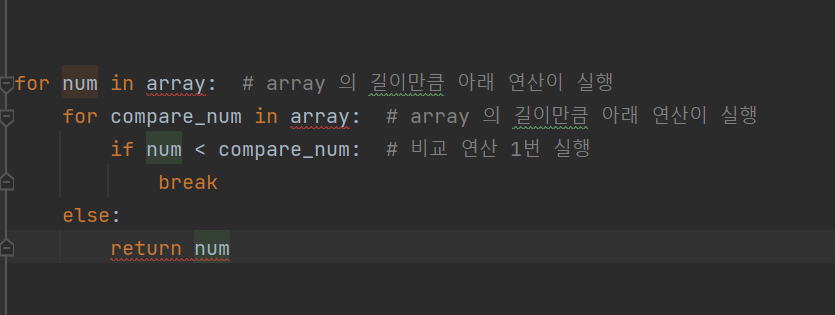
각 줄이 실행되는걸 1번의 연산이 된다!!!!! 라고 생각하고 있으면 된다.
위 방법에선
array의 길이 X array의 길이 X 비교연산 1번
의 시간이 필요하다.
여기서 array(입력값)의 길이는 보통 N이라고 표현.
그렇다면 다음과 같이 표현 가능하다 ---> N x N
그러면 이제 이 함수는 N^2 만큼의 시간이 걸렸겠구나! 라고 말할 수 있다.
- 두번째 방법에서
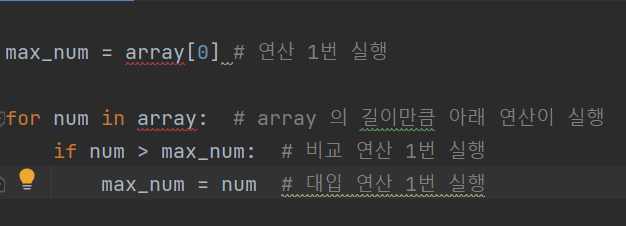
- max_num 대입 연산 1번
- array의 길이 X (비교 연산 1번 + 대입 연산 1번)
의 시간이 필요하다.
즉 -----> 1+2 x N
2N + 1 만큼의 시간이 걸렸구나!! 라고 알 수 있다.
비교해보면 2번째 방법이 N의 길이가 길어질수록 훨씬 효율적이라는 것을 알 수 있다.
4. 공간 복잡도 판단하기
공간 복잡도란?
입력값과 문제를 해결하는 데 걸리는 공간과의 상관관계
입력값이 2배로 늘어났을 때 문제를 해결하는 데 걸리는 공간은 몇 배로 늘어나는지를 보는 것
입력값이 늘어나도 걸리는 공간이 덜 늘어나는 알고리즘이 좋은 알고리즘.
시간 복잡도보다는 차이가 크지 않기 때문에 시간복잡도를 더 신경 써줘야 한다!
5. 점근 표기법(asymptotic notation)
점근 표기법이란?
알고리즘의 성능을 수학적으로 표기하는 방법. 알고리즘의 "효율성" 평가하는 방법
점근 표기법의 종류에는
빅오(Big-O)표기법, 빅 오메가(Big-Ω) 표기법이 있다.
빅오 표기법은 최악의 성능이 나올 때 어느 정도의 연산량이 걸릴것인지,
빅오메가 표기법은 최선의 성능이 나올 때 어느 정도의 연산량이 걸릴것인지에 대해 표기.
예를 들어
input = [3, 5, 6, 1, 2, 4] 배열에서 특정숫자가 존재하는지 안하는지 찾는문제라면?
만약 찾는숫자가 3이라면 첫번째 원소 비교하는순간 바로찾음. 1번의 연산으로 끝난다.
하지만 input = [4, 5, 6, 1, 2, 3] 여기에서 3을 찾는다면??
마지막에 가서야 찾을것이다. 운이나쁘면 input의 길이(N)만큼 연산해야 할것...
이처럼 알고리즘의 성능은 항상 동일한게 아니라 입력값에 따라 달라질 수 있다.
빅오 표기법으로 표시하면 ,
빅 오메가 표기법으로 표시하면 의 시간복잡도를 가진 알고리즘이다!
라고 표현가능
알고리즘에서는 대부분 빅오 표기법으로 분석하는데, 항상 최악의 경우를 대비해야 하기 때문.
6. 알고리즘 더 풀어보기
Q. 다음과 같이 0 혹은 양의 정수로만 이루어진 배열이 있을 때, 왼쪽부터 오른쪽으로 하나씩 모든 숫자를 확인하며 숫자 사이에 '✕' 혹은 '+' 연산자를 넣어 결과적으로 가장 큰 수를 구하는 프로그램을 작성하시오.
단, '+' 보다 '✕' 를 먼저 계산하는 일반적인 방식과는 달리, 모든 연산은 왼쪽에서 순서대로 이루어진다.
[0, 3, 5, 6, 1, 2, 4]