01. 정렬 - 1
정렬이란?
데이터를 순서대로 나열하는 방법을 의미
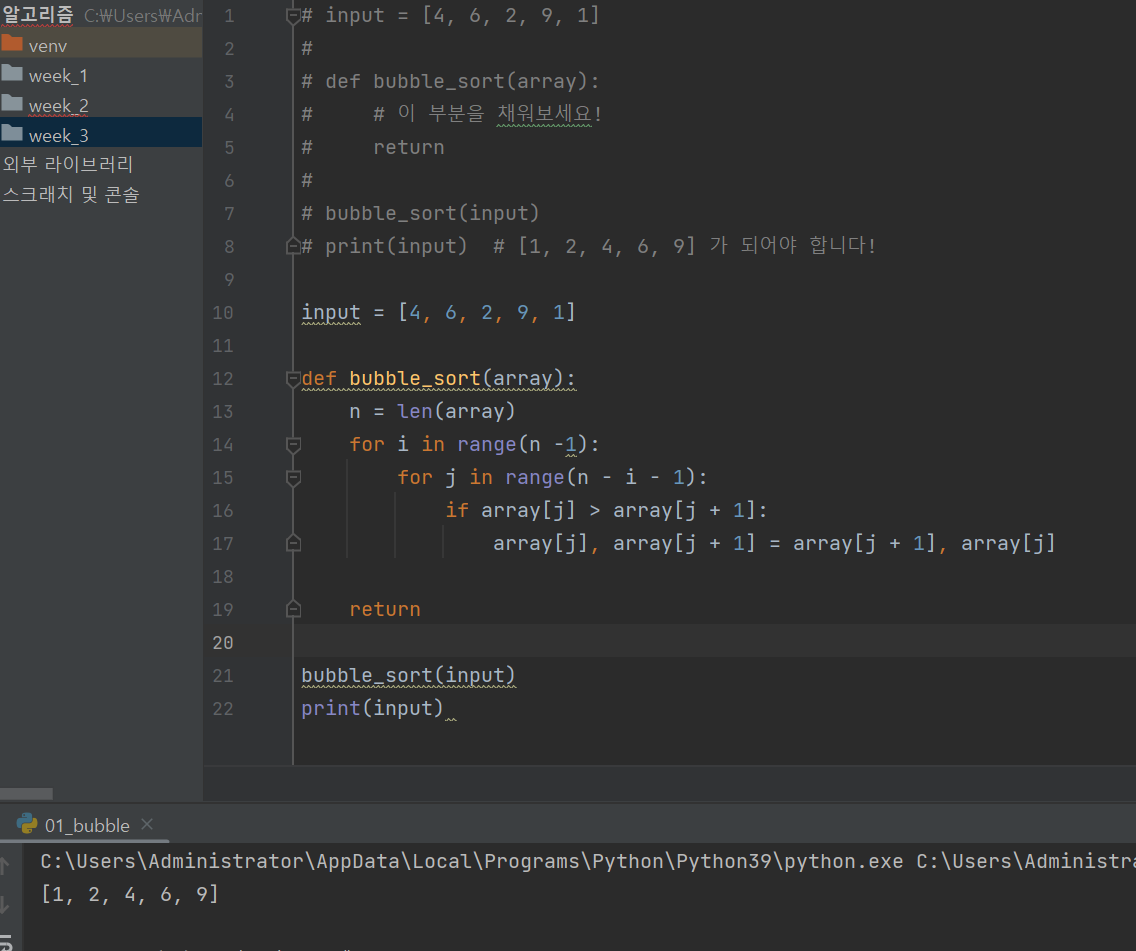
버블정렬

버블 정렬은 첫 번째 자료와 두 번째 자료를, 두 번째 자료와 세 번째 자료를, 세 번째와 네 번째를, … 이런 식으로 (마지막-1)번째 자료와 마지막 자료를 비교하여 교환하면서 자료를 정렬하는 방식.
Q. 다음과 같이 숫자로 이루어진 배열이 있을 때, 오름차순으로 버블 정렬을 이용해서 정렬하시오.
02. 정렬 - 2
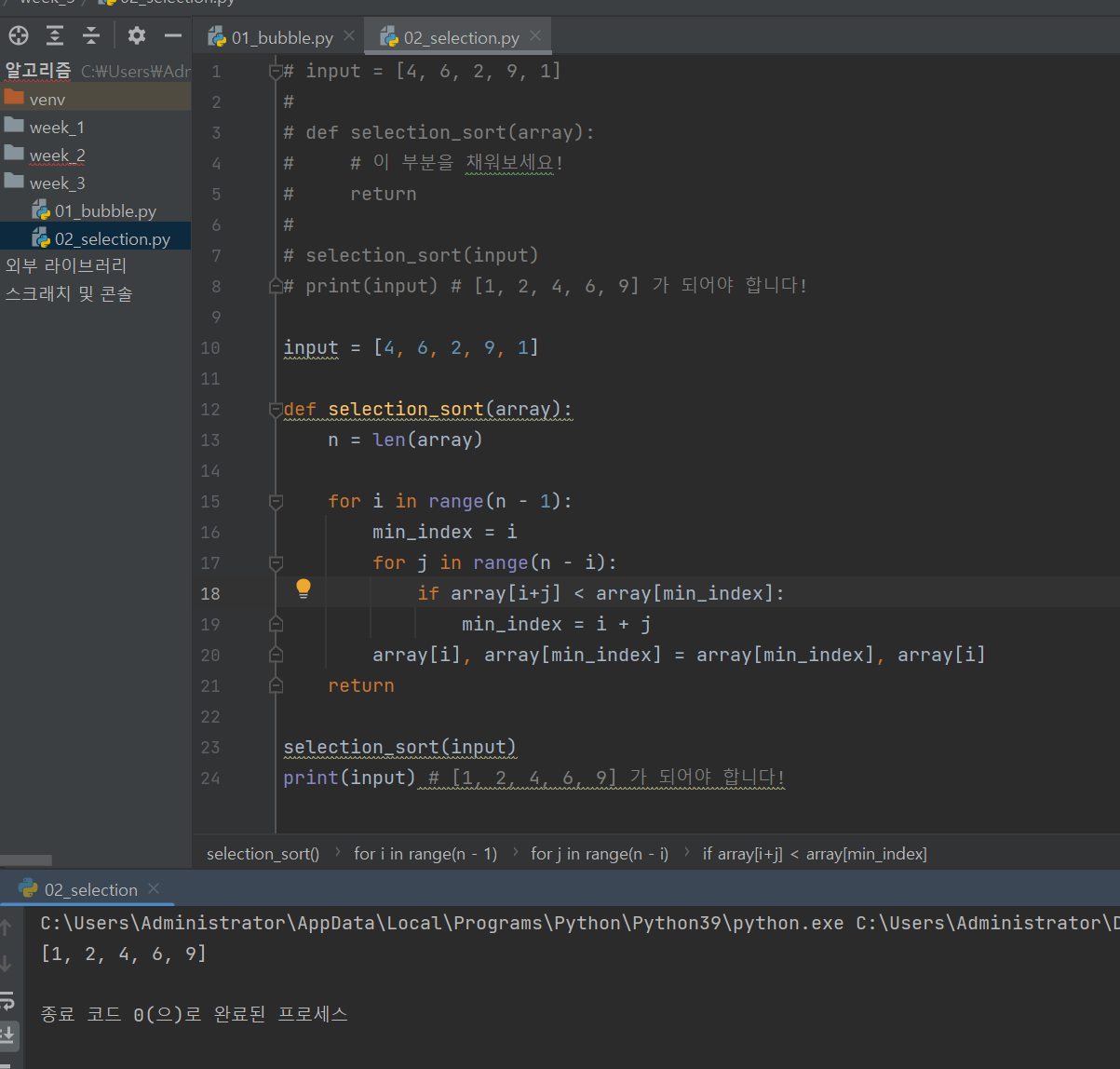
선택 정렬
[4, 6, 2, 9, 1] --> [1, 6, 2, 9, 4] --> [1, 2, 6, 9, 4] --> [1, 2, 4, 9, 6] --> [1, 2, 4, 6, 9]
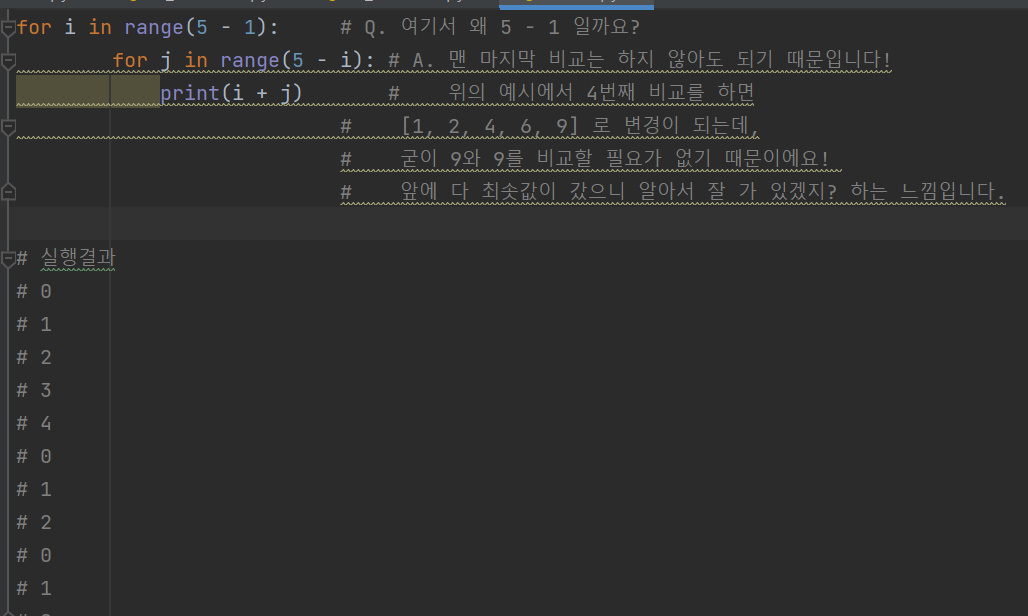
배열의 크기만큼 반복했다가,
앞에서부터 1개씩 줄어들면서 반복된다.
이 반복문을 구현하려면 아래처럼 작성!
버블 정렬하고 다른 건 바로 "최솟값"을 찾아 변경하는 것이다.
따라서, min_index라는 변수를 설정해줘 비교해준다.
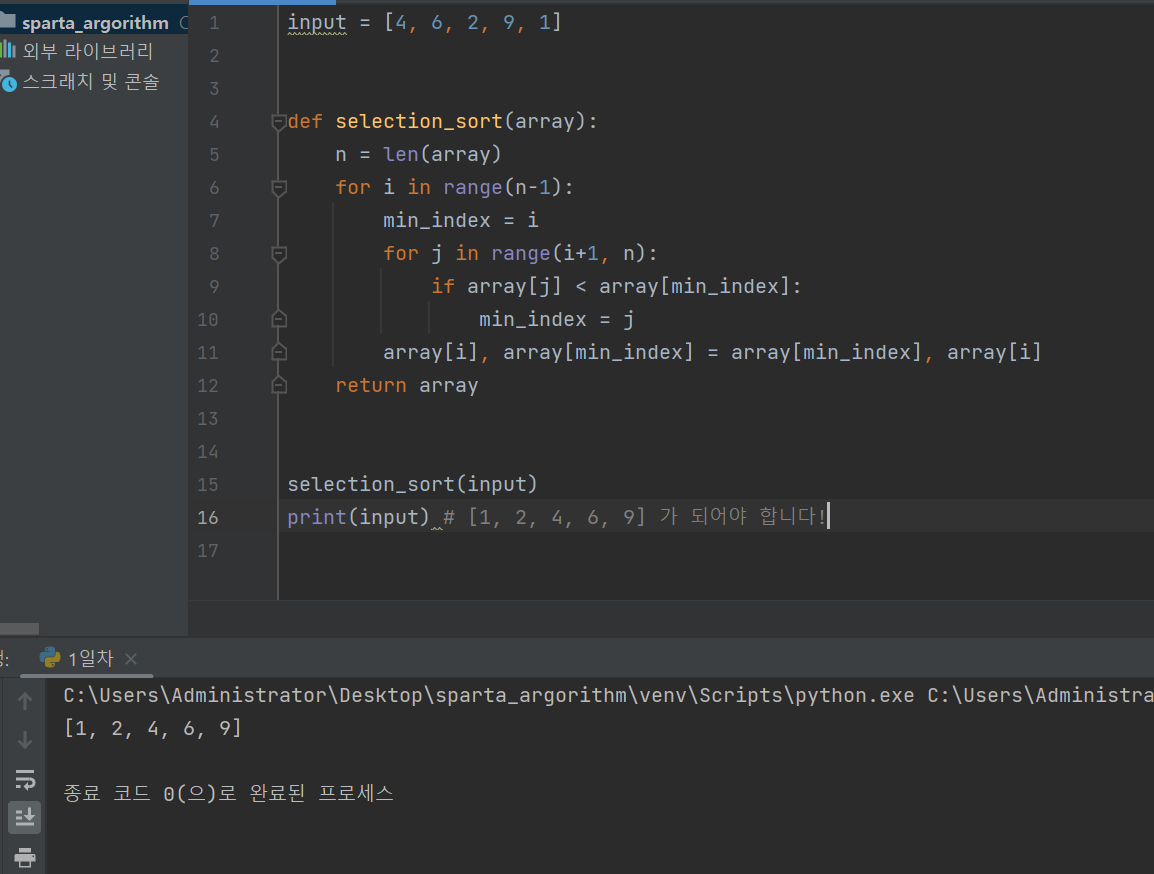
(위 식을 내가 좀 더 이해하기 쉽게 다시 써봄)
삽입 정렬
[4, 6, 2, 9, 1] -> [4, 6, 2, 9, 1] -> [2, 4, 6, 9, 1] -> [2, 4, 6, 9, 1] -> [1, 2, 4, 6, 9]
1번째 : [4, 6, 2, 9, 1]
← 비교!
2번째 : [4, 6, 2, 9, 1]
← ← 비교!
3번째 : [2, 4, 6, 9, 1]
← ← ← 비교!
4번째 : [2, 4, 6, 9, 1]
← ← ← ← 비교! 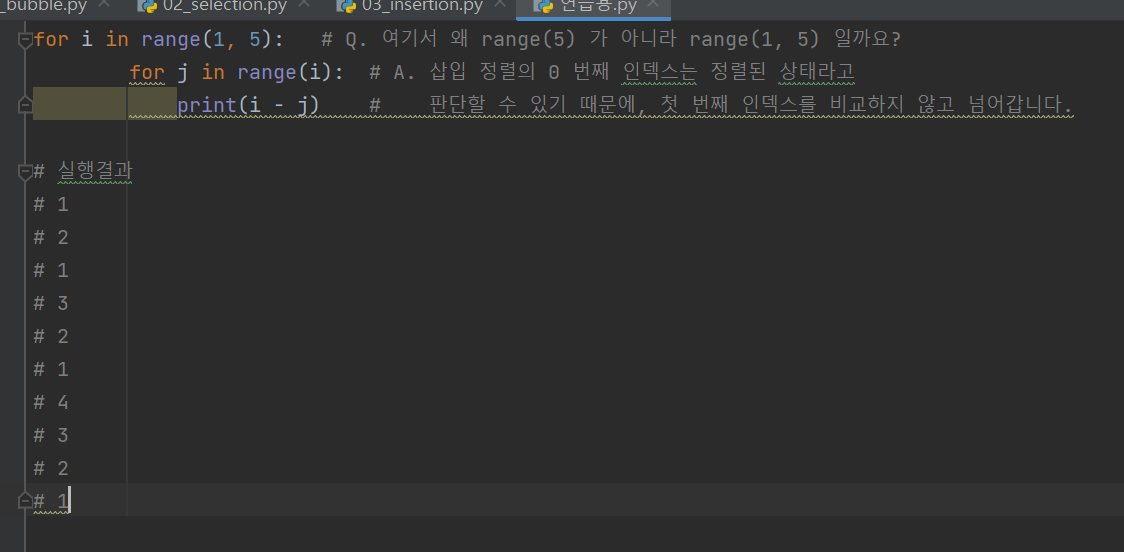

이걸 내가 알아보기 더 쉽게 바꿨다.
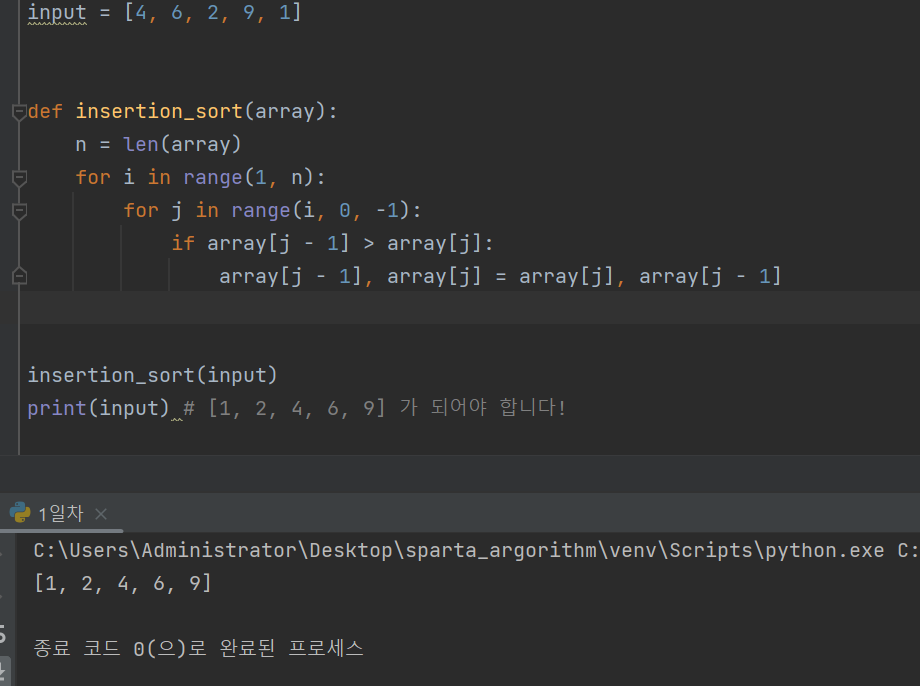
시간복잡도를 더 줄이기 위해 최적화를 해서 다시 구현
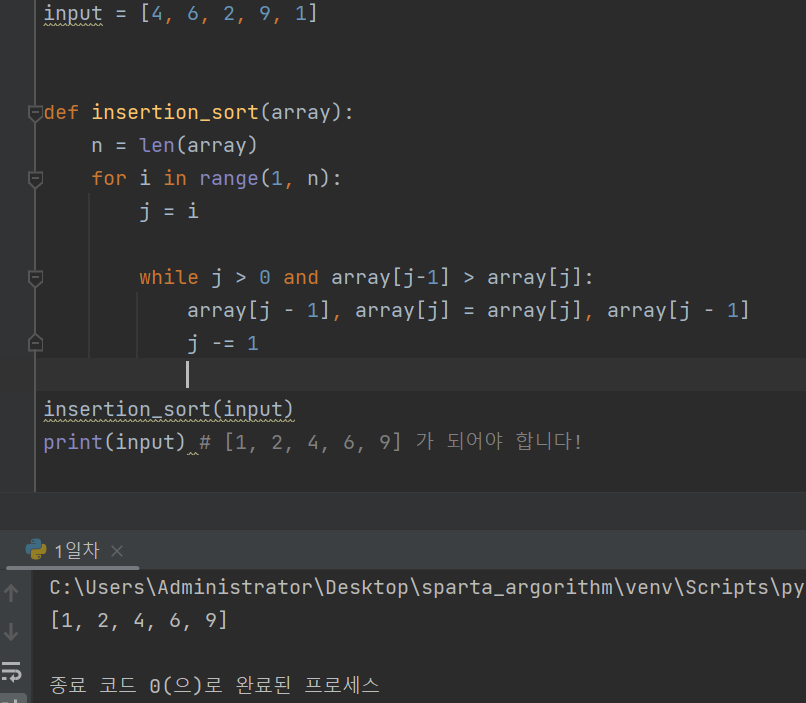
03. 정렬 - 3
병합 정렬 (merge)
병합 정령은 배열의 앞부분과 뒷부분의 두 그룹으로 나누어 각각 정렬한 후
병합하는 작업을 반복하는 알고리즘.
[1, 2, 3, 5] # 정렬된 배열 A
[4, 6, 7, 8] # 정렬된 배열 B
[] # 두 집합을 합칠 빈 배열 C
↓
1단계 : [1, 2, 3, 5]
↓
[4, 6, 7, 8]
1과 4를 비교합니다!
1 < 4 이므로 1을 C 에 넣습니다.
C:[1]
↓
2단계 : [1, 2, 3, 5]
↓
[4, 6, 7, 8]
2와 4를 비교합니다!
2 < 4 이므로 2를 C 에 넣습니다.
C:[1, 2]
↓
3단계 : [1, 2, 3, 5]
↓
[4, 6, 7, 8]
3과 4를 비교합니다!
3 < 4 이므로 3을 C 에 넣습니다.
C:[1, 2, 3]
↓
3단계 : [1, 2, 3, 5]
↓
[4, 6, 7, 8]
5와 4를 비교합니다!
5 > 4 이므로 4을 C 에 넣습니다.
C:[1, 2, 3, 4]
↓
3단계 : [1, 2, 3, 5]
↓
[4, 6, 7, 8]
5와 6을 비교합니다!
5 < 6 이므로 5을 C 에 넣습니다.
C:[1, 2, 3, 4, 5]
엇, 이렇게 되면 A 의 모든 원소는 끝났습니다!
그러면 B에서 안 들어간 원소인
[6, 7, 8] 은 어떡할까요?
하나씩 C 에 추가해주면 됩니다.
C:[1, 2, 3, 4, 5, 6, 7, 8] 이렇게요!
그러면 A 와 B를 합치면서 정렬할 수 있었습니다.출저 : 스파르타 코딩클럽
그러면 직접 코드로 문제풀이 해보자
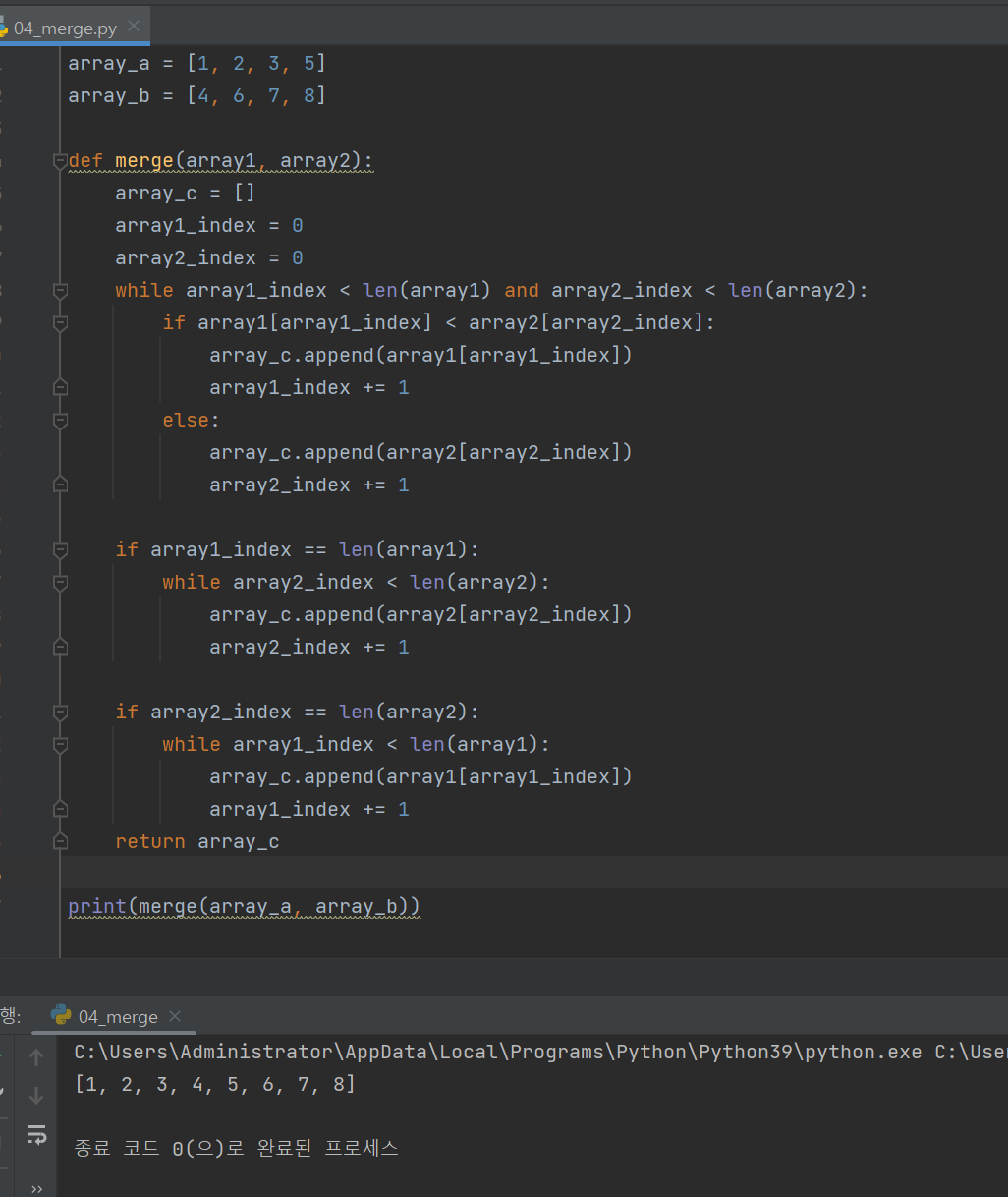
병합 정렬 (merge Sort)
분할정복의 개념을 사용
분할정복 : 문제를 작은 2개의 문제로 분리하고 각각 해결한 다음, 결과를 모아서 원래의 문제 해결
[5, 3, 2, 1, 6, 8, 7, 4]
[5, 3, 2, 1][6, 8, 7, 4]
[5, 3][2, 1] [6, 8][7, 4]
[5][3] [2][1] [6][8] [7][4]
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
[5][3] 을 병합하면 [3, 5]
[2][1] 을 병합하면 [1, 2]
[6][8] 을 병합하면 [6, 8]
[7][4] 을 병합하면 [4, 7]
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
다시
[3, 5] 과 [1, 2]을 병합하면 [1, 2, 3, 5]
[6, 8] 와 [4, 7]을 병합하면 [4, 6, 7, 8]
다시
[1, 2, 3, 5] 과 [4, 6, 7, 8] 를 병합하면 [1, 2, 3, 4, 5, 6, 7, 8]
이를 분할 정복, Divide and Conquer 라고 한다.
이렇게 동일한 형태로 반복되는 경우에 떠오르는것?? 바로 "재귀"
MergeSort(시작점, 끝점)이라고 한다면
MergeSort(0, N) = Merge(MergeSort(0, N/2) + MergeSort(N/2, N))
라고 할 수 있다.
즉, 0부터 N까지 정렬한 걸 보기 위해서는
0부터 N/2 까지 정렬한 것과 N/2부터 N까지 정렬한 걸 합치면 된다. 라는 개념
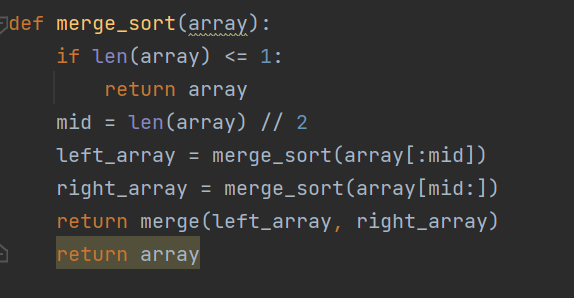
재귀함수이기 때문에 1보다 작거나 같을 때 탈출조건을 써줘야 한다.
04. 스택
스택이란?
한쪽 끝으로만 자료를 넣고 뺄 수 있는 자료 구조.
빨래통을 생각해보자. 맨 마지막에 벗어놓은 옷이 맨 위로 오게된다. 따라서 뺄 때도 맨 위부터 뺀다.
즉 가장 처음에 넣은 빨래는 제일 마지막에 나오고, 제일 늦은 빨래는 제일 빨리나옴
이런 자료구조를 Last In First Out 이라고 해서 LIFO 라고 부른다.
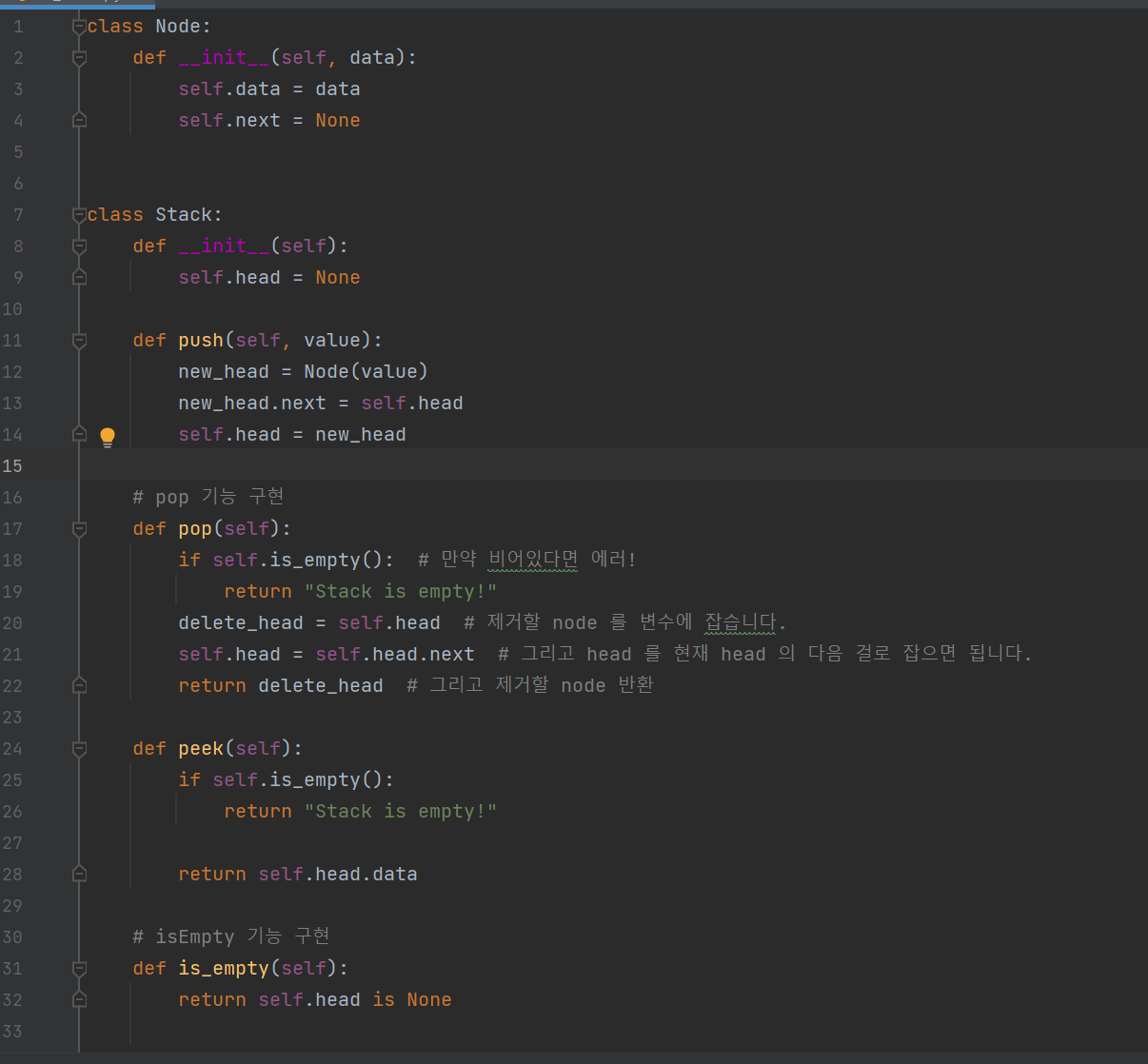
스택 이라는 자료 구조에서 제공하는 기능은 다음과 같다.
push(data) : 맨 앞에 데이터 넣기
pop() : 맨 앞의 데이터 뽑기
peek() : 맨 앞의 데이터 보기
isEmpty(): 스택이 비었는지 안 비었는지 여부 반환해주기
사용 예
05. 큐
큐란?
한쪽 끝으로 자료를 넣고, 반대쪽에서는 자료를 뺄 수 있는 선형구조
만약 줄을 섰을 때, 가장 빨리 섰던 사람이 가장 빨리 밥을먹든 나가든 할 것이다.
이런 자료 구조를 First In First Out 이라고 해서 FIFO 라고 부름.
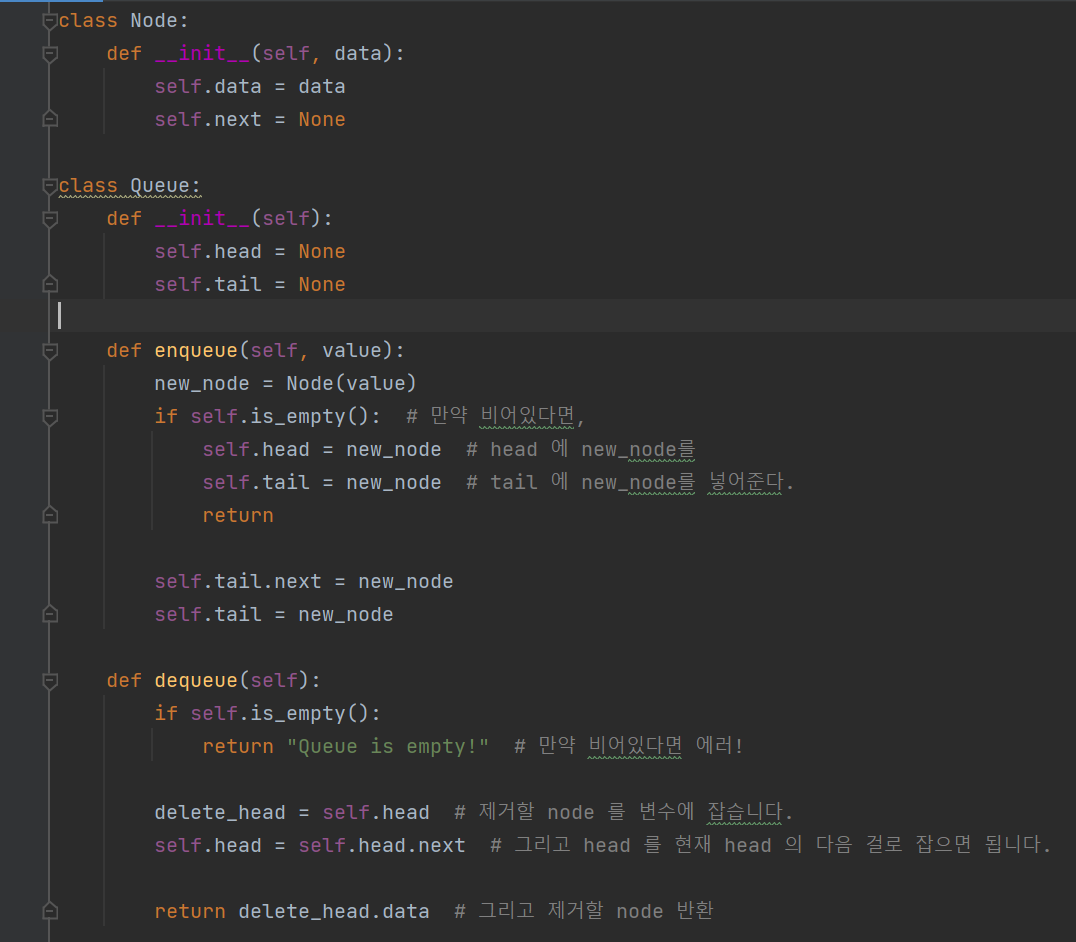
큐라는 자료 구조에서 제공하는 기능은 다음과 같다.
enqueue(data) : 맨 뒤에 데이터 추가하기
dequeue() : 맨 앞의 데이터 뽑기
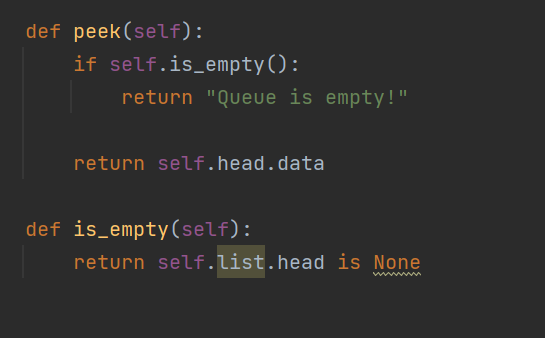
peek() : 맨 앞의 데이터 보기
isEmpty(): 큐가 비었는지 안 비었는지 여부 반환해주기
사용 예
06. 해쉬
해쉬 테이블이란?
컴퓨팅에서 키를 값에 매핑할 수 있는 구조인, 연관 배열 추가에 사용되는 자료 구조이다. 해시 테이블은 해시 함수를 사용하여 색인(index)을 버킷(bucket)이나 슬롯(slot)의 배열로 계산한다. 데이터를 다루는 기법 중에 하나로 데이터의 검색과 저장이 아주 빠르게 진행된다.
그냥 쉽게 딕셔너리 = 해쉬 테이블.. 같다고 보자
값이 배열 어딘가에 있다고 할때, 그걸 찾을 때 해쉬함수 이용
해쉬 함수(Hash Function)는 임의의 길이를 갖는 메시지를 입력하여 고정된 길이의 해쉬값을 출력하는 함수이다
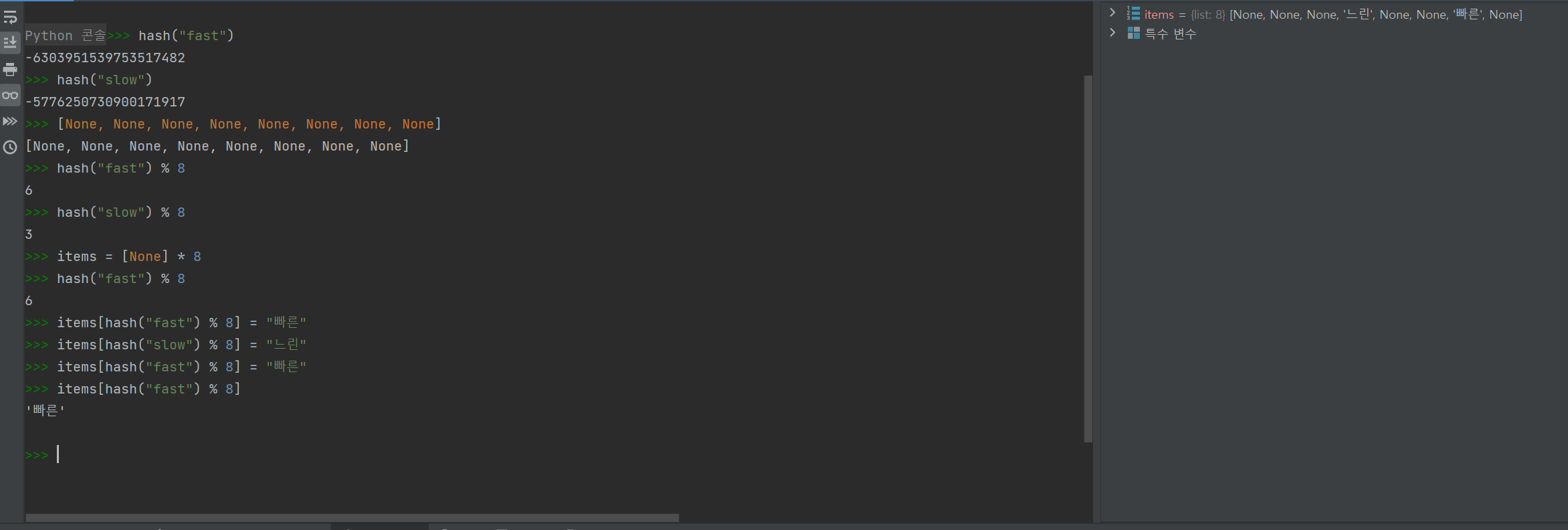
간단하게 딕셔너리를 구현해보자!
put(key, value) : key 에 value 저장하기
get(key) : key 에 해당하는 value 가져오기
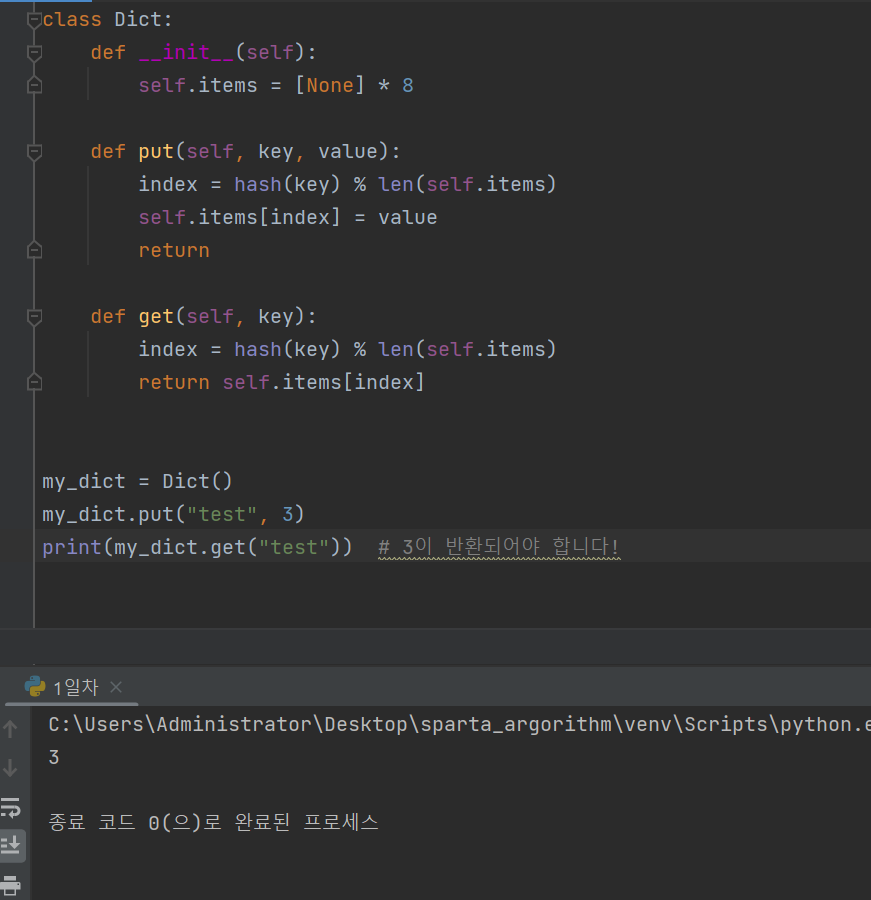
충돌 (collision)
그런데 만약 해쉬의 값이 같으면 어떡하지? 해쉬 값을 배열길이로 나눈값이 똑같으면 어떡하지?
이를 충돌(collision)이 발생했다고 한다.
첫번째 방법은 링크드 리스트 사용하는 방식, 체이닝(chaining) 이라고 한다.
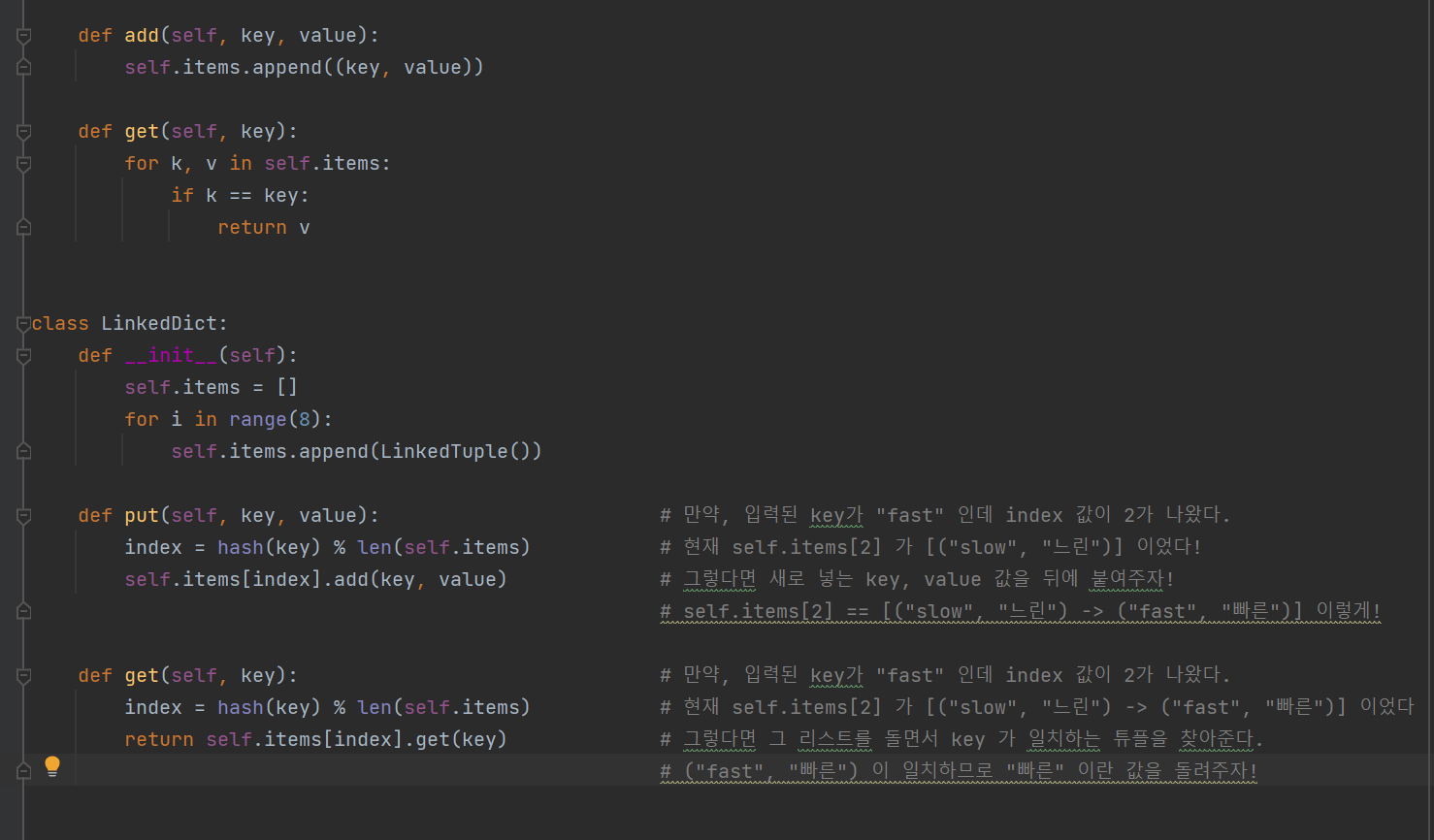
두번째 방법은 개방 주소법(Open Addressing)이 있는데, 나중에 따로 설명하겠다.
정리
-
해쉬 테이블(Hash Table)은 "키" 와 "데이터"를 저장함으로써 즉각적으로 데이터를 받아오고 업데이트하고 싶을 때 사용하는 자료구조.
-
해쉬 함수(Hash Function)는 임의의 길이를 갖는 메시지를 입력하여 고정된 길이의 해쉬값을 출력하는 함수.
-
해쉬 테이블의 내부 구현은 키를 해쉬 함수를 통해 임의의 값으로 변경한 뒤 배열의 인덱스로 변환하여 해당하는 값에 데이터를 저장.
그렇기 때문에 즉각적으로 데이터를 찾고, 추가. -
충돌이 일어난다면 체이닝과 개방 주소법으로 해결
