1. 스프링의 의의
스프링의 정의는 아래와 같다.
자바 엔터프라이즈 개발을 편하게 해주는 오픈소스 경량급 애플리케이션 프레임워크
대충 이게 뭔 개소리야? 하는 짤
스터디 주제는 제어 역전이긴 하지만, 내 성격상 공부 이유부터 따지고 보는 참으로 피곤한 성격인지라 공부의 시작점을 왜 스프링을 쓰는지에 대해서부터 간단하게 따져보고 핵심 원칙들에 대해 (가능하다면) 예제 코드를 따라해보고 진행해 볼 예정.
암튼, 위에서 말한 스프링의 정의에서부터 하나씩 파고들어보면서 스터디 주제까지 닿아보도록 공부를 해 볼 생각.
1) 스프링의 정의
(1) 특징
하나씩 파고들어보자. 우선 자바 기반 프레임워크니까... 라고 당연히 여길 수 있지만 스프링은 애플리케이션 프레임워크 특징을 지녔다. 즉, 애플리케이션의 전 영역을 커버하면서 빠르게, 효율적으로 개발을 진행하는 프레임워크다.
경량급이라는 것은 코드가 적다는 뜻이 아닌, 불필요하게 무겁지 않다의 의미를 지녔다. 스프링 이전에 존재했던 EJB(엔터프라이즈 자바빈즈)는 동작을 위한 무거운 자바 서버(WAS)가 필요했던 반면, 스프링은 가장 단순한 서버환경인 톰캣 등의 환경에서도 완벽하게 동작한다. 만들어진 코드가 지원하는 기술수준이 비슷해도 훨씬 빠르고, 간편하게 작성할 수 있음으로써 생산성과 품질 측면에서 우위을 지닌다.
그 외에도, 오픈소스에 해당해서 구축된 커뮤니티의 규모가 방대하고 투명해서 매우 빠르고 유연한 개발이 가능해진다.
(2) 목적
스프링의 목적은 위에서 전술한 정의와도 일맥상통한다. 결국 엔터프라이즈 애플리케이션 개발을 편하게 하는 것이며, 그 목적을 달성하기 위해 돌파해야 할 난관이 바로 엔터프라이즈 개발의 복잡성이었다.
엔터프라이즈 시스템의 특성상, 다수의 사용자 요청을 동시에 처리하며 서버 자원의 효율적인 공유, 분배를 꾀해야 하고 거기에 더해서 보안과 안정성, 확장성도 챙길 수 있어야 한다. 즉, 개발에 있어 순수한 비즈니스 로직 외에도 고려사항이 많다는 점이 비중을 크게 차지했다.
또한, 단순히 다 배제하고 비즈니스 로직만을 봐도 다양하고 복잡한 업무 처리 기능을 담당하려고 EJB 컨테이너에서 필수 객체들을 상속받으면서 복잡성 자체가 증대됐기 때문에 애플리케이션 개발이 힘들어질 수밖에 없는 것이다. 즉, EJB는 기술 관련 코드 및 규약이 코드 상에 등장하는 침투 방식을 채택했지만 이를 위해서는 EJB가 제공하는 것들에 비즈니스 로직이 강하게 의존되면서 자바의 장점인 객체지향을 한정시키게 됐다.
스프링은 비침투적인 방식을 통한, 기술적인 복잡함(서비스 속도가 느려지는 등의 문제 : 시스템 복원, 서버 증설 등으로 대응이 가능)과 비즈니스 로직(멋대로 결제 처리되거나 잔액 삭감이 이뤄지는 문제)을 다루는 코드를 깔끔하게 분리가 가능했다.
정리하자면, 스프링은 특정 기술에 종속되지 않으면서 객체를 관리할 수 있는 컨테이너를 제공하고 결국 코드를 작성하는 입장에서 중요하게 다룰 부분인 비즈니스 로직에만 집중하게 된다. 이것을 효율적으로 다루기 위해 선택한 언어인 자바의 강점, 객체지향성에 따른 유연함과 재사용성이 발휘되는 것이다.
2) 스프링의 도구 : 객체지향, IoC/DI
사실 AOP와 PSA, 그리고 그것들을 아우르는 POJO도 있지만 걔네는 다음 포스팅에서 정리할 예정.
(1) 객체지향
자바를 공부할 때도 많이 접했고 직접 자바 문법을 활용하면서 어느 정도 체감했던 객체지향은 간략하게 특징만 정리해보면...
캡슐화
- 필드의 데이터 고유성을 유지하려는 정보 은닉을 구현할 수 있다.
- 사용자 입장에서는
public과 관련된 내용만 알면 된다.추상화
- 존재하는 모든 자동차 종류를 각각 클래스 객체화하는 것은 비효율적이다.
- 바퀴는 굴러가고, 차문을 열리고, 핸들은 돌려지는, 그저 필요에 의한 행위(메서드)가 존재한다.
- 객체들은 실제 그 모습이지만, 클래스는 객체들이 어떤 특징들이 있어야 한다고 정의하는 추상화된 개념, 즉 객체의 공통적인 특징들을 추상적으로 모아뒀다고 할 수 있겠다. 자바에서는 인터페이스와 추상 클래스를 통해 설계할 수 있다.
다형성
- 동일한 행위를 바탕으로 다양한 결과를 도출하게 된다.
- 기능의 확장을 꾀함으로써 중복된 코드 작성을 방지할 수 있다.
- 메서드의 오버로딩 및 오버라이딩, 혹은 클래스의 상속, 람다식이 대표적인 예시다.
재사용성
- 사실 이건 위의 다형성과도 좀 겹치는 것 같은데...
- 왜냐하면 상속을 통해 코드의 중복을 방지하면서 기존 기능(부모 클래스)을 여전히 재사용할 수 있기 때문이다.
(2) 도구의 필요성
예를 들어서, 프레임워크를 사용하지 않는 일반적인 프로그램에서의 객체 라이프사이클을 생각해보자. 아래는 단순한 예시 코드다.
// None Framework Client
public class ClientWithNoFramework {
public static void main(String[] args) {
// 생성
Board board = new Board(seq, content);
// 기능 호출...
board.submit();
}
}// Board Class
public class Board {
private long seq;
private String content;
public Board(long seq, String content) {
this.seq = seq;
this.content = content;
}
public void submit() {
//...
}
}위의 코드는 프레임워크를 사용하지 않은 프로그램의 클라이언트를 모식화한 것이다. Board 클래스의 인스턴스 생성 및 메소드 호출은 현재 클라이언트 클래스 내에서 이뤄지고 있다. 간략히 모식하고 있지만 Board 클래스의 핵심 기능들이 오로지 클라이언트에 의해서 이뤄지는 것이다. 위 코드가 왜 문제가 될까?
만약 사용자가
Board클래스에 기능 추가를 요구한다면...?
단순하게 Board 클래스에 메소드를 추가하는 것으로는 해결이 안 된다. 왜냐하면 해당 인스턴스의 생명주기는 별도의 클라이언트 클래스에 강하게 의존되고 있기 때문이다. 즉, ClientWithNoFramework 클래스 역시 추가로 수정이 이뤄져야 한다. 이는 좋은 설계가 아니다. 코드의 유지보수를 어렵게 만들고 기능의 확장성을 저해한다.
(3) 제어 역전(IoC)
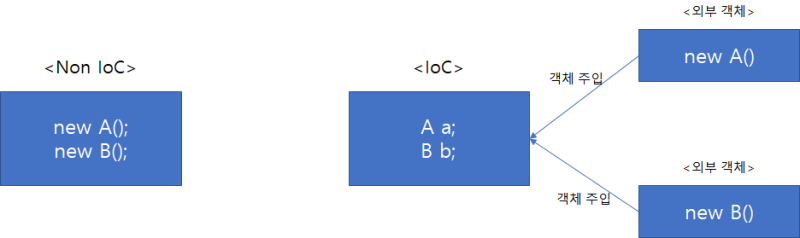
위의 상황을 극복할 수 있도록 스프링은 클라이언트가 객체를 직접 객체를 제어하지 않고 IoC 컨테이너에게 제어권을 양도할 수 있게 하고, 이것이 스프링 컨테이너에 해당한다. 스프링 빈은 제어 역전이 적용되어 제어권을 스프링에게 넘겨줬기 때문에 Spring IoC에 의해 관리되는 객체애 해당하지만, 스프링 빈이나 스프링 컨테이너 역시 다룰 내용이 많으므로 이번 포스팅에서는 다루지 않는다.
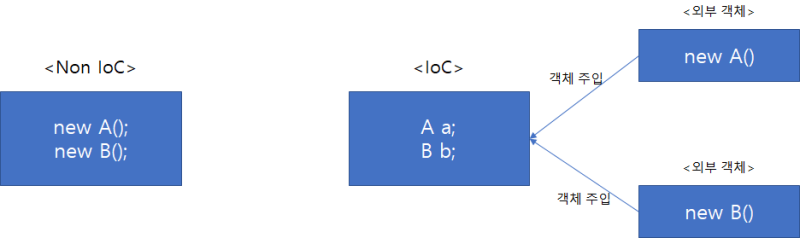
제어 역전은 Inversion of Control의 약자이며, 코드의 흐름을 주체할 수 있는 제어권이 넘어가는 것을 의미한다. 핵심은 객체가 자신이 사용할 객체를 스스로 선택하지 않고, 타 객체에게 넘겨줘서 자신이 사용하는 객체에 대하여 컨트롤하지 않는다는 점이다. (사실 뭔 말인지 여전히 뜬구름 잡는 표현이다.)
조금 더 천천히 이해하자면... 사용하는 객체의 흐름은 자신이 관여하지 않는다 -> 즉, 흘러가는 객체를 그저 사용만 하고 놔둔다 -> 이로 인해 사용의 관점에서는 신경쓸 몫이 줄어든다... 라는 흐름이 되는듯?
// 어노테이션을 통해 IoC 컨테이너가 제어권 획득
@Controller
public class ExampleController {
// ...
@GetMapping("/")
public String getView(Board board) {
// ...
}
}스프링 프레임워크에서는 어노테이션을 기반으로 IoC 컨테이너에게 제어를 양도할 수 있게 된다. 아래 그림을 확인해보자.
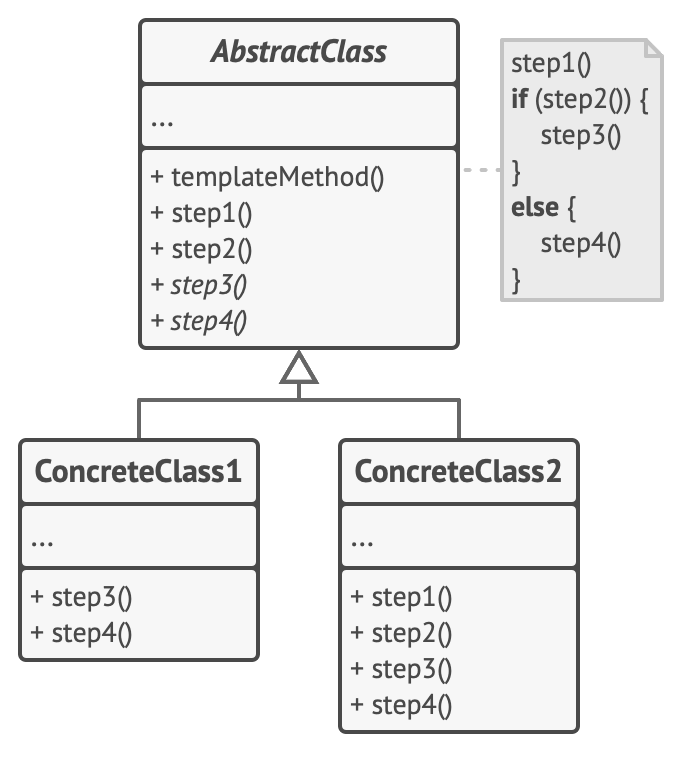
IoC를 구현할 수 있는 대표적인 방법에는 템플릿 메소드 패턴이 존재한다. 처음 봤을 때, 띠용... 하는 단어였지만 나는 이미 자바를 공부하면서 해당 패턴을 적극 활용하고 있었다. 추상 클래스나 인터페이스의 추상 메소드를 구현체에서 구체화하는 과정에서 해당 추상 메소드들을 하나로 묶어 단계화하는 작업이 대표적인 예시였다.
왜 저것이 IoC의 예시냐면, 분명 stepN() 메소드들의 구체적인 로직은 구현체에서 구체화됐음에도 불구하고 해당 메소드가 호출되는 시점(생명 부여)은 상위 클래스의 templateMethod()에 의해 결정된다. 즉, 제어의 역전이 발생했다. 예시 코드로 다시 이해해보자.
// 추상 클래스 Farming
public abstract class Farming {
public void farm() {
seed();
water();
fertilize();
harvest();
}
public abstract void seed();
public void water() {
System.out.println("물 주기.");
}
public void fertilize() {
System.out.println("비료 뿌리기.");
}
public abstract void harvest();
}Farming 클래스에는 농사의 일련 과정을 나타내는 템플릿 메소드인 farm()과 각각의 단계 알고리즘을 나타내는 인스턴스 메소드 water()와 fertilize() 메소드, 그리고 추상 메소드인 seed() 메소드와 harvest() 메소드가 있다.
// 구현체 Fruit
public FruitFarming extends Farming {
@Override
public void seed() {
System.out.println("과일 씨 뿌리기.");
}
@Override
public void harvest() {
System.out.println("과일 수확하기.");
}
}
// 구현체 Vegetable
public VegetableFarming extends Farming {
@Override
public void seed() {
System.out.println("채소 씨 뿌리기.");
}
@Override
public void harvest() {
System.out.println("채소 수확하기.");
}
}추상 클래스를 상속받아서 구체화하는 FruitFarming 클래스와 VegetableFarming 클래스에서는 추상 메소드인 seed(), harvest()를 오버라이딩하면서 구현하고 있다. 로직의 구현은 하위 클래스 FruitFarming, VegetableFarming에서 이뤄졌지만, 결국 저것을 호출하는 제어의 핵심은 상위 클래스인 Farming이 보유하고 있다.
스프링에서는 IoC 컨테이너를 통해 객체의 흐름을 제어하고, 개발자는 객체의 제어권을 IoC 컨테이너에 양도함으로써 프로그램의 흐름을 고려할 필요없이 구현로직에만 집중할 수 있게 되는 것이다.
마지막 예시 정리!
// IoC의 적용 없이, UserDao 클래스가 직접 ConnectionMaker 인스턴스 생성
class UserDao {
private ConnectionMaker connectionMaker;
public UserDao(){
connectionMaker = new ConnectionMaker();
}
}// IoC의 적용, UserDao 클래스 외부에서 생성된 ConnectionMaker 인스턴스 주입받음
class UserDao {
private final ConnectionMaker connectionMaker;
public UserDao(ConnectionMaker connectionMaker){
connectionMaker = this.connectionMaker;
}
}(4) 의존성 주입(DI)
Dependency Injection의 약자에 해당하며, IoC를 구현할 수 있는 대표적인 방법 중 하나다. 바로 위에서 마지막 예시로 정리한 이유가, IoC 적용 예시 코드가 바로 생성자 주입 방식을 구현한 것이어서 뇌절과 보완 정리의 느낌으로 추가했다.
사실 의존성 주입이라는 키워드를 처음 봤을 때는 이해가 잘 안 됐다. 왜냐하면 분명 의존성 주입? 그럼 의존성 양이 많아지네? 그럼 의존이 강화되는 거 아냐? 근데 약해진다고? 무한 츠쿠요미.. 라는 함정 아닌 함정에 빠져서 혼란스러워했다.
얘도 다시 천천히 정리해보면... 의존성이란 한 객체가 다른 객체를 사용할 때 의존성이 있다고 의미한다. 위의 예시에서는 UserDao 객체가 ConnectionMaker 객체를 사용하고 있음으로써 UserDao 객체가 ConnectionMaker 객체에 의존성이 있다라고 표현할 수 있다.
이 과정에서 의존성을 주입한다는 것은, 누가 주입하고 왜 주입하게 되는 것일까? 위의 예시 대신 아까 작성했던 Farming 클래스 관련 예시로 다시 정리를 해보자.
농부가 농사를 한다라고 생각을 해본다.
// Farming 클래스를 사용하는 Farmer 클래스
public class Farmer {
// 다형성 구현
private Farming farming = new FruitFarming();
public void farmCrops() {
farming.farm();
}
}
// Main 클래스
public class Main {
public static void main(String[] args) {
Farmer farmer = new Farmer();
try {
farmer.farmCrops();
} catch (Exception e) {
e.printStackTrace();
}
}
}위의 코드대로라면 Main 클래스의 메인 메소드가 실행될 때, 정상적으로 농부는 과일을 농사짓게 된다. 근데, 농작물이 다양(?)해지면서 새로운 내용이 추가되었다고 가정해보자.
// 구현체 Fruit
public FruitFarming extends Farming {
// ** 생성자와 필드 추가 ** //
private String fruit;
public FruitFarming(String fruit) {
this.fruit = fruit;
}
// ** 생성자와 필드 추가 ** //
@Override
public void seed() {
System.out.println(fruit + " 씨 뿌리기.");
}
@Override
public void harvest() {
System.out.println(fruit + " 수확하기.");
}
}농부는 농작물의 다양성을 꾀하기 위해서 생성자와 필드를 추가하고 다양한 과일을 재배하려고 코드를 수정했다. 이걸로 끝일까? FruitFarming을 직접 생성해서 다루는 Farmer 클래스 역시 수정해야 된다. 어라? 아까 본 상황이다...? 이런 상황을 방지하기 위해서 어떻게 극복해야 할까.
Farmer 코드를 아래처럼 바꿔본다.
// Farming 클래스를 사용하는 Farmer 클래스
public class Farmer {
// 다형성 구현 + 직접 생성 x
private Farming farming;
public Farmer(Farming farming) {
this.farming = farming;
}
public void farmCrops() {
farming.farm();
}
}
// Main 클래스
public class Main {
public static void main(String[] args) {
// 기존의 Farmer 클래스에서의 FruitFarming 생성을
// 외부 별개의 클래스, 메소드에서 수행한다.
Farming farming = new FruitFarming("사과");
Farmer farmer = new Farmer(farming);
try {
farmer.farmCrops();
} catch (Exception e) {
e.printStackTrace();
}
}
}여전히 Farmer 클래스는 Farming 클래스를 사용하면서 의존하고 있다. 그런데 FruitFarming 클래스를 수정(생성자, 필드 추가)하더라도 Farmer 클래스에서 건드릴 내용은 없다. 즉, 의존성이 약화됐다! 더군다나 메인 메소드에서 다양한 생성자의 매개값(String)을 제공함으로써 쉬운 다형성 구현까지 기대할 수 있다.
위의 Farmer 코드에서는 외부(메인 메소드)에서 생성된 Farming 객체를 생성자를 통해 주입받으면서 의존 관계를 약화시키고 유지보수성의 능률을 높였다. 이것이 의존성 주입의 예시다.
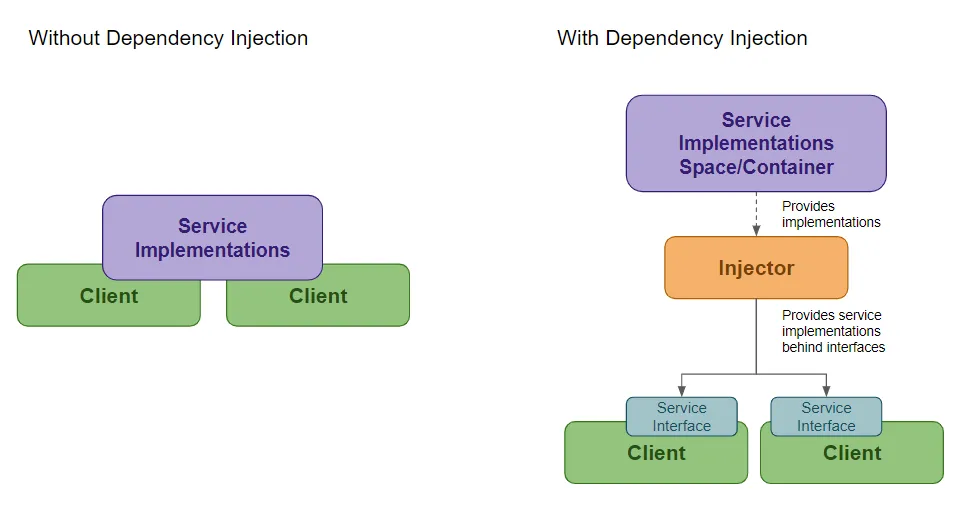
Farmer 클래스가 클라이언트, Farming이 서비스 인터페이스 혹은 추상 클래스, FruitFarming이 서비스의 구현체라고 생각하면 되겠다.
의존성 주입의 방법에는 생성자 주입, 필드 주입, 세터 주입이 있다. 스프링 4 이상에서는 생성자 주입을 권장하고 있으며 위에 내가 작성한 예시 코드도 역시 생성자 주입이 적용된 예시다.
생성자 주입
public class Farmer {
private Farming farming;
// 생성자 주입
public Farmer(Farming farming) {
this.farming = farming;
}
public void farmCrops() {
farming.farm();
}
}스프링에서의 생성자 주입은 최초 빈(Bean) 1회의 호출을 보장하며, 후술할 다른 방식과 달리 필드 사용이 가능하다. 또한, 컴파일 시점에서 순환참조를 체크하기 때문에 에러의 초기 발견이 가능하다.
@Controller
public class ExampleController {
private final ExampleService ExampleService;
@AutoWired
public ExampleController(xampleService ExampleService) {
this.exampleService = exampleservice;
}
// ...
}@Controller 어노테이션을 붙이면 스프링의 IoC 컨테이너 관리 객체인 Bean으로 등록되고 이 때, 자동으로 의존성 주입이 일어난다. @AutoWired 어노테이션을 붙여서 의존성 주입을 명시화할 수 있으며, 만약 단일 생성자라면 @AutoWired 어노테이션이 없어도 자동으로 의존성이 주입된다.
만약 생성자가 여러 개인데, @AutoWired 어노테이션이 없으면 매개변수가 가장 많은 생성자에 의존성을 주입한다.
필드 주입
@Controller
public class ExampleController {
@AutoWired
private final ExampleService ExampleService;
// ...
}필드에 @Autowired 어노테이션을 붙여 의존성을 주입할 수 있는 방식이다. 가장 단순하고 쉽지만 스프링에서 가장 권장하지 않는 방식이다. 심지어 인텔리제이에서도 너 이거 맞아? 하는 식으로 경고를 날리기도 한다.
이유는 필드 주입의 경우 외부에서 접근이 불가능해지며 DI 프레임워크나 리플렉션 없이는 필드값을 주입해 줄 방법이 없다는 것을 의미한다. 즉, 프레임워크에 강하게 종속적인 객체가 된다. 또, 순환참조의 문제가 발생할 수 있다.
@Component
public class Parent {
@Autowired
private Child child;
public void nurtureChild() {
child.becomeParent();
}
}
@Component
public class Child {
@Autowired
private Parent parent;
public void becomeParent() {
parent.nutureChild();
}
}조금 극단적인 예시긴 한데, 좋은 예제가 있어서 참조했다. 위의 Parent 클래스와 Child 클래스는 서로를 참조하면서 컴파일 시점에서는 문제가 없지만, 런타임 시점에서 상호 메소드를 호출하게 되면 무한한 순환참조를 일으키면서 오버스택플로우가 발생하게 된다.
세터 주입
public class Farmer {
private Farming farming;
// 세터 주입
public void setFarming(Farming farming) {
this.farming = farming;
}
public void farmCrops() {
farming.farm();
}
}자바빈 패턴으로 세터를 통해 의존성을 주입할 수도 있다. 사실 얘 역시 순환참조의 문제가 발생할 수 있지만, 의존성 수정이 가능해서 런타임 시점에서의 의존성 수정이 필요한 경우에 사용할 수 있다.
@Controller
public class ExampleController {
private ExampleService exampleService;
@Autowired
public void setExampleService(ExampleService exampleservice) {
this.exampleService = exampleservice;
}
// ...
}세터 주입은 Setter 메소드에 @Autowired 어노테이션을 붙여 의존성을 주입할 수 있다.
