6. 챌린지 프로젝트(4)
대용량 트래픽을 관리해야 되는 프로젝트에서 마주해야 될 중요 이슈는 바로 동시성 제어였다. 간단하게 말해서, 50개의 쿠폰이 주어진 상황에서 100명이 동시에 쿠폰을 발급받으려고 할 때, 순서와 결과를 보장해야 한다는 이슈에 대한 대응책이다.
자바에서 일컫는 스레드는 cpu 작업의 한단위이다. 여기서 멀티 스레드 방식은 멀티태스킹을 하는 방식 중, 한 코어에서 여러 스레드를 이용해서 번갈아 작업을 처리하는 방식이다. 멀티 스레드를 이용하면 공유하는 영역이 많아 멀티 프로세스 방식보다 context switcing(작업전환) 오버헤드가 작아, 메모리 리소스가 상대적으로 적다는 장점이 있다.
하지만 자원을 공유해서 단점도 존재한다. 그게 바로 동시성(concurrency) 이슈다. 여러 스레드가 동시에 하나의 자원을 공유하고 있기 때문에 같은 자원을 두고 경쟁상태(raceCondition) 문제가 발생하는 것이다.
여담으로 멀티 스레드에서의 동시성이라는 것은, 동시에 작동하는 것이 아닌 동시에 작동하는 것처럼 보이게 하려고 스레드가 번갈아가면서 실행하는 것을 말한다. 반대로 병렬성이라는 개념이 실제로 동시에 실행되는 것을 말한다.
이런 동시성을 제어하는 것이 중요한 이유는 트랜잭션 처리의 순서를 보장해서 데이터베이스 상에서의 표시와 실제 예상하는 표시의 괴리를 없애기 위함이다. 동시성을 제어할 수 있는 방법으로 나는 서버 사이드의 코드 단위에서 해결하는 것과 redis를 사용하는 것으로 나눠서 생각했다.
0) 트랜잭션과 데이터 정합성
예를 들어서, 데이터베이스에 A, B, C 세 개의 테이블이 존재한다. 만약 세 테이블에 순차적으로 INSERT를 수행한다고 가정할 때, A와 B 테이블에는 정상적으로 INSERT 됐으나, C에는 INSERT가 정상적으로 이뤄지지 않으면 데이터의 정합성이 깨지게 된다.
이를 대비하기 위해서 데이터베이스는 All or Nothing 전략을 수행한다. 즉, 하나의 테이블이라도 작업이 완료되지 않으면 전부를 수행하지 못한 결과로 취급하게 된다. 트랜잭션의 정의는 나눠지지 않는 단위인데, 여기서 A와 B의 처리를 롤백하게 됨으로써 All or Nothing 전략을 수행할 수 있게 된다.
트랜잭션은 4가지의 특징을 가지는데, 이를 ACID라고 부른다.
- 원자성(Atomicity)
트랜잭션은 더 이상 분해가 불가능한 업무의 최소단위이므로, 전부 처리되거나 아예 하나도 처리되지 않아야 한다.
- 일관성(Consistency)
일관된 상태의 데이터베이스에서 하나의 트랜잭션을 성공적으로 완료하고 나면 그 데이터베이스는 여전히 일관된 상태여야 한다. 즉, 트랜잭션 실행의 결과로 데이터베이스 상태가 모순되지 않아야 한다.
- 격리성(Isolation)
실행 중인 트랜잭션의 중간결과를 다른 트랜잭션이 접근할 수 없다.
- 영속성(Durability)
트랜잭션이 일단 그 실행을 성공적으로 완료하면 그 결과는 데이터베이스에 영속적으로 저장된다.
(1) 트랜잭션의 격리성으로 인해 생기는 문제
트랜잭션의 실행 도중의 결과, 즉 중간결과의 상황에 따라 다양한 문제가 발생할 수 있다. 대표적인 것들을 꼽자면...
Dirty Read
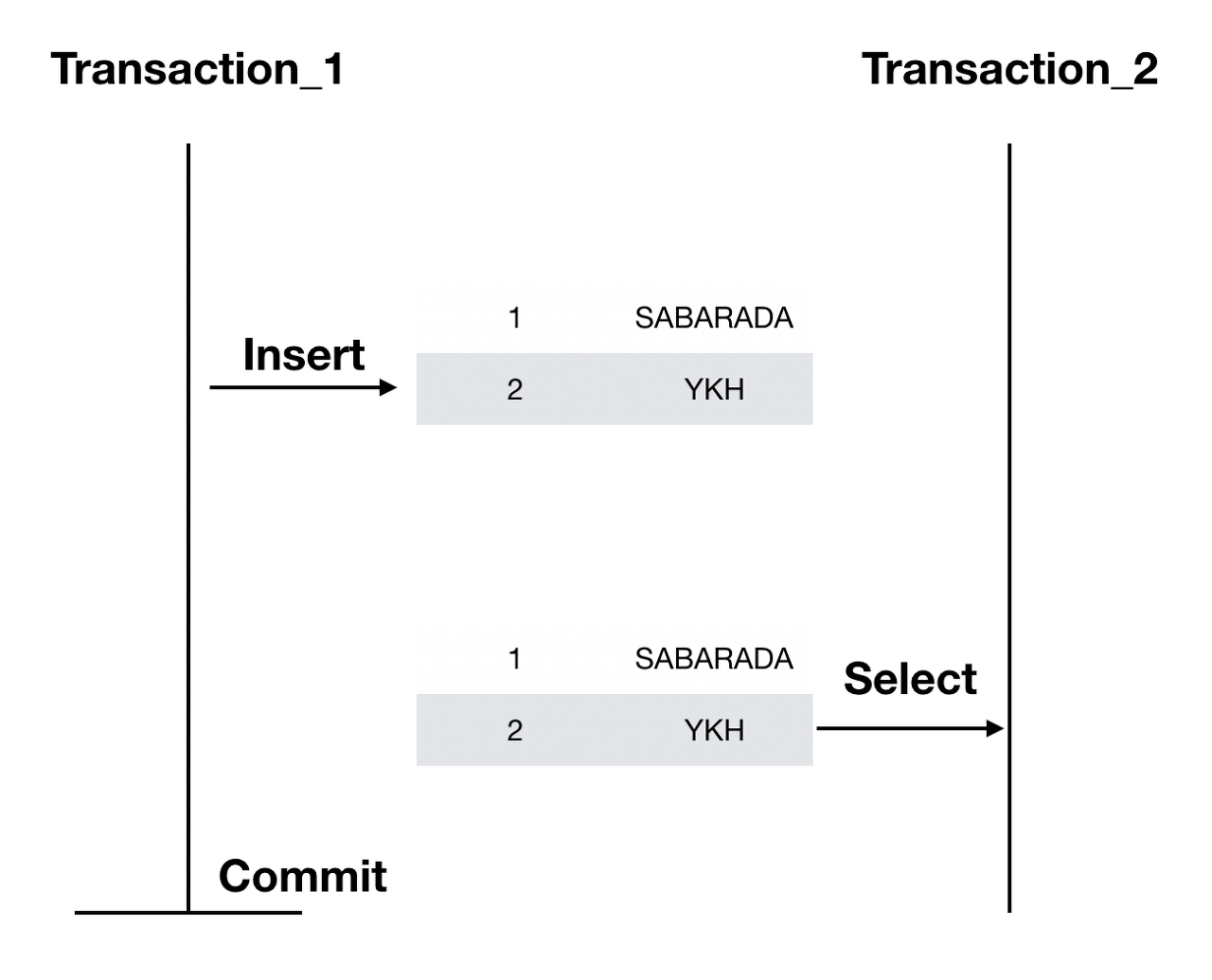
Dirty Read는 다른 트랜잭션에 의해 수정됐지만 아직 커밋되지 않은 데이터를 읽는 것이다. 예를 들어서 커밋되지 않고 롤백되기 직전의 데이터를 다른 트랜잭션이 활용하고, 해당 트랜잭션이 롤백되면 데이터 정합성이 깨지게 된다.
Non-Repeatable Read
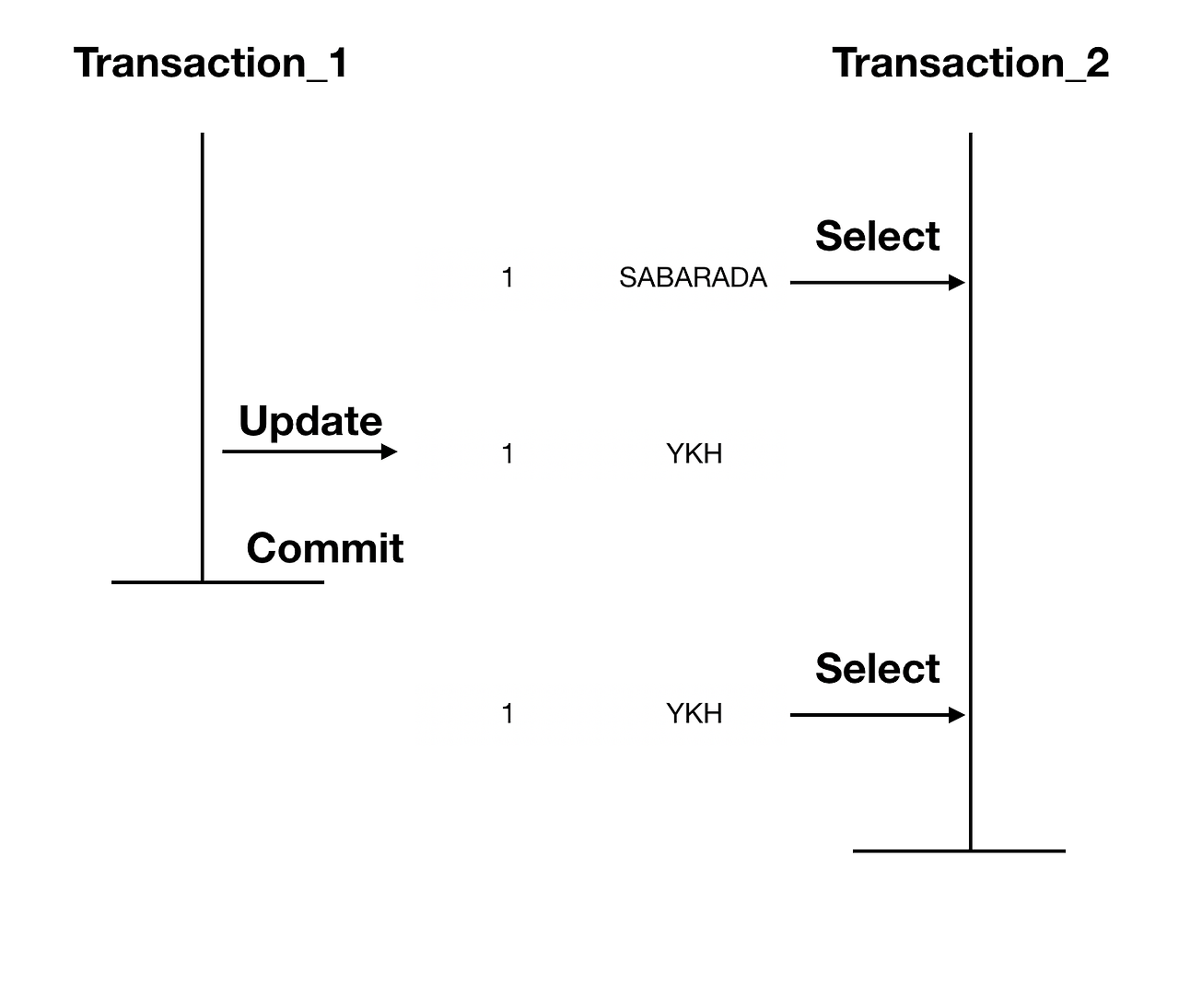
Non-Repeatable Read는 한 트랜잭션 내에서 같은 Key를 가진 Row를 두 번 읽었는데 그 사이에 값이 변경되거나 삭제되어 결과가 다르게 나타나는 현상을 말한다. 이로 인해서 동일한 Key에 대해서 두 트랜잭션이 다른 결과를 내게 된다.
Phantom Read
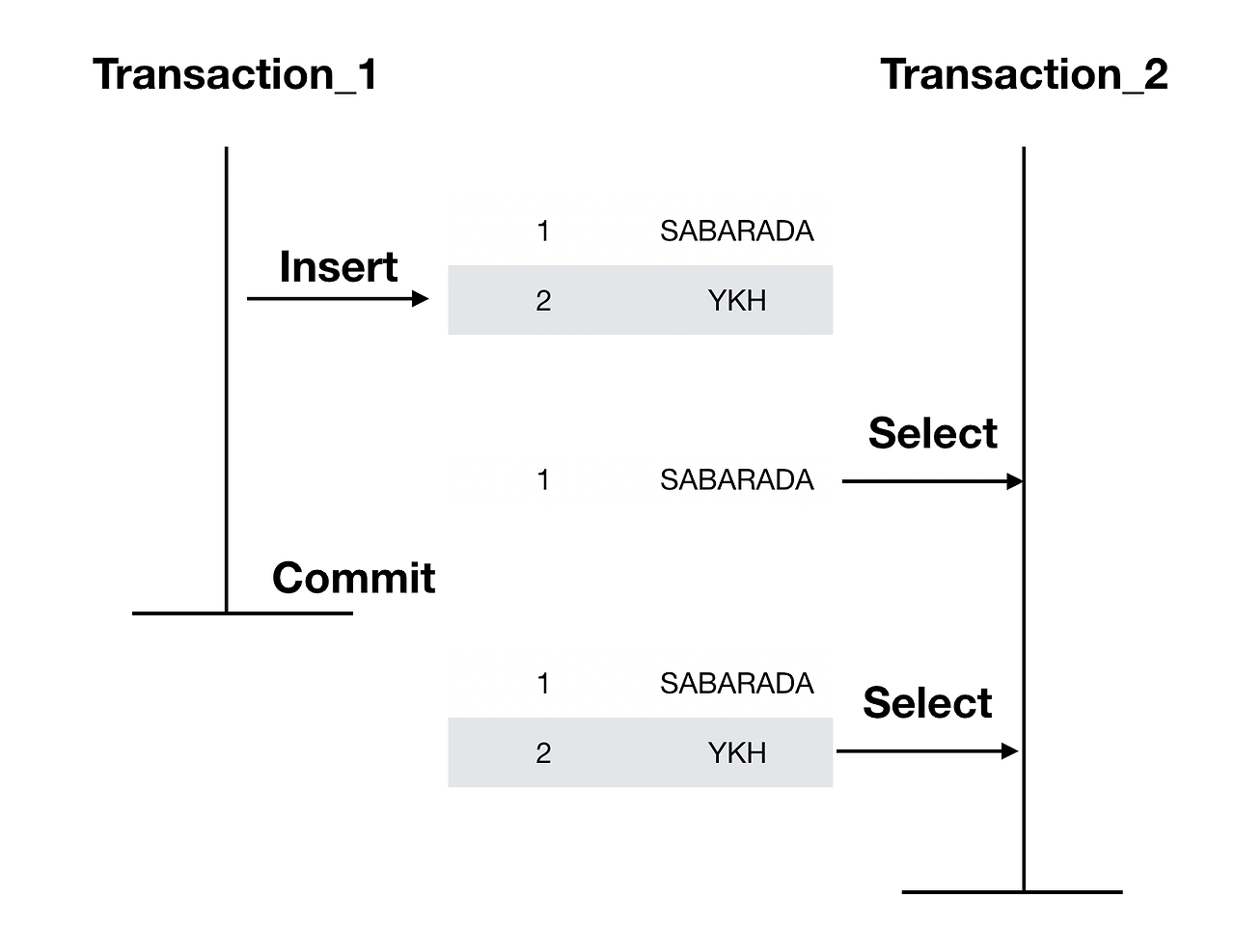
Phantom Read는 하나의 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 첫 번째 쿼리에서 없던 유령(Phantom) 레코드가 두 번째 쿼리에서 나타나는 현상을 말한다. Non-Reaptable Read와의 차이점은, Non-Repeatable Read는 1개의 Row의 데이터의 값이 변경되는 것이며 Phanton Read는 여러 건을 요청하는 것에 대해서 데이터의 값이 변경되는 것이다.
(2) 트랜잭션의 격리성 레벨
DB의 정합성과 관련된 개념인 격리성은 실행 중인 트랜잭션의 중간결과에 다른 트랜잭션이 간섭할 수 없지만, 무조건적인 것은 아니고 접근 레벨을 달리 설정할 수 있다. 아래의 격리성 레벨은 ANSI/ISO SQL 표준(SQL92)에서 정의한 내용이다.
- Read Uncommitted
트랜잭션에서 처리 중인 아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽는 것을 허용한다. 해당 수준에서는 Dirty Read, Non-Repeatable Read, Phantom Read가 일어날 수 있으며 정합성에 문제가 있기 때문에 권장하는 설정은 아니다.
- Read Committed
트랜잭션이 커밋되어 확정된 데이터만 다른 트랜잭션이 읽도록 허용한다. 커밋 되지 않은 데이터에 대해서는 실제 DB 데이터가 아닌 Undo 로그에 있는 이전 데이터를 가져오는 것이라서 Dirty Read의 발생가능성을 막지만, Non-Repeatable Read와 Phanton Read에 대해서는 발생 가능성이 있습니다.
- Repeatable Read
트랜잭션 내에서 삭제, 변경에 대해서 Undo 로그에 넣어두고 앞서 발생한 트랜잭션에 대해서는 실제 데이터가 아닌 Undo 로그에 있는 백업 데이터를 읽게 함으로써 트랜잭션 중 값의 변경에 대해서 일정한 값으로 처리하게 한다. 이로써 삭제와 수정에 대해서 트랜잭션 내에서 불일치를 가져오던 Non-Reapeatable Read를 해소하게 된다.
- Serializable Read
트랜잭션 내에서 쿼리를 두 번 이상 수행할 때, 첫 번째 쿼리에 있던 레코드가 사라지거나 값이 바뀌지 않음은 물론 새로운 레코드가 나타나지도 않도록 하는 설정이다.
1) 객체 단위에서의 라킹(Locking)
현재 진행하는 프로젝트가 스프링 JPA를 기반으로 한 프로젝트여서 트랜잭션 관리가 중요한 주제 중 하나다. 동시성 이슈가 발생하는 것도 결국 객체 공유가 발생하면서 스레드의 처리 이전에 다른 스레드가 갱신 이전의 작업을 가져가기 때문에 그러하다.
그래서 synchronized 키워드를 기반으로 객체 잠금을 수행해서 작업이 진행되는 동안 다른 스레드가 작업을 가져가지 못하게 하면 되겠지만, 트랜잭션의 작업 단위는 객체 메소드의 작업 단위를 포괄해서 가져간다.
// transaction start
startTransaction()
public synchronized void method() {
// ...
}
// transaction end(commit!)
endTransaction()즉, 만약 서버가 1대, 즉 프로세스가 단일이라면 문제가 되지 않지만 통상의 프로젝트는 복수의 서버가 기반이고 이때의 데이터 관리를 위해서 트랜잭션 관리는 불가피하므로, 단일 프로세스에서의 객체 단위 잠금이 이뤄지는 synchronized 키워드를 덧붙여도 결국 트랜잭션의 관리는 불가능하므로 근본적인 해결책이 안 된다.
2) 서버 사이드에서의 라킹(Locking)
(1) 비관적 락
비관적 락은 현재 트랜잭션에서 변경하고자 하는 레코드에 대해 잠금을 먼저 획득하고 변경 작업을 처리하는 방식으로, Repeatable Read 또는 Serializable 정도의 격리성 수준을 제공한다. 비관적 락에는 공유 락과 배타 락이라는 두 개념이 등장한다.
- 공유 락 (Shared Lock)
Read Lock(읽기 락)이라고도 불리는 공유 락은 트랜잭션이 읽기를 할 때 사용하는 락이며, 데이터를 읽기만하기 때문에 같은 공유 락끼리는 동시에 접근이 가능하지만, write 작업은 막는다.
- 배타 락 (Exclusive Lock)
Write Lock(쓰기 락)이라고도 불리며, 데이터를 변경할 때 사용하는 락이다. 트랜잭션이 완료될 때까지 유지되며, 배타 락이 끝나기 전까지 read/write를 모두 막는다.
Shared Lock을 걸게 되면 write를 하기 위해서는 Exclucive Lock을 얻어야하는데 Shared Lock이 다른 트랜잭션에 의해서 걸려 있으면 해당 Lock을 얻지 못해서 업데이트를 할 수 없고, 수정을 하기 위해서는 해당 트랜잭션을 제외한 모든 트랜잭션이 종료(commit)되어야 한다.
현재 프로젝트에서는 개념적인 비교를 통해 비관적 락과 redisson 기반 분산 락을 고려 중이라서, 구현된 비관적 락을 바탕으로 개념을 정리해보면...
@Transactional
public void registrationSubjectByPessimisticLock(Long subjectId, Long studentId) {
Student student = studentRepository.findById(studentId)
.orElseThrow(() -> new IllegalArgumentException("유효하지 않은 회원 정보입니다."));
// 비관적 락 적용
Subject subject = subjectRepository.findByIdForPessimistic(subjectId)
.orElseThrow(() -> new IllegalArgumentException("신청하려는 강의가 존재하지 않습니다."));
// 장바구니 목록에서 해당하는 데이터 찾기
RegisteredSubject registeredSubject =
registeredSubjectRepository.findByStudentIdAndSubjectId(studentId, subjectId)
.orElseThrow(() -> new IllegalArgumentException("신청하려는 강의가 장바구니에 존재하지 않거나, 유효한 회원이 아닙니다."));
// 수강 신청이 이미 완료되었는지 확인
if (registeredSubject.isRegistered()) {
throw new IllegalArgumentException("이미 수강신청이 완료된 과목입니다.");
}
// 수강 신청 가능한 학점을 초과하는지 확인한다.
Integer subjectCredit = subject.getCredit();
if (student.getCurrentCredit() + subjectCredit > GlobalVariables.MAX_CREDIT) {
throw new IllegalArgumentException("신청 가능한 학점을 초과 하였습니다.");
}
// 과목의 수강 가능 여부 확인
if (subject.getLimitCount() <= 0) {
throw new IllegalArgumentException("수강 인원이 다 찼습니다.");
}
boolean updated = subject.cutCount();
if (!updated) {
throw new IllegalStateException("Unable to register due to limit count.");
}
// 수강 신청 성공 시, 상태값 true로 변경 & 학생 학점 갱신
registeredSubject.changeRegisterStatus(); // 상태값
}사실 그 당시에는 고민해도 보이지 않던 부분인데, 왜 많은 dao 메소드들 중에서 과목 조회 메소드에 대하여 락을 걸어야 하는지를 자체적인 코드 리뷰를 통해서 나름의 사고 결론을 내봤다.
- 자바의 작업 단위인 스레드가 특정 학생의 수강신청을 맡는다.
- 수강신청 서비스 비즈니스 로직은 여러 dao의 메소드를 참조해서 구성된다.
- 특정 학생의 정보를 가져오는 것(
studentRepository.findById(studentId))은 단위 스레드 당 단위 작업이므로 여러 스레드들의 충돌이 일어날 이유가 없다.- 또한, 특정 학생의 장바구니 정보에서 담겨있는 특정 과목의 신청 처리를 업데이트하는 것(
registeredSubject.changeRegisterStatus())도 단위 스레드 당 단위 작업이므로 여러 스레드들의 충돌이 일어날 이유가 없다.- 반면, 과목 정보를 조회하는 것(
subjectRepository.findByIdForPessimistic(subjectId))은 모든 스레드들이 테이블에서 똑같은 과목 정보를 조회해야 되는데, 여기서 순서가 결정되므로 여러 스레드들의 충돌이 발생(중첩 조회)하게 된다. 그렇기 때문에 특정 과목 조회에 대해서 락을 걸어야 한다.
비관적 락은 충돌 발생을 미연에 방지하고 데이터의 일관성을 유지할 수 있으나, 동시 처리에 대한 성능 저하 및 교착상태(Deadlock) 발생 가능성이 있다.
(2) 낙관적 락
데이터 수정 시, 버전 정보를 이용하여 다른 트랜잭션에 의해 데이터가 변경되지 않았는지 확인하는 방식
데이터의 read와 write 시점에서 지속적으로 버전 확인을 위한 작업을 수행하게 돼서 서버에 부하를 가하게 됨
리소스 경쟁이 적고 락으로 인한 성능저하가 적지만, 충돌 발생 시 처리해야 할 외부 요인이 존재한다.
(3) 네임드 락
이름을 지닌 잠금을 획득하고 작업을 처리할 때까지 다른 트랜잭션이 잠금을 획득하지 못하게 함
네임드 락은 분산 락과 타임아웃 구현아 가능하나 세션 관리가 중요하고 트랜잭션이 자동으로 해제해주지 않기 때문에 별도의 명령어 구현 등의 로직의 복잡성이 증대
3) redis 기반 라킹(Locking)
(1) lettuce
spring data redis 를 이용하면 lettuce 가 기본으로 제공되기 때문에 별도의 라이브러리를 사용하지 않아도 되며, 구현이 간편
스핀 락 방식이기 때문에 동시에 많은 스레드가 잠금 획득 대기 상태로 진입하면 redis에 부하가 갈 수 있음
Lettuce는 공식적으로 분산락 기능을 제공하지 않는다. 따라서 직접 구현해서 사용해야 한다.
Lettuce의 락 획득 방식은 락을 획득하지 못한 경우 락을 획득하기 위해 Redis에 계속해서 요청을 보내는 스핀 락(spin lock)으로 구성되어 있다. 이 스핀 락 방식은 계속해서 요청을 보내는 방식으로 인해 redis에 부하가 생길 수 있다는 단점이 있다.
(2) reddison
pub-sub 방식으로 구현이 되어있기 때문에 lettuce 와 비교했을 때 redis 에 부하가 덜 감
별도의 라이브러리 세팅이 필요하며, 러닝 커브가 높은 축에 속함
Redisson은 락 획득 시 스핀 락 방식이 아닌 pub/sub 방식을 이용한다.
pub/sub 방식은 락이 해제될 때마다 subscribe중인 클라이언트에게 "이제 락 획득을 시도해도 된다."라는 알림을 보내기 때문에, 클라이언트에서 락 획득을 실패했을 때, redis에 지속적으로 락 획득 요청을 보내는 과정이 사라지고, 이에 따라 부하가 발생하지 않게 된다.
또한 Redisson은 RLock이라는 락을 위한 인터페이스를 제공한다. 이 인터페이스를 이용하여 비교적 손쉽게 락을 사용할 수 있다.
현재 프로젝트에서 구현한 redisson facade 패턴을 기반으로 한 분산 락 클래스는 다음과 같다.
@Slf4j
@Component
@AllArgsConstructor
public class RedissonLockFacade {
private RedissonClient redissonClient;
private RegisteredSubjectService registeredSubjectService;
public void registerSubject(Long subjectId, Long studentId) {
RLock lock = redissonClient.getLock(subjectId.toString());
try {
boolean available = lock.tryLock(10, 1, TimeUnit.SECONDS);
if (!available) {
log.error("학생 {}의 해당 {} 과목에 대한 잠금 획득 실패", studentId, subjectId);
return;
}
log.info("학생 {}의 해당 {} 과목에 대한 잠금 획득 성공", studentId, subjectId);
registeredSubjectService.registrationSubject(subjectId, studentId);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
log.info("학생 {}의 해당 {} 과목에 대한 잠금 해제", studentId, subjectId);
}
}
}Redisson의 RLock 객체를 사용하여 과목에 대한 잠금을 관리하게 된다. tryLock 메소드를 통해 과목에 대한 잠금을 최대 10초 동안 시도하며, 1초 간격으로 잠금을 시도하고 만약 잠금을 성공적으로 획득하면 true를 반환하지만 그렇지 않으면 false를 반환하게 된다.
