2. 해시
해시 테이블 혹은 해시 맵은 키를 값에 매핑할 수 있는, 연관 배열 추상 자료형(ADT)을 구현하는 자료구조다. 해시 맵과 해시 테이블을 같이 언급한 이유는 둘을 자료구조에서는 혼용하지만 자바에서 둘은 다른 기능을 가지는 Map 인터페이스 구현체이기 때문이다. 여기서는 파이썬을 기반으로 공부하므로 두 용어를 혼용하면서 주로 해시 테이블로 언급할 것이다.
1) 해시의 요소
(1) 해시 함수
해시 테이블의 핵심은 임의의 크기를 지니는 데이터를 고정된 크기의 데이터로 매핑하는 작업이다. 아래의 예시를 보자.
'ABC' -> 'A1'
'153BAS' -> 'B5'
'A123AMND21J' -> 'N2'좌변은 임의의 길이를 지닌 문자열이 입력되었음에도 우변은 항상 길이가 2인 문자열로 반환된다. 중요한 점은 항상 길이가 고정된 데이터로 매핑이 되는 점이며, 이 역할을 맡는 화살표에 해당하는 부분이 해시 함수가 맡을 역할이다.
매핑을 무작위의 데이터가 아닌 동일한 크기 범위 내에서 반환을 해야하는 점이 해시 함수의 핵심 로직이다. 많은 방법이 있지만, 우선은 모듈러 연산을 기반으로 한 나눗셈 방식에 대해서 알아보고, 이를 해시 커스터마이징에서 사용할 것이다.
만약 입력되는 데이터가 임의의 정수 타입이라고 생각을 해보자. 이를 동일한 크기(한 자릿수)로 반환을 하는 해시 함수를 고안해야 될 때, 활용할 수 있는 간단한 방법이 나눗셈의 나머지를 활용하는 것이다. 왜냐하면 나머지는 언제나 0부터 제수 - 1까지의 크기를 가질 수밖에 없기 때문이다. 제수를 10으로 고정시키고 나머지를 매핑 값으로 반환하는 해시 함수를 생각해본다.
# 정수형 입력값 -> 나머지
1 % 10 == 1
26 % 10 == 6
59 % 10 == 9
2372817484 % 10 == 4(2) 버킷
해시 테이블의 대표적인 특징이 빠른 검색을 부여한다는 것이다. 빠른 검색이라 함은, 요소를 인덱스로 관리할 수 있다는 점이고 인덱스를 활용하는 대표적인 자료구조는 배열이다.
즉, 정리하자면 데이터를 key-value 형식으로 저장할 때, 해시 함수가 각각의 key 값에 적용되면서 고유한 인덱스값을 도출한다. 그리고 이 인덱스값을 활용해서 사전에 제공된 배열에 저장하고 조회할 수 있게 되는데, 이 배열을 버킷 혹은 슬롯이라고 정의한다.
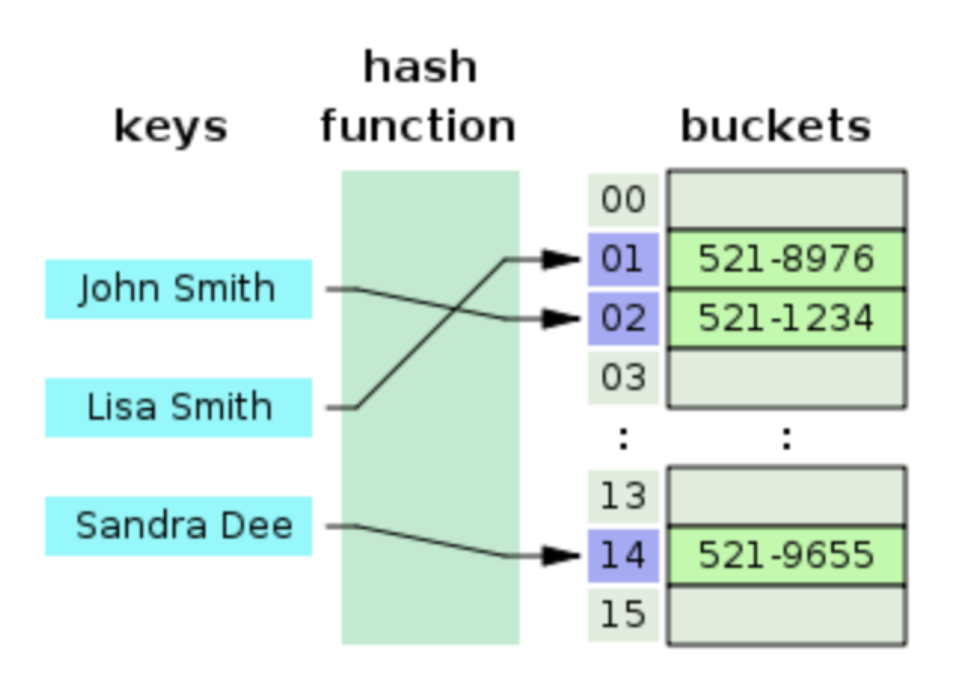
key-value가"John Smith" : "521-1234"인 데이터를, 크기가 16인 해시 테이블에 저장하는 과정
index = hash_function("John Smith") % 16연산을 통해index값을 계산한다.
array[index] = "521-1234"로 전화번호를 저장하게 된다.
(3) 로드 팩터
load_factor = n / k로드 팩터는 해시 테이블에 저장된 데이터 개수 n을 버킷의 개수k로 나눈 값이다. 로드 팩터는 해시 테이블의 재할당 기준 혹은 해시 함수의 재작성 기준이 되며, 해시 함수가 키들을 얼마나 잘 분산시키는 지에 대한 척도가 된다.
(4) 충돌
해시 함수로 매핑을 시킨다고 한들, 결국에는 매핑된 리턴값의 고유함이 훼손되기 마련이다. 매핑 리턴값을 활용해서 역으로 저장된 데이터를 검색하고 조회하게 되는데, 아래의 경우를 보자.
1 % 10 == 1
531 % 10 == 1나눗셈 나머지를 통해 산출된 매핑 리턴값이 동일해지면서 결국 1과 531은 동일한 배열의 인덱스를 가지게 된다. 이 경우, 같은 공간에 두 개의 데이터가 들어가야 되는 충돌이 발생한다.
해시 구조에서는 충돌의 대비책으로 두 가지를 제시하는데, 개별 체이닝(spearate chaining)과 오픈 어드레싱(open addressing)이 있다.
개별 체이닝
동일한 인덱스값을 배정받은 두 입력값을 연결 리스트로 묶어버리는 해결책이다. 위 그림의 예시에는 동일한 인덱스값을 할당받은
John Smith와Sandra Dee가 연결 리스트로 체이닝을 이루고 있다.이 경우, 버킷의 크기에 구애받지 않게 된다. 시간 복잡도는
O(1) : 연결 리스트가 없는 경우에서O(n) : 모든 입력값이 충돌이 발생해서 전부 연결 리스트로 체이닝이 된 경우가 된다. 자바, C++, Go가 이런 형식의 해시 구조를 채택하고 있다.
오픈 어드레싱
충돌이 발생하면 탐사를 통해 빈 공간을 찾아 나선다. 찾은 빈 공간에 충돌이 발생한 나머지 입력값의 저장
value에 인덱스를 할당하게 된다. 이 특성 때문에 오픈 어드레싱은 버킷의 크기를 초과하는 데이터 규모를 할당시킬 수 없다. 버킷의 규모를 초과하게 될 경우, 리해싱 과정을 통해서 또 다른 버킷을 생성하게 된다.오픈 어드레싱의 대표적인 단점은 데이터의 저장 분포가 고르지 못하고 한 곳으로 몰리는, 이른바 클러스터링이 일어나기 쉽다. 이런 클러스터링은 탐사 시간을 크게 소모시키며 종국에는 해시의 효율을 떨어뜨리게 된다. 파이썬, 루비가 이런 형식의 해시 구조를 채택하고 있다.
2) 해시 커스터마이징
앞서 언급했듯이 지금은 파이썬 문법 및 로직을 익히는 것이 아니므로, 파이썬에서 해시 관련 알고리즘 문제가 출제되면 어떤 수단을 통해서 해시 구조를 활용한 풀이를 이끌어낼 수 있는 방법을 찾는 것에 중점을 둘 것이다.
대표적인 파이썬 해시 활용 수단은 Dictionary가 있다. 다만 해시를 커스터마이징 함에 있어서, 개별 체이닝 방식을 채택할 것이고 별도의 Dictionary는 사용하지 않을 것이다.
(1) 해시 커스터마이징 개요
key-value형식으로 저장한다.key를 바탕으로 해싱을 통해 인덱스를 부여 후, 초기에 선언된 버킷 배열의 해당 인덱스에value를 저장한다.- 구현 기능은
set(저장 및 업데이트),get(조회),delete(삭제)이다.- 충돌이 일어날 경우, 개별 체이닝 방식을 채택한다.
- 동일
key가 중복 저장되면 업데이트가 된다.
(2) 파이썬 코드
커스텀 코드는 링크 참조
https://github.com/kimD0ngjun/algorithm_structure/blob/main/src/data_structure/linear/hashTable/hash_table.py
