제네릭 프로그래밍

1. 서론
제네릭은 자바만의 전유물은 아니고, 엄밀히 표현하자면 프로그래밍 기법이라고 할 수 있다. 구체적으로는 특정된 데이터 타입에 의존하지 않고 여러 다른 데이터 타입을 가질 수 있는 기술에 중점을 두면서 재사용도의 향상을 꾀하는 것이 제네릭 프로그래밍의 핵심이라 할 수 있다. 이 점은 객체지향 프로그래밍 패러다임에서 다형성을 실현할 수 있는 수단의 가능성을 시사하기도 한다.
데이터의 타입과 밀접한 관련이 있기 때문에 인터프리터를 활용하는 런타임 언어에서는 비중이 낮은 개념이긴 하다. 자바스크립트나 파이썬 같은 경우 코드를 짤 때, 타입을 명시하지 않아도 되는 이유가 런타임 시점에 타입이 결정되기 때문이다. 물론 데이터 타입의 안정성을 유지하는 것은 컴파일, 런타임을 넘어 성능과도 직결되는 중요한 부분이어서 파이썬의 타입 힌트 혹은 자바스크립트의 슈퍼셋 언어인 타입스크립트 같은 것들이 등장하게 된다.
2. 자바의 제네릭
private String stringData;
private Integer integerData;
private CustomType customData;자바는 대표적인 정적 언어다. 즉, 컴파일 시점에 데이터의 타입이 결정되기 때문에 개발자의 구체적인 타입 명시가 중요한 언어다. 분명히 타입을 명시하는 것은 중요한 일이지만 동일한 기능을 수행함에도 데이터 타입이 다르다는 이유로 동일 기능을 각각 데이터들의 타입에 맞춰 반복 작성하는 것은 오히려 비효율적이다.
T TData;그래서 등장하는 개념이 제네릭인 것이다. 타입을 구체적으로 명시하지 않고 사용하는 케이스에 맞춰서 그때그때 타입을 유연하게 지정하는 것이 제네릭의 취지이자 핵심 동작 매커니즘이라고 할 수 있다.
자바 내에서 제네릭과 관련된 문법인 타입 파라미터, 제네릭 타입 및 메소드, 와일드카드 등에 대해서는 내가 예전에 자바 공부할 때 기록한 스터디 레코드를 참조할 것.
아래의 내용부터는 저우즈밍 저 'JVM 밑바닥까지 파헤치기'의 내용을 일부 참조하며 나의 의견을 담음
3. 제네릭 프로그래밍의 모순
1) 타입에 대한 제네릭의 취급
어느 정도 자바 문법이 익숙해지고 스프링 개발 연습을 하면서 제네릭이 점차 익숙해지고 다시 저 제네릭 프로그래밍의 개념을 유심히 읽었을 때 약간 의아한 점이 느껴졌다.
- 제네릭은 타입 안정성을 위한 도구다.
- 제네릭을 활용하여 유연성을 발휘할 수 있다.
처음 접했을 때는 무심코 넘어갔지만, 다시 읽었을 때 저 두 표현이 상당히 모순적이라는 위화감을 떨칠 수가 없었다. 왜 그런가 해서 제네릭이 필요한 이유를 다시 읽어보다가 아래의 문구가 핵심이라는 느낌을 받았다.
동일한 기능을 수행함에도 데이터 타입이 다르다는 이유로 동일 기능을 각각 데이터들의 타입에 맞춰 반복 작성하는 것은 오히려 비효율적이다...
볼드체 처리된 부분이 핵심이라 느꼈는데, 이유는 오히려 타입 안정성을 지키는 것이 핵심이라면 중복 작업이어도 감수하고 타입에 맞춰 기능들을 작성하는, 타입을 우선적으로 생각하는 관점이 지향되어야 하지 않는가라는 점이었다.
애시당초 타입의 안정성을 위한다면서 타입의 유연성을 같이 챙기려는 점이 제네릭의 모순이라는 것이 포인트였다. 좀 더 구체적으로 말하자면, 타입의 안정성을 지키는 것(현실)이 중요하지만, 그로 인해 생기는 반복적인 작업의 피로도와 비효율성이 높기 때문에 타입의 유연성을 발휘(이상)할 수 있는 방법으로써 제네릭이 등장한 것이다.
2) 코드로 살펴보는 모순점
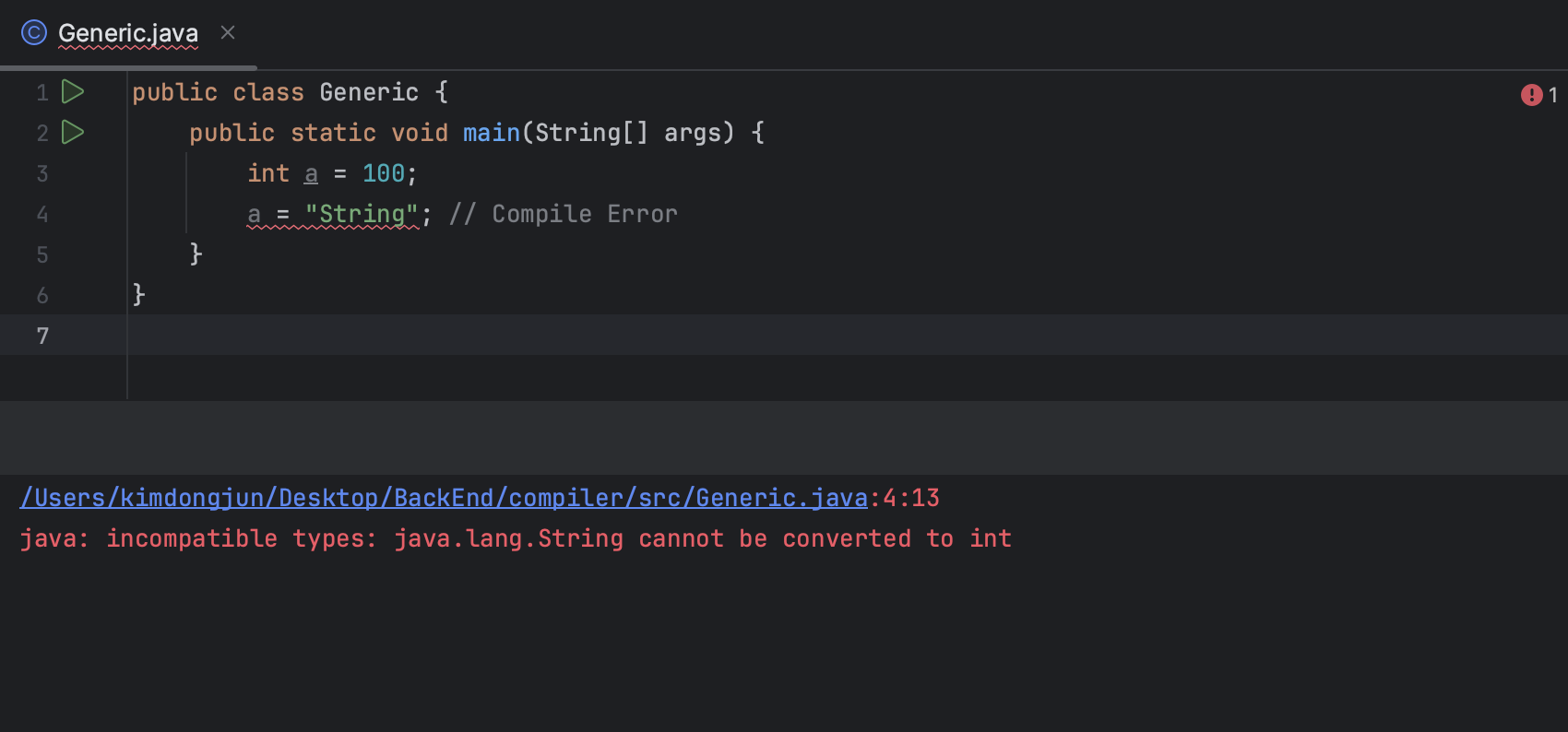
int a = 100;
a = "String"; // Compile Error위의 코드는 비단 자바가 아닌 다른 정적 언어여도 컴파일 시점에서 에러를 반환하게 된다. 애시당초 정의한 타입과 다른 타입과 관련된 코드를 작성하기 때문에 문제가 발생하는 것이 자명하다. 런타임 시점에 데이터 플로우가 이뤄지는 것의 핵심은 컴파일 시점의 타입 정의이기 때문에 타입 정의가 옳지 못한 위의 코드는 런타임으로 넘어갈 필요도 없이 에러가 나게 된다.
위의 코드는 우리가 아는 정적 언어의 지식으로 무리 없이 받아들여진다. 근데 여기서 이제 제네릭을 도입했을 때, 과연 어떻게 될까? 아래와 같이 개략적인 상황이 있다.
// T : Generic Type Parameter
T data = 100;
data = "String"; // ???앞서 말했듯, 제네릭은 타입 결정의 유연성을 위하여 컴파일 시점에 타입이 결정되지 않는다. 그렇기 때문에 위와 같은 코드 개략을 생각해볼 수 있다.
분명히 위의 코드를 컴파일한다면 T는 컴파일 시점에 결정되지 않은 타입이기 때문에 첫 번째 라인(T data = 100;)은 유연하다라는 키워드에 맞춰 이해할 수 있어도 두 번째 라인(data = "String";)에서 괴리가 생기게 된다. 바로 이 런타임에 서로 다른 타입을 대입하는 부분이 제네릭 프로그래밍으로부터 발생하는 모순점이라고 볼 수 있다.
3) 제네릭 설계 취지의 관점
이 모순을 해결하기 위해 정적 프로그래밍 언어의 매커니즘으로 돌아가서 살펴보면, 컴파일 시점에 타입이 결정되는 절대 원칙을 고수하는 입장에서 제네릭은 어떻게 취급할 것인가가 언어별의 제네릭 설계 취지가 될 것이다.
// T : Generic Type Parameter
T data = 100;
data = "String"; // ???위의 모순 상황을 나타내는 코드 개략으로 돌아가보자. 분명히 이 코드는 정적 언어의 입장에서 잘못된 것이 맞다. 타입 안정성이 절대원칙인데 이것을 정면으로 위반하는 코드이기 때문에 에러나 예외를 던져서 코드 실행을 막아야 한다. 이 말은 곧 제네릭에서의 타입 결정의 태만으로 인해 에러나 예외가 발생하니까 제네릭에서 타입의 결정 시점을 정해야 한다는 뜻이 된다.
4. 모순의 해결책(?) : 타입 소거
우리는 해결책을 두 가지로 생각할 수 있다. 정적 언어는 컴파일 -> 런타임 순으로 프로그램이 동작하므로 제네릭에서의 타입 결정 시점에 대해 논하자면
1. 컴파일 시점에 바로 타입을 결정시킨다.
2. 컴파일은 일단 넘기고 런타임 시점에 타입을 결정시킨다.
이렇게 정리할 수 있고, 실제 정적 언어들의 제네릭 취급에 대한 모순 해결책이 이렇게 두 개로 나뉘어지는 편이다. 이렇게 제네릭 처리 방식에 대한 두 가지 접근이 있으며, 이는 언어별 제네릭 설계 취지의 핵심을 반영한다. 각 언어는 타입 안정성과 유연성 사이에서 균형을 맞추기 위해 각자의 방식으로 제네릭을 설계하고 구현한다.
일단 저 두 해결책들 중 1번 해결책은 타입 소거 개념을 담고 있으며 이를 도입한 대표적인 언어가 자바이다. 그리고 2번 해결책은 타입 유지 개념을 담고 있으며 이를 도입한 대표적인 언어가 C++이다.
나는 1번 해결책을 중점적으로 살펴볼 예정이다. C언어 시리즈도 공부해보고 싶긴 한데 지금의 메인 언어는 자바니까 :D
1) 타입 소거의 개념
들어가기 전에 문맥이 조금 아리송할 수도 있다. T라는 정해지지 않은 타입을 그냥 컴파일 때에 정하면 제네릭의 유연성을 포기하겠다는 의미인가라는 뜻으로도 들릴 수 있기 때문이다. 구체적으로 런타임 때에 무리 없이 동작시키기 위한 임의의 타입 지정이라고 생각하면 된다. 제네릭의 취지는 타입의 안정성과 동시에 타입의 유연성이기 때문이다. 타입의 유연성을 조금 더 우선시한 해결책이라 생각할 수 있다.
동작 매커니즘은 아래와 같다.
컴파일 시점
- 타입 파라미터 변수가 확인된다.
- 구체화된 대입에 대한 타입 검사를 수행하여 구체적인 타입이 결정된다.
- 이를 통해 타입 안정성을 확보한다.
런타임 시점
- 컴파일이 완료되면 타입을 소거해 버린다.
- 이로써 흡사 임의의 포괄적인 타입처럼 동작할 수 있게 된다.
- 이를 통해 타입 유연성을 확보하게 된다.
이런 순서를 거치기 때문에 1번 해결책을 타입 소거라고 한다. 런타임 시점에 타입 자체를 소거시켜버려서 개별적으로 구체화되는 타입이 전부 달라도 유연하게 동작할 수 있게 된다는 것이다. 이를 코드 기반으로 확인해보자.
Box라는 제네릭 타입을 하나 정의한다.
class Box<T> {
T content;
Box(T content) {
this.content = content;
}
}그리고 두 개의 Box 인스턴스를content 필드를 채우면서 생성한다.
Box<Integer> integerBox = new Box<>(100);
Box<String> stringBox = new Box<>("내용물");이제 이 코드들을 바탕으로 타입 소거의 순서에 맞춰서 자바의 제네릭 타입 컴파일 수행 단계를 하나씩 체킹해보자.
(1) 타입 파라미터 변수가 확인된다.
Box<Integer> integerBox = new Box<>(100);
Box<String> stringBox = new Box<>("내용물");자바 컴파일러는 컴파일 단계에서 타입 파라미터 변수들이 있나 확인을 할 것이다.
(2) 구체화된 대입에 대한 타입 검사를 수행하여 구체적인 타입이 결정된다.
integerBox.content = "이상한 내용물"; // Compile Error!integerBox라는 변수는 Box<Integer>에서 볼 수 있듯이 Integer 타입의 내용물만을 받아들여야 할 것이고 컴파일러가 구체적인 타입 검사를 수행하는 것이 바로 이 부분이다. 그렇기 때문에 integerBox.content라는 필드 역시 Integer 타입이 확인되지 않으면 컴파일러가 바로 컴파일 에러를 일으킬 것이다.
(3) 이를 통해 타입 안정성을 확보한다.
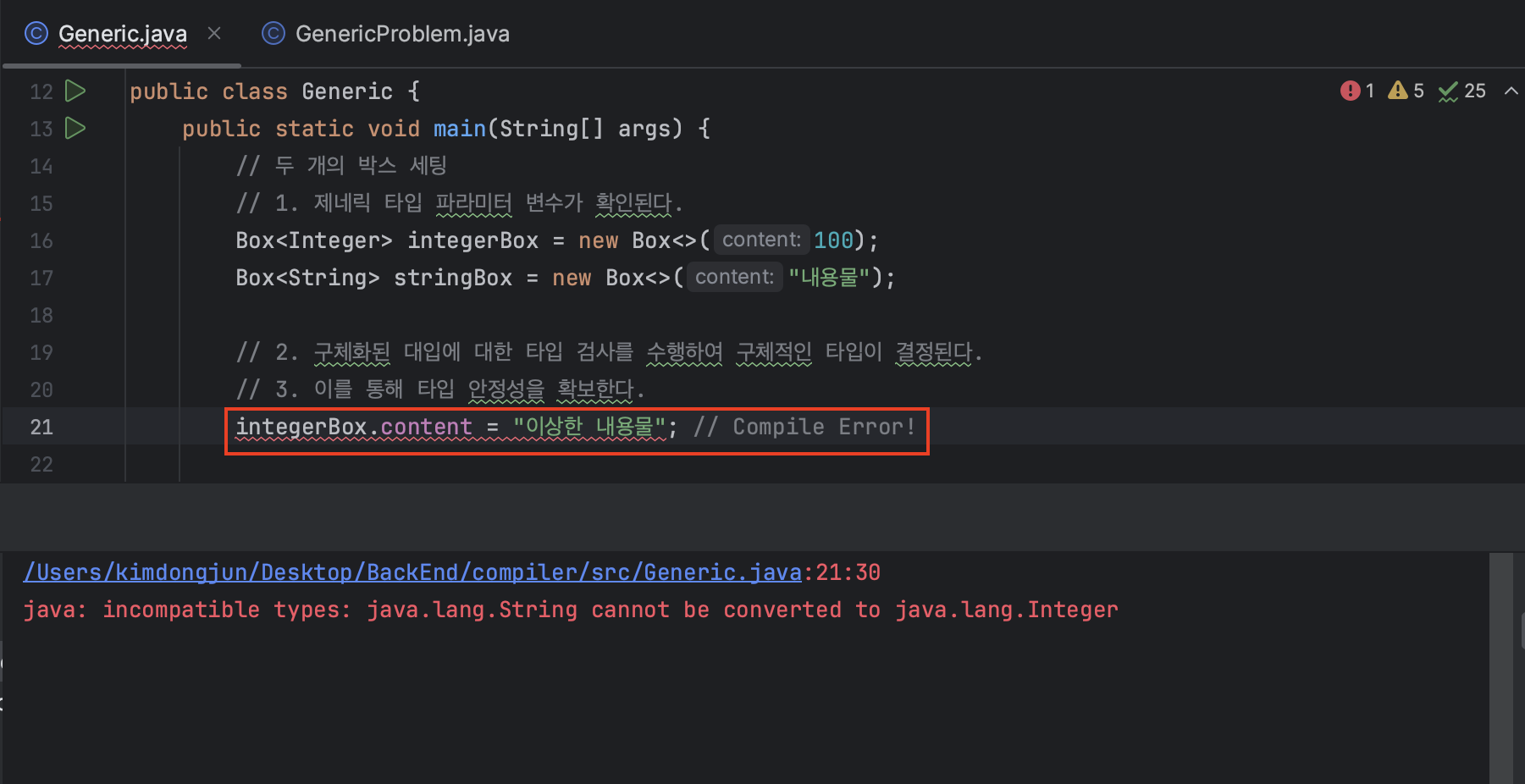
여담인 내용인데, 인텔리제이 같은 IDE에서 코드를 작성하다가 빨간 줄이 죽 그이는 것을 가끔 볼 것이다. 웬만한 빨간 줄들은 컴파일 에러를 사전에 경고하는 IDE의 기능이다. 즉, 실제로는 그러하나 우리는 마치 컴파일 결과 여기서 에러가 발생했다라고도 이해할 수 있다.
위의 사진처럼 컴파일러의 타입 검사 결과, 컴파일 시점에 결정된 타입(Integer) 과 다른 타입의 데이터("이상한 내용물")이 할당되기 때문에 런타임까지 넘어가지 않고 컴파일 에러를 내뱉고 이를 통해 타입 안정성을 확보하는 것이다.
이제 런타임으로 넘어가 보자.
(4) 컴파일이 완료되면 타입을 소거해 버린다.
타입 소거가 바로 런타임 시점에서 발생하게 된다. 이게 무슨 뜻이냐면 임의의 포괄적인 타입(Object)으로 치환 해석한다는 의미와 유사하다.
(5) 이로써 흡사 임의의 포괄적인 타입처럼 동작할 수 있게 된다.
이것은 마치 코드로 나타내자면 다음과 같이 동작하게 될 것이다.
class Box<T> {
T content;
Box(T content) {
this.content = content;
}
}기존의 Box<T> 제네릭 타입의 컴파일을 마치고 런타임에 진입하면 마치 아래처럼 취급된다.
class Box {
Object content;
Box(Object content) {
this.content = content;
}
}이렇게 해석되기 때문에 아까 생성했던 두 개의 인스턴스도 다음처럼 취급된다.
// 컴파일 이전
Box<Integer> integerBox = new Box<>(100);
Box<String> stringBox = new Box<>("내용물");
// 런타임 시점
Box integerBox = new Box(100);
Box stringBox = new Box("내용물");즉, 분명히 다른 목적(내용물)을 갖고 생성한 별개의 제네릭 타입 인스턴스임에도 불구하고 런타임 시점에서는 동일한 타입처럼 취급되면서 타입 유연성을 확보할 수 있게 된다.
(6) 이를 통해 타입 유연성을 확보하게 된다.
integerBox.getContent();
stringBox.getContent();만약 Box<T> 제네릭 타입 안에 T getContent()라는 Getter 메소드가 존재한다면 동일한 Getter를 호출할 수 있게 되는 것 또한 타입 유연성의 실현이라 볼 수 있다.
조금 근본적인 의문점이 들 수도 있는데 왜 타입을 런타임 때 소거하는지에 대해 간략히 설명하자면 다형성의 실현을 위해서다. 다형성이라는 건 단순히 코드 작성에서 중복을 줄이고 재사용성을 높이는 것만을 뜻하지 않고 JVM 내부의 컴파일링 등의 과정에서도 통용될 수 있는 개념이다.
만약 타입 소거가 되지 않으면 Box<Integer> 타입과 Box<String> 타입이 별개의 타입으로 취급될 수밖에 없고 이는 컴파일링 작업이 2배로 늘어나는 것을 의미한다. 그런데 애시당초 둘은 Box<T>라는 프레임을 바탕으로 생성됐기 때문에 별개의 타입으로 취급하여도 중복되는 작업이 다수 존재하므로 이런 비효율성을 해소하여 컴파일러 처리 비용과 런타임 비용을 줄이는 것이 자바의 제네릭 도입에 대한 근거이자 관점이라 할 수 있다.
2) 타입 소거의 문제점
다만 타입 소거는 앞서 제네릭의 모순의 완벽한 해결책이 아니다. 컴파일 시점의 타입 결정으로 확실하게 검증하는 것은 분명 타입 소거의 장점이지만 결국 제네릭의 취지를 살리기 위해 검증한 타입을 소거해야 되는 점 때문에 문제가 발생할 수도 있다.
(1) Issue 1: 리플렉션과의 활용
자바의 리플렉션은 런타임에 클래스, 메소드, 필드 등을 동적으로 조회하고 수정할 수 있는 기능을 제공하는 기능이다. 리플렉션을 사용하면 코드가 컴파일된 후에도 객체의 구조를 분석하고 조작할 수 있기 때문에 주로 동적 프록시 패턴 등에서 활용될 수 있다.
자바의 제네릭 타입 컴파일링은 런타임 시점에는 타입 소거가 된다고 위에서 확인했었다. 이 과정에서 리플렉션을 제네릭 타입 인스턴스에 활용하는 코드를 작성해보자.
// 두 개의 박스 세팅
Box<Integer> integerBox = new Box<>(100);
Box<String> stringBox = new Box<>("내용물");
// Issue 1 : 둘 다 같은 박스인가?
System.out.println("같은 박스? : " + (integerBox.getClass() == stringBox.getClass()));논리적으로 생각했을 때는 말이 안 된다. 분명 다른 타입의 내용물을 담는 박스니까 우리의 논리대로라면 저 둘은 다른 박스라는 결과가 나오니 false가 로그로 출력되어야 한다. 하지만 실행해보면
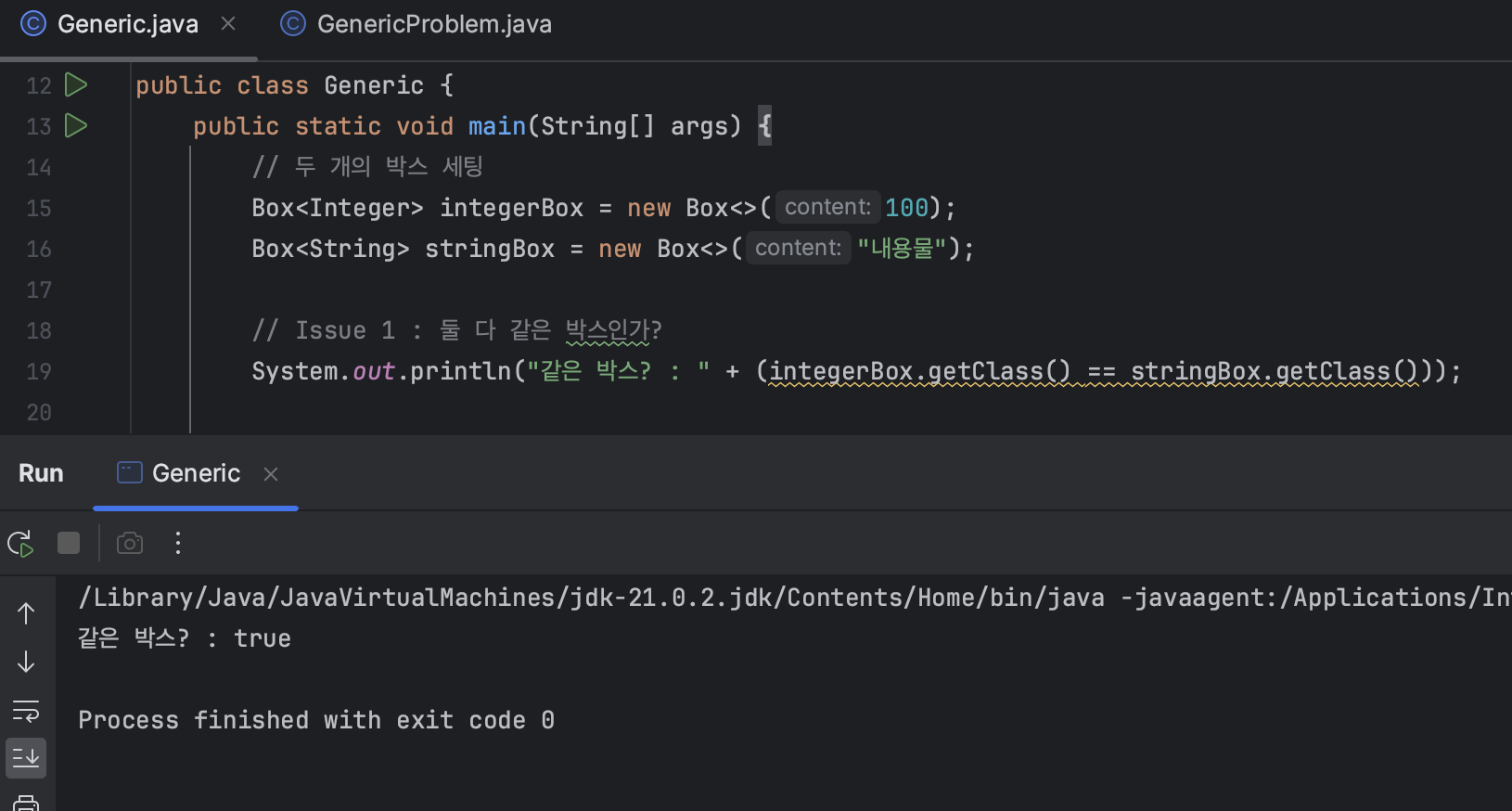
바로 이 부분이 타입 소거의 맹점 중 하나다.
앞서 얘기했듯 리플렉션은 런타임 시점에서의 클래스, 메소드, 필드에 대한 작업을 처리하는데, 제네릭 타입 파라미터는 런타임 시점에서 타입이 소거되기 때문에 Object처럼 취급된다고 했었다. 이런 특성들이 맞물려서 리플렉션을 통해 제네릭 타입 인스턴스들의 개별적이고 구체화된 타입 조회가 불가능해진다.
(2) Issue 2: 원시 타입(raw type)과의 호환
여기서 말하는 원시 타입은, 자바 문법의 원시 타입(primitive type)을 말하는 것이 아닌 제네릭 프로그래밍에서 타입 파라미터 없이 사용하는 원시 타입(raw type)을 의미한다.
타입 파라미터 변수는 타입 소거로 Object처럼 취급되고, 제네릭 타입은 런타임 시점에서 원시 타입과 차이점이 없어지게 된다. 즉 런타임 시점에서 제네릭 타입 인스턴스나 원시 타입 인스턴스나 다를 바가 없다는 특징이 생기게 되는데, 이 부분 역시 문제 가능성이 다분하다.
앞서 봤던 Box<T> 제네릭 타입을 다시 활용하여 두 개의 제네릭 타입 인스턴스를 정의한다.
Box<Integer> integerBox = new Box<>(100);
Box<String> stringBox = new Box<>("내용물");그리고 여기서 원시 타입(Box) 변수에 integerBox 변수를 할당할 수 있다. 이것이 가능한 이유는 타입 매개변수 없는 원시 타입이 모든 타입의 객체를 받을 수 있기 때문이다. 즉, 타입 소거로 인해 발생하는 특이한 상황이기 때문에 우리는 아래와 같은 코드를 거부감 없이 받아들일 수 있다.
Box box = integerBox
box.content = "이상한 내용물"; // 내용물 바꿔치기...?
// 원시 타입의 취급
class Box {
Object content;
Box(Object content) {
this.content = content;
}
}여기서 이제 자바 객체의 기초를 생각하자면 변수는 객체를 참조하여 객체 주소를 담는 역할을 한다. 즉 new Box<>(100); 이라는 생성자를 통해 생성된 Box<Integer> 제네릭 타입의 객체를, 처음에는 integerBox라는 변수만 참조하고 있다가 이제 box라는 변수도 같이 참조하게 되면서 box 변수를 통해 객체를 건드리는 행위는 integerBox에도 영향을 같이 미치게 된다.
이제 아래의 코드를 통해 integerBox의 내용물을 꺼내보자. 우리는 integerBox라는 박스의 내부에 Integer 타입의 내용물이 들어있음을 알고 해당 내용물을 담는 변수의 타입을 Integer로 생각하는 것이 당연할 것이다.
Integer content = integerBox.content;심지어 여기까지 작성해도 IDE의 빨간줄 경고 없이 컴파일이 잘 수행된다. 코드가 잘 돌아갈까? 한번 실행해보자.
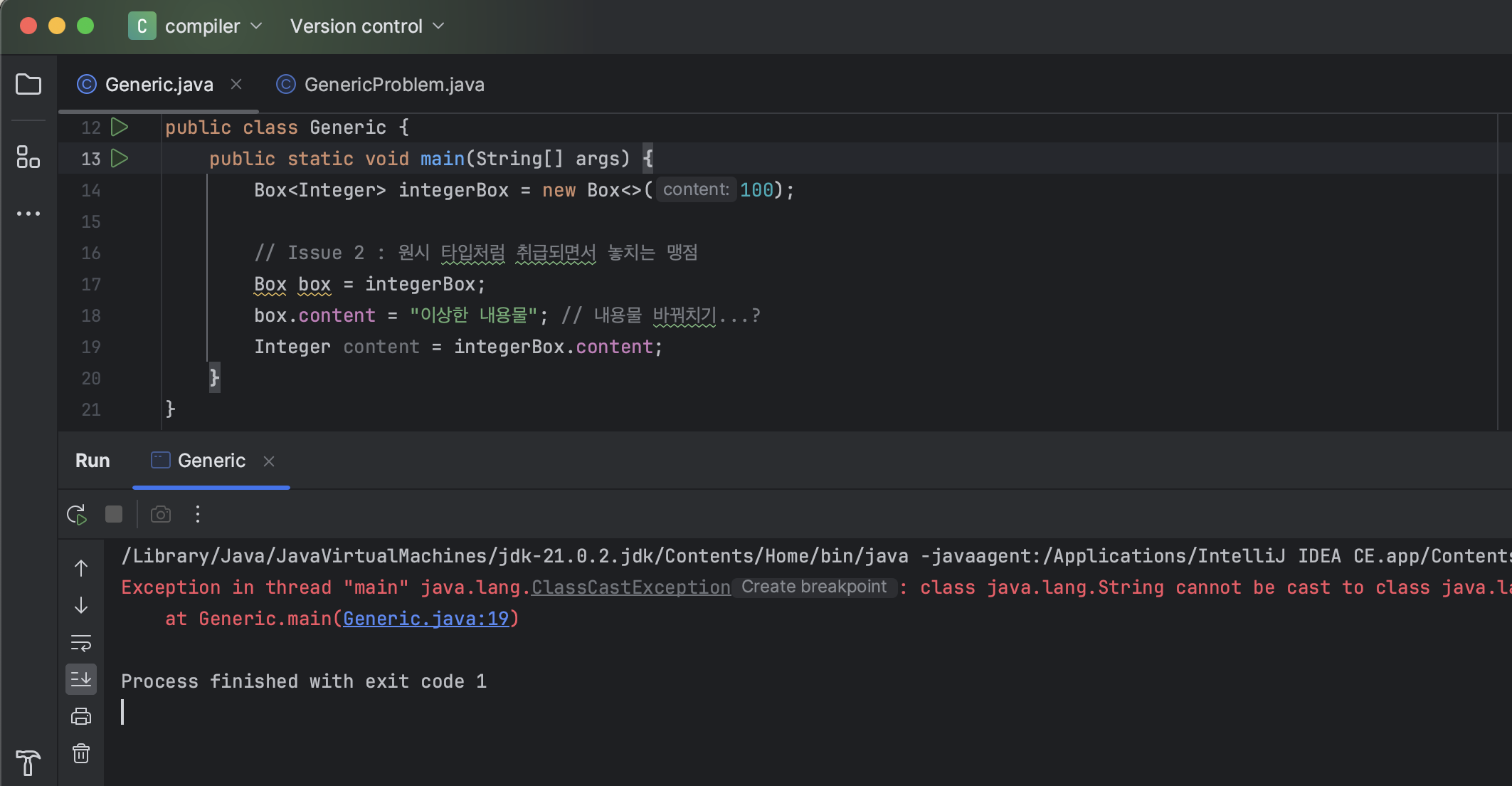
실행 결과, ClassCastException이 발생했다. 해당 예외는 런타임에 던져지며 잘못된 타입 변환을 수행하려고 할 때 문제가 발생한다. 아까 언급했듯 Integer 타입 내용물을 담은 박스 객체에 대하여 2개의 변수(integerBox, box)가 내용물에 관여했는데 마치 편법처럼 box 변수를 통해 String 타입 내용물로 바꿔치기를 한 것이 런타임에 와서야 문제로 커진 것이다.
아까 위에서 컴파일 에러를 유발하는 코드와 비교하면 괴리가 느껴지는 부분이다.
// 동일 객체 참조
Box box = integerBox;
// 비교
integerBox.content = "이상한 내용물"; // Compile Error!
box.content = "이상한 내용물"; // 컴파일은 통과, CCE 발생 원인분명 동일한 객체에 대한 내용물 조작임에도 하나는 컴파일에서 막히고 다른 하나는 런타임에서 막히게 된다. 타입 소거로 인해 컴파일 시점에서는 Box<Integer>여도 런타임 시점에서는 원시 타입인 Box처럼 동작하기 때문에 동일 객체를 참조하게 하는 변수 할당 코드가 정상 동작하는 것이다. 이 부분 역시 타입 소거의 맹점 중 하나라 할 수 있다.
3) 보완책은 없을까?
사실 애초에 제네릭 문법이 반쪽짜리 문법이라 느껴질 수밖에 없다. 타입 안정성과 타입 유연성을 동시에 챙긴다는 모순적인 발상에서 시작됐고, 그 간극으로 인해 발생하는 문제를 타입 소거 혹은 타입 유지로 해결하려고 하지만 정적 언어의 특성 상, 컴파일에 타입을 결정한다는 절대 원칙을 따를 것인지 아니면 인정하고 원칙의 예외로써 동작하게 할 것인지의 선택 문제이니까.
즉, 제네릭의 취지와 정적 언어의 절대 원칙은 양립할 수 없는 태생적인 모순을 가지고 있기 때문에, 절대 원칙을 준수하면서 런타임에서 늦게나마 타입의 유연성과 재사용성을 확보하는 방향(자바의 타입 소거)을 선택하거나 혹은 절대 원칙의 예외로써 런타임 시점으로 타입 결정을 미루는 방향(C#의 타입 유지) 중 하나를 울며 겨자먹기 식으로 선택할 수밖에 없다.
타입 유지는 크게 알아보진 않았지만, 타입 결정 작업을 제네릭 타입 인스턴스마다 따로따로 처리하게 되고 결국 런타임 비용이 늘어나는 치명적인 문제점을 갖고 있고 나아가 정적 언어의 취지인 타입 선제 해석을 통한 비용 절감이라는 취지를 위배한다. 결국 얘도 타입 소거처럼 반쪽짜리 해결책인 셈이다.
혹시나 자바의 와일드카드가 해결책이지 않을까... 생각할 수도 있지만 아니다. 와일드카드를 사용한 <?>은 애시당초 타입이 명확하지 않다는 것을 명시하는 것이기 때문에 타입이 명확하지 않은 상태에서 타입이 명확한 데이터를 할당하는 것이 불가능하다. 자바 컴파일러는 타입 안정성을 확보하는 것이 절대 원칙인데 이 절대 원칙을 지키지 못하는 상황에서 값의 할당을 막는 것이 당연하다.
Box<?> wildBox = new Box<>("와일드");
wildBox.content = "바꾸기"; // Compile Error!순수하게 읽기 전용이라면 그나마 가능하겠지만, 데이터 수정과 변경은 불가능하기 때문에 와일드카드가 제네릭에서 발생하는 모순의 해결책이 될 수 없다.
5. 마무리
제네릭은 처음 타입스크립트를 접했을 때에도 어려웠고, 스프링 연습을 하면서도 많이 활용해보지 못했기 때문에 이번 기회에 심도 있는 고민을 할 수 있었다. 나름대로 깊게 생각하며 제네릭 프로그래밍의 모순에 대한 해결책의 실마리라도 조금이나마 떠올려보고 싶었는데 내 역량으로는 아직 무리...
끝!
1) 전체 소스 코드
/**
* 컴파일 시점
* 1. 타입 파라미터 변수가 확인된다.
* 2. 구체화된 대입에 대한 타입 검사를 수행하여 구체적인 타입이 결정된다.
* 3. 이를 통해 타입 안정성을 확보한다.
*
* 런타임 시점
* 4. 컴파일이 완료되면 타입을 소거해 버린다.
* 5. 이로써 흡사 임의의 포괄적인 타입처럼 동작할 수 있게 된다.
* 6. 이를 통해 타입 유연성을 확보하게 된다.
*/
public class Generic {
public static void main(String[] args) {
// 두 개의 박스 세팅
// 1. 제네릭 타입 파라미터 변수가 확인된다.
Box<Integer> integerBox = new Box<>(100);
Box<String> stringBox = new Box<>("내용물");
// 2. 구체화된 대입에 대한 타입 검사를 수행하여 구체적인 타입이 결정된다.
// 3. 이를 통해 타입 안정성을 확보한다.
// integerBox.content = "이상한 내용물"; // Compile Error!
// Issue 1 : 둘 다 같은 박스인가?
System.out.println("같은 박스? : " + (integerBox.getClass() == stringBox.getClass()));
// Issue 2 : 원시 타입처럼 취급되면서 놓치는 맹점
Box box = integerBox;
box.content = "이상한 내용물"; // 내용물 바꿔치기...?
Integer content = integerBox.content;
// 와일드카드는 해결책이 될 수 없다.
// Box<?> wildBox = new Box<>("와일드");
// wildBox.content = "바꾸기";
}
}
class Box<T> {
T content;
Box(T content) {
this.content = content;
}
}
