인사이트 출처 : https://joyhong-91.tistory.com/12#whatBO, https://zoosso.tistory.com/883, https://blog.chulgil.me/algorithm/, https://velog.io/@abc2752/시간-복잡도Time-Complexity
입력값과 연산 수행 시간의 상관관계를 나타내는 척도.
최상은 오메가 표기법, 평균은 세타 표기법, 최악은 빅오 표기법
시간복잡도는 최악을 기준으로 성능을 예측한다.
빅오 표기법에서 시간복잡도는 입력된 N의 크기에 따라 실행되는 조작의 수
공간복잡도는 알고리즘이 실행될 때 사용되는 메모리의 양
시간 복잡도를 잘 이해해야 하는 이유
코딩 테스트를 통과하기 위한 것도 있지만, 개발자라면 여러 코드를 짬에 있어서 코드의 성능을 개선하고, 실행 시간을 단축시킬 수 있다.
단순히 돌아가는 코드를 짤 수 있지만 최적화 적인 측면에서 시간복잡도 개념을 알고 있으면 성능향상을 시도할 수 있는 발판이 된다.
코딩 테스트 시간 복잡도 판단법 (Python 기준)
1초 = 약 1억 번(2 * 10^8) 연산을 할 수 있다.
시간복잡도가 ~이면 최대 연산 횟수 ~ 번 가능
O(logN) → 약 10억번 가능
O(n) → 약 1억번 가능
O(N log N) - 약 100,000번 가능
O(N²) - 약 2,000번 가능
O(N³) → 약 500번 가능
O(1) 상수
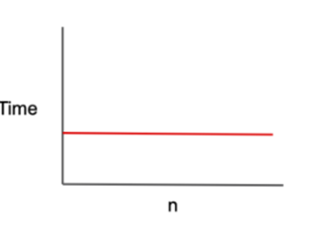
설명
- 데이터 원소가 N개와 상관없이 항상 일정한 상수 갯수의 단계 수만 걸림.
- 알고리즘의 실행 시간이 입력 데이터의 크기와 무관.
- 가장 빠른 시간 복잡도.
- 대부분의 경우 단일 연산이나 고정된 횟수의 연산을 수행할 때 나타난다.
예시
배열(첫, 마지막) 요소 접근, 해시 테이블 키를 통해 조회, 스택의 push, pop
배열의 첫 번째 또는 마지막 요소에 접근하는 경우
def get_first_element(arr):
return arr[0]해시 테이블에서 키를 사용해 값을 조회하는 경우 (평균적인 경우)
def get_value(hash_table, key):
return hash_table[key]스택의 push 또는 pop 연산
def push(stack, item):
stack.**append**(item)O(log N) - 로그 시간
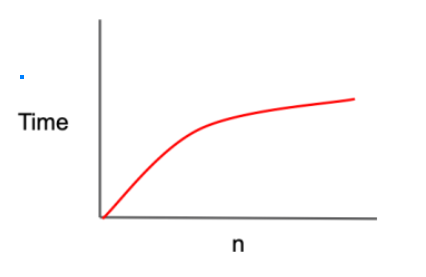
설명
- 입력 크기가 증가함에 따라 실행 시간이 로그적으로 증가.
- 문제를 해결하기 위해 입력을 반복적으로 절반으로 나누는 알고리즘에서 주로 나타남.
왜 입력을 반복적으로 절반으로 나누는 알고리즘에서 나타나는가
지수적 감소
각 단계마다 처리해야 할 데이터의 양이 절반으로 줄어든다.
이는 문제의 크기가 지수적으로 감소함 의미.
로그의 정의
log₂n은 2를 몇 번 곱해야 n이 되는가?를 나타낸다. 이는 n을 몇 번 2로 나누어야 1이 되는가?와 동일한 의미
효율성
입력 크기가 증가해도 처리 시간이 느리게 증가.
예 : 입력이 2배가 되어도 처리 시간은 1만큼만 증가
대표 예시로 이진 탐색
알고리즘 과정
정렬된 배열에서 중간 요소 확인.
찾는 값과 비교하여 왼쪽 또는 오른쪽 절반을 선택.
선택된 절반에서 과정을 반복
단계 수
각 단계마다 검색 범위가 절반 줄어듬.
n개의 요소를 가진 배열은 최대 log₂n 단계 후에 단일 요소로 줄어듬.
// 이진 탐색
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1# 오른쪽 절반 선택
else:
right = mid - 1# 왼쪽 절반 선택
return -1# 찾지 못한 경우복잡도 분석
1,000,000개의 요소를 가진 배열에서도 최대 약 20번의 비교만으로 검색 가능.
8개(3), 16개(4), 32개(5), 1024(10)
log₂(1,000,000) ≈ 19.93
이러한 특성 때문에 O(log n) 알고리즘은 대규모 데이터셋에서도 매우 효율적으로 동작한다.
O(N) 선형 시간
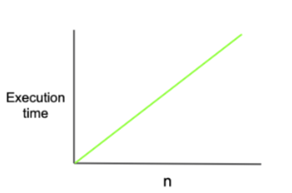
설명
- 실행 시간이 입력 크기에 비례하여 선형적으로 증가.
- 입력 데이터의 모든 요소를 한 번씩 처리해야 하는 경우에 주로 나타납니다.
- 단일 루프를 사용하여 입력 데이터를 처리하는 알고리즘에서 흔히 볼 수 있다.
- 입력 크기가 두 배가 되면 실행 시간도 대략 두 배.
배열의 모든 요소, 선형 검색 알고리즘
배열의 모든 요소를 순회하는 경우
def find_max(arr):
max_val = arr[0]
for num in arr:
if num > max_val:
max_val = num
return max_val선형 검색 알고리즘
def linear_search(arr, target):
for i, num in enumerate(arr):
if num == target:
return i
return -1O(N log N) - 로그 선형 시간
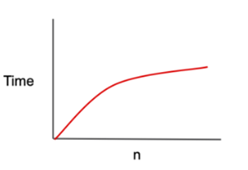
설명
- 실행 시간이 N log N에 비례하여 증가.
- 주로 효율적인 정렬 알고리즘에서 나타나는 시간 복잡도.
왜 효율적인 정렬 알고리즘에서 나타나는가
분할 정복 전략
많은 효율적인 정렬 알고리즘(예: 병합 정렬, 퀵 정렬)이 분할 정복 전략을 사용. 이 전략은 문제를 더 작은 부분 문제로 나누고, 각 부분을 해결한 뒤 결과를 합치는 방식이다.
로그적 분할
- 입력을 반복적으로 절반으로 나누는 과정에서 log n의 깊이가 생김.
- 예를 들어, 8개의 요소를 가진 배열은 3번의 분할로 1개의 요소로 나눈다. (8 -> 4 -> 2 -> 1).
선형적 결합
- 각 단계에서 n개의 요소를 처리하는 작업 필요하다.
- 예를 들어, 병합 정렬에서는 분할된 부분 배열들을 병합하는 과정에서 n개의 요소를 비교 정렬.
총 복잡도
- 로그적 분할(log n)과 각 단계에서의 선형적 작업(n)이 결합되어 O(n log n)이 됩니다.
예시로 병합정렬
병합 정렬 (Merge Sort)
- 분할(Divide) : 배열을 절반으로 나누고, 더 이상 나눌 수 없을 때까지 이 과정 반복. 이때 배열을 나누는 데 걸리는 시간은 log n.
- 병합(Conquer & Merge) : 나눈 배열을 다시 병합하면서 정렬. 이때 각 단계에서 두 배열을 병합하는 작업은 n번의 비교 필요.
병합 정렬의 동작 과정 요약
- 배열을 반으로 나누기(log n) : 배열을 재귀적으로 계속 나누면서 작은 단위로 분할.
- 병합하기(n) : 나누어진 배열을 다시 병합하면서 정렬된 상태로 합칩니다.
따라서, 병합 정렬의 총 시간 복잡도는 배열을 나누는 log n번의 과정과 각 단계에서 이루어지는 n번의 병합 작업이 결합 O(n log n)
장점
- 안정적인 정렬(stable sort): 동일한 값의 원소들의 상대적인 순서가 유지.
O(n log n)의 시간 복잡도로 일관된 성능을 보장. 특히 최악의 경우에도 O(n log n)을 유지하는 것이 특징.
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i, j = 0, 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return resultO(N^2) 이차 시간
설명
- 실행 시간이 입력 크기의 제곱에 비례 증가.
- 주로 2중 반복문
- 작은 입력 크기에 대해서는 괜찮지만, 큰 입력에 대해서는 비효율적.
- 입력 크기가 두 배가 되면 실행 시간은 네 배.
예시
버블 정렬(이중 for문)
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr선택 정렬
모든 가능한 쌍을 비교하는 알고리즘
