아티클스터디
오늘의 아티클
https://datarian.io/blog/how-to-ask-good-sql-questions
[주제]
- SQL 질문 잘하는 법
[아티클 요약]
✅질문 전 체크리스트
-코드에 오탈자가 있지는 않은가
-에러메시지에 맞는 조치를 취했는가
-where절 필터링 조건, order by절 정렬 조건, select절에 컬럼명이 정확하게 정의되었는가
🧐구글에서 검색하기
:관련 공식문서나 잘 구축된 기술 커뮤니티인 stackoverflow가 검색결과로 자주 등장
🧐영문으로 검색하기
:구글 언어설정 영어로 먼저 바꿔놓고, 영어로 검색→ 영어문서의 양이 압도적으로 이러한 문서들이 상단에 올라올 것.
영어 문법에 맞춰 질문할 필요 없이, ‘sql window function lag(함수명)’라고 단어만 나열해놓는 것도 충분하다
🧐검색 키워드 잘 넣기
:너무 넓게도X 좁게도X
PostgreSQL 의 cube라는 함수가 궁금하다 →그냥 cube 검색하는 것보다 ‘postgresql cube’라고 범위를 좁혀서 검색하는 것이 좋다
윈도우 함수 예시를 보고 싶다면, mysql window function이라고 특정 dbms를 넣는 것보다 ‘sql window function’이라고 검색해야 더 다양한 검색 결과를 볼 수 있다
🧐신뢰할 수 있는 사이트를 클릭하기
http://dev.mysql.com/
공식문서는 가장 좋확한 정보를 제공하고, stackoverflow는 좋은 기술 커뮤니티 이다.
공식문서라서 해석에 오해가 없도록 쉽고 명확하게 쓰여져 있는데, 영어가 조금 막힌다면
https://www.deepl.com/ko/translator를 통해 전반적인 내용과 글을 구조를 빠르게 파악하고, 정확히 이해가 필요한 부분만 영어로 읽어보는 것도 좋다.
🧐언제 쓰여졌는지 확인하기
:ex.MySQL은 2018년 8.0버전부터 윈도우 함수를 지원하기 시작했기 때문에 2018이전자료를 보게된다면 서브쿼리만을 이용한 풀이를 보게될 확률이 높다.
🧐주변 도움받기
-질문답변방
-슬랙 검색
:슬랙 앱 상단에 ‘데이터리안 커뮤니티 검색’창
→ 여기에 나와 비슷한 질문이 있는지 먼저 확인
<질문 템플릿>
‼️질문과 관련된 강의 영상제목+시간대 or 문제링크 노션수업자료 링크
‼️작성한 코드는 코드 복붙
스크린샷이나 사진
‼️기대했던 결과+내 시도의 결과 차이를 중심으로 한 문제 상황 서술
‼️기타 추가 설명(구글 검색어, 참고자료 링크 etc)
[인사이트]
**나는 보통 문제가 생겼을 때(맞는 것 같은데 왜 에러가 뜨지? 어디가 잘못된거지? ,, etc) 구글링이나 chat-gpt의 도움을 받았다.
chatgpt를 사용할 때도 프롬프트를 잘 써야 내가 원하는 답변이 나오는 것처럼,
검색과 질문을 잘하는 것도 중요하다는 생각이 들었다.
이 아티클에서도 마지막에, 질문 템플릿을 작성하다보면 기대했던 결과와 내가 시도한 결과의 차이를 고민하는 부분에서 스스로 해결을 할 수도 있고 도움이 많이 될 것이라고 하였는데,
velog에 스터디 기록을 남길 때 이 부분을 중점적으로 기록해봐야겠다.
mysql의 공식페이지에 들어가보니 몇가지 튜토리얼이 있는 것 같은데, 필요할 때 이용해보면 도움이 될 것 같다라는 생각이 들었고,
deepl 번역기는 처음 들어봤는데, 덕분에 영어에 크게 겁먹지 않고 문서를 읽는 시도를 해볼 수 있을 것 같다.
.
.
.
오늘 공부한 내용
DBeaver
Ctrl + Shift + F : 자동들여쓰기 및 정렬.
JOIN_필요한 데이터가 서로 다른 테이블에 있을 때 조회하기
excel Vlookup 기능과 유사
=VLOOKUP(찾을값, 참조범위, 열번호, [일치옵션])
💠선택인수? 정확히 일치 또는 유사 일치 여부.
기본값은 TRUE (유사일치).
실무에서는 주로 FALSE(또는 0) 을 입력하여 '정확히 일치'로 검색.
(유사일치는 찾을 값보다 '작거나 같은 값'을 검색하며, 유사 일치로 검색할 경우 참조범위의 첫번째 열은 반드시 오름차순으로 정렬되어야 함)
.
그냥 궁금해서 찾아봤다.. 엑셀이 필요할 때도 있을테니..!
.
.
Join도 마찬가지로,
공통 열이 있을 때 사용가능하고,
없다면 공통 열을 생성하거나 조합하여 기준 키를 만들어야 한다.
.
left join과 inner join
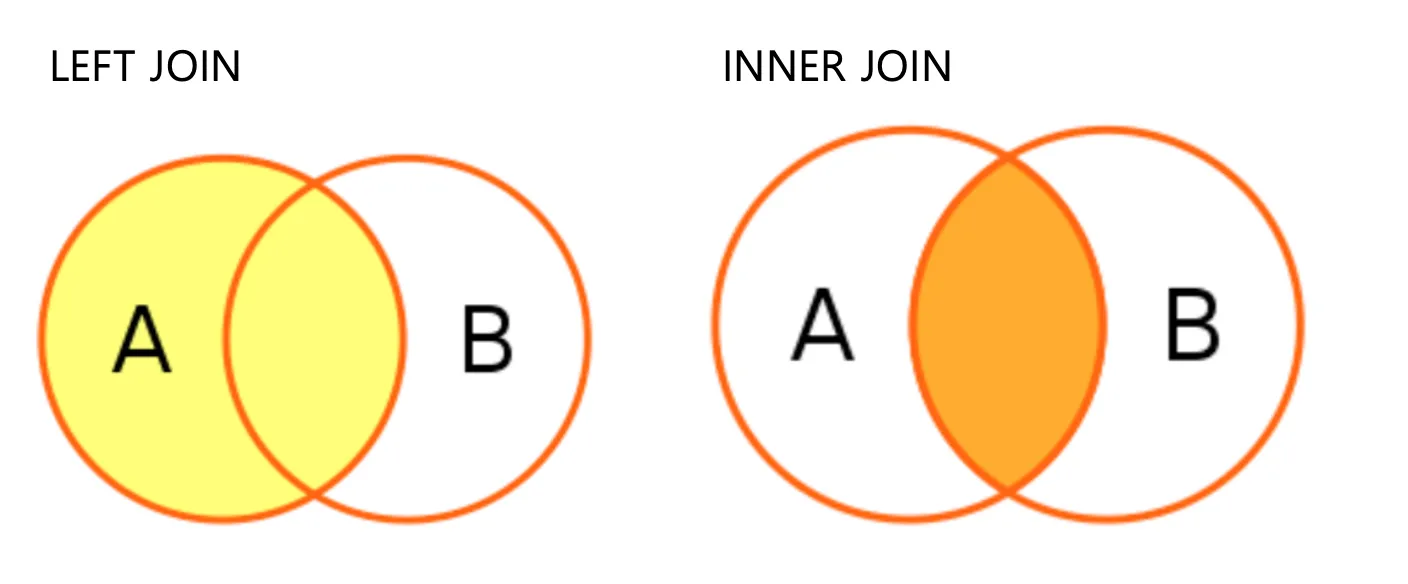
Join의 기본정보
✅LEFT JOIN
select 조회 할 컬럼
from 테이블1 a left join 테이블2 b on a.공통컬럼명=b.공통컬럼명✅INNER JOIN
select 조회 할 컬럼
from 테이블1 a inner join 테이블2 b on a.공통컬럼명=b.공통컬럼명*여기서 a와 b는 컬럼에 대한 alias이다
However, 두 테이블의 컬럼명이 달라도 괜찮다 !
예를 들어 주문정보에는 ‘고객ID’, 고객정보에는 ‘고객아이디’ 라고 컬럼명이 되어있다면,
테이블1.고객ID=테이블2.고객아이디 와 같이 묶어줄 수 있다.
문제_JOIN 을 이용하여 두 개의 테이블에서 데이터를 조회해보기
주문 테이블과 고객 테이블을 cusomer_id 를 기준으로 left join 으로 묶어보기
(조회 컬럼 : order_id, customer_id, restaurant_name, price, name, age, gender)
별명은 섭쿼리, 컬럼, 테이블에 모두 적어줄 수 있다
문제_- 1) 한국 음식의 주문별 결제 수단과 수수료율을 조회하기
(조회 컬럼 : 주문 번호, 식당 이름, 주문 가격, 결제 수단, 수수료율)
*결제 정보가 없는 경우도 포함하여 조회
💡사고과정
cuisine_type='korean' 을 조건,
'결제 정보가 없는 경우도 포함하여 조회'이니까 left join ~ on 을 쓰고 공통 칼럼은 order_id
불러올 테이블은 food_orders , payments 이대로 처음 시도했을 때 틀렸다
왜냐? 수수료를 내맘대로 rate칼럼을 불러왔다..
다음엔 select* from food_orders해서 무슨 칼럼을 불러올지 정확히 타깃팅 해야지..😓
다행히 vat으로 고치니까 정상실행됐다!
select
f.order_id
, f.restaurant_name
, f.price
, p.pay_type
, p.vat
, f.cuisine_type
from food_orders f left join payments p
on f.order_id=p.order_id
where cuisine_type='Korean' 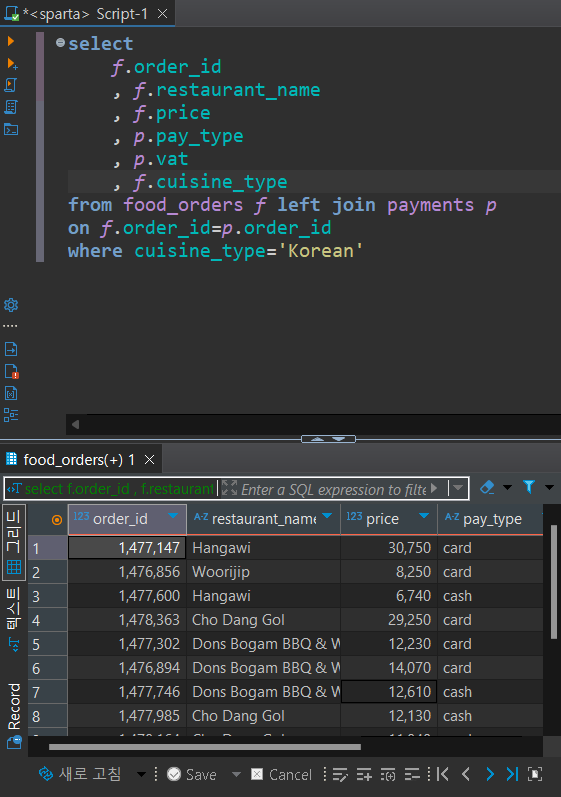
나는 where조건이 잘 걸렸는지도 확인해보기 위해, cuisine_type도 select에 넣었다
.
문제_2) 고객의 주문 식당 조회하기
(조회 컬럼 : 고객 이름, 연령, 성별, 주문 식당)
*고객명으로 정렬, 중복 없도록 조회
💡사고과정
inner join
불러올 테이블 - food_orders, customers
order by랑 distinct 이용해서 정렬이랑 중복 해결
select distinct(c.name)
,f.customer_id
,c.age
,c.gender
,f.restaurant_name
from food_orders f inner join customers c
on f.customer_id=c.customer_id
order by 1🔴정답코드
select distinct c.name
,c.age
,c.gender
,f.restaurant_name
from food_orders f inner join customers c
on f.customer_id=c.customer_id
order by 1⭐알게된 점
1.distinct 뒤에 괄호없이 바로 칼럼이름 쓰기
2.select에 customer_id 불러오지 않으면 inner from으로 묶었어도 실행결과에 안나온다
3.order by 칼럼이 한글 칼럼이면 가나다 순으로 정렬이다.
잠시 헷갈려서 group by와 order by를 정리하고 가자면,,
| 구분 | ORDER BY | GROUP BY |
|---|---|---|
| 기능 | 결과 데이터를 정렬 (오름차순/내림차순) | 데이터를 그룹으로 묶어서 집계 연산 수행 |
| 목적 | 데이터를 보기 쉽게 정렬 | 데이터를 특정 기준으로 그룹화 및 집계 결과를 반환 |
| 사용 위치 | 쿼리의 마지막 부분에 위치 (GROUP BY 뒤 가능) | SELECT 절에서 집계 함수와 함께 사용 |
| 필요한 열 | 정렬하려는 열이 반드시 존재해야 함 | 그룹화 기준 열이 반드시 존재해야 함 |
| 적용 대상 | 쿼리 결과 전체를 정렬 | 동일한 값들을 가진 데이터를 하나의 그룹으로 묶음 |
| 집계 함수 사용 여부 | 필수 아님 | 주로 집계 함수(SUM, COUNT, 등)와 함께 사용 |
| 결과 개수 | 정렬만 수행하므로 원본 데이터의 행 개수를 유지 | 그룹별 하나의 결과를 반환 (그룹 개수만큼 결과가 줄어듦) |
| 결과 순서 | 정렬 기준에 따라 데이터 순서가 결정 | 그룹화 후 결과의 순서를 보장하지 않음 (원한다면 ORDER BY 사용) |
.
JOIN으로 두 테이블의 값을 연산하기
문제_1) 주문 가격과 수수료율을 곱하여 주문별 수수료 구하기
(조회 컬럼 : 주문 번호, 식당 이름, 주문 가격, 수수료율, 수수료)
수수료율이 있는 경우만 조회
💡사고과정
불러올 테이블 -> food_orders, payments
공통 칼럼 -> customer_id
나머지 칼럼 불러오기
inner join을 이용한 연산은....?
💠기억할 점: select 이하에, pricevat 바로 식 넣어줄 수 있다.
<join으로 연산하기의 Point => ex.두 테이블의 값을 연산한다는 것
join으로 묶어줬기 때문에 서로 다른 테이블에 있는 값이지만, price와 vat을 곱해줄 수 있다.
문제 2) 50세 이상 고객의 연령에 따라 경로 할인율을 적용하고, 음식 타입별로 원래 가격과 할인 적용 가격 합을 구하기
(조회 컬럼 : 음식 타입, 원래 가격, 할인 적용 가격, 할인 가격)
할인 : (나이-50)0.005
- 고객 정보가 없는 경우도 포함하여 조회, 할인 금액이 큰 순서대로 정렬
( (age-50💡사고과정 select cuisine_type , price, discount, dis_price from customers c left join food_orders f on c.cus
)a discount*0.005
) b dis_price
=> 🔴여기가 좀 이상함. 서브쿼리 위치가 이상함..어떻게 해야할지 모르겠음.. 조건
where age>= 50
group by cuisine_type
sum(price,dis_price)
order by dis_price
'''
⭐풀이SELECT f.cuisine_type ,f.price ,c.age ,(c.age-50)*0.005 discount_rate from food_orders f left join customers c on f.customer_id=c.customer_id where c.age>=50
여기까지는 비슷했던 것 같다..내가 막혔던 부분은 여기까지 작성했던 것을 서브쿼리로 두는 것..
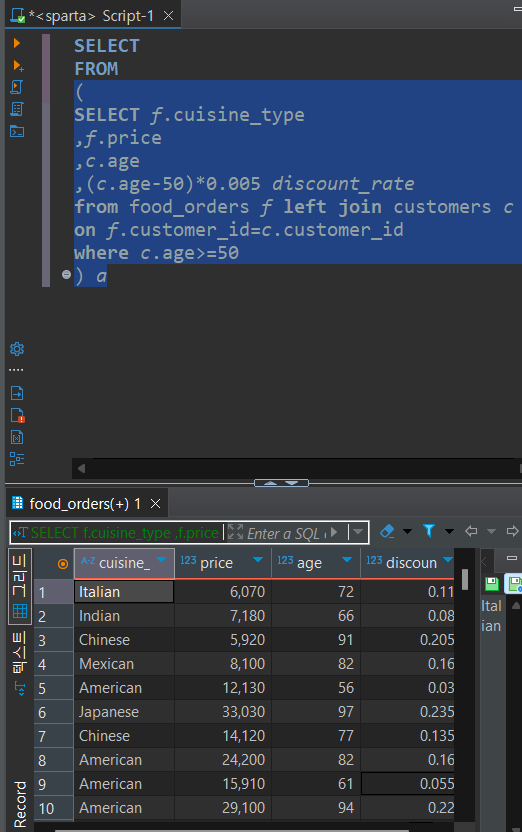
이렇게 쓴 서브쿼리는 이미 하나의 식으로 처리가 되기때문에(서브쿼리식 결과를 보면 알 수 있듯이 컬럼명 그대로임) ,
f.cuisine_type 이런식으로 안하고 그냥 cuisine_type으로 적어도 무방하다고 한다.
🔻최종코드🔻
SELECT cuisine_type
,sum(price) price
,sum(price*discount_rate) discounted_price
FROM
(
SELECT f.cuisine_type
,f.price
,c.age
,(c.age-50)*0.005 discount_rate
from food_orders f left join customers c
on f.customer_id=c.customer_id
where c.age>=50
) a
group by 1
order by 3 desc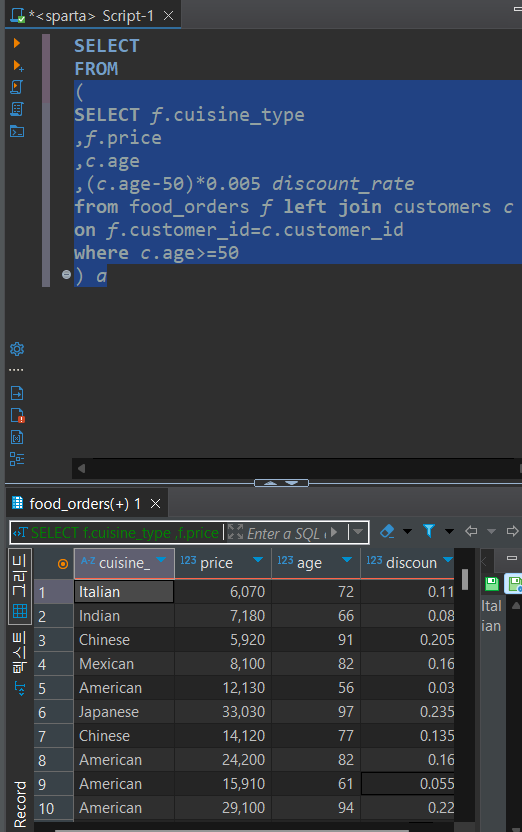
4주차 숙제문제
식당별 평균 음식 주문 금액과 주문자의 평균 연령을 기반으로 Segmentation 하기
- 식당별 평균 음식 주문 금액과 주문자의 평균 연령을 기반으로 Segmentation 하기
평균 음식 주문 금액 기준 : 5,000 이하 / ~10,000 / ~30,000 / 30,000 초과
평균 연령 : ~ 20대 / 30대 / 40대 / 50대 이상
두 테이블 모두에 데이터가 있는 경우만 조회, 식당 이름 순으로 오름차순 정렬
일단 가격 빼고 식 실행해봄
SELECT f.restaurant_name
,case when c.age<30 then "20대이하"
when c.age<40 then "30대"
when c.age<50 then "40대"
when c.age>=50 then "50대이상"
end age_froup
from food_orders f inner join customers c
on f.customer_id=c.customer_id
order by 1그리고 완성했다
SELECT f.restaurant_name,
AVG(f.price) price_group,
AVG(c.age) age_group,
CASE
WHEN AVG(f.price) <= 5000 THEN '5,000 이하'
WHEN AVG(f.price) <= 10000 THEN '~10,000'
WHEN AVG(f.price) <= 30000 THEN '~30,000'
WHEN AVG(f.price) > 30000 THEN '30,000 초과'
END price_group,
CASE
WHEN AVG(c.age) < 30 THEN '20대 이하'
WHEN AVG(c.age) < 40 THEN '30대'
WHEN AVG(c.age) < 50 THEN '40대'
ELSE '50대 이상'
END age_group
FROM
food_orders f INNER JOIN customers c
ON f.customer_id = c.customer_id
GROUP BY 1
ORDER BY 1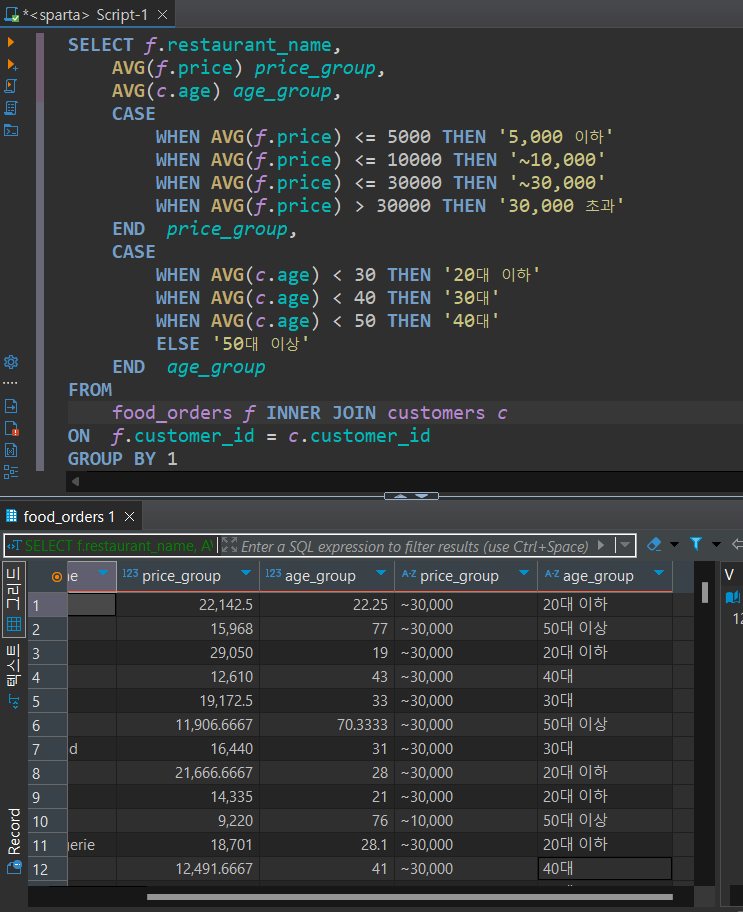
휴..너무 아직은 어렵다...
익숙해지게 많이 연습해야지 !
내일은 5주차 끝낼 수 있었으면 좋겠다 !!
