오늘 공부를 시작하기 전에 직무인터뷰를 몇개 찾아봤다.
카카오 PM 인터뷰
직무 인터뷰 ② “카카오 PM을 꿈꾼다면, 스스로에게 질문을 꼭 던져보세요”
지금까지 구체적인 도메인에 대한 꿈보다는,
네이버,카카오,토스,당근,컬리,배민 등 IT기업에서 일하고 싶다는 생각만 가득했다.
그래서 각 기업에서 pm이 어떤 역할을 담당하고 어떤 프로젝트를 수행해나가는지,,차차 분석하고 알아보아야겠다는 생각을 했다. 이 인터뷰를 가져온 이유는
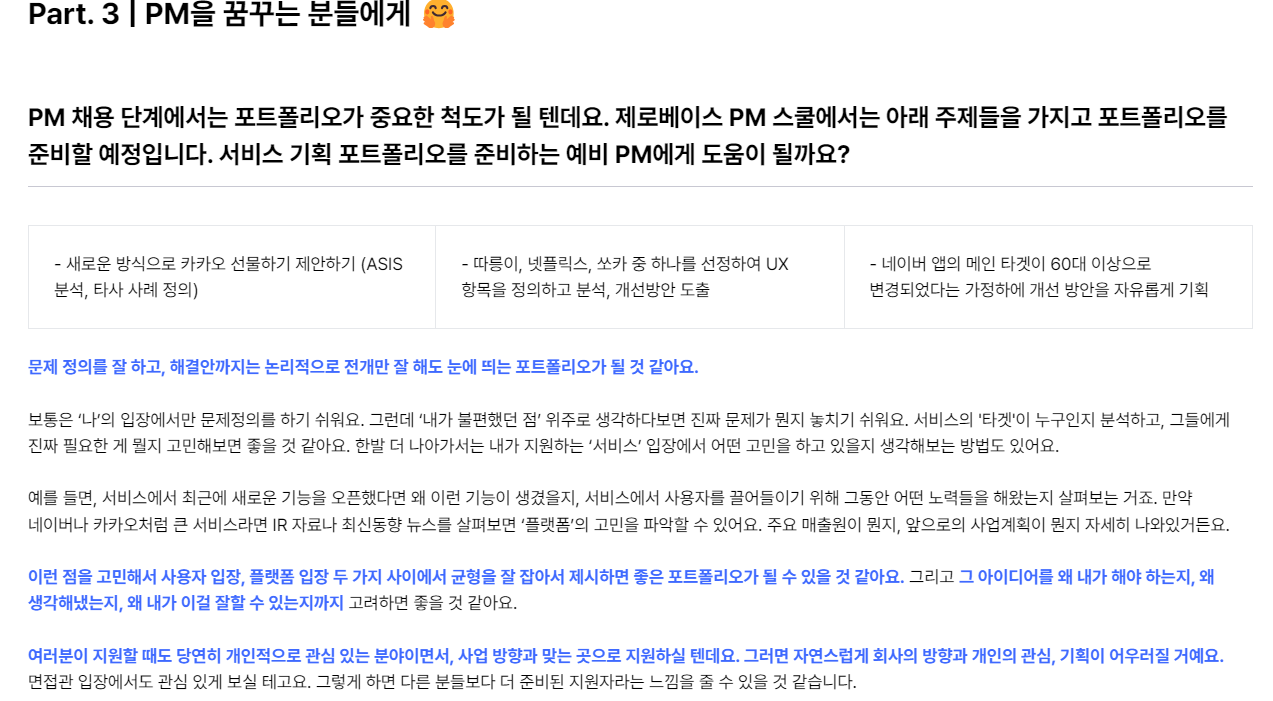 포트폴리오 구성이 재밌어보여서이다.
포트폴리오 구성이 재밌어보여서이다.
'네이버 앱의 메인 타겟이 60대 이상으로 변경되었다는 가정하에 개선 방안을 자유롭게 기획?' 벌써 내 상상력을 마구 자극한다..😳
앞으로 시간날 때 종종 서칭해봐야지 : )
아티클 스터디
오늘의 아티클
데이터를 쉽게 찾고 잘 활용할 수 있는 기반을 만드는, Data Analytics Engineer
[주제]
- 데이터를 쉽게 찾고 잘 활용할 수 있는 기반을 만드는, Data Analytics Engineer
[아티클 요약]
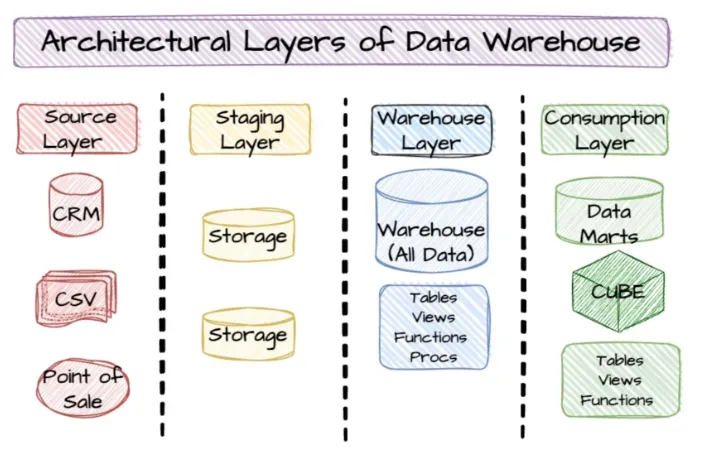
토스 환경분석
애자일 조직 기반
데이터 사일로화(조직 내의 데이터가 서로 분리되어 저장 및 관리되는 상황) 가속화
→ 이를 극복하기 위해 데이터 활용을 깊게 고민하고 개선하려는 것에 Data Analytics Engineer 분들이 힘쓰고 있음.
- 자기소개
DAE팀
:다른 데이터 사용자에게 데이터를 제공하는 입장에서의 경험을 더 쌓아보고 싶어 토스에 오게 됨.
토스는 유저 기반의 행동 데이터들이 많다 보니 데이터의 의미나 맥락을 파악하는 것이 더 재미있을 것 같았고, 현재 광고 도메인과 유저 규모의 성장을 도모하는 그로스 도메인의 DW를 구축하고 데이터를 표준화, 자산화 하는 업무를 담당하고 있음
:개인과 회사 모두의 성장을 동시에 경험할 수 있을 것이라 생각해 조인하게 됨.
토스페이와 토스쇼핑 등의 DW구축/운영, 표준화 업무를 담당하고 있음
토스 데이터 마트팀
:합류 전 에는 데이터베이스, DW관련 업무를 주로 담당
토스 데이터 분석가
:제품 조직에서 분석 업무를 담당, 이후엔 전략팀에서 유저/매출 등 전사 차원의 분석을 진행
여러 제품의 데이터를 활용하다 보니 데이터를 잘 활용할 수 있는 환경을 만드는 일에 관심이 생겨 DAE로 직군전환 → 대출/신용 도메인 및 새롭게 구조를 잡아나가고 있는 DW구축 업무를 담당
- DAE를 자세하게 설명해주세요!
토스에서 DAE는,
각 제품팀에서 생산하는 데이터가 전사적으로 유용하게 사용될 수 있게끔 데이터를 자산화하고 관련 데이터 파이프라인을 운영하는 역할
: 사용자 제공 서비스와 서비스를 운영하는 팀들이 모두 많다보니, 특정 데이터를 빠르게 찾고 활용하기가 쉽지 않은 환경→ 이를 극복하기 위한 기반을 만들어가고 있음
:데이터를 활용하는 구성원들이 분석에 필요한 데이터에 쉽게 접근하여 사용하고, 믿고 사용할 수 있는 환경을 제공하려 노력 + 모니터링과 최적화를 통해 데이터 파이프라인 안정성을 유지하며, 새로운 데이터 소스를 적용하거나 변화에도 대응하고자 함.
- DAE로서 토스에서 다양한 직무와 협업하는 방법
-담당 도메인 데이터 분석가와 협업을 많이 하는 편
어떠한 데이터 마트들이 생성되면 좋을지 파악
→ 이에 맞춰 개발하고 전사의 활성 유저 집계나 매출,비용등을 연동
실시간 데이터 모니터링 지원
다양한 데이터 활용을 위한 데이터 연동 작업
-데이터 마트팀에서는 ?
→데이터분석 플랫폼팀, DW팀과도 정기적인 미팅을 통해 해결과제 발굴
→비즈니스/세일즈에서 활용할 수 있는 데이터를 자산화, 표준화
.
- Data Maturity를 높이기 위하여
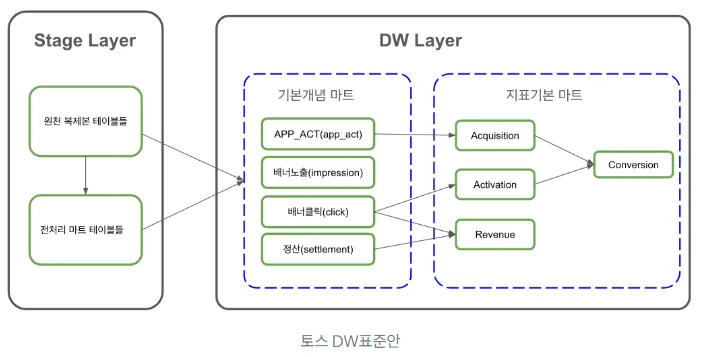
1.토스 DW표준안 정립→ 각 제품들의 주요 개념들을 명확하게 정의한 표준 데이터 마트를 빠르게 구축ing
2.데이터 오너십 부여→ 데이터 소비 주체들에게 서비스 수준으로 제공 가능한 하나의 Data Product를 만드는 포지션
⇒ 중앙의 표준 관리 조직(데이터 마트팀)은 각 도메인에 표준을 전파, 교육, 표준 모니터링을 수행하고, 각 도메인의 DAE는 분산된 데이터 오너십을 가짐
.
- 데이터마트팀과 도메인에 배치되는 DAE들의 목표는 다른가?
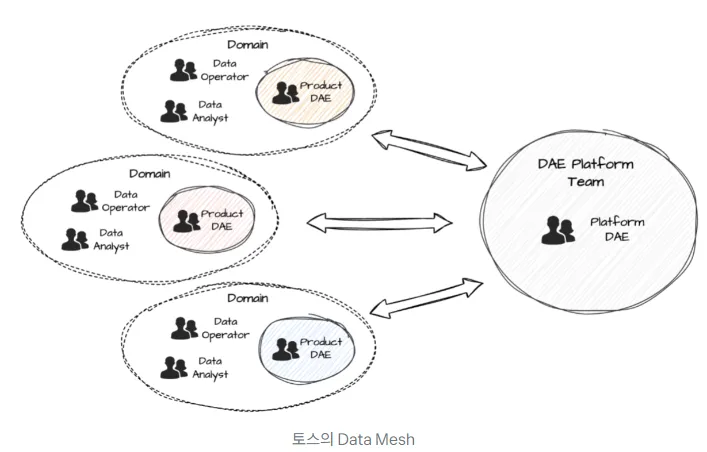
데이터 마트팀 DAE는 DW표준안이 전사적으로 잘 안착할 수 있도록 도메인 DAE들과 소통
공통의 목표:토스의 데이터 사용자들이 데이터를 쉽게 찾고 활용할 수 있는 기반을 만든다
- 토스 입사 장점
다양한 맥락 제품 많고, 그만큼 복잡도 높은 데이터를 적극적으로 활용하는 곳 ⇒ 데이터를 어떤 식으로 소비하고, 효율적으로 소비를 하기 위해 어떠한 환경을 구축해야하는지 유의미한 경험을 할 수 있음 - 지원자에게 바라는점
:데이터를 사용하는 사람들이 어떻게 하면 쉽게 데이터를 찾고, 잘 사용하게 할 수 있을지에 대한 고민과 실행 경험이 있는 사람
- 특정시각보다, 재사용성과 확장성이 높도록 테이블이나 데이터를 구조화해 본 경험이 있는 사람
[인사이트]
어느덧 마지막 아티클 스터디인데, 처음과 달리 아티클 용어들이 비교적 자연스럽게 읽히는 느낌을 받았다.
데이터 분석에 관심이 생겨서 관련 정보를 찾아보기 시작했던 때, 처음 접했던 기업이 토스였다. 유저기반의 행동 데이터 활용과 편리한 UI/UX 개발이 강점인 것으로 알고 있었고 어느정도 호감이 있는 기업이었기 때문에 특히나 이번 아티클에 몰입해 리딩할 수 있었던 것 같다.
토스는 다양한 데이터, 다량의 데이터를 확보하고 계속 생성해내고 있는 만큼 효율적으로 데이터를 활용하기 위해 세분화된 업무 분담, 데이터 전달 구조가 촘촘하다는 점을 체감할 수 있었다. 특히 ‘Data Mesh’를 봤을 때 각 도메인과 플랫폼팀이 구분되어있고 각 도메인 마다 데이터분석가를 비롯한 데이터 전문가들이 배치되어있는 것이 인상적이었다.
확실히, 이렇게 데이터를 잘 활용하고자 하는 것에 총력을 기울이고 있는 회사에서 ‘내가 원하는 데이터를 기반으로한 제품기획(PM)’업무를 효과적으로 실행해낼 수 있을 것이라는 생각이 들었고, 이러한 회사에 입사하고 싶은 마음이 더 강해진 계기가 된 것 같다.
글 마지막 부분에, 데이터 사용에 고민과 실행 경험이 있고 재사용성과 확장성을 높힐 수 있도록 데이터를 구조화해본 경험이 있으면 좋을 것 같다는 얘기가 있었는데,
⭐다음주부터 본캠프에 참여하면서 고민도 많이 해보고 오류도 많이 겪어보고, 기존데이터를 다양한 관점과 방법으로 활용할 수 있도록 구조화해보는 경험을 많이 해야겠다고 생각했다.
.
.
sql달리기반
달리기반 문제를 시작하기 전에 걷기반 마지막 문제가 하나 더 남아있었다..!
이 문제를 풀기 위해서 orders테이블을 삽입하던 도중.. 기존에 만들어뒀던 orders 테이블이 있어서 새롭게 생성이 안됐다! 난 전에 만든 orders 테이블은 사용하지 않을 것이기 때문에 삭제(Drop Table)를 해줬다.🔻
DROP TABLE IF EXISTS orders;
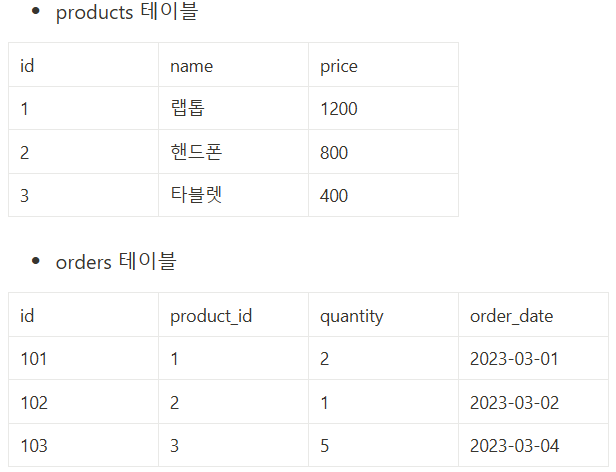
- 모든 주문의 주문 ID와 주문된 상품의 이름을 나열하는 쿼리를 작성해주세요!
select p.name, o.id
from products p inner join orders o
on p.id=o.product_id- 총 매출(price * quantity의 합)이 가장 높은 상품의 ID와 해당 상품의 총 매출을 가져오는 쿼리를 작성해주세요!
select o.id, sum(p.price*o.quantity) total
from products p inner join orders o
on p.id=o.product_id
group by o.id
order by total desc limit 1- 각 상품 ID별로 판매된 총 수량(quantity)을 계산하는 쿼리를 작성해주세요!
SELECT p.id, SUM(o.quantity) AS total_quantity
FROM products p INNER JOIN orders o
ON p.id = o.product_id
GROUP BY p.id - 2023년 3월 3일 이후에 주문된 모든 상품의 이름을 나열하는 쿼리를 작성해주세요!
SELECT p.name
FROM products p INNER JOIN orders o
ON p.id = o.product_id
where order_date >'2023-03-03'- 가장 많이 판매된 상품의 이름을 찾는 쿼리를 작성해주세요!
SELECT p.name
FROM products p INNER JOIN orders o
ON p.id = o.product_id
order by quantity desc limit 1나는 이렇게 작성해서 '태블릿'이라는 결과가 나왔는데, 답에서는 SUM(o.quantity) AS total_quantity 이것도 select에 넣었다. 결과로 name과 total_quantity 두개를 불러오기 위함인 것 같다.
- 각 상품 ID별로 평균 주문 수량을 계산하는 쿼리를 작성해주세요!
SELECT p.id, avg(o.quantity) AS avg_quantity
FROM products p INNER JOIN orders o
ON p.id = o.product_id
GROUP BY p.id - 판매되지 않은 상품의 ID와 이름을 찾는 쿼리를 작성해주세요!
SELECT p.id, p.name
FROM products p left JOIN orders o
ON p.id = o.product_id
where order_date is null.
.
달리기반_Lv1.데이터 속 김서방 찾기
<문제>
“김”씨로 시작하는 이용자들 수를 세어 보기
<조건>
name_cnt: “김”씨 성을 가지고 있는 교육생의 수
🔻내가 작성한 코드
select count(*) name_cnt
from users
where name like '김%'🔻스파르타 정답 코드
SELECT count(distinct(user_id)) as name_cnt
FROM
users
where substr(name,1,1) = '김'일단 답은 둘 다 동일하게 100으로 나온다.
그러나,
🔹 1. 두 코드의 차이점
📌 사용자의 중복 제거 방식
내가 작성한 코드
1.LIKE '김%'을 사용하여 "김"으로 시작하는 모든 사용자를 카운트함.
2.중복된 사용자가 있을 경우, 중복을 포함하여 모두 계산함.
3.COUNT(*)를 사용하여 중복이 있는 경우 정확한 고유 사용자 수를 보장하지 않음.
스파르타 정답 코드
SUBSTR(name,1,1) = '김'을 사용하여 "김"으로 시작하는 사용자 필터링.
COUNT(DISTINCT(user_id))를 사용하여 중복된 user_id를 제거하고 고유 사용자 수를 계산.
.
🔹 2. 어떤 코드가 더 정확한가?
✅ 스파르타 정답 코드가 더 정확함.
1.고유한 사용자 수를 세어야 하는 경우 COUNT(DISTINCT(user_id))가 적절함.
2.COUNT(*)는 단순히 테이블의 행 수를 세기 때문에 중복된 값이 포함될 가능성이 있음.
3.LIKE '김%'과 SUBSTR(name,1,1) = '김'은 기능적으로 같은 역할을 하지만, 일반적으로 LIKE는 와일드카드를 포함하여 더 넓은 문자열 검색이 가능하기 때문에 SUBSTR보다 성능이 떨어질 가능성이 있음.
🔶결론
1.count(*)를 count(distinct(user_id))로 작성해 중복을 제거하고 정확한 사용자 수를 계산!
Lv2. 날짜별 획득포인트 조회하기
문제: 다음과 같은 결과테이블을 만들어봅시다.
created_at: 익명화된 유저들의 아이디(varchar255)
average_points: 유저가 획득한 날짜별 평균 포인트(int), 반올림 필수
음, 일단 반올림을 하기 위해 어떻게 작성해야하는지 찾아봐야겠다.
ROUND(number, decimal_places)
-number: 반올림할 숫자
-decimal_places: 반올림할 소수점 이하 자릿수
이 값이 0이면 정수 부분만 남기고 반올림
양수면 소수점 이하 자리로 반올림하고, 음수면 소수점 왼쪽 자리로 반올림
ex.
소수점 이하 첫 번째 자리에서 반올림:SELECT ROUND(123.456, 1); -- 결과: 123.5정수로 반올림:
SELECT ROUND(123.456, 0); -- 결과: 123소수점 왼쪽 자리에서 반올림:
SELECT ROUND(123.456, -1); -- 결과: 120
date만 있는 줄 알고 order by로 정렬하려했는데, 시간도 같이 있는거 뒤늦게 확인하고 group by로 바꿈
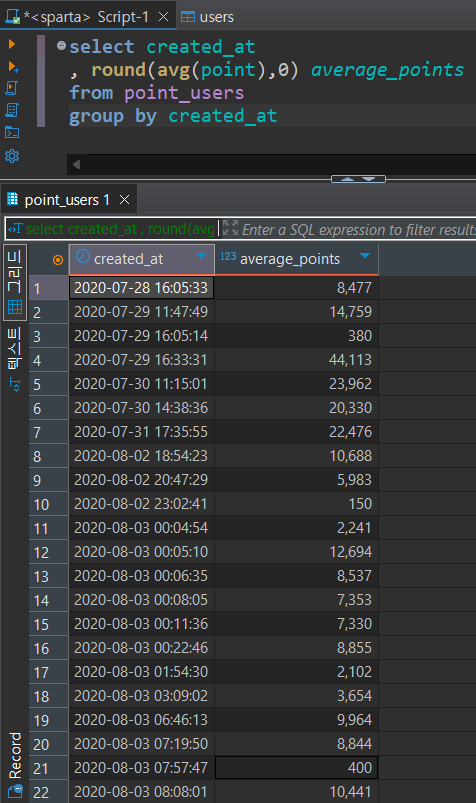
잉..? 그래도 뭔가 이상한데..?😮💦
🔻내가 작성한 코드
select created_at
, round(avg(point),0) average_points
from point_users
group by created_at🔻스파르타 정답 코드
SELECT
DATE(p.created_at) AS created_at,
ROUND(AVG(p.point)) AS average_points
FROM
point_users p
GROUP BY
DATE(p.created_at);🔹 두 코드의 차이점
📌 DATE() 함수를 사용해서 날짜형식으로 바꿔줌
아직 DATE()함수가 익숙하지 않은 것 같다 ㅠ 답안을 보고는 생각이 났지만 문제를 풀 때 생각하지는 못했다.
그리고 p.created_at을 하면 더 정확하게 불러올 수 있는 것 같다.
Lv3. 이용자의 포인트 조회하기
문제
user_id: 익명화된 유저들의 아이디
email: 유저들의 이메일
point: 유저가 획득한 포인트
users 테이블에는 있지만 point_users에는 없는 user는 포인트가 없으므로 0 으로 처리
포인트 기준으로 내림차순 정렬
if null 을 사용하려했는데 null이면 0을, null이 아니면 그대로를 어떻게 써야할지 막막했다.
이리저리 써보다가 힌트를 봤는데 coalesce()를 사용해야했다.
참고한 링크_coalesce()
덕분에 정답 그대로 작성할 수 있었다.
select u.name, u.email,
coalesce(p.point,0) point
from users u left join point_users p
on u.user_id=p.user_id
order by p.point descLv4. 단골 고객님 찾기
- 고객별로 주문 건수와 총 주문 금액을 조회하는 SQL 쿼리를 작성해주세요.
a.
출력 결과에는 고객 이름, 주문 건수, 총 주문 금액이 포함되어야 합니다. 단, 주문을 한 적이 없는 고객도 결과에 포함되어야 합니다.
select c.CustomerName CustomerName,
count(o.customerid) ordercount,
sum(o.TotalAmount) totalspent
from orders o left join customers c
on o.customerid=c.customerid
group by o.customerid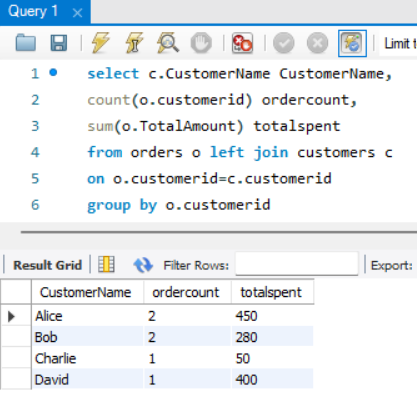
주문이 없는 경우, 총 주문금액을 0으로 처리하는 걸 빠뜨렸다..
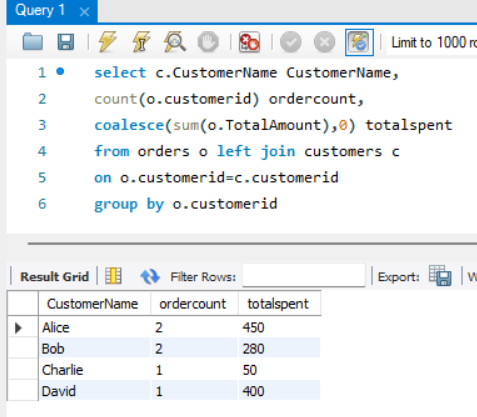
결과 차이는 없었지만, ⭐조건 꼭 챙기기ㅣ~!
#### 문제는 2번이다..
2.
나라별로 총 주문 금액이 가장 높은 고객의 이름과 그 고객의 총 주문 금액을 조회하는 SQL 쿼리를 작성해주세요.
🔻처음 시도
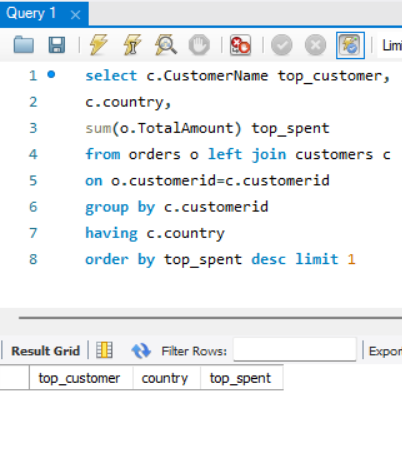
아.,,,,,,,,먼가 이상하고 조건을 더 써야할 것 같긴한데 뭘 써야할지 모르겠었다....
🔻정답 확인
SELECT
c.Country,
c.CustomerName AS Top_Customer,
SUM(o.TotalAmount) AS Top_Spent
FROM
Customers c
JOIN
Orders o ON c.CustomerID = o.CustomerID
GROUP BY
c.Country, c.CustomerName
HAVING
SUM(o.TotalAmount) = (
SELECT
MAX(SumSpent)
FROM
(SELECT
SUM(o2.TotalAmount) AS SumSpent
FROM
Customers c2
JOIN
Orders o2 ON c2.CustomerID = o2.CustomerID
WHERE
c2.Country = c.Country
GROUP BY
c2.CustomerID) AS Subquery
);아니 having 걸고 써야할 게 이렇게나 많았다니... 이건 시간 들여서 다시 분석해봐야할 것 같다..ㅠ 그냥 join은 뭐더라...ㅜ
참고한 링크
HAVING절
추가학습
일단 그냥 join 은 뭐야? 하고 찾아보니,,
JOIN = INNER JOIN
LEFT JOIN = LEFT OUTER JOIN
having 이하를 수정하면 되는데.. having이 집계함수를 불러온다는 것은 알겠다.
나의 첫 번째 의문점.
💫HAVING SUM() = (서브쿼리) 대신 HAVING MAX()를 사용할 수 있는가?
💡 HAVING SUM() = (서브쿼리)가 필요한 이유
💭각 국가별(Country) 총 주문 금액이 가장 높은(MAX()) 고객을 찾아야한다
총 주문 금액(TotalAmount)은 SUM()을 사용해서 고객별로 계산해야 하며,
그 중에서 MAX()를 사용하여 국가별 최고 금액을 찾아야 한다.
즉, SUM()이 먼저 필요하고, 그 결과에서 MAX()를 비교해야 한다.
나의 두 번째 의문점
💫그렇다면, 서브쿼리에서 SUM(o.TotalAmount) AS ta로 설정하고, 본쿼리에서 HAVING MAX(ta)를 사용하면 안 되는가?
💡 HAVING MAX(ta)가 불가능한 이유
❌ 집계 함수 안에서 또 다른 집계 함수를 직접 사용할 수 없음
SUM(o.TotalAmount) AS ta로 서브쿼리에서 미리 계산했다고 가정.
본쿼리에서 HAVING MAX(ta)를 적용하면 SQL 문법적으로 오류 발생!
HAVING 절에서 MAX(ta)를 사용하면, 각 그룹에서 최대값을 찾는 것이 아니라, 전체 그룹의 하나의 값을 가져오려는 동작이 되기 때문.
집계 함수 안에 또 다른 집계 함수를 직접 사용할 수 없음
따라서having sum() = (서브쿼리)구조를 만들어야함
나의 세 번째 의문점
💫본 쿼리와 서브쿼리에서 둘 다 c.Country를 사용했으므로 WHERE subquery.Country = c.Country 없이도 괜찮지 않나?
✅ 결론: ❌
✔ 본 쿼리와 서브쿼리에서 둘 다 c.Country를 사용했지만, 이들은 각기 다른 스코프(범위)에서 동작하므로 명시적인 연결(WHERE subquery.Country = c.Country)이 필요함.
✔ 이 조건이 없으면, 서브쿼리는 전체 데이터에서 하나의 MAX(total_spent)만 반환하여 원하는 결과가 나오지 않음.
✔ 따라서, 국가별 최고 주문 금액을 정확히 구하려면 WHERE subquery.Country = c.Country가 반드시 필요함! 🚀.
나의 네 번째 의문점
💫 WHERE subquery.Country = c.Country 대신 GROUP BY c.Country, c.CustomerName를 한 번 더 쓰면 해결될까?
✅ 결론: ❌ 해결되지 않음
왜?
GROUP BY는 데이터 그룹을 만드는 역할만 수행하며, 우리가 원하는 "국가별 최고 주문 금액을 가진 고객을 필터링"하는 역할을 수행하지 않음.
GROUP BY를 사용해도 각 국가에서 최고 금액을 가진 고객만을 정확하게 가져오는 기능은 수행하지 않음.
따라서 서브쿼리에서 국가별(Country)로 필터링하는 WHERE subquery.Country = c.Country 조건이 반드시 필요함.
좀..의문점이 많긴 했지만 확실히 이러한 부분위주로 왜 안되는지, 그럼 어떻게 해야하는지를 정리하고 나니까 실마리들이 풀리는 느낌이었다.
이 문제를 with로도 풀 수 있다고 한다
WITH CustomerTotal AS (
SELECT c.Country, c.CustomerName, SUM(o.TotalAmount) AS TotalSpent
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
GROUP BY c.Country, c.CustomerName
)
SELECT ct.Country, ct.CustomerName, ct.TotalSpent
FROM CustomerTotal ct
WHERE ct.TotalSpent = (
SELECT MAX(TotalSpent)
FROM CustomerTotal
WHERE Country = ct.Country
);이런식으로 말이다.
with도 공부하고 나서 이문제를 다른 방식으로 다시 접근해봐야겠다.
이 문제를 리뷰하는데 시간이 많이 걸려서 달리기반 lv.5는 내일 해야할 것 같다
느낀점
생각보다 lv4.2번문제에서 시간을 많이 써서 문제를 많이 못푼 것 같은데,
저녁시간을 활용해서 2번 오답이랑 추가 문풀을 진행해야겠다..
내일 북스터디 하는데 나만 아는게 없으면 안되니까는... 열심히 해야겠다아 ㅠㅠ
다른 팀원분들이 벨로그 깔끔하게 잘 작성하시길래 나도 시리즈물로 정리해봤는데!
이게 훨씬 나은 듯 하다.
앞으로도 열심히 TIL을 써야지~! 😊🔥
