📕 북스터디
,
🔻분석 전
1️⃣데이터 분석 문제 정의
- 분석 배경
: [내가 보스턴으로 이사를 하려는 상황이라고 가정]
✅ 금액은 해당지역의 집값 중간 이하로 희망하며,
✅ 여자 혼자 살기에 범죄율도 중요한 조건
✅ 자택당 평균 방 개수는 상관 없으며, 1940년 이후에 건설된 집을 선호
✅ 지역에 상업 비즈니스가 활발했으면 좋겠음
✅ 고용센터와도 가깝다면 더욱 좋음.
(위-아래 순서대로 우선순위임)
- 목적
우선순위에 가장 적합한 지역 찾기
.
.
🔻분석 실행
1. 평가 지표 및 기준을 결정
어떤 요소와 지표가 더욱 목적에 부합하는가?
2️⃣사용한 데이터
- 보스턴 시의 주택 가격에 관한 데이터. 주택 정보, 근처 환경 정보 등이 포함 됨.
2.수집한 데이터의 형식과 속성
- TOWN(object) : 지역 이름
- CMEDV(float) : 해당 지역의 집값(중간값)
- CRIM(float) : 근방 범죄율
- AGE(float) : 1940 년 이전에 건설된 비율
- INDUS(float) : 상업적 비즈니스에 활용되지 않는 농지 면적
- DIS(float) : 5 개의 보스턴 고용 센터와의 거리에 다른 가중치 부여
2. 적합한 데이터 및 그래프를 선택
어떤 데이터 형태와 그래프가 효과적인가?
3️⃣데이터 살펴보기
기초 통계량 분석
표본 크기, 평균 등 기초통계량을 분석해봐요
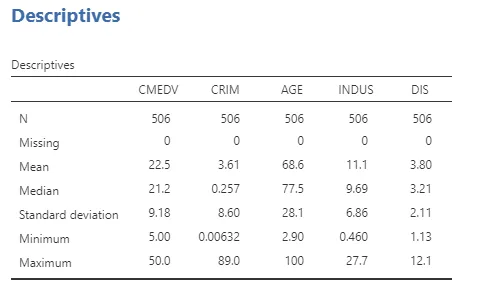 📌집값 (CMEDV)
📌집값 (CMEDV)
:평균과 중간값의 차이는 크게 존재하지 않지만,
최솟값: 5.0, 최댓값: 50.0, 표준편차: 9.18 를 봤을 때 → 지역별 가격 편차 큼
📌 범죄율 (CRIM)
:평균 3.61과 중간값 0.257 의 차이가 큼. → 범죄율이 낮은 지역이 상대적으로 더 많음
하지만 평균을 3.61로 올릴만큼의 극단적으로 범죄율이 높은 지역도 존재함을 알 수 있음
📌 건축연도 기준 (AGE)
age값이 높을수록 1940 이전 건설 비율이 높다는 의미인데,
평균적으로 약 70%에 가까운 집들이 1940 이전에 건설됨. 나는 age값이 낮은 지역을 보는 것이 유리함
📌 상업적 비즈니스 지역 비율 (INDUS)
평균 11.1 중앙값 9.69 이며, 상업적 활동이 많은 곳을 선호하기에 해당 값이 낮은 지역을 찾는게 좋음
📌 고용센터까지 거리 (DIS)
평균 3,80 중앙값 3.21 로 보아, 고용센터와 가까운 지역을 선택하기 위해서 DIS값이 3.21 이하인 곳이 적합함
.
.
.
4️⃣데이터 분석하기 - 기술통계를 기반으로 한 sql 자료 조회
- sql 이용하기
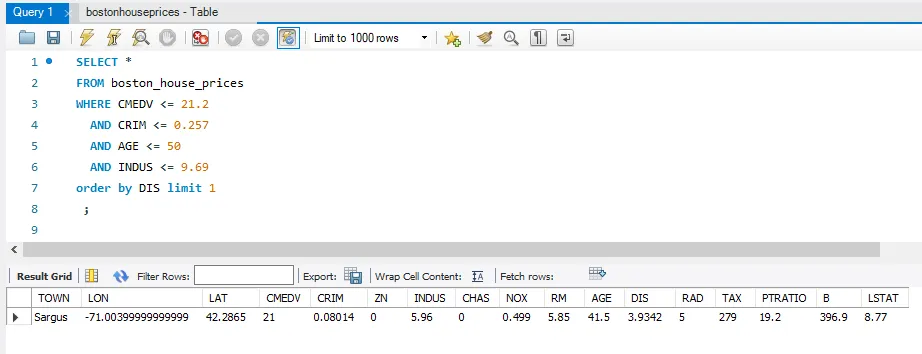
평균과 중간값을 고려해서 최종적으로 선별조건을 작성했다.
SELECT *
FROM boston_house_prices
WHERE CMEDV <= 21.2
AND CRIM <= 0.257
AND AGE <= 50
AND INDUS <= 9.69
AND DIS <= 3.21;이렇게 실행하면, 조건에 맞는 지역은 0개이다. 조회되지 않는다. 따라서 가장 마지막 우선순위인 DIS 조건을 바꾸고 실행하였다.
🔻최종쿼리
SELECT *
FROM boston_house_prices
WHERE CMEDV <= 21.2
AND CRIM <= 0.257
AND AGE <= 50
AND INDUS <= 9.69
;
.
🔴한계점
select *
from boston_house_prices
order by CMEDV,
CRIM,
AGE,
INDUS,
DIS ; 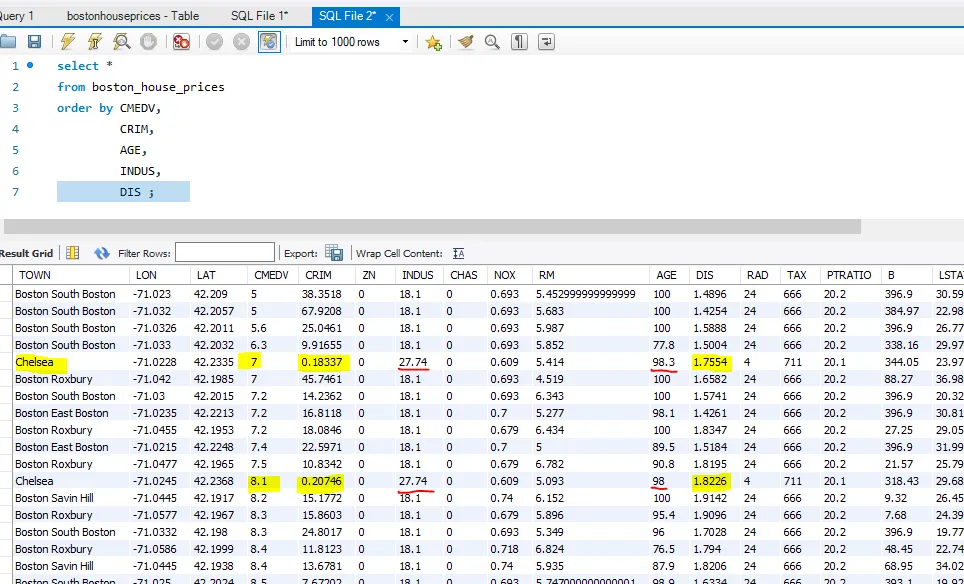 나는 단순히 평균/중간값 이하, 오름차순 정렬 정도로 필터링하여 지역을 찾았었는데,
나는 단순히 평균/중간값 이하, 오름차순 정렬 정도로 필터링하여 지역을 찾았었는데,
위결과에서 볼 수 있듯이, 1,2 순위에 해당하는 조건이 상당히 좋고 몇가지 조건만이 고려범위 밖이라는 것을 알 수 있다.
따라서, 개별항목과 값에도 가중치를 매기고 복잡한 비교를 수행했었다면 다른 지역이 최종 후보지가 될 수도 있겠다는 생각이 들었다.
4️⃣데이터 분석하기 -2. 상관관계 분석
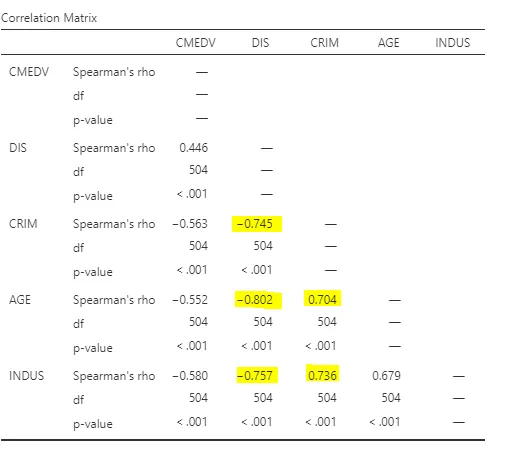
- 종합분석 (강한 상관관계 위주로 정리)
 (고용센터가 도심에 있나..?)
(고용센터가 도심에 있나..?)
.
.
🔻분석 후
3. 결론
결국 무슨 말을 할 수 있는가?
5️⃣결과 해석해보기
🔑데이터 분석하기 - 기술통계를 기반으로 한 sql 자료 조회
분석 목적을 고려하여 최종 결정을 내린 지역은 Sargus 지역임.
🔑데이터 분석하기 -2. 상관관계 분석
- DIS(거리)와 CRIM(범죄율) → -0.745 (강한 음의 상관관계) → 거리가 멀어질수록 범죄율이 낮아지는 경향이 매우 뚜렷함.
- DIS(거리)와 AGE(건물 연식) → -0.802 (강한 음의 상관관계) →거리가 멀어질수록 오래된 건물이 적고, 신축 건물이 많아지는 경향이 있음.
- DIS(거리)와 INDUS(산업 비즈니스 비율) → -0.757 (강한 음의 상관관계) →거리가 멀어질수록 산업 비즈니스 비율이 낮아지는 경향이 매우 뚜렷함.
- CRIM(범죄율)과 AGE(건물 연식) → 0.704 (강한 양의 상관관계) →오래된 건물이 많을수록 범죄율이 높아지는 경향이 있음.
- CRIM(범죄율)과 INDUS(산업 비즈니스 비율) → 0.736 (강한 양의 상관관계) →산업 비즈니스 비율이 높을수록 범죄율도 높아지는 경향이 강함.
💥범죄율은 산업 지역 비율과 건물 연식이 높을수록 증가하는 경향을 보임.
💥거리가 멀어질수록 산업 지역과 오래된 건물 비율이 낮아지고 범죄율도 감소하는 특징이 있음.
2.인사이트 도출
💡
나는 단순히 평균/중간값 이하, 오름차순 정렬 정도로 필터링하여 지역을 찾았었는데,
위결과에서 볼 수 있듯이, 1,2 순위에 해당하는 조건이 상당히 좋고 몇가지 조건만이 고려범위 밖이라는 것을 알 수 있다.
따라서, 개별항목과 값에도 가중치를 매기고 복잡한 비교를 수행했었다면 다른 지역이 최종 후보지가 될 수도 있겠다는 생각이 들었다.
💡💡
상관관계 분석을 통해 도출해낸 결과를 토대로, 지역을 선택하는 우선순위를 수정해봐도 좋을 것 같다는 생각이 들었다.
그리고 거리라는 요인이 다른 요인과 유의미한 상관관계를 보이는 것이 많았는데, 자료 정의에는 고용센터와의 거리로밖에 나와있지 않다. 따라서 이부분에 대한 추후 탐색이 더 필요해보인다.
.
.
.
sql 달리기반
아ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ join을 여러번 쓸 수 있다는 사실을 ..깜빡했어..........
혼자 having절도 써보고 subquery도 써보고..무튼 그러다가 오류가 발생했다.
오류원인
🚨OrderCount는 s 서브쿼리에서 정의되지 않음 → 존재하지 않는 컬럼을 HAVING에서 사용.
🚨SUM(OrderCount)을 사용했지만 OrderCount는 s 서브쿼리에서 계산되지 않음.
🚨서브쿼리는 여러 행(CustomerID, CustomerName, OrderCount)을 반환하지만, HAVING에서는 단일 값만 필요.
즉, 서브쿼리 결과가 다중 행이므로 HAVING 절에서 비교 불가
고민하던 중 예전에 한 번 스쳐본듯한 with를 알아보기로 했다.
📌 WITH 절 (Common Table Expression, CTE)
✅ WITH 절이란?
- SQL에서 임시 결과 집합(테이블)을 만들어 재사용하는 기능.
- 복잡한 쿼리를 가독성 높게 구조화하는 데 유용함.
✅ 사용 형식
WITH CTE_Name AS (
SELECT 컬럼명 FROM 테이블명 WHERE 조건
)
SELECT * FROM CTE_Name;
ex.
WITH HighSalary AS (
SELECT Name, Salary FROM Employees WHERE Salary > 80000
)
SELECT * FROM HighSalary;
▶️```Employees```에서 급여가 높은 직원만 추출하여 활용 가능!✅ 주요 활용
- 반복 사용되는 서브쿼리 정리
- 재귀 쿼리(Recursive Query) 구현
- 가독성 개선 및 성능 최적화
무튼 이건.. 따른
WITH CustomerOrders AS (
SELECT c.CustomerName, COUNT(o.OrderID) AS OrderCount
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID
GROUP BY c.CustomerName
),
ProductSales AS (
SELECT c.CustomerName, SUM(o.Quantity) AS Total_Quantity, o.ProductID
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID
GROUP BY c.CustomerName, o.ProductID
)
SELECT ps.CustomerName, (p.Price * ps.Total_Quantity) AS Total_Amount
FROM ProductSales ps
JOIN Products p ON ps.ProductID = p.ProductID
JOIN CustomerOrders co ON ps.CustomerName = co.CustomerName
HAVING co.OrderCount = (SELECT MAX(OrderCount) FROM CustomerOrders);
.
.
느낀점
북스터디를 하고 난 뒤 서로의 발표를 들었는데,
책이나 아티클을 단순히 읽고하는는 것보다,
각자 자유롭게 다양한 관점에서 나름대로 분석을 해보고 과정,결과,피드백을 공유했던 오늘의 발표 시간이 가장 유익했던 것 같다.
내일은 타이타닉 생존자 데이터분석을 진행하는데, 도메인까지는 아니더라도 관련 자료를 찾아봐 이해를 어느정도 해놓고 시작한다면, 더 나은 분석을 해낼 수 있을 것 같다 !
진짜진짜 본캠프가 얼마 남지 않았는데 .. 마음의 준비를 단단히 해야겠다~!
