코드카타
SQL
- 아직 입양을 못 간 동물 중, 가장 오래 보호소에 있었던 동물 3마리의 이름과 보호 시작일을 조회하는 SQL문을 작성해주세요. 이때 결과는 보호 시작일 순으로 조회해야 합니다.
SELECT ai.name, ai.datetime
from animal_ins ai
left join animal_outs ao
on ai.animal_id=ao.animal_id
where ao.animal_id is null
order by ai.datetime
limit 3left join이랑 where 생각해내면 쉽게 풀 수 있는 문제인 것 같다.
알록달록해졌다. 감사한 피드백이다🤗!!
마크다운 꿀팁
- 2022년 1월의 카테고리 별 도서 판매량을 합산하고, 카테고리(CATEGORY), 총 판매량(TOTAL_SALES) 리스트를 출력하는 SQL문을 작성해주세요.
결과는 카테고리명을 기준으로 오름차순 정렬해주세요.
SELECT b.category CATEGORY
,count(date_format(bs.sales_date,'%y-%m')='2022-01') TOTAL_SALES
from book b
join book_sales bs
on b.book_id=bs.book_id
group by b.category
order by b.category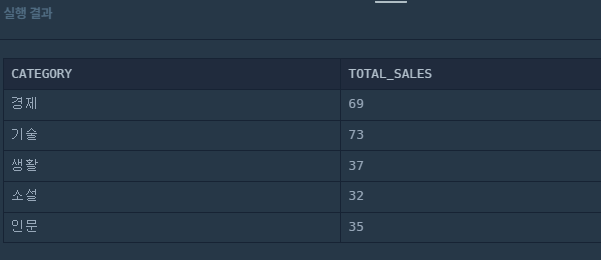
음,, 왜 틀린거지..?
아...........left join !! 내가 그냥 join에 너무 익숙해져있었어,,, 그냥 join=inner join..그리고 합산이라 sum(sales)써줘야하고 ⭐%Y 대문자로 써줘야 4자리가 조회되는 것 같다!!
SELECT b.category CATEGORY
,sum(bs.sales) TOTAL_SALES
from book b
left join book_sales bs
on b.book_id=bs.book_id
where date_format(date(bs.sales_date),'%Y-%m')='2022-01'
group by b.category
order by b.category- PRODUCT 테이블과 OFFLINE_SALE 테이블에서 상품코드 별 매출액(판매가 * 판매량) 합계를 출력하는 SQL문을 작성해주세요. 결과는 매출액을 기준으로 내림차순 정렬해주시고 매출액이 같다면 상품코드를 기준으로 오름차순 정렬해주세요.
SELECT product_code, sum((price*sales_amount)) sales
from product p
inner join offline_sale o
on p.product_id=o.product_id
group by product_code
order by sales desc, product_code- 관리자의 실수로 일부 동물의 입양일이 잘못 입력되었습니다. 보호 시작일보다 입양일이 더 빠른 동물의 아이디와 이름을 조회하는 SQL문을 작성해주세요. 이때 결과는 보호 시작일이 빠른 순으로 조회해야합니다.
SELECT ai.animal_id, ai.name
from animal_ins ai
join animal_outs ao
on ai.animal_id=ao.animal_id
where ai.datetime > ao.datetime
order by ai.datetime - 입양을 간 동물 중, 보호 기간이 가장 길었던 동물 두 마리의 아이디와 이름을 조회하는 SQL문을 작성해주세요. 이때 결과는 보호 기간이 긴 순으로 조회해야 합니다.
SELECT ai.animal_id, ai.name
from animal_ins ai
join animal_outs ao
on ai.animal_id=ao.animal_id
order by datediff(ao.datetime, ai.datetime) desc
limit 2python
- 정수 num1과 num2가 주어질 때, num1에서 num2를 뺀 값을 return하도록 soltuion 함수를 완성해주세요.
a=num1
b=num2
print(a-b)에.. 머지 이 쉬운걸 왜..🤔
C 언어로 설정되어있었고 Python3 형식에 맞춰서 작성했어야했다
def solution(num1, num2):
answer = num1-num2
return answer통과~
.
2.
정수 num1, num2가 매개변수 주어집니다. num1과 num2를 곱한 값을 return 하도록 solution 함수를 완성해주세요.
solution=lambda num1,num2:num1*num2.
🔺3.
정수 num1, num2가 매개변수로 주어질 때, num1을 num2로 나눈 몫을 return 하도록 solution 함수를 완성해주세요.
solution=lambda num1,num2:num1/num2📌 // 연산자의 특징:
// 연산자는 나눗셈의 몫을 정수로 반환해서
소수점 이하를 버림(내림) 처리해준다solution=lambda num1,num2:num1//num2
🔴4.
머쓱이는 선생님이 몇 년도에 태어났는지 궁금해졌습니다. 2022년 기준 선생님의 나이 age가 주어질 때, 선생님의 출생 연도를 return 하는 solution 함수를 완성해주세요
def solution(age):
answer = 2022-age+1
print(f"2022년 기준 {age}살이므로 {answer}년생입니다.")❌
🔍 오류 원인:
프로그래머스는 print()가 아니라 return을 사용해야 함
그래서 null이 기대값 1983과 다릅니다.라는 오류 메시지가 나온 것.def solution(age): answer = 2022-age+1 return(answer)
- 정수 num1과 num2가 매개변수로 주어집니다. 두 수가 같으면 1 다르면 -1을 retrun하도록 solution 함수를 완성해주세요.
def solution(num1, num2):
return 1 if num1== num2 else -1파이썬을 ..안쓴지 좀 됐더니 if를 쓸 수 있는지 없는지 조차도 헷갈려서 좀 구글링했다. 그래서 그런지 검색찬스(?)로 쉽게 풀 수 있었다.
(1을 반환해/ 만약 num1과 num2가 같다면/ 그밖엔 -1)
💫추가 개념
num1 == num2 -> 같다
num1 != num2``` -> 같지 않다.
.
아티클스터디
오늘의 아티클
직관적인 데이터 시각화 만들기
-
시각화가 왜 중요할까? → 직관적인 데이터 시각화 방법
시각정보를 처리하는 과정
콜린 웨어(Colin Ware) 박사 : 우리 뇌는 3단계로 시각 정보를 처리한다.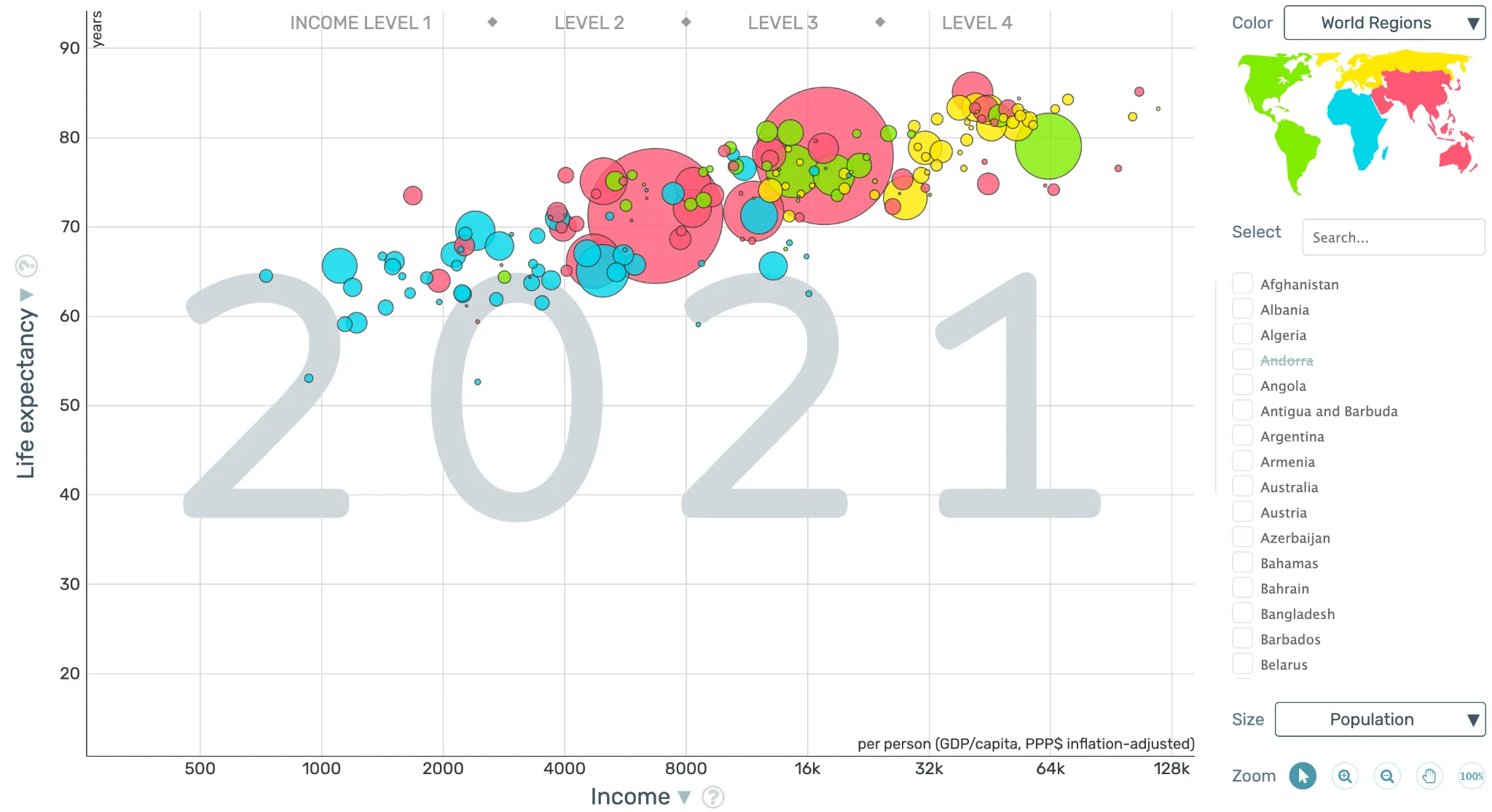
1단계: 뚜렷한 시각 요소 파악하기
시각정보 → 눈(신경세포)→뇌
신경세포들이 색,질감,선 두께 등 기본적인 시각 요소들을 추출하고,
뚜렷한 시각요소들은 감각 기억에 저장. (ex. 색-빨,파 / 형태-원)2단계: 패턴 알아차리기
추출된 시각요소들의 공통점과 차이점 발견
더 구체적으로, 동일한 색이나 질감, 방향성 등에 따라 그룹으로 분류하며 패턴을 인식 (ex. 동일 색인 원들 : 같은 그룹이겠구나 !, 파란색 원들: 왼쪽 아래에 모여있네?)3단계: 해석하기
추출 시각요소+인지한 패턴 = “뇌: 능동적 의미부여 & 해석”
(ex. 텍스트-이미지 연결하여 해석, 이미 가지고있는 정보를 바탕으로 한 새로운 의미부여와 정보 찾기
🔻-
원의 사이즈는 인구수를 의미,
-
아시아 지역에 많은 인구 수를 가진 두 나라가 존재하며 이는 아마도 중국과 인도일 것,
3.파란색의 아프리카 그룹은 소득이 적으며 기대수명도 적은 걸 알 수 있음)전주의적 속성 이해하기
1단계에서 보자마자 빠르게 시각요소를 추출할 수 있는 이유
➡전주의적 속성(Preattentive attributes) 때문!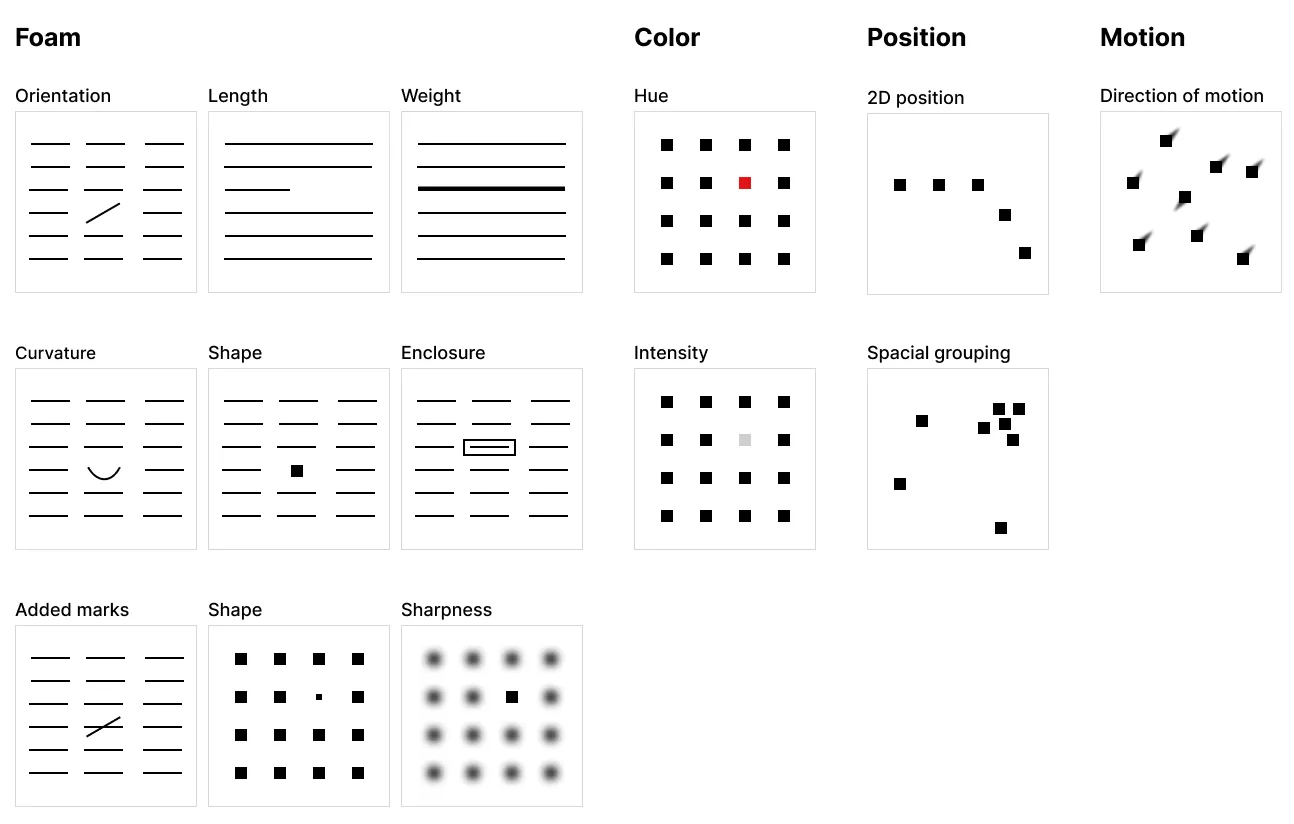
직관적인 데이터 시각화는 이러한 전주의적 속성을 의도적으로 사용
전주의적 속성을 사용한 예시들
🔻지진 데이터
두 개의 큰 지진이 16,000개 이상의 다른 지진을 촉진시켰다는 정보를 전달
따라서 두개의 큰 지진을 강조.
이후에, 전체 지진을 날짜,그기별로 배열 및 지진 크기에 따른 원의 크기&색 디자인.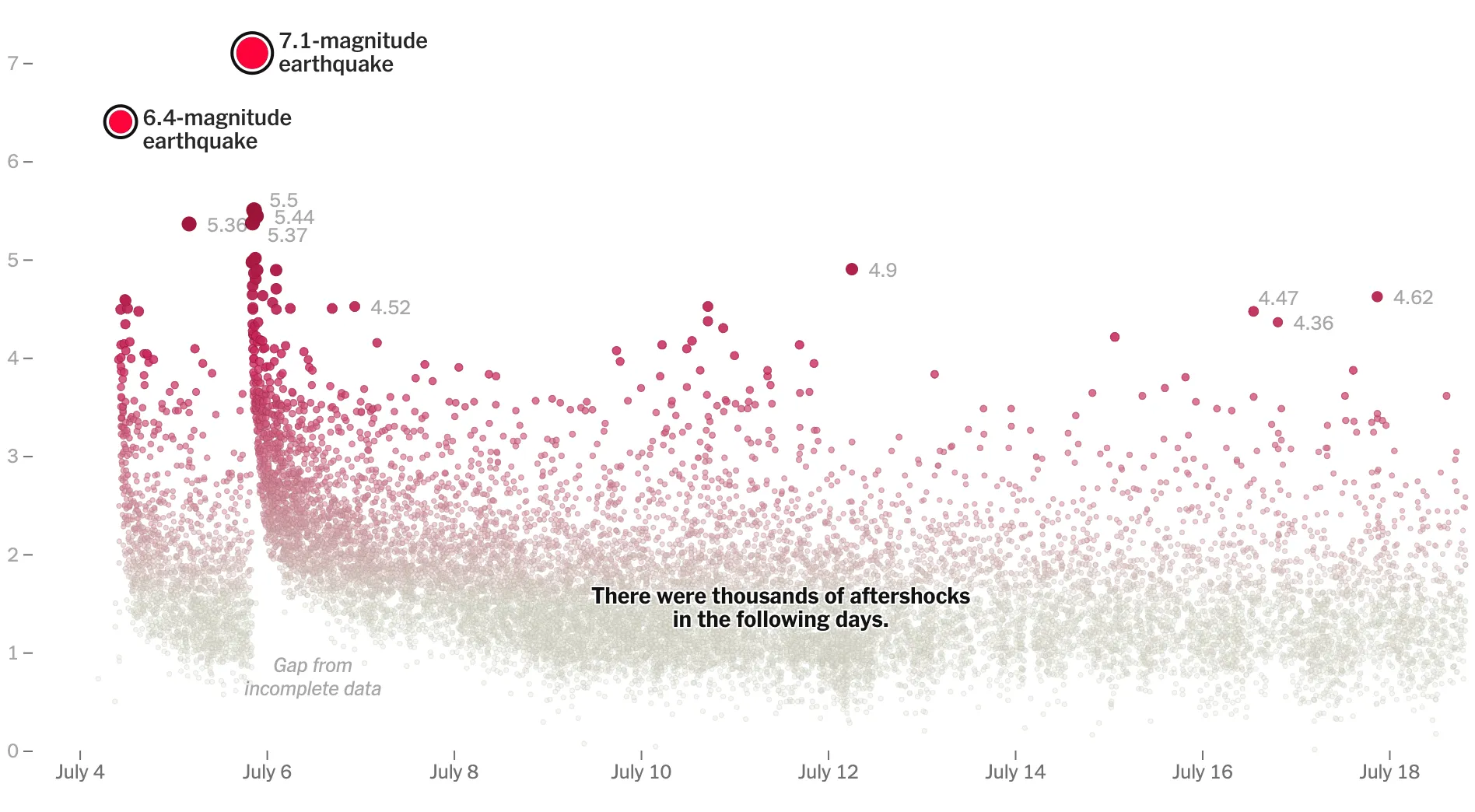
🔻백신의 효과
굵은선 → 백신이 소개된 시점을 강조,
붉은 색, 푸른색→ 확진자 수의 많고 적음
따라서, 백신 소개된 이후 확진자 수가 급감했음을 알 수 있음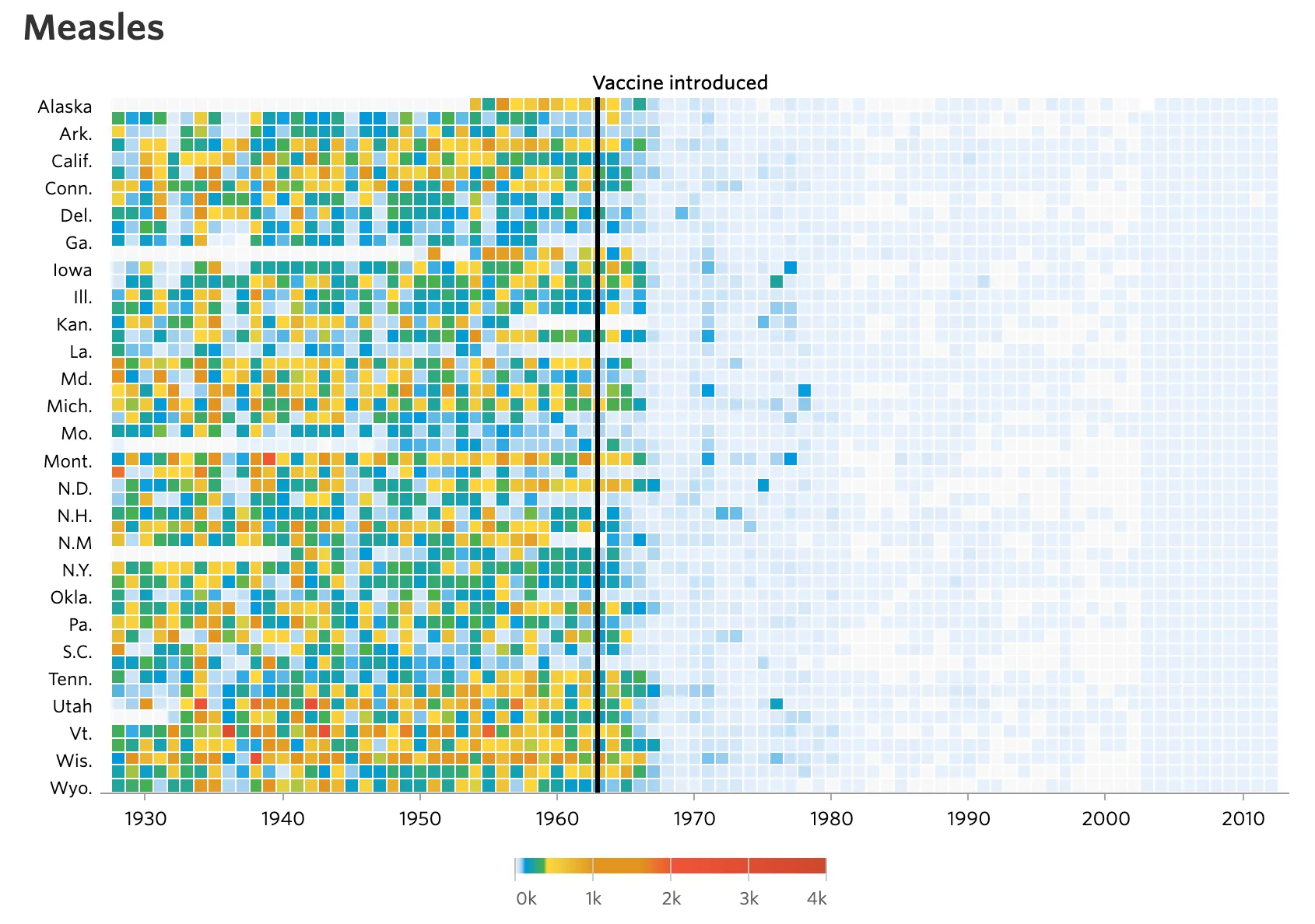
-
그러나, 너무 많은 속성들을 사용하지 말아야하고 실제 의도한 대로 되는지 테스팅!
게슈탈트 원리를 바탕으로 한 디자인
2단계::패턴을 찾는 것은, 우리의 뇌가 사물의 형태를 지각하는 원리를 정리한 게슈탈트 원리를 적용해볼 수 있다.
By 게슈탈트 원리,
우리의 뇌는 사물을 구성 요소로 분해하는 것보다 큰 전체를 이해하는 데 탁월. 그리고 특정 규칙이 적용될 때 요소들을 연관된 하나의 그룹으로 인식
- 가까이 위치하기
가까이 있을 수록 연관성 부여 up (점차 양극화 현상이 벌어지는 상황을 설명할 때 good)- 비슷한 특징가지기
비슷한 붉은색이더라도, 각 색상의 밝기와 텍스처 별로 그룹화 하여 인식할 수 있음. ( 오미크론 BA.4와 BA.5가 얼마나 우세한 지 보여줄 때, 동일한 변이의 확산을 보여주기 위해 공통적으로 붉은 색을 사용하되, 정도의 차이를 보여주기 위해 밝기와 텍스처를 다르게 사용)- 같은 방향으로 움직이기
공동 운명(common fate)원리와 관련있는데,
같은 방향으로 움직이는 요소들은 움직이지 않거나, 서로 다른 방향으로 움직이는 요소들에 비해 더 연관되어 보인다. (시계열 데이터를 표현하기 좋음)- 연결하기
균일한 연결의 원리 → 시각적으로 연결된 요소들은 연결되지 않은 요소들에 비해, 더 연관성이 있는 것처럼 인지됨.
시각정보 처리 과정을 이해하기
1,2단계에서 추출되는 시각 정보들을 의도적으로 디자인
→ 해석 단계에 도움
직관적으로 이해된 시각화가 부정확한 정보를 전달하기도 하고, 시각적으로 오해를 불러일으키기도 함.
.
.
실무적용사례
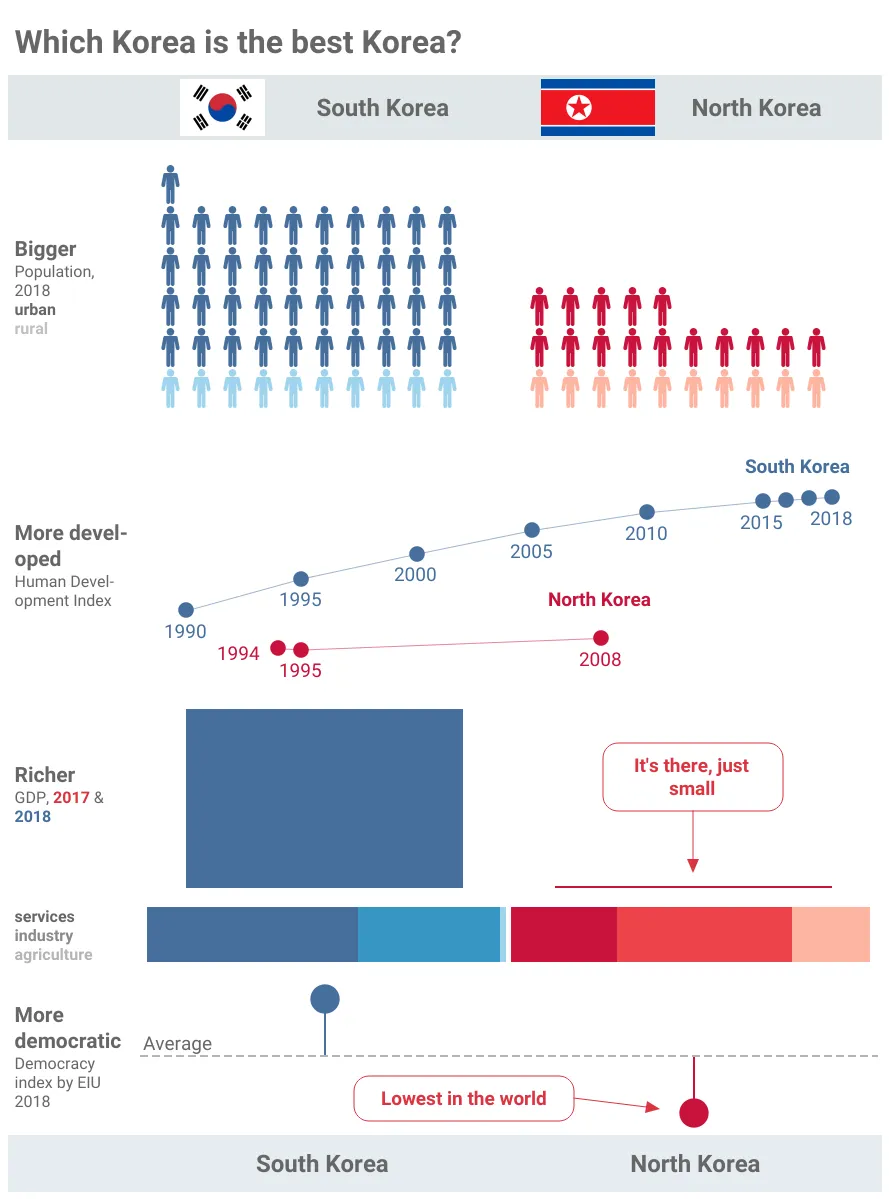
- 관련 사례 : 남한과 북한을 Demographic하게 시각화 해 둔 자료 인데,
오늘 배운 전주의적 속성과 게슈탈트 원리가 잘 반영된 것 같아 선정해보았다.
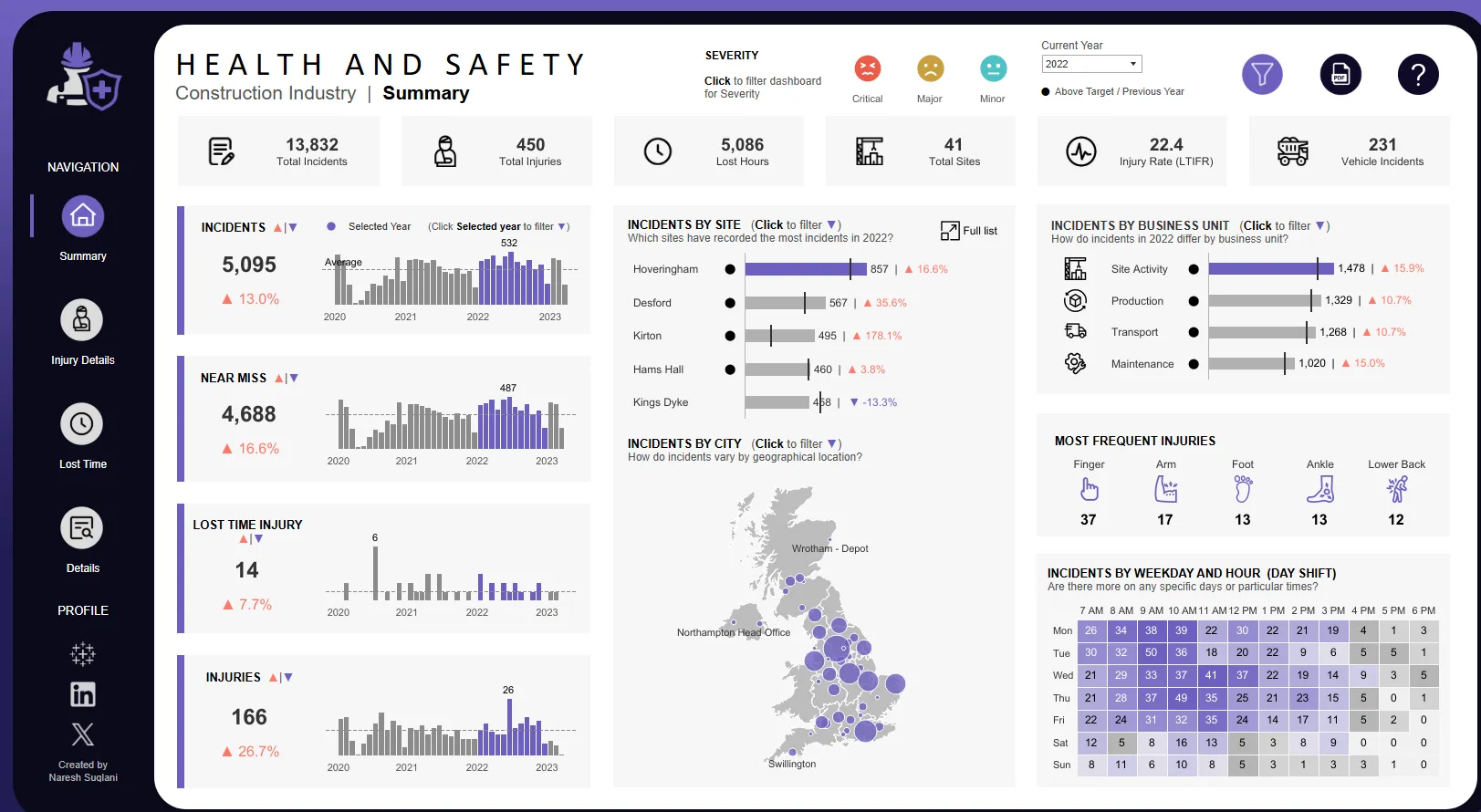
- 가상 시나리오 : 내가 헬스케어회사에서 건강데이터 기반으로 시각화 자료를 만든다면? 아래 차료처럼(세부 정보들은 다르긴함)
지역별로, 어떤 지역이 가장 활성화가 많이 될지, 같은 서울이더라도 어느 지역에서 이용차이가 나는지, 그 지역의 인구특성은 무엇이기 때문에 그럴지,
이것에 대한 구체적 정보를 옆 세부 그래프로 제시(사진 왼쪽처럼).
🔻by Naresh Suglani
인사이트
시각화 속성별, 실제 시각화 사례들이 첨부되어 이해를 빨리 할 수 있었다. 해석이 3단계를 거쳐 일어나고, 전주의적 속성을 가진 예시들, 게슈탈트 원리를 이용한 디자인들을 알 수 있었다. 1,2단계에서 전주의적 속성을 바탕으로 직관적 이해를 빠르게 할 수 있는 디자인을 고안하고, 3단계인 해석 단계에서 게슈탈트 원리를 이용해 시각화를 해본다면 효과적일 것이라 생각한다.
나중에 내가 직접 시각화를 해볼 때, 좋은 참고 자료가 될 것 같아서 더 열심히 요약정리를 해두었다. (나온 사례들 중 백신 효과 사례가 가장 직관적 이해가 빨랐는데, 나는 굵은 구분선과 밝기의 차이를 가장 빠르고 중요하게 인식하는 듯 하다)
어제 직무세션에서 강아지의 안구질환에 대한 어플을 만드시고, 이에 사용한 시각화디자인을 직접 보여주셨는데, 그 디자인에도 오늘 배운 속성들이 사용되고 있었음을 다시한 번 깨달을 수 있었다.
아마, 여러 시안이 나왔을 것이고 여러번의 수정을 거쳤을 텐데, 한번에 적절한 디자인이 나오기 힘들것이다. 왜냐하면 주의점에서도 언급된 것처럼, 사람마다 이해 과정에서 차이가 있을 수 있기 때문에, 유저테스팅의 중요성에도 공감할 수 있었다.
발표자료 제작
우리는 각자 제작했다. (사실상 내일 발표 스포다)
그리고 발표도 내가한다(?)





직무세션
사실 이건 느낀점에 적어야할 것 같긴한데...(직무세션을 들을 때마다 느끼는거지만.. 배운다도있지만 ..감탄하는 느낌이 큼)
AARRR FUNNEL이 나왔는데 ㅋㅋㅋ 익숙해서 깜짝놀랐다. 경영학&마케팅 용어인 줄 알았는데 데이터분석업계에서도 쓰이는 게 신기했다.
또한 대안데이터가 되게 흥미로운 개념이었다. 인스타그램, 위치, 구매이력 etc가 신용평가에 쓰일 수 있다니..!
그리고 정윤성 튜터님이 채용공고 링크를 모아주신 것이 내가 이커머스 도메인을 준비하며 방향성을 잡는데 많은 도움이 될 것 같다. 내 희망 계열을 고려해본다면, 이준수 튜터님과 정윤성 튜터님을 자주 찾아뵈어야겠다(아마 나중에 프로젝트를 하며 많이 찾아뵙게되지않을까)
그리고 이 부트캠프에서 좋은 결과물을 만들어내신분들이 수상까지 하는 것을 보니, 최종 프로젝트에 더욱 욕심이 생겼다. 좋은 팀원들과 함께 할 수 있었음 좋겠다.🙏
느낀점& 내일계획
오늘 우리 조에 새로 오신 분이 계셔서 어쩌다 (소프트)온보딩을 내가 하게됐다(?).
내일이 발표라서 급하게 이것저것 알려드려야 했다..! 신선한 기분...!
그리고 아티클 스터디를 할 때, 사전캠프 때 처럼 인사이트를 적는 곳이 없어서 서로 인사이트를 기억하기도 어렵고 내가 하고싶었던 말을 다 기억해서 하기도 어려워서, 각자 토글을 만들어 드리고 그곳에 작성했다.
이렇게 하니까 팀원 인사이트를 3배 이상의 분량으로 남겨놓을 수 있었다. 분량이 늘어난 만큼, 서로의 의견을 충분히 알아볼 수 있어서 아티클스터디가 더욱 의미있어진 것 같다.
나는 이제 대본을 최종적으로 마무리 짓고 자야겠다 ~
내일까지 화이팅 해서 첫주를 잘 마무리 짓자 ~~ !!!
-내일계획
09:00~ 코드카타, 최종 대본 (팀)슬랙 보내놓기
09:50~ 데일리스크럼
10:00~ sql 라이브세션
11:00~ 개인스터디
14:00~팀스터디 발표회
15:30~ 개인스터디
20:00~ 팀_주간회고,데일리스크럼, TIL 작성
