코드타카
오늘은 sql+python 합해서 5문제 풀기로.
sql
- PATIENT, DOCTOR 그리고 APPOINTMENT 테이블에서 2022년 4월 13일 취소되지 않은 흉부외과(CS) 진료 예약 내역을 조회하는 SQL문을 작성해주세요. 진료예약번호, 환자이름, 환자번호, 진료과코드, 의사이름, 진료예약일시 항목이 출력되도록 작성해주세요. 결과는 진료예약일시를 기준으로 오름차순 정렬해주세요.
SELECT a.apnt_no, p.pt_name, p.pt_no, d.mcdp_cd, d.dr_name, a.apnt_ymd
from doctor d
join appointment a
on a.mddr_id=d.dr_id
join patient p
on a.pt_no=p.pt_no
where date_format(apnt_ymd, '%Y-%m-%d') = '2022-04-13'
and d.mcdp_cd='CS'
and a.APNT_CNCL_YN='n'
order by a.apnt_ymd순차적으로 join 이 돼서 2번째로 쓴 테이블이 가운데에 있나보다.
이 사실을 미리 기억했었다면, 더 빠르게 문제를 풀 수 있었을 텐데 !
python
- 자연수 n이 매개변수로 주어집니다. n을 x로 나눈 나머지가 1이 되도록 하는 가장 작은 자연수 x를 return 하도록 solution 함수를 완성해주세요. 답이 항상 존재함은 증명될 수 있습니다.
def solution(n):
for x in range(1,n):
if n % x == 1:
return x가장 작은 x를 찾는 조건때문에 떠올리기 너무 막막했는데, 검색찬스를 이용하긴 했지만 이해 안가는 부분은 없었다.
n-1까지 반복하는데, x가 n-1까지 반복문을 거치면, 최소 1개의 x값이 존재하게되고,
n=10라면, 9보다 작은 3이라는 숫자가 있기 때문에 1부터 반복하게 만들어야 가장 작은 x 를 구할 수 있을 것이다.(내가 이해한 내용)
(수학 안한지 너무 오래돼서 힘들다...)
- 함수 solution은 정수 x와 자연수 n을 입력 받아, x부터 시작해 x씩 증가하는 숫자를 n개 지니는 리스트를 리턴해야 합니다. 다음 제한 조건을 보고, 조건을 만족하는 함수, solution을 완성해주세요.
- 오답원인
: for 반복문을 먼저 쓰느라,
answer = for ~~~ 이렇게 됐는데, 이게 문법에 어긋나서였다. - 알게된 점
: 꼭 for 반복문이 수식 앞에 먼저 와야하는 건 아니구나 !
for문 리스트 컴프리헨션의 기본 구조⭐⭐⭐
[표현식 for 변수 in 반복 가능한 객체]
🔻최종 수정쿼리
def solution(x, n):
answer = [x*i for i in range(1,n+1)]
return answer- 자연수 n을 뒤집어 각 자리 숫자를 원소로 가지는 배열 형태로 리턴해주세요. 예를들어 n이 12345이면 [5,4,3,2,1]을 리턴합니다.
def solution(n):
answer = [ n for n in str(n) ]
return answer여기까지 적었는데.. -1로 반대방향 해야하는 것까지도 알겠는데.. 그걸 어디에 어떻게 쓰지??
.
.
이리저리 시도해보다가 구글링!
🤷♀️ 2가지 방법을 찾았다.
1.[::-1]
[n for n in str(n)[::-1]]
2.reserved()
[n for n in reversed(str(n))]
❌그러나, 한가지가 오류가 더 있었다..
문자열로 바꿔서 출력이 "5","4" .. 이런식으로 됐다.
그래서 int()를 한번 더 써줬다..
def solution(n):
return [int(i) for i in str(n)[::-1]]cf.
def solution(n):
answer = [int(i) for i in str(n)[::-1]]
return answer이렇게 작성하면 프로그래머스 작동환경 때문에 실행이 안되는 듯 하다
(비효율적임을 느끼고 답안을 제출한 뒤 다른사람의 풀이를 봤다.)
🔻
def digit_reverse(n):
return list(map(int, reversed(str(n)))) map을 활용한 풀이 같은데, map을 까먹어서
종합반 강의를 들으며 다시 복습한 뒤, 이 문제를 다시 풀어봐야겠다 !!
- 문자열 s를 숫자로 변환한 결과를 반환하는 함수, solution을 완성하세요.
def solution(s):
answer = int(s)
return answer한번에 쉽고 빠르게 풀어서
덕분에 정신건강이 해로워지지 않고 마무리할 수 있었다.
.
.
라이브세션
💡union (a.k.a 쌍둥이)
# union/union all 기본구조
# 컬럼 순서가 같고, 그 형식이 같아야 함
select 컬럼1, 컬럼2, 컬럼3..
from 테이블명1
union (all) #수직결합 명시
select 컬럼1, 컬럼2, 컬럼3..
from 테이블명2 📌• 열의 갯수와 순서가 모든 쿼리에서 동일해야 한다.
• 두 테이블의 컬럼 이름이 일치해야 한다.
-> 다르다면? as 로 이름 맞춰줘야한다 !!
as 사용해서 컬럼 이름
• 위 두 가지의 조건을 만족할 경우, UNION 과 UNION ALL 은 2개 이상의 테이블도 결합할 수 있다.
.
.
(조인만 깊게 파다가 코테에서 유니온 틀려오지 말기 ~)
.
💡join
공통컬럼은 꼭 하나가 아닐 수 있다. 여러개도 가능!
🙋테이블A: 나는 이름컬럼과 나이컬럼이 있어.
🙋♂️테이블B: 나는 이름컬럼과 나이컬럼과 국가컬럼이 있어.
.
.
→ 공통컬럼: 이름, 나이
→ 공통컬럼 조건 1개: 이름이 같은 경우를 확인하고 싶은 경우
→ 공통컬럼 조건 2개: 이름과 나이가 같은 경우를 확인하고 싶은 경우
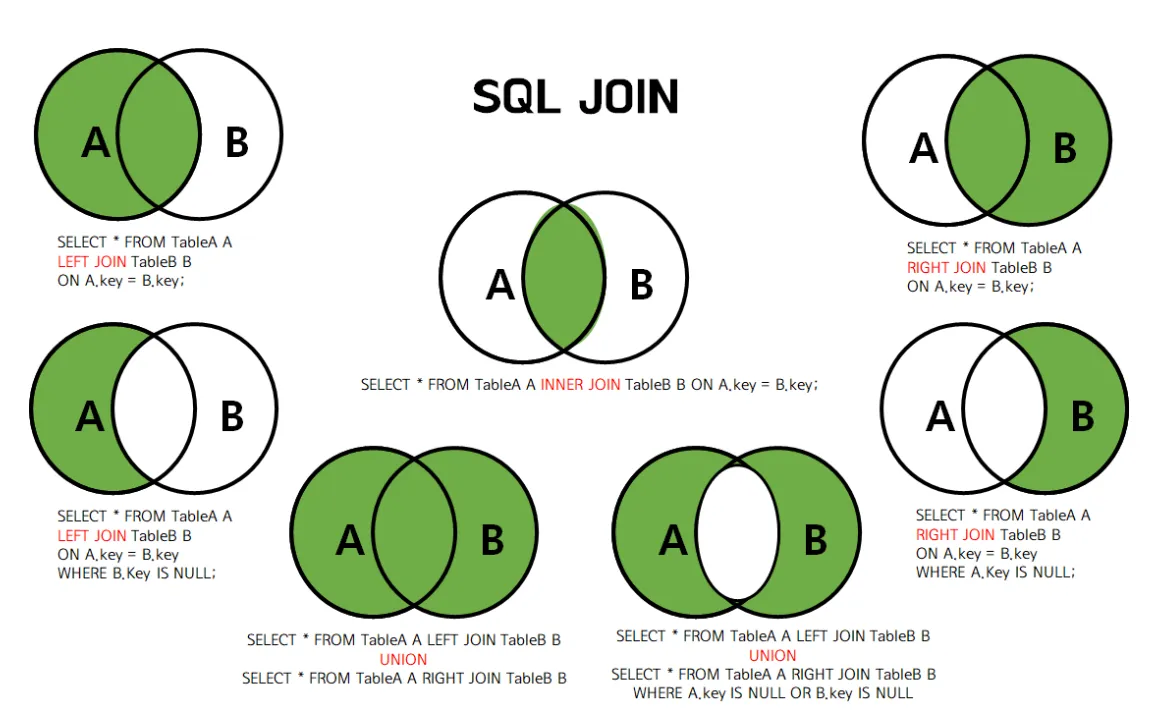
이 그림으로 이해해보면 쉽다.
(left join과 inner join을 가장 많이 사용한다)
기초분석과제
오늘 가장 많이 참고한 자료 !!
datef_format 을 많이 사용했는데, 앞으로 인자들을 다양하게 써보면서 자주쓰이는 건 기억해둬야겠다.

심화분석 + 쓸만한 데이터 정리🔻
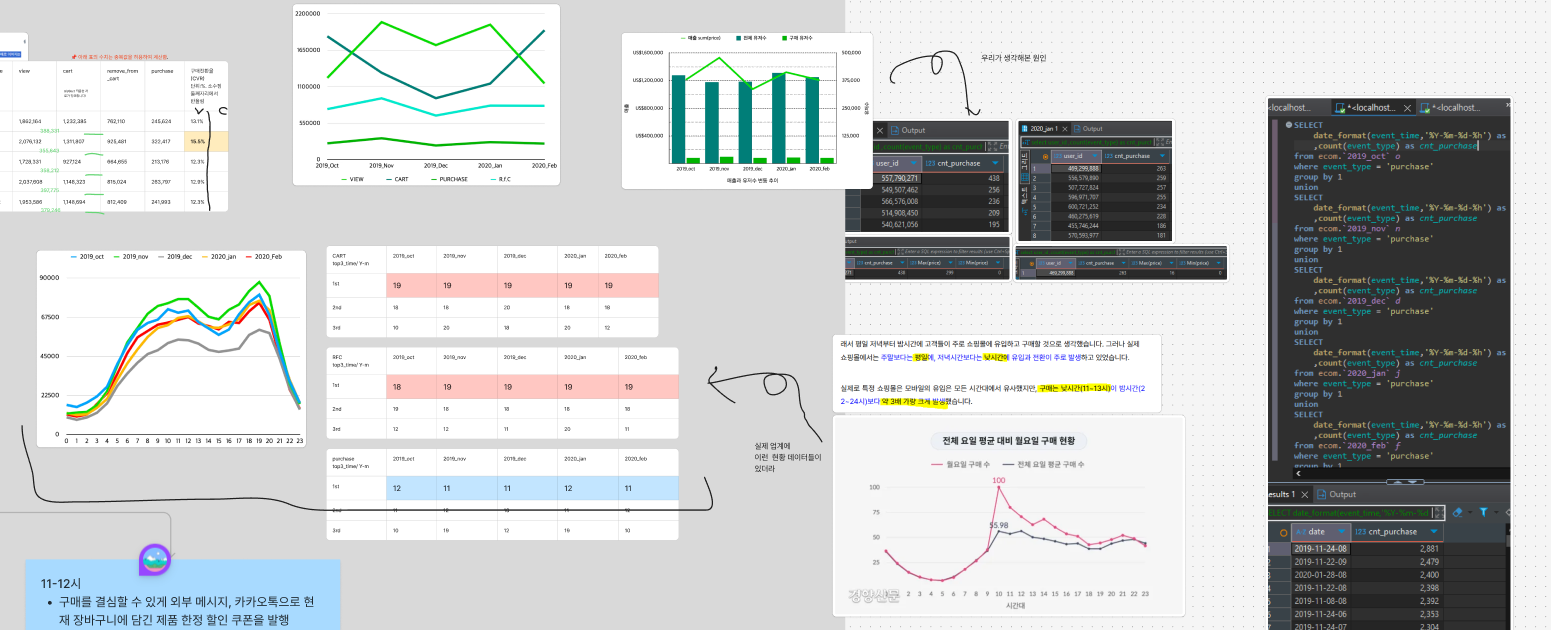
그리고 템플릿을 정하고 각자 맡을 역할을 정하고 오늘 팀스터디를 마무리했다.
내일 열심히 준비한 자료들을 바탕으로, ppt+발표준비에 박차를 가해야겠다.
.
.
데이터 리터러시 강의
🔻오늘 총 3강을 들었다.
1) 데이터 리터러시
2) 문제 정의
3) 데이터의 유형
🔺
.
북스터디를 진행한 책과 내용이 매우 유사해서, 편하게 들을 수 있었다.
아는 내용이 나와서 반갑기도 했다 ㅎㅎ
주요 내용을 정리해보자
☑️ 심슨의 역설 (Simpson’s Paradox)
- 심슨의 패러독스란 '부분'에서 성립한 대소 관계가 그 부분들을 종합한 '전체'에 대해서는 성립하지 않는 모순적인 경우를 말한다.
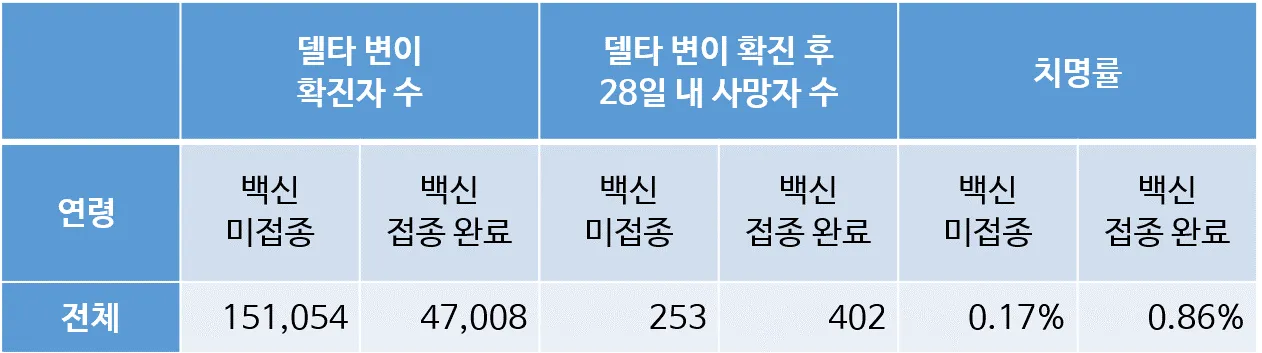
하지만 50대를 기준으로 연령을 나누어보면, 데이터 값 비교가 가능해짐.
결론 - 전체에 대한 결론이 언제나 개별 집단에 그대로 적용되는 것은 아님
- 데이터에 기반한 결론이라고 해서 이를 맹목적으로 받아들여서는 안됨
.
☑️ 시각화를 활용한 왜곡
- 자료의 표현 방법에 따라서 해석의 오류 여지가 존재
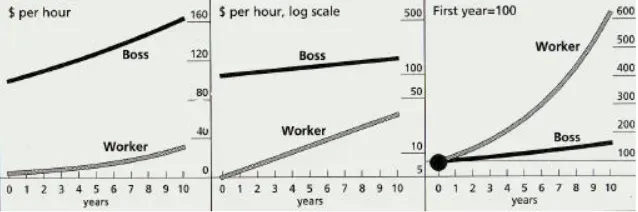
각각 다르게 해석될 여지가 존재한다.
.
☑️ 샘플링 편향 (Sampling Bias)
- 전체를 대표하지 못하는 편향된 샘플 선정으로 인해 오류가 발생
예시사례

- 문제는 Literary Digest의 샘플링 방법
- 첫째, 여론조사용 주소를 얻기 위해 전화번호부, 자사의 구독자 명부, 클럽 회원 명부 등을 사용. 이런 명부는 모두 공화당(따라서 랜던)에 투표할 가능성이 높은 부유한 계층에 편중된 경향이 존재
- 둘째, 우편물 수신자 중 25% 미만의 사람이 응답. 이는 정치에 관심 없는 사람, Literary Digest를 싫어하는 사람과 다른 중요한 그룹을 제외시킴으로써 역시 표본을 편향되게 만듦
- 표본이 편향되면서 실제와는 다르게 해석하게 될 수 있음
상관관계=!인과관계
☑️ MECE (Mutually Exclusive, Collectively Exhaustive)
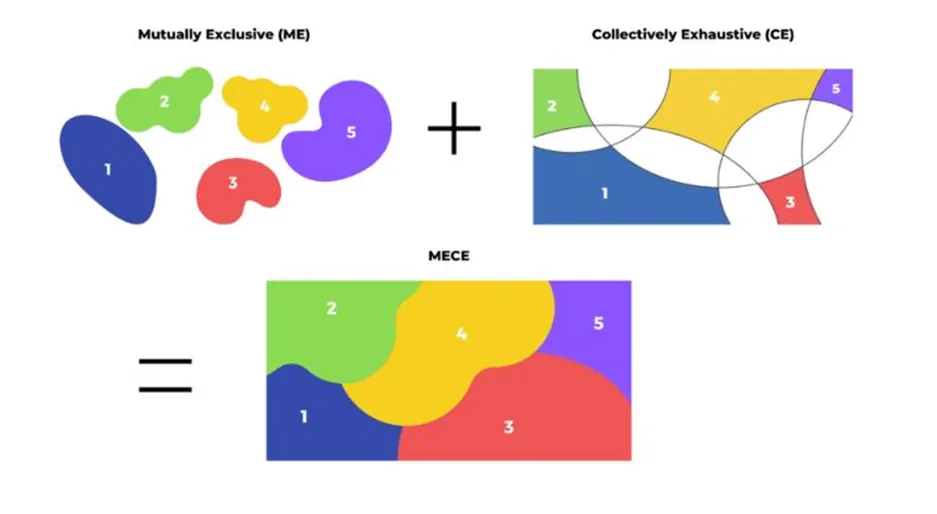
(정성 정량 데이터 비교는 이전 게시물로 업로드한 적이 있어 SKIP)
기초분석과제에 적용해볼만한 인사이트
🔴🔴🔴1. 문제정의를 구체적이고 명확하게 하자.
예를 들어, 매출 증가가 목표 -> 모호하고 명확하지 않다.
그럼 어떻게?
지난 N개월 동안 전환율이 2%였는데, 어떤 마케팅 전략으로 전환율을 5%까지 향상시킬 수 있을지.
.
🔴🔴🔴2.우리 팀이 실제 업계 데이터와 비교하거나 유사성을 표현할 때,
이커머스 관련 행동 로그데이터를 검색해서 참고해보면 좋을 것 같다.
.
🔴🔴🔴3.PPT만들때 로직트리를 활용해보자
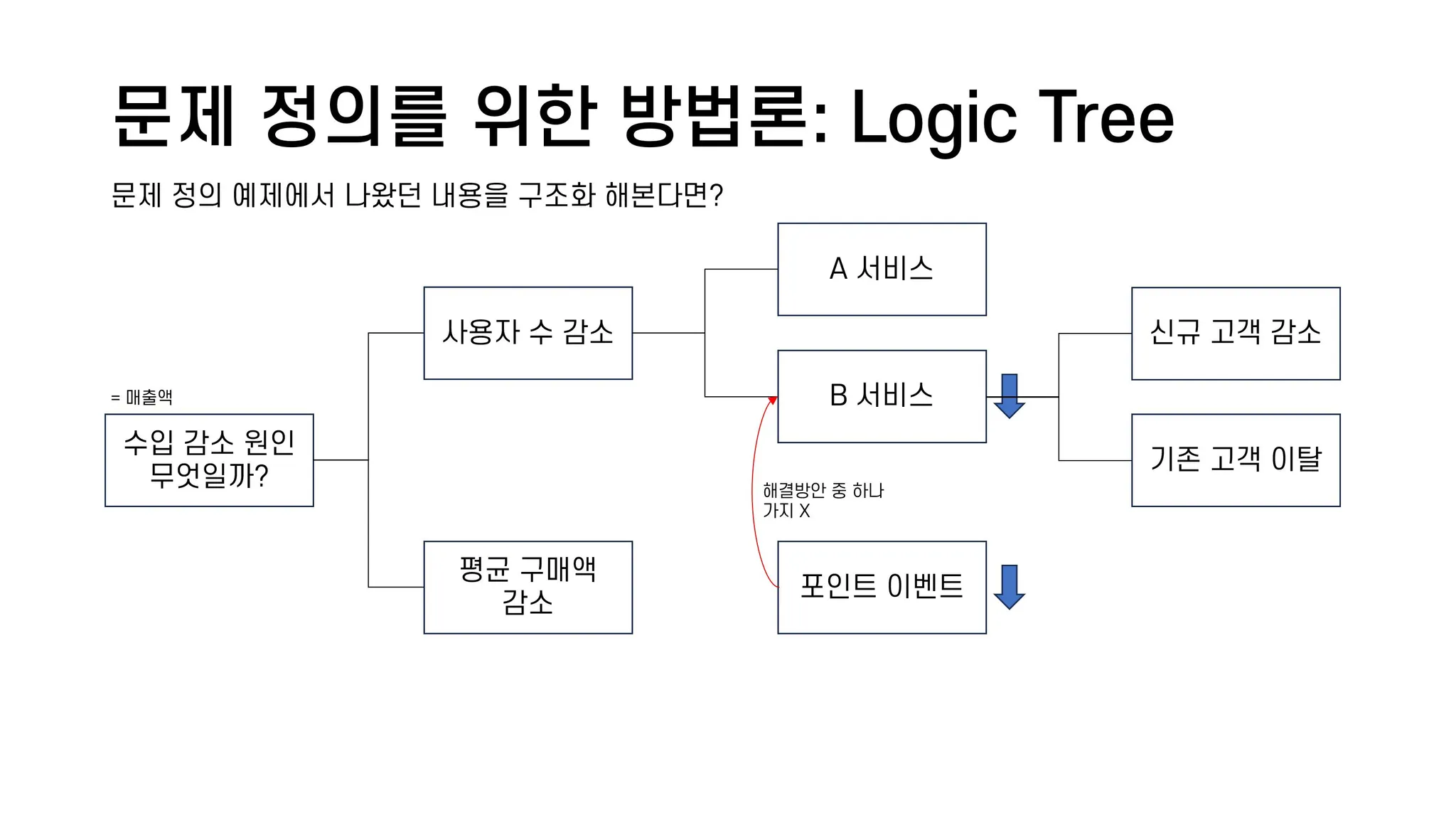
.
🔴🔴🔴4. SO WHAT? WHY SO? 활용
-
So what?
- 수집한 정보와 소재에서 ‘결국 어떻다는 것인지’를 알아내는 작업
- 그래서, 따라서, 이렇듯 앞에 오는 정보나 소재에서 과제의 답변에 맞는 중요한 핵심을 추출하는 작업
-
나타난 현상을 바탕으로 과제에 비추어 말할 수 있는 내용의 핵심을 추출하는 작업
-
Why So?
- 왜 그렇게 말할 수 있는지
- 구체적으로 무슨 뜻인지를 검증하고 확인하는 작업
- So what?한 요소의 타당성을 자료 전체 혹은 그룹핑한 요소로 증명할 수 있다는 사실을 검증하는 작업
느낀점&회고
내가 내일 최종적으로 데이터+결론 흐름을 잘 연결지어야 발표를 매끄럽게 진행할 수 있을 것 같다.
내일 오후에는 이부분에 최대한 집중해보려한다.
팀스터디를 열심히 하고있다고 생각했는데, 스스로에게 부족한 부분이 자꾸 느껴진다.
데이터 분석 skill 말고 인간적으로.. (소통하는 법을 잊은 듯하다 왤케 말을 못하지)
같이 밥먹고 싶은 사람은 언제 될 수 있는걸까.. ?! 어렵다 어려워 ~~
오늘따라 유독 허리가 아팠다. . 그래서 자꾸 이상한 자세로 있느라 캠키기가 민망했다.
자세가 이상해서 더 아팠던 거겠지?? 내일은 아침부터 정신차리고 정자세로 앉아있으려 노력해야겠다. 이번주도 벌써 절반이 지나갔군. 잘 마무리하자 🍀
