📌Today's routine
1.프로그래밍 기초 발제
2.팀 재편성
3.sql 라이브세션_6회차
4.아티클스터디
5.파이썬 종합
6.코드카타
📢sql 라이브세션_6회차 [ 과제 해설 ]
☑️ 3회차 과제해설
문제1 - 집계함수의 활용
기준- 서버,월 (총 2개)
(집계함수 제외)
=> 기준 2개를 group by 에 모두 넣기
distinct 사용
date_format or substr 등을 활용하여 추출형태 자유롭게 변환하기
문제3 - 집계함수와 조건절의 활용
*group by 에 case when 바로 갖다 쓸 수 있다.
group by serverno, case when first_login_date <'2024-01-01' then '기존유저'
else '신규유저' end문제 4 -SubQuery의 활용
문제 2번 + 서브쿼리 + having 잘 이해했다면 2번 복붙해서 3초(?)만에 풀 수 있는 문제..(튜터님 왈.)
select *
from( select *
)는 지양하자. 서브쿼리 안에 select에서 가져오고 싶은 기준을 써주자
(시간 toomuch)
🔥🔥문제5 - SubQuery의 응용
select actor_cnt, count(distinct game_account_id)as accnt
from( select game_account_id , count(distinct game_actor_id) as actor_cnt
from basic.users
where level>=30
group by game_account_id
having actor_cnt>=2
)as a
group by actor_cnt # 서브쿼리에서 group by 를 사용해 주었으므로 해당 구문의 distinct 는 필수가아닙니다.
=> 섭쿼리 안에 그룹바이로 묶여나온 건 distinct 사용 유무 차이 없음(원리 이해해보면 됨)
• group by, having, subquery 가 혼합된 형태의 문제
레벨이 30 이상인 캐릭터를 기준으로, 게임계정 별 캐릭터 수를 중복값 없이 추출 => 맨안쪽 쿼리 where문으로 애초에 30 이상인 것만 추출
having은 group by 결과에 대한 필터링이므로 차이점을 이해하자.
- ☑️ 5회차 과제해설 - DBeaver
문제1 - JOIN 활용
count(distinct a.game_account_id)as usercnt 요게 포인트.
기준 테이블인 left = users 테이블의 개수를 세어줘야, 결제함과 결제안함(b.~~ is null)을 둘 다 count해줄 수 있다 !!!
현업에서
case when 과 left join은 짝꿍처럼 많이 쓰인다!! ( view만 하고 카트에 담지 않은 사람, 카드 발급받고 사용 안한 사람 ..etc) wow 이거 짱
문제2 - JOIN 응용1
from table a =
from( select a.game_account_id, count(distinct game_actor_id) as actor_cnt, sum(pay_amount)as sumamount
from( select game_account_id, game_actor_id
from basic.users
where serverno>=2
)as a
inner join
( select distinct game_account_id, pay_amount, approved_at
from basic.payment
where pay_type='CARD'
)as b
on a.game_account_id=b.game_account_id
group by a.game_account_id
)as a left join 을 사용해도 된다고는 한다. 그럼 더 길어진다고는 하는데 머리로 한번 이해해봐도 좋을 것 같다.
문제2 - JOIN 응용2
select game_account_id, max(approved_at)as date2여기서 game_account_id는 고유할까?
-> 고유하다, 따라서 group by에 써줘야한다.
Max, Min 등 집계함수를 쓰면 값이 고유해진다!는 점도 기억해줄만한 포인트~!
where date2>first_login_date접속 안했는데 결제 된 이상치(?) 제외하는 조건으로 쓰임. (현업짬)
datddiff 날짜형식 맞춰주자(ex.0000-00-00 00:00:00 - 0000-00-00 ❌)
.
- 아.. 내가 having을 왜 못쓰나 질문했던 것..
H 다음 S 라는 것만 생각했따..
G 다음 H 인걸 왜 생각 못했나 !
group by 필터링인데, group by에는 serverno 라서 당욘히,,오류가 뜰것이다having쓸거면, 서브쿼리 안에서 having 써주고
밖에서 쓰고 싶으면 datediff 쓰자
cf.
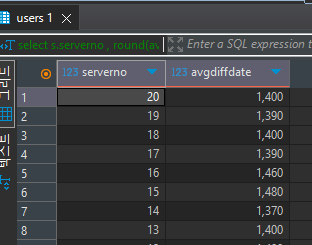
round(avg(diffdate),-1)요거 실행해보면? => 일의자리에서 반올림✔
아티클스터디
오늘의 아티클
사용자 데이터를 효과적으로 분석하는 법
- 요약
- 정량데이터) 만족도 점수, 과제 수행시간, 에러 수 etc
정성데이터) 사용자의 리얼 보이스, 행동 관찰 기록, 사진
✅ 정량 데이터가 얼마나 많은 행동이 일어나고 있는지를 알려준다면, 정성데이터는 행동이 일어난 이유를 알려준다.
🙄그렇다면, 정량적 데이터를 어떻게 분석하고 시각화하는가⁉
-
기술통계
: 수집된 데이터의 특성을 파악하기 위해 활용- 범주형 데이터
- 선호하는 디자인 타입 or 과제 성공 여부 etc
⇒ 빈도나 백분율로 표현 / 원그래프나 누적 막대그래프로 시각화
. - 수치형 데이터
- 만족도 or 수행시간 etc
⇒ 평균이나 표준편차로 표현 / 막대그래프나 선그래프로 시각화
💡막대그래프는 디자인 컨셉이나 태스크와 같이 분리된 카테고리에 대한 연속적인 값(만족도, 시간, 에러 수 등)을 표현하고자 할 때 효과적으로 사용가능. (막대 길이를 통해 카테고리 간의 크기 비교가능!)
💡반면에, 연속적 속성이라면 선그래프가 더 효과적
- 만족도 or 수행시간 etc
- 범주형 데이터
-
중심경향지표
-> 평균,중앙값,최빈값 이용 (극단값 주의)
⭐극단값이 많다면 평균보다는 중앙값을, 주관적 적도처럼 데이터가 제한된값을 가진다면 최빈값 활용도 고려해볼만 !- 방사형 그래프와 산점도
- 방사형 그래프: 특정 대상에 대해 여러 평가 항목들로 비교해 전체적인 경향을 유추하고 싶을 때 활용
🔻 브랜드 A가 B보다 사용성과 디자인 심미성 높은 반면, 기능의 유용성과 전체적인 일관성이 낮다는 점을 직관적으로 확인 가능

- 방사형 그래프: 특정 대상에 대해 여러 평가 항목들로 비교해 전체적인 경향을 유추하고 싶을 때 활용
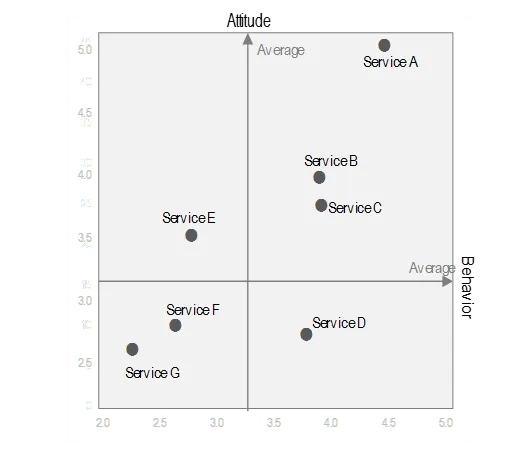
- 산점도 : 평균을 기준 선으로 하여 포지셔닝 맵 형태로 변형한 결과
🔻특정 서비스의 이용행동(이용빈도)과 태도(이용 의향)를 한번에 비교해서 볼 수 있음
서비스E는 사용자의 서비스 접근성을 향상하고, 서비스의 매력성을 적극 마케팅해 미사용자의 유입을 높이기 위한 전략이 필요함
- 방사형 그래프와 산점도
-
추론통계
:샘플을 통해 모집단을 추론하거나 가설을 검정 -
집단 간의 차이
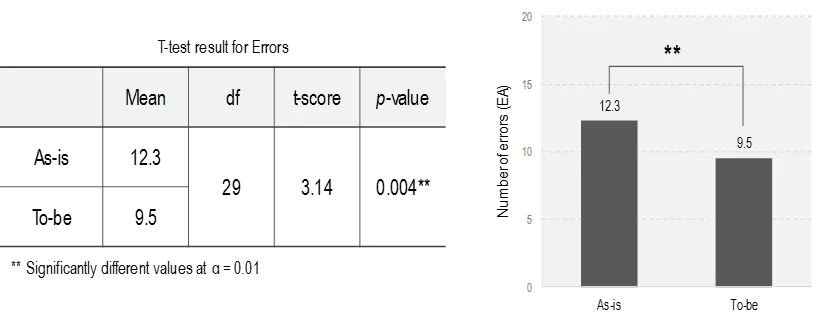
- t 검정, 분산분석현업…💭
경쟁사의 서비스나 자사의 디자인 개선안이 현재의 자사 서비스와 ux경쟁력이 얼마나 차이나는지 검증하는 것. ( = 개선안이 그만큼의 효과를 지니는가ㅏ)
비교 대상이 2개를 초과한다면 분산분석이 필요.
- 변수 간 연관성 파악
- 상관분석
2개 이상의 변수들의 선형적인 관계를 살펴보기 위한 분석방법.
⇒상관계수와 p값을 통해서 해석 - 회귀분석
하나의 종속 변수에 대해 다수의 독립변수들이 어떻게 영향을 미치는지에 대한 인과 관계를 분석할 때 많이 활용
(p-value, R2,Beta)
🔻

- 상관분석
- 변수 간 연관성 파악
-
인사이트
통계 개념들이 잘 요약되어 정리된 아티클이었던 것 같아, 이해하기 어렵지 않았던 것 같다.오늘 아티클에서 나온 내용들로, ott구독개수에 따른 재구독 의향 분석 프로젝트를 해본 경험이 있다.
하지만 회귀분석에 대해서 자세히 다루지는 못했어서, 베타라는 개념은 오늘 처음 접하기도 했는데, 앞으로 더욱 심화적인 통계내용을 배우고, 데이터 전처리 및 분석 실력을 키워 다양한 데이터들을 만져보고 싶다. 그리고 나중에 기회가 된다면, spss같은 프로그램을 다루는 방법도 배워보고싶다.
오늘 나온 내용을 잘 이해해둔다면, 논문을 읽을 때나 전문 자료를 읽을 때 큰 도움이 될 것같다. 개념도 중요하지만, 각 분석방법마다 어떤 데이터를 활용하는 게 효과적인지, 어떻게 분석할 때 필요한 방법인지를 잘 기억해두어야겠다.
파이썬 종합
정욱 튜터님이 강의해주셔서 엄청 반갑다 !!! ㅎㅎ (내적친밀감max)
1주차~2주차 리스트 기본(2-2)까지 들었다. 사전캠프 때 들었던 강의랑 비슷했다.
.
변수
x=10
print("변수x의 값은",x,"입니다.")변수x의 값은 10 입니다.
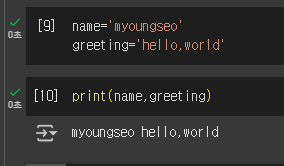
full_greeting=greeting + ' my name is ' + name
print(full_greeting)입력문
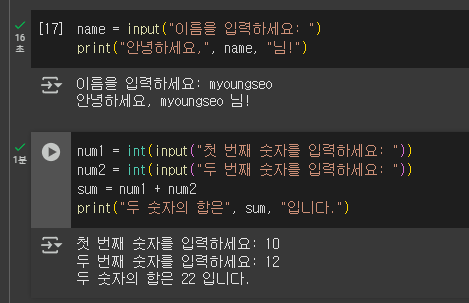
마무리 문제

개인적으로 SQL을 공부할 때도 그랬고, 기본 개념+코드를 손필기 해놓은 작은 공책 도움을 많이 받았어서 강의코드 실습 + 필기를 병행하며 강의를 수강했다.➰



코드카타
SQL-조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기
SELECT concat('/home/grep/src/',board_id,'/',file_id,file_name,file_ext) as file_path
from USED_GOODS_FILE
where board_id in (select board_id
from USED_GOODS_BOARD
having Max(views))
order by file_id desc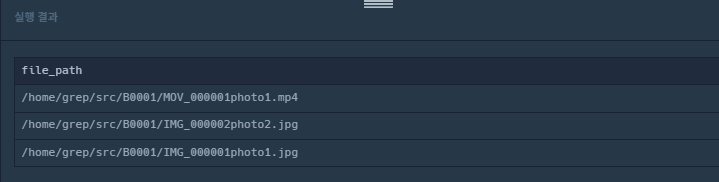
이렇게 하면, board_id가 B0001인 파일경로들이 조회 된다.
즉 where문에 있는 서브쿼리에서 board_id가 B0001로 조회된다는 것이다.
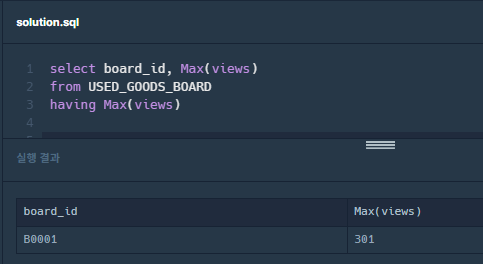
최대 조회수는 301이 맞는데, 이 view 수에 해당하는 board_id가 B0001이 아니다.
흠.. 왜 이렇게 나오지..?
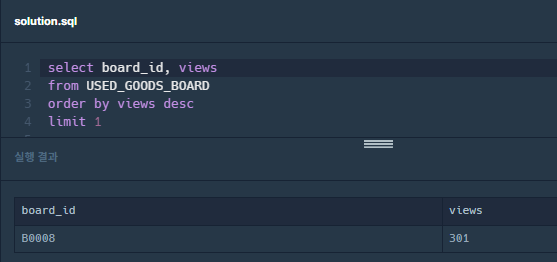
board_id는 B0008이 나와야한다...
이렇게 나오는 이유를 구글링+고민 해봤는데..답을 못찾겠다.
내가 확실한건 max(view)가 301이니까 그냥 조인쓰고, where 조건 넣어서 풀었다.
구글링해보니까 대부분의 사람들의 정답쿼리가 이거더라.(나같은 사람 왜 없지.....)
🔻
SELECT concat('/home/grep/src/',f.board_id,'/',file_id,file_name,file_ext) as file_path
from USED_GOODS_FILE f
join USED_GOODS_BOARD b
on f.board_id=b.board_id
where views in (select max(views)
from USED_GOODS_BOARD )
order by file_id desc
이 문제에 대해서는, 내일 정신이 맑을 때 다시 고민해보고 질문해봐야겠다.
지금은..뇌가 너무 고였다....(계속 꼬리물기 고민이야...)
느낀점&회고
오늘 팀빌딩 날이라 되게 긴장을 많이 했는데, 아티클스터디나 tmi제출 같은 팀활동을 원활하게 한 것 같아서 기분이 좋다. 앞으로도 팀활동이 기대가 된다 !! 💖
오늘 과제 해설을 진짜 자세하게 해주셔서 배우는 게 많았다 !! 벌써...1회차밖에 안남았다니 ㅠㅜ 시간넘빨랑.. 앞으로의 과제도 잘 해결할 수 있게 파이썬도 열심히 공부해야겠다 !!
샤워하고 얼렁 자야지 (●'◡'●)
