
- 자동차 대여 기록 별 대여 금액 구하기
답답해서 데이터 뜯어봄
SELECT car_type, discount_rate
from CAR_RENTAL_COMPANY_DISCOUNT_PLAN p
where car_type='트럭'
??
예시랑 plan_id도 달랐고, discount_rate도 다름
그래서 할인율만 0.85, 0.92,0.95로 바꿔줬더니 됐다..
예시는 예시일 뿐 ...
SELECT
h.history_id,
CASE
WHEN DATEDIFF(h.end_date, h.start_date) + 1 >= 90
THEN ROUND(c.daily_fee * (DATEDIFF(h.end_date, h.start_date) + 1) * 0.85, 0)
WHEN DATEDIFF(h.end_date, h.start_date) + 1 >= 30
THEN ROUND(c.daily_fee * (DATEDIFF(h.end_date, h.start_date) + 1) * 0.92, 0)
WHEN DATEDIFF(h.end_date, h.start_date) + 1 >= 7
THEN ROUND(c.daily_fee * (DATEDIFF(h.end_date, h.start_date) + 1) * 0.95, 0)
ELSE ROUND(c.daily_fee * (DATEDIFF(h.end_date, h.start_date) + 1)*1, 0)
END AS fee
from CAR_RENTAL_COMPANY_CAR c
join CAR_RENTAL_COMPANY_RENTAL_HISTORY h
on c.car_id=h.car_id
join CAR_RENTAL_COMPANY_DISCOUNT_PLAN p
on c.car_type=p.car_type
where c.car_type='트럭'
group by 1
order by 2 desc, 1 desc76.상품을 구매한 회원 비율 구하기
select Year(o.sales_date) as year
, Month(o.sales_date) as month
, count(distinct o.user_id) as PURCHASED_USERS
, round((count(distinct o.user_id)/ count(a.user_id)),1) PUCHASED_RATIO
from (select user_id
from USER_INFO
where joined like '2021%') a
right join ONLINE_SALE o
on a.user_id=o.user_id
where o.user_id in (select user_id
from USER_INFO
where joined like '2021%')
group by 1,2
order by 1,2 으아 !!!!!! right join으로 묶여나오면서 a.user_id 개수가 달라진다는 점을 인지하지 못함..>!!
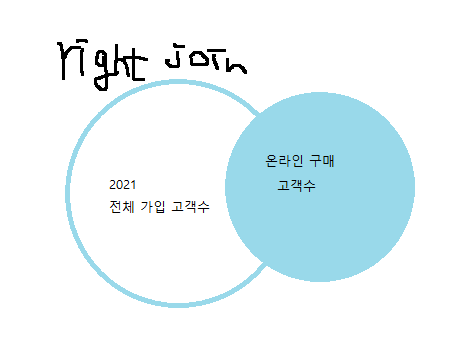
🔻그래서 count(a.user_id) 대신
(select count(user_id) from USER_INFO where joined like '2021%')로 수정 !!
select Year(o.sales_date) as year
, Month(o.sales_date) as month
, count(distinct o.user_id) as PURCHASED_USERS
, round((count(distinct o.user_id)/ ((select count(user_id)
from USER_INFO
where joined like '2021%'))
),1) PUCHASED_RATIO
from (select user_id
from USER_INFO
where joined like '2021%') a
right join ONLINE_SALE o
on a.user_id=o.user_id
where o.user_id in (select user_id
from USER_INFO
where joined like '2021%')
group by 1,2
order by 1,2정답!
한국어문제 끝
아티클 스터디
오늘의 아티클
기획자도 파이썬을 배워야 하나요? - 2.실전편
-
김명서
-
요약 : 기획자에게 파이썬이 필요한 이유
- 주요 포인트 :파이썬이 엑셀에 비해 구체적으로 얼마나 효율적일까?
데이터 정리 목표
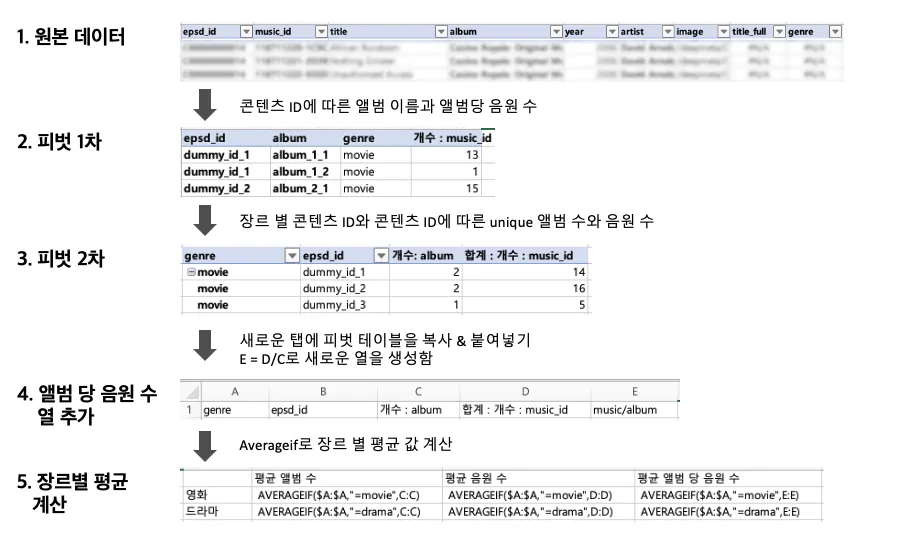
(1)한 콘텐츠 당 평균 앨범 수, (2) 콘텐츠 당 평균 음원 수, (3)평균 앨범 당 음원 수를 장르별 구분해서 보기.🔻excel ver.
🔻python ver.
#장르, EPSD ID 기준으로 피벗 테이블 만들기 pvt= pd.pivot_table(output, index=['genre','epsd_id'], values=['music_id','album'], aggfunc=pd.Series.nunique) #unique count 집계 #피벗 테이블을 dataframe으로 변환하기 pvt.reset_index(inplace=True) #music/album 열 추가 pvt['music/album]=pvt['music_id']/pvt['album'] #장르 별 평균 계산 pvt.groupby(pvt['genre']).mean()결론, 엑셀로는 두개의 피벗테이블, 4개의 탭(원본, 피벗1, 피벗2,분석), 7개의 함수가 사용되었지만 파이썬으로는 한 개의 피벗 테이블, 탭 없음, 4개의 함수
추가적인 파이썬의 장점
1.짧은 로딩 시간
2.빠른 데이블 머지 속도
💡 인사이트 파이썬과 sql이 엑셀보다 얼마나 효율적인지는 익히 알고있다. 그동안 sql을 공부하면서 , 더 체감할 수 있었다. 아직 파이썬은 연산함수정도만 사용할 줄 알아서, 판다스 라이브러리 이용력도 얼른 키워서 데이터를 효율적으로 처리해보고싶다. 추가적인 장점으로는, 파이썬으로 데이터 수집을 자동화할 수 있고 다양한 라이브러리와 연결 가능하다는 점도 생각이 났다. 또한 코드 셀을 계속해서 추가하여 작성할 수 있기 때문에, 중간 확인도 가능할 것이다.
-
.
.
🔍 관련 사례 아티클
파이썬 종합
📌코드 위주로 정리
파일 불러오기
import pandas as pd
df = pd.read_csv('/content/sample_data/data.csv')
#경로는 상황에 따라 다름클래스
- 평균 계산기
1. 아래의 데이터와 클래스 일부분을 수정하여 평균을 계산하는 클래스를 완성하고 실제로 클래스를 선언하여 계산된 결과 까지도 출력해 보세요!
class DataPreprocessor:
def __init__(self, data):
self.data = data
def calculation(self):
answer= sum(self.data)/len(self.data)
return answer
data = [2, 4, 6, 8, 10]
preprocessed_data = DataPreprocessor(data)
answer = preprocessed_data.calculation()
print("평균:",answer)
#평균: 6.0💡 마지막에
preprocessed_data = DataPreprocessor(data)
answer = preprocessed_data.calculation()이 부분을 작성못했다.. 아직 코드 작성이 익숙하지 않은 것 같다..ㅜ!! 차차 복습하며 채워야겠다아아 ✔
개인 스터디
과제하며 배운 점들을 모아놓았다.
⭐⭐ 3.
MAX
max(iterable, key=function)🔺기본적으로 위 구조를 참고했다.
1. max(sales_data, key=sales_data.get)딕셔너리 형태인 sales_data가 들어가면, 기본적인 key만 순회하기 때문에 과일 이름 중에 사전 순으로 가장 큰 키를 반환한다.
따라서 , key=sales_data.get이라고 작성해서 키에 대한 값을 가져오게 만들어줬다.
=>각 키에 대해 value=값(판매수량)을 비교해서 최댓값을 가진 키를 반환
2. sales_data[top_product] -> sales_data[top_product]
딕셔너리에 [key]를 사용해서 해당하는 value값을 가져왔다.
.
.
.
⭐⭐4.
if/elif 조건문을 기본적으로 이용하고,
try:
num1 / num2
except:
return 'Cannot divide by zero' 여기서 try, except를 이용해줬다
try: except:
.
.
.
⭐⭐5.
여기에 시간을 좀 쏟았다.
수정한 내용
if len(split_email[0])>0 and len(split_email[1].split('.'))==2:난 naver.com 만 생각해서 ==2라고 썼는데, email.co.uk 요런 애도 있었다 !! >1로 고쳐줬다!
.
근데 아직 결과가 이렇게 나온다 ㅋㅋㅋ
example@example.com 유효한 이메일 주소입니다. correct@email.co.uk 유효한 이메일 주소입니다. correct@email.co.uk 유효하지 않은 이메일 주소입니다.
그치만, 내일 마저 완성할 수 있을 것 같다 !!😊😊😊
📌참고참고
e-mail 정규식
import re
def is_valid_email(email):
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))정규식으로 안풀거지만, 구글링 좀만 해보면 쉽게 찾을 수 있었다.
느낀점&회고
뭔가.. 아직 익숙하지 않은 파이썬으로 과제를 해야하다보니까, 자꾸 생각이 딴 데로 샜다..ㅜ😥
sql도 논리 허점을 채워나가야할 부분이 많은 것 같고.. 점점 부족한 부분들이 보인다.
4주차인데..? 그래 4주차니까..
이대로 전처리&시각화 하는게 맞나...🤦♀️
일단 내일 파이썬 라이브 세션 듣고 생각해보자.
코드 좀 못쓰면 어때..! 판다스 잘쓰면 되지..! (진짜 이러겠다는거 아니고.. 좀 훌훌 부담감을 털으려는 ..^^)
내일은 더 열심히 해보자🙂

파이썬 잘하는 비결은 뭘까요