
라이브세션- 시각화
복습하면서 코드실행해보고 있었는데 날짜 관련해서 아래와같은 오류가 발생했다.
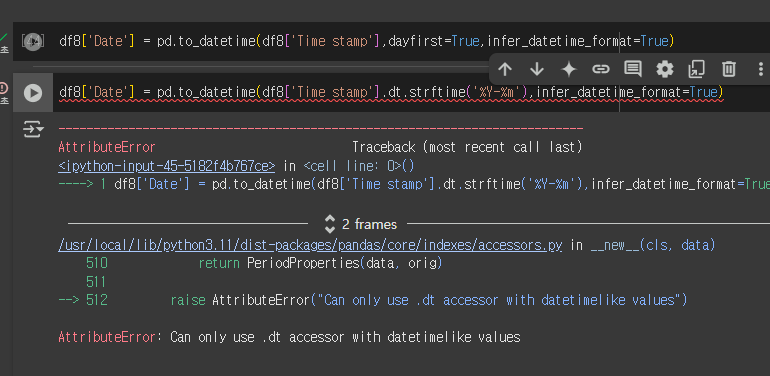
AttributeError: Can only use .dt accessor with datetimelike values
🔻
이렇게 수정해줬다.
먼저 datetime 형식으로 바꿔주고 format 지정을 해준 뒤,
다음줄 코드로 strftime작업을 해줘야하는 듯 하다ㅏ~!!
df8['Date'] = pd.to_datetime(df8['Time stamp'],dayfirst=True,infer_datetime_format=True)
df8['Date'] = df8['Date'].dt.strftime('%Y-%m')
df9 = df8.groupby('Date')['user id'].count().reset_index()기초프로젝트 - 결측치 작업 마무리
오늘은 서울시 부동산 데이터(df_2018 ~ df_2024)를 대상으로 결측치 처리, 데이터 조회, 상관관계 분석 등 다양한 전처리 작업을 진행했다. 각 작업을 단계별로 정리하고, 주요 코드와 함께 학습 내용을 풀어서 기록해보려한다.
.
.
1. '권리구분' 값 분포 확인 및 통계 분석
작업 내용: df_2018에서 '권리구분'의 고유값(, '분양권', '입주권') 분포를 확인하고, '분양권'과 '입주권'의 '물건금액(만원)' 평균과 중앙값을 계산.
# '권리구분' 값별 개수 확인
print(df_2018['권리구분'].value_counts(dropna=False))
# '분양권'과 '입주권'의 물건금액 평균과 중앙값
result = df_2018.groupby('권리구분')['물건금액(만원)'].agg(['mean', 'median']).loc[['분양권', '입주권']]
print(result)value_counts(dropna=False)로 결측치()를 포함한 분포를 확인하는 방법.
groupby()와 agg()를 활용해 그룹별 통계(평균, 중앙값)를 효율적으로 계산.
부동산 데이터에서 '권리구분'이 가격에 미치는 영향을 분석하는 첫걸음이었다.
.
.
2. '지번구분' 값 분포 내림차순 확인
# 모든 연도 데이터에 결측치 '미상' 채우기
dfs = [df_2018, df_2019, df_2020, df_2021, df_2022, df_2023, df_2024]
for df in dfs:
df['지번구분'].fillna('미상', inplace=True)
# df_2018의 '지번구분' 값별 개수 내림차순
print("df_2018 지번구분 개수 (내림차순):\n", df_2018['지번구분'].value_counts(ascending=False))반복 작업에서 for 루프를 활용해 코드를 간소화하는 방법을 사용해보았다.
.
.
3. '층' 결측치 처리 판단 및 전처리 작업
작업 내용: '층' 결측치(14,346개)를 '단독'으로 대체할지 판단하기 위해 '단독다가구'와의 연관성을 확인하고, 여러 전처리 작업을 모든 연도에 적용.
팀원분께서 '층'과 '건물용도' 에서 특이점을 발견하시고 공유해주셨다 !!!
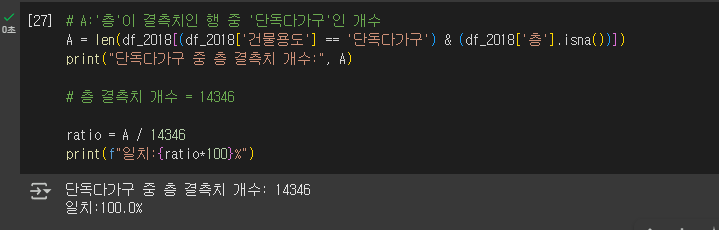
🔺🔺🔺
그래서..나는 수저만 얹은 느낌으로... 확인을 해보았다...^
.
print("단독다가구 행 개수:", len(df_2018[df_2018['건물용도'] == '단독다가구']))
#'층' 결측치와 '단독다가구' 연관성 확인
A = len(df_2018[(df_2018['건물용도'] == '단독다가구') & (df_2018['층'].isna())])
print("단독다가구 중 층 결측치 개수:",A)
len()과count()의 차이: len()은 행 개수, count()는 결측치 제외 개수.
.notna(): 결측치가 아닌 값을 필터링.
inplace=True 사용 시 경고(FutureWarning) 해결: 명시적 할당(df['층'] = df['층'].fillna('단독'))으로 변경.
.
.
4. '본번' 결측치 처리 및 데이터 조회
# 1. '단독다가구'이면서 '본번' 결측치인 경우 '단독_미상'으로 대체
df_2019.loc[(df_2019['건물용도'] == '단독다가구') & (df_2019['본번'].isna()), '본번'] = '단독_미상'
df_2019.loc[(df_2019['건물용도'] == '단독다가구') & (df_2019['부번'].isna()), '부번'] = '단독_미상'
# 2. A:'본번' 결측치 중 '단독다가구'가 아닌 데이터 조회
A = df_2019[(df_2019['본번'].isna()) & (df_2019['건물용도'] != '단독다가구')]
print("본번 결측치 중 단독다가구가 아닌 데이터:\n", A)
print("본번 결측치 중 단독다가구가 아닌 데이터 개수:", len(A))
df_2019.loc[(df_2019['건물명']=='힐스테이트 서초 젠트리스') & df_2019['본번'].isna(), '본번']='557'
df_2019.loc[(df_2019['건물명']=='힐스테이트 서초 젠트리스') & df_2019['부번'].isna(), '부번']='0'
df_2019.loc[(df_2019['건물명']=='자연누리 오피스텔') & df_2019['본번'].isna(), '본번']='253'
df_2019.loc[(df_2019['건물명']=='자연누리 오피스텔') & df_2019['부번'].isna(), '본번']='12'
# 1. '단독다가구'이면서 '본번' 결측치인 경우 '단독_미상'으로 대체
df_2023.loc[(df_2023['건물용도'] == '단독다가구') & (df_2023['본번'].isna()), '본번'] = '단독_미상'
df_2023.loc[(df_2023['건물용도'] == '단독다가구') & (df_2023['부번'].isna()), '부번'] = '단독_미상'
# 2. '본번' 결측치 중 '단독다가구'가 아닌 데이터 조회
B = df_2023[(df_2023['본번'].isna()) & (df_2023['건물용도'] != '단독다가구')]
print("본번 결측치 중 단독다가구가 아닌 데이터:\n", B)
print("본번 결측치 중 단독다가구가 아닌 데이터 개수_2023:", len(B))
df_2023.loc[(df_2023['건물명']=='힐스테이트 서초 젠트리스') & df_2023['본번'].isna(), '본번']='557'
df_2023.loc[(df_2023['건물명']=='힐스테이트 서초 젠트리스') & df_2023['부번'].isna(), '부번']='0'
df_2023.loc[(df_2023['건물명']=='자연누리 오피스텔') & df_2023['본번'].isna(), '본번']='253'
df_2023.loc[(df_2023['건물명']=='자연누리 오피스텔') & df_2023['부번'].isna(), '부번']='12' 19년,23년을 맡아서 진행했고
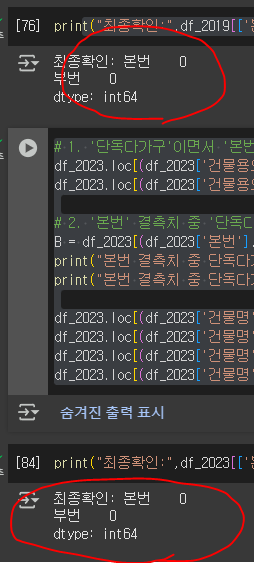
최종 확인도 해줬다.
loc을 활용한 조건 기반 데이터 수정.
.
.
5. '토지면적(m²)' 복구 및 상관관계 분석
작업 내용: '토지면적(m²)' 결측치 행을 삭제한 데이터를 복구하고, 2019년 데이터에서 '토지면적(m²)'과 '건물면적(m²)' 및 다른 컬럼 간 상관계수 계산. 2018년 데이터에서 결측치와 0 제외 후 상관계수 계산.
#'토지면적(m²)' 복구 (원본 로드 후 재적용):
df_2018 = pd.read_csv('path_to_2018_data.csv')
df_2019 = pd.read_csv('path_to_2019_data.csv')
# ... 나머지 연도 데이터 로드
dfs = [df_2018, df_2019, df_2020, df_2021, df_2022, df_2023, df_2024]
#2018년 상관계수 (결측치와 0 제외):
filtered_df = df_2018[(df_2018['토지면적(m²)'].notna()) & (df_2018['토지면적(m²)'] != 0)]
correlation = filtered_df['토지면적(m²)'].corr(filtered_df['건물면적(m²)'])
print("토지면적(m²)과 건물면적(m²)의 상관계수 (결측치와 0 제외):", correlation)데이터 삭제 전 백업의 중요성을 절실히 느꼈다.. 사실 아직도 이 작업 중이다... 나름 토지면적 결측행 제거가 확실시 된 것같아 .. inplace=True를 했는데... 우리팀의 전략이 변경되어버렸ㄷ다..또르르
느낀점&회고
어제 결측값 작업을 한 것들 중에서, 원천데이터에 대해서 더 알아보고싶은 부분이 있어서 팀원들과 회의를 했고, 팀원 중 한 분이 전화연결을 해주셔서 질문내용에 대한 서울시열린데이터광장+국토교통부의 확답을 받았다. 어제 내가 슬랙에 아티클과 함께 공유한 추측이 들어맞았다..!! 야호
.
오늘 저녁쯤에 EDA방향이 살짝 바뀐 부분이 있었는데..
아직 데이터 정리할 것 이 좀 더 남아있어, 이것까지 마무리하고 잘 예정이다..! 진짜 전처리가 쉽지않고 시간도 오래 걸리는 일임을 느낀 하루였다.
코드 복붙 안하고 진짜 알짜배기만 TIL에 써야지! 했는데도 이만큼이.. 되어버렸다...
.
아니 근데 SQL&Python개인과제라니요.... 시각화 복습도 할 수 있을까 말까인데요.... ㅠㅠㅠ 정말 스파르타식인 것 같다 ㅋㅋㅋㅋㅋㅋ나중에 돌아봤을때, 후회없는 시간일 수 있도록 이번주 WIL회고도 잘해서 더 나은 한 주를 보낼 수 있도록 해야겠다.
Tmi
내일 야구 개막전 티켓팅을 해야해서.. 늦잠 자면 안되는데 !!
눈뜨면 12시 일 것 같은 피로..이다..ㅎㅎ...⚾
혹시 누군가.. 이 글을 본 누군가도.. 내일 티켓팅 예정이라면.. 꼭 우리 성공해요 . . .😊

eda 진도가 엄청 많이 나가신것 같아서 부러워요~! 😂 분석 결과도 기대하겠습다 ㅎㅎ