find함수를 사용하면 document가 많을 수록 느려지는데,
binary search를 사용하면 이를 해결할 수 있다.
여기서 사용되는 index란, 컬렉션에 있던 document를 복사해서 미리 정렬해둔 것으로, 정렬된 컬렉션 복사본으로 이해하면 될 것 같다.
✨MongoDB에서 Index 만들기
-
MongoDB에 들어가서 원하는 collection 안에서 indexes 클릭
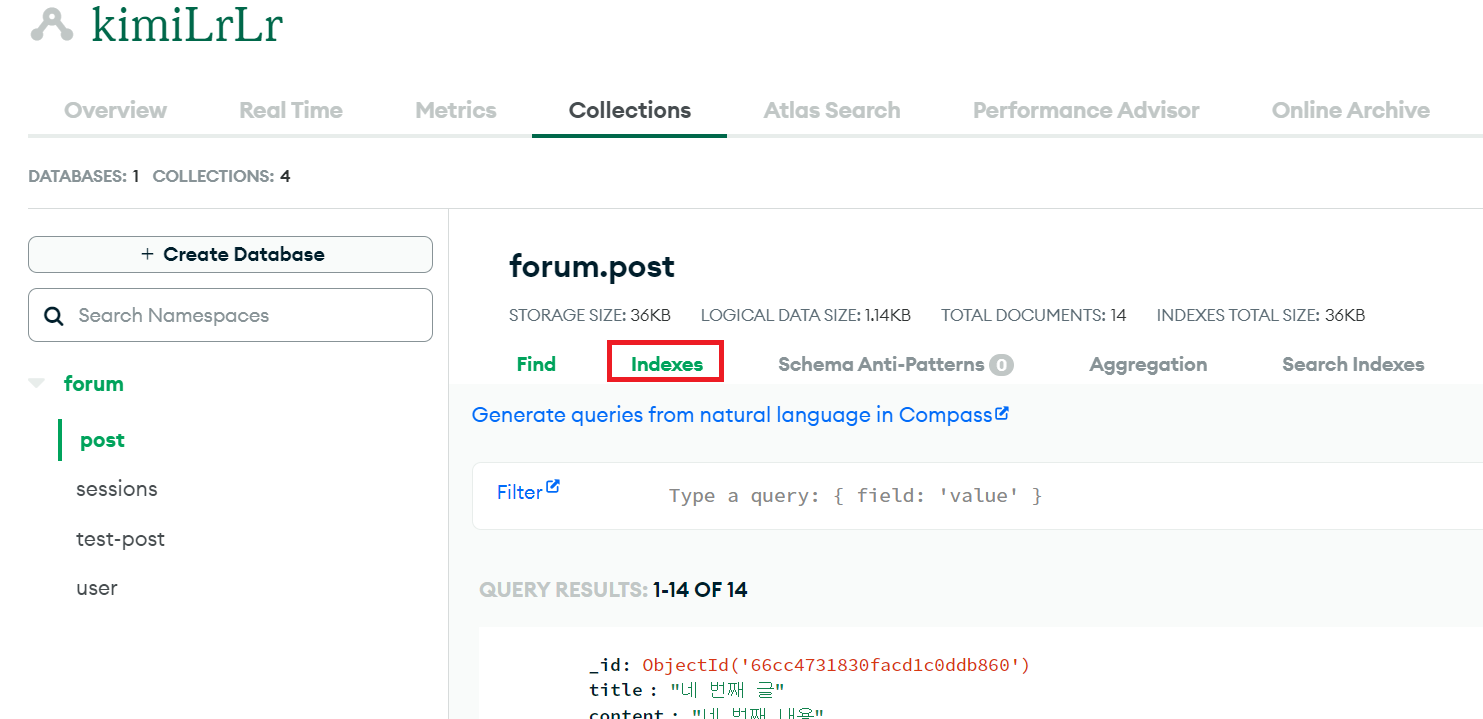
-
기존에
_id가 있지만 새로 만들고 싶은 경우, "create index"를 눌러준다.
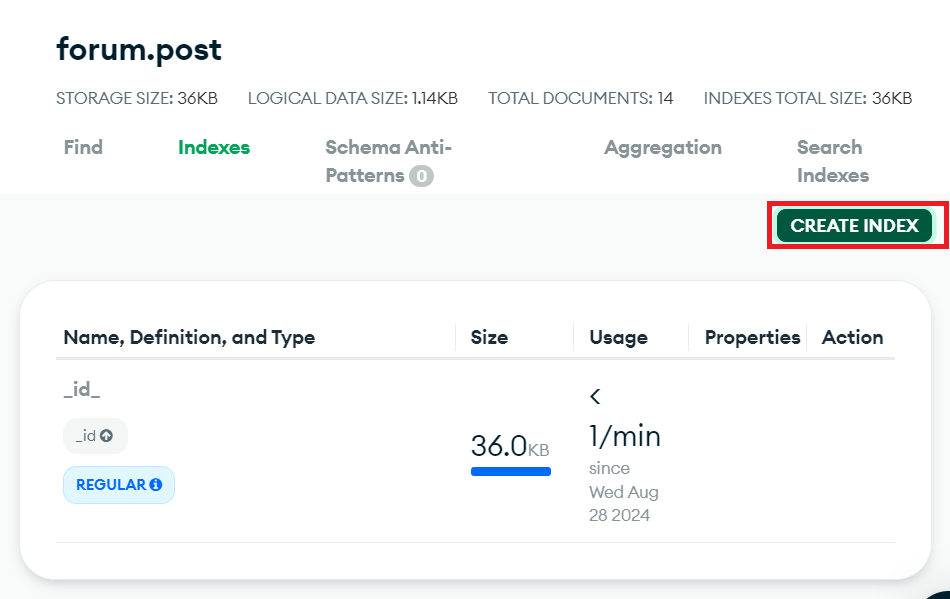
-
index만들필드명: 데이터타입("text"혹은 1 이나 -1)형식으로 넣어준다.
문자형의 경우"title":"text"이런 식으로,
숫자형의 경우"title": 1"이런 식으로.
참고로 숫자의 경우, 1과 -1은 오름차순/내림차순 선택이다.
지금은 타이틀을 기준으로 한 index를 만들고싶으니 아래처럼 작성해주었다.
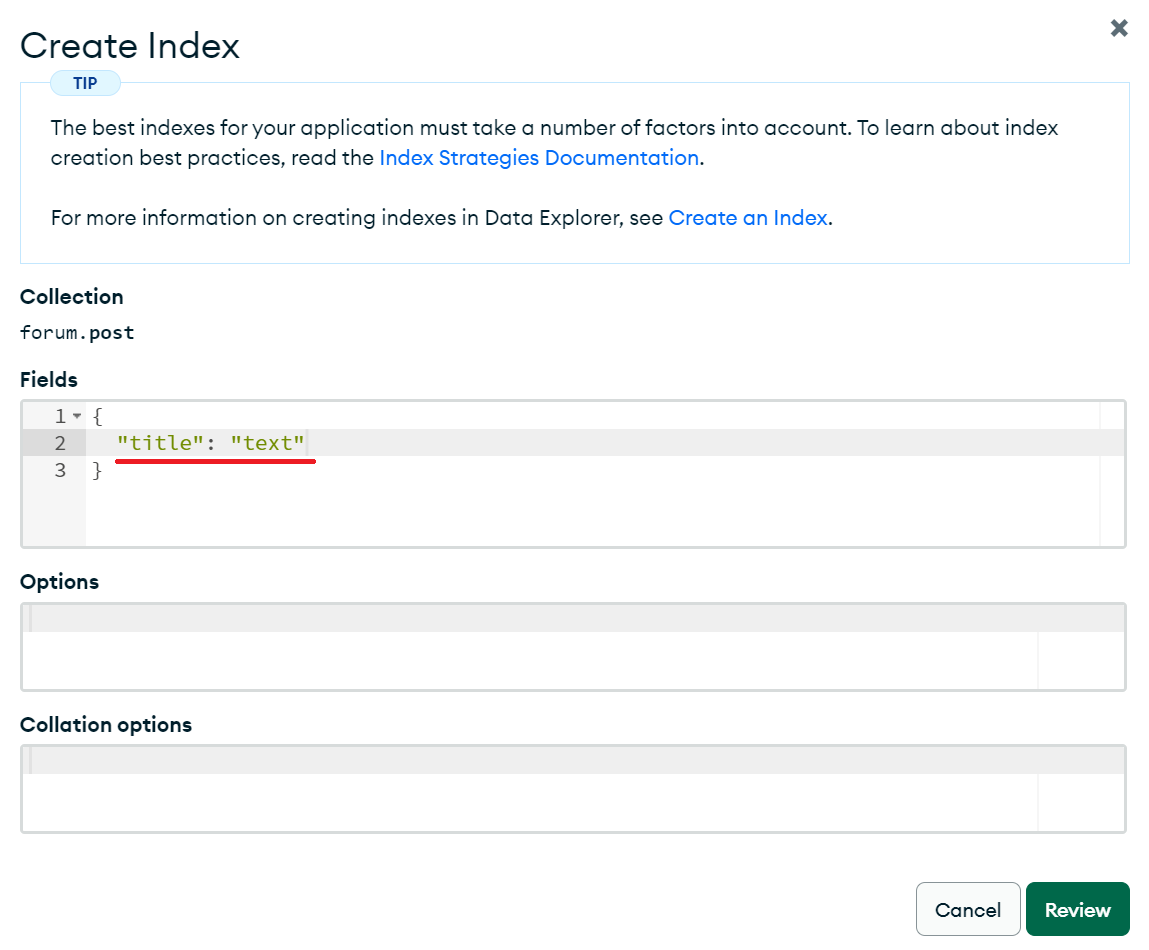
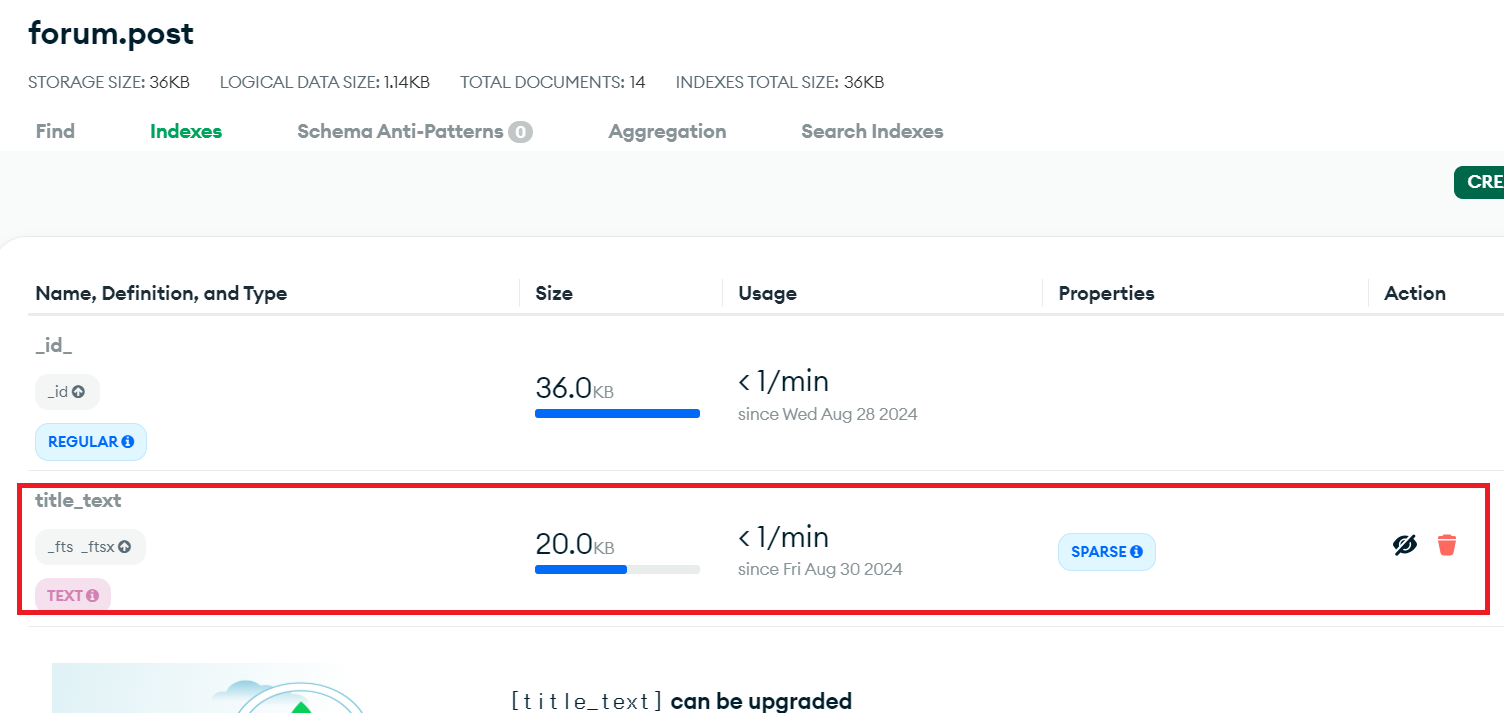
잘 만들어져있으니 코드로 돌아가자.
- 이 index를 사용해서 document를 찾으려면 문법이 조금 달라진다!!
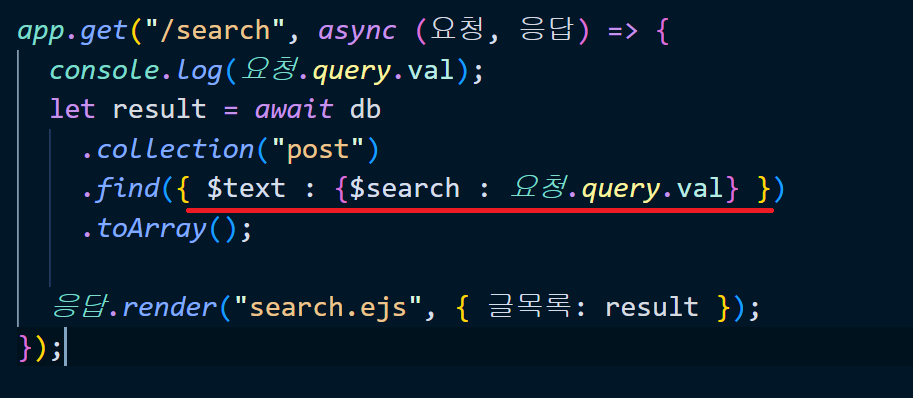
문자형의 경우$text를 사용해주는데,
숫자면 그냥.find()로도 잘 찾아진다고 함.
*근데 단어 위주로밖에 검색할 수 없음. ....... 한국어는 text index는 조금 힘들 듯함.
문자말고 숫자 위주의 검색이 필요하면 좋다..!
부분검색까지 가능한 것을 찾는다면 Search index(Full text index) 사용해주자!!!!
✨성능평가
성능 판단을 위해 .explain('executionStats')를 써보자
db.collection().find( { title : 'kimlrlr' } ).explain('executionStats')
db.collection().find( { $text : { $search: 'kimlrlr' } } ).explain('executionStats')이런 식으로 검색했을때,
totalDocsExamined는 몇 개의 document를 봤는지 말해주는 것이고,
executionStages 안에 있는 stage에 전부 까봤으면 COLLSCAN이라고 뜨니..
이게 나오지 않는 편이 좋다..
