데이터셋 전처리 과정
이제부터 파이썬을 사용하여 데이터를 전처리하는 과정을 상세히 설명하겠다. 데이터셋의 문제점을 해결하고 이를 재구조화하는 과정을 단계별로 진행해보자.
1. 데이터 재구조화: 피벗 테이블 및 멜트
피벗 테이블을 사용하여 데이터를 요약하고,
멜트(melt) 메서드를 사용하여 데이터를 다시 세로로 긴 형태로 재구조화한다.
2.1 피벗 테이블 생성
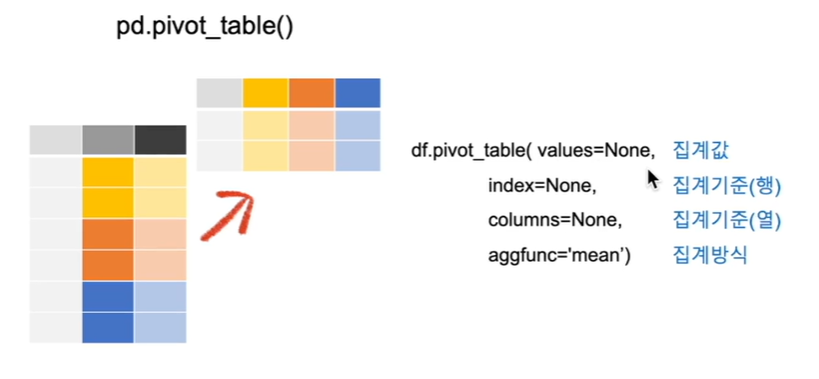
피벗 테이블은 엑셀의 피버 테이블과 동일하며 세로로 긴 형태의 데이터를 집계해 주는 역할을 한다.
우리의 지금 데이터셋은 이 피버 테이블이 된 후에 데이터셋 형태를 갖고 있다라고 볼 수 있다.
어떤 카테고리를 기준으로 집계할 것인지를 지정할 수 있고 어떤 값을 집계할 것인지를 지정할 수 있고, 그리고 이 값을 집계할 때 어떤 방식으로 집계할 것인지 예를 들어 값들의 평균 값을 낼 것인지 값들의 총합을 구할 것인지, 값들 중 최댓값을 구할 것인지 이러한 집계 방식을 지정할 수 있다.
# 예시 피벗 테이블 생성
pivot_df = pd.pivot_table(df, values='거래액', index=['상품군'], columns=['운영 형태'], aggfunc='sum')
print(pivot_df.head())
df.pivot_table(values=None, 집계값
index=None, 집계기준(행)
columns=None, 집계기준(열)
aggfunc='mean') 집계방식
2.2 멜트 메서드를 이용한 재구조화
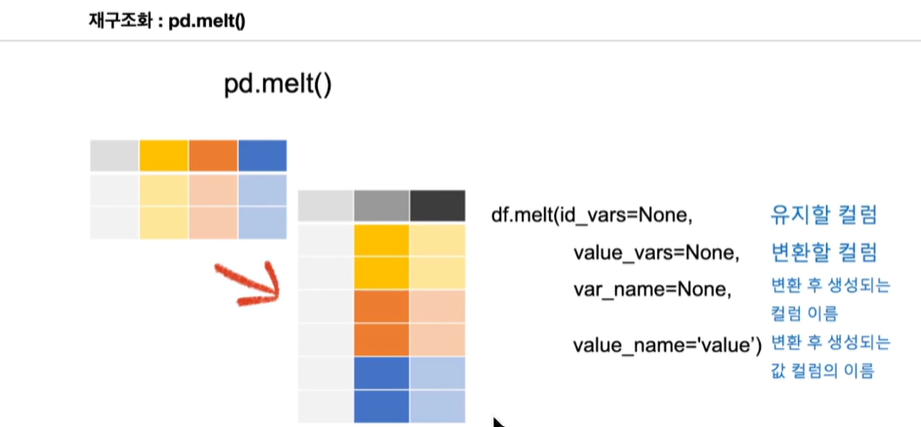
이 피버 테이블을 반대로 만드는 역할이 판다스의 멜트이다. 판다스의 멜트는 집계된 형태의 데이터를 다시 세로로 길게 펴주는 그런 역할을 하는 메서드이다.
멜트는 집계된 형태의 데이터셋을 다시 세로로 길게 늘어뜨려주는 역할을 하며 그래서 크게 지정할 수 있는 것들은 벨트를 통해서 유지한 컬럼을 지정할 수 있고 변환할 컬럼, 즉 오른쪽으로 긴 형태였는데 세로로 길게 만들어줄 컬럼을 지정할 수 있다.
# 데이터 멜트 (재구조화)
melted_df = df.melt(id_vars=['상품군'], var_name='운영 형태', value_name='거래액')
print(melted_df.head())
df.melt(id_vars=None, 유지할 컬럼
value_vars=None, 변환할 컬럼
var_name=None, 변환 후 생성되는 컬럼 이름
value_name='value') 변환 후 생성되는 값 컬럼의 이름
2. 라이브러리 임포트 및 파일 불러오기
우선 필요한 라이브러리를 임포트하고 데이터를 불러오는 과정이다.
import pandas as pd
# 데이터 파일 경로
file_path = '온라인 쇼핑몰 운영 형태별 상품군별 거래액.csv'
# 데이터 읽기 (인코딩 설정)
df = pd.read_csv(file_path, encoding='cp949')
# 데이터 확인
print(df.head())
데이터 분석 스쿨 블로그 입니다.