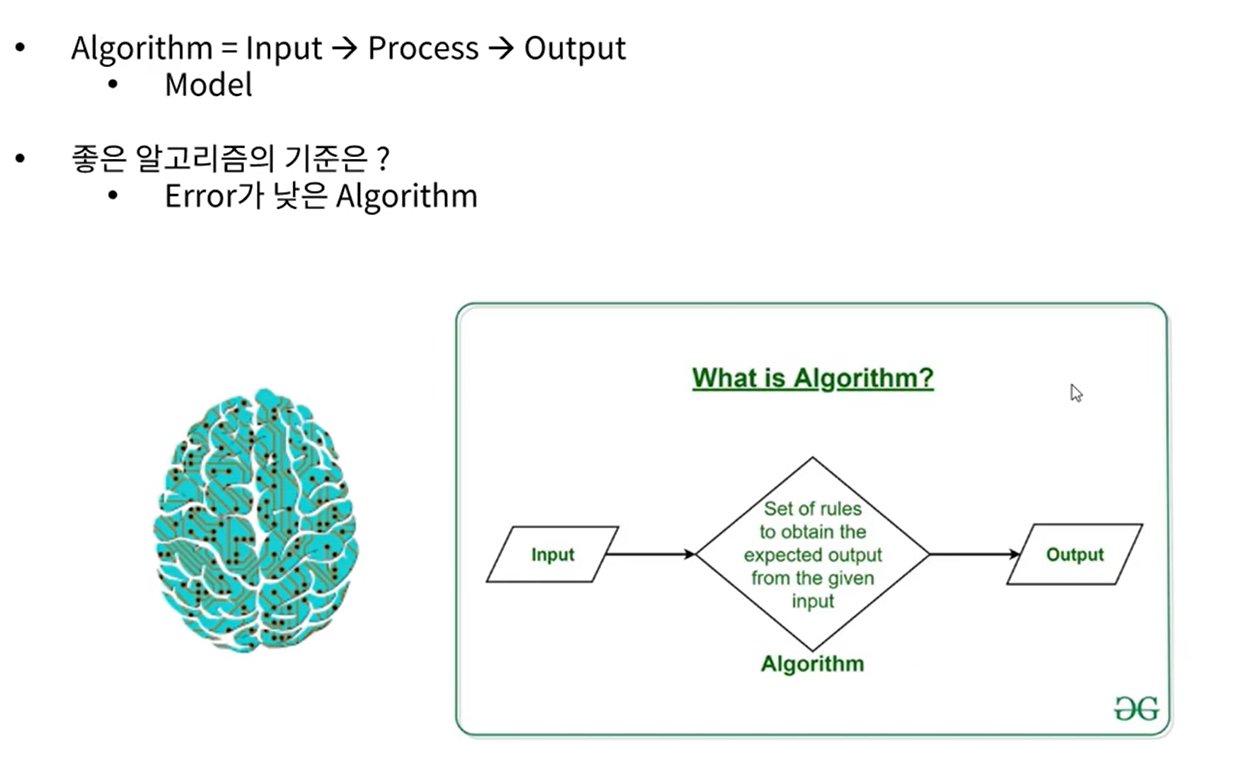
[머신러닝] : Lost Function / 손실함수, error, variance, bias, 추정 값, 예측 값, 실제 값, Mse
▶ 요약
-
Lost Function은 모델의 예측값과 실제 값 사이의 차이를 계산하는 함수이다.
-
편향 (Bias)은 모델의 예측값과 실제 값 사이의 평균적인 차이를 의미한다.
-
분산은 모델의 예측값이 평균적으로 퍼져 있는 정도를 나타낸다.
(1) Lost function (손실함수)
-
손실 함수는 모델의 예측값과 실제 값 사이의 차이를 계산하는 함수이다.
-
주로 사용되는 손실 함수에는 평균 제곱 오차(MSE)가 있으며 손실 함수의 값이 낮을수록 에러가 적다는 것을 의미하며 모델이 예측을 더 정확하게 수행한다고 할 수 있다.
(2) 편향 (Bias)과 분산 (Variance)
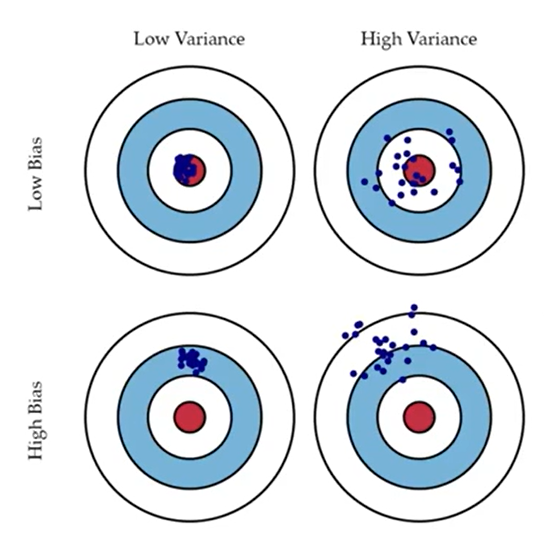
1. 편향 (Bias):
-
편향은 모델의 예측값과 실제 목표로 하는 값 사이의 평균적인 차이를 의미한다. 즉, 모델이 실제 목표로 하는 값으로 예측하지 못하고 얼마나 틀린 방향으로 예측하는 경향을 보이는 것인지를 나타낸다.
-
편향이 크면 모델이 데이터의 복잡성을 충분히 반영하지 못하고 일반화를 잘 하지 못하는 경향이 있다. 그래서 편향이 크면 실제로 목표하는 값에서 예측한 값이 완전히 벗어나 다른 방향으로 에측한 값이 나오고 참 값에서 멀어지게 된다.
2. 분산 (Variance):
-
분산은 모델의 예측값이 평균적으로 퍼져 있는 정도를 나타내는 것이다. 즉, 예측값의 변동성을 의미한다.
-
분산이 크면 모델이 작은 데이터 변화에도 예측이 크게 달라질 수 있게 되고 실제로 목표하는 값에 가깝게 예측 값이 분포하지 못하고 흩어져서 분포하게 된다.
3. 편향과 분산의 관계:

-
편향과 분산은 서로 상충하는 관계에 있다. 모델을 복잡하게 만들면 편향은 줄어들지만 분산은 증가할 수 있고, 반대로 모델을 간단하게 만들면 편향은 커지고 분산은 줄어들 수 있다. 하지만 보통 분산을 조절하여 모델링을 하는 것이 더 낫다.
-
underfitting은 편향이 높고 분산이 낮은 것으로 아예 예측한 값에서 벗어났다고 판단하는 것이다. -
overfitting은 편향은 낮지만 분산이 높아 분산을 조금만 조절 했을 때 값이 쉽게 바뀌게 된다.
