
트랜잭션 격리 수준에 대한 이해가 부족하다면 이전 포스팅인 트랜잭션 격리 수준(Isolation)을 먼저 읽고 오는 것을 권장합니다.
동시성 제어(Concurrency Control)란
동시성 제어(Concurrency Control): 동시성 제어는 데이터베이스와 같은 공유 자원에서 여러 사용자(프로세스와 쓰레드)가 동시에 작업을 수행할 때 데이터의 무결성을 유지하고 충돌을 방지하기 위한 메커니즘이다. 이를 통해 다수의 트랜잭션이 동시에 실행되더라도 데이터의 일관성과 정확성이 보장된다.
동시성 제어가 제대로 이루어지지 않으면 어떠한 문제점들이 발생할 수 있을까???
예를 들어 쇼핑몰에 주문이 들어와 결제가 이루어지고 해당 상품의 재고 수가 1 감소해야 하는 상황이라고 가정해보자.
하지만 만약 똑같은 상품에 5개의 주문들이 거의 동시에 들어오고 동시성 제어가 제대로 되어 있지 않다면 재고가 5가 감소해야 되는데 그보다 적은 3, 4개만 감소하는 상황이 발생하여 데이터의 정확성과 무결성이 무너지는 문제점이 발생할 수도 있다.
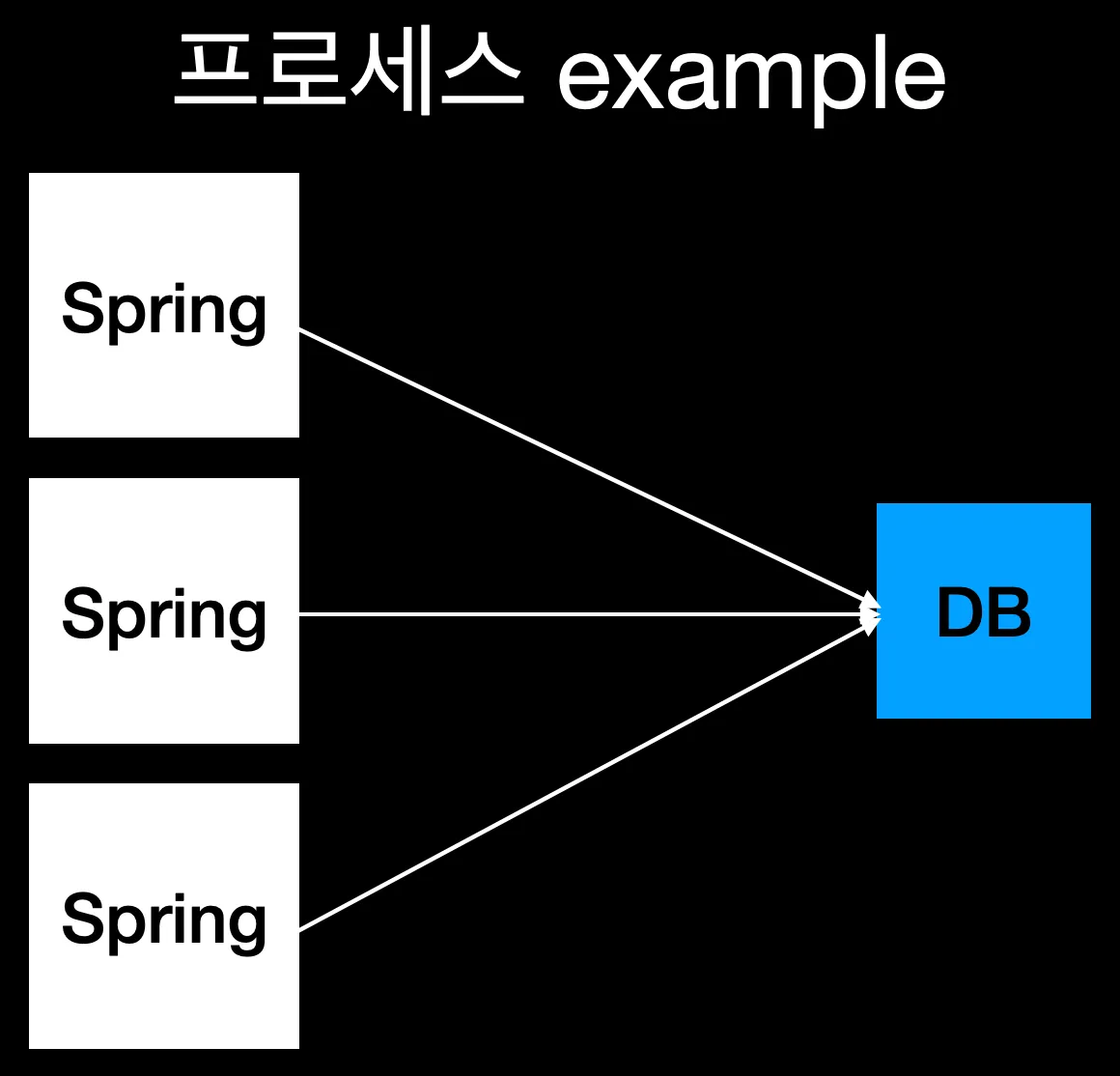
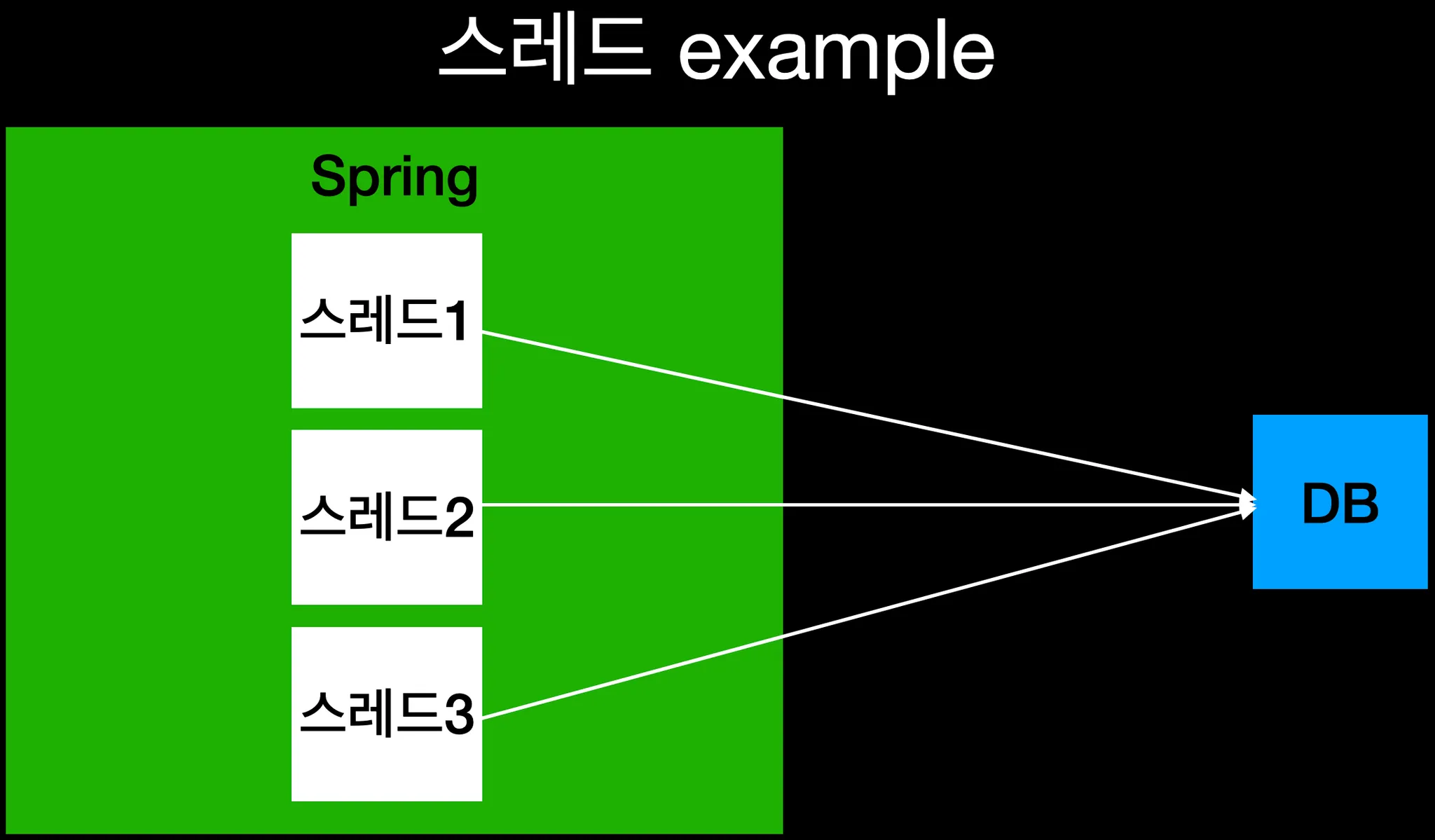
(※ 프로세스는 하나의 프로그램, 쓰레드는 하나의 프로세스 안에서의 각 작업의 단위이다. 스프링에서는 각 요청에 하나의 쓰레드가 할당된다.)
쓰레드 1과 쓰레드 2와 쓰레드 3이 동시에 하나의 데이터를 수정하려고 접근한다고 생각해보자. 과연 어떤 쓰레드의 요청이 최종적으로 반영되게 될까?
정답은 그때 그때 달라서 아무도 모른다이다.
이러한 다수의 동시성이 일어나는 상황에서 생겨나는 현상이 바로 Race Condition이다.
Race Condition(경쟁 상태): Race Condition은 두 개 이상의 프로세스나 스레드가 동시에 공유 자원에 접근하거나 작업을 수행할 때, 실행 순서와 타이밍에 따라 결과가 달라질 수 있는 상황을 말한다. 이는 병렬 처리나 멀티스레드 환경에서 흔히 발생하며, 예측하지 못한 결과를 초래할 수 있다.
공유 자원 접근: 여러 스레드나 프로세스가 하나의 자원을 동시에 읽거나 쓰려고 함.실행 순서에 의존: 어떤 스레드가 먼저 실행되느냐에 따라 결과가 달라짐.예측 불가능한 결과: 올바른 데이터 처리나 로직이 보장되지 않음.
예시를 통해 살펴보자.
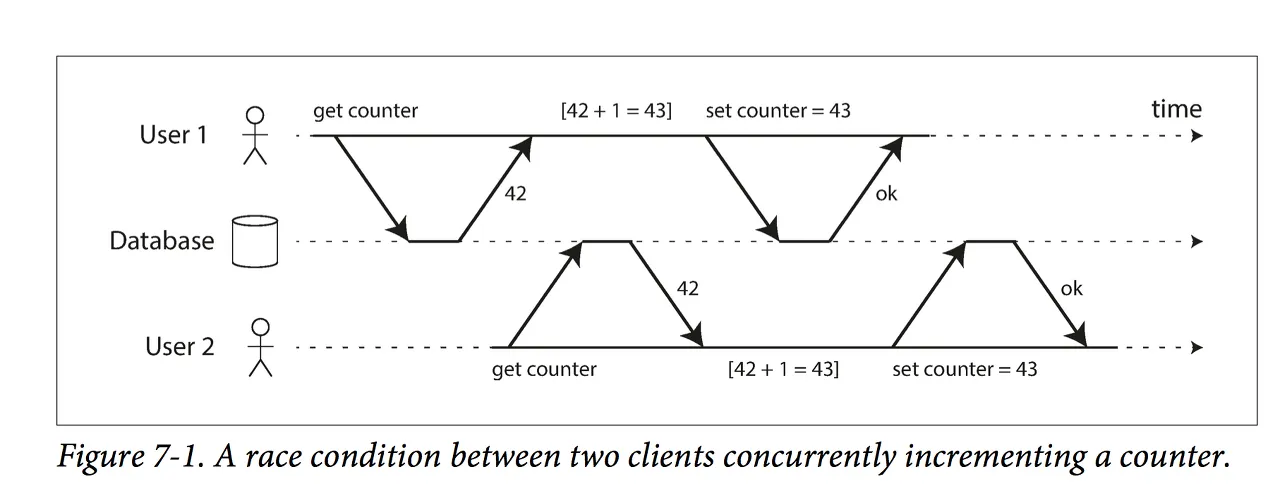
이미지를 보면서 Race Condition에 대해 이해해보자. User 1이 counter = 42라는 데이터를 먼저 읽어오고 아직 수정 및 커밋하지 않은 상태에서 User 2가 또 counter = 42를 읽어온 후 User 1이 counter를 1 증가시켜 43으로 만들고 커밋했지만 직후 User 2가 conter를 1 증가시키고 커밋하면 42라는 수치를 총 2번 증가시켰기 때문에 counter는 44가 되어야 정상이지만 유저 두 명이 각각 42를 1씩 증가시켰기 때문에 counter는 43으로 반영되는 문제가 발생한다.
이러한 문제를 방지하는 것이 바로 동시성 제어이다.
Race Condition의 구체적 유형
동시성이 발생하는 상황에서는 Race condition으로 인하여 여러 문제가 발생할 수 있다.
Dirty Read (더티 리드)
한 트랜잭션이 커밋되지 않은 다른 트랜잭션의 데이터를 읽는 문제.
EX) 트랜잭션 A가 데이터를 변경했으나 아직 커밋하지 않았을 때, 트랜잭션 B가 그 데이터를 읽어 잘못된 값을 사용할 가능성.
Non-Repeatable Read (비반복 읽기)
같은 트랜잭션 내에서 동일한 쿼리를 두 번 실행했을 때, 다른 트랜잭션이 데이터를 수정하거나 삭제하여 결과가 달라지는 문제.
EX) 트랜잭션 A가 데이터를 읽고 나중에 다시 읽을 때 값이 변경됨.
Phantom Read (팬텀 리드)
같은 트랜잭션 내에서 동일한 쿼리를 실행했을 때, 다른 트랜잭션이 새로운 데이터를 삽입해 결과가 달라지는 문제.
EX) 트랜잭션 A가 조건에 맞는 데이터를 읽은 후 다시 쿼리했을 때 새로운 행이 추가됨.
Lost Update (갱신 손실)
두 트랜잭션이 동시에 데이터를 수정하면 마지막에 실행된 트랜잭션의 결과로 이전 업데이트가 덮어씌워지는 문제.
EX) 사용자 A와 B가 동시에 잔액을 수정했을 때, 한쪽의 수정 사항이 유실.
해당 문제들의 자세한 내용은 트랜잭션 격리 수준(Isolation)포스팅에 정리되어 있습니다.
동시성 제어 방법
V1. Java 언어 기능 활용
Java에는 동시성을 제어할 수 있는 synchronized, ReentrantLock 등의 여러 기능들이 존재한다.
그 중에서도 대표적으로 synchronized는 메서드나 블록에 적용하여 해당 코드가 동시에 여러 스레드에 의해 실행되지 않도록 보장하여 멀티스레드 환경에서 동기화된 코드를 만들기 위해 사용 방법이다.
실제 예시 코드를 통해 살펴보자.
public class SynchronizedExample {
private int counter = 0;
// 동기화된 메서드
public synchronized void increment() {
counter++;
}
public int getCounter() {
return counter;
}
public static void main(String[] args) {
SynchronizedExample example = new SynchronizedExample();
// 두 개의 스레드 생성
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
example.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
example.increment();
}
});
// 스레드 시작
thread1.start();
thread2.start();
// 스레드가 종료될 때까지 대기
try {
// join() : 호출한 스레드(현재 실행 중인 스레드)가 특정 다른 스레드가 종료될 때까지 실행을 멈추고(차단하고) 기다리게 하는 동기화 기능
thread1.join();
thread2.join();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 최종 결과 출력
System.out.println("Final counter value: " + example.getCounter());
}
}
increment() 메서드에 synchronized 키워드를 사용하여 한 번에 하나의 스레드만 이 메서드를 실행할 수 있도록 하였다. 이를 통해 다중 스레드가 동시에 counter 값을 변경하는 상황에서 데이터의 일관성을 보장한다.
한 번에 하나의 스레드만 메서드를 실행하였기 때문에 thread1과 thread2는 각각 1000번씩 increment() 메서드를 호출했다. 동기화 덕분에 경쟁 상태가 발생하지 않고, counter의 값은 제대로 2000이 출력된다.
하지만 synchronized는 많은 단점들이 존재한다. 동기화 방식이기 때문에 성능적으로 부족하고 교착 상태(Deadlock) 문제가 발생할 수 있으며, 이를 예방하기 위한 설계가 필요하다.
자바의 synchronized는 간단한 동기화 문제를 해결하는 데 유용하지만, 고성능 멀티스레드 프로그램을 위해서는 java.util.concurrent 패키지의 도구를 활용하는 것이 일반적이다.
하지만 이러한 자바 기능을 이용한 동시성 제어는 그다지 권장되지 않는다.
synchronized는 공유 자원의 동시 접근을 제어하는 데 사용된다.
공유 자원이 서버에 존재하면 서버가 상태(Stateful)를 유지하게 되는데, 이는 Stateless 서버의 설계 원칙에 위배된다.
서버는 상태를 가지지 않고 최대한 Statless해야 한다. Scale out 등으로 인하여 서버가 여러 대 존재한다고 가정해보자. 이러면 여러 개의 프로세스가 생겨나는데 해당 방식으로는 스레드간에 동시성 처리는 가능하지만 프로세스간의 동시성 처리는 적용되지 않는다.
결론적으로 자바 기능만을 이용하여 동시성 처리를 하면 한 서버의 상태가 다른 서버와 동기화될 수 없으므로, 결과적으로 Lock이 동작하지 않게 된다. 기본적으로 서버는 항상 확장 가능하게, stateless하게 설계해야 한다.
서버 statless: 서버가 상태를 가지지 않는다(statless)는 것은 서버가 각 요청과 관련된 정보를 메모리 등 서버에는 저장하지 않고, 요청마다 독립적으로 처리한다는 의미이다.
stateless한 서버는 상태 관리가 필요한 경우DB,쿠키,HTTP 헤더,JWT,캐시 서버(Redis, Memcached 등)서버 외부의 시스템에 맡기고 결과만을 반환해야 하는데synchronized같은 자바 기능을 통해 동시성을 제어하면 서버의 메모리 변수에 데이터를 저장하고 여러 요청에서 이를 읽고 써야 하기 때문에 서버가stateful하게 된다.
V2. 트랜잭션 격리 레벨 활용(Transaction Isolation Level)
해당 포스팅에서는 트랜잭션 격리 수준에 대한 별도의 설명은 제외되었으니 트랜잭션 격리 수준에 대한 이해가 부족하다면 이전 포스팅인 트랜잭션 격리 수준(Isolation)을 먼저 읽고 오는 것을 권장합니다.
서버의 stateless를 유지하고 단순하고 쉽게 동시성 제어를 하고 싶다면 전체 데이터베이스를 대상으로 트랜잭션의 전역(global) 격리 수준을 Serializable로 설정하면 된다.
다만 이 방식에도 치명적인 단점들이 존재한다.
우선 트랜잭션을 직렬적으로 하나 하나 처리하면서 데이터 무결성과 안정성을 보장하는 방식이기 때문에 동시성으로 인한 문제는 일어나지 않지만 성능이 매우 나쁘기 때문에 프로그램의 전반적인 성능이 매우 열악할 것이다.
그렇다면 전역적으로가 아니라 동시성 문제가 일어나는 트랜잭션에만 @Transactional(isolation = Isolation.SERIALIZABLE)을 걸면 되지 않을까???
하지만 이 부분적으로 Serializable을 거는 방식에는 문제가 있다.
왜냐하면, Serializable은 WRITE는 막지만, READ는 막지 못하기 때문이다. 단순 SELECT문으로 테이블을 읽어버리기 때문에 다른 트랜잭션이 여전히 오래된 데이터를 읽고 사용할 가능성이 있기 때문에 마찬가지로 동시성 제어가 되지 못한다.
또한 Serializable은 데이터 읽기 시 공유 잠금(Shared Lock), 쓰기 시 배타적 잠금(Exclusive Lock)을 사용하는데 서로 다른 트랜잭션이 동일한 자원에 대해 상충하는 잠금을 요청하면 Dead Lock(데드락)이 발생할 가능성이 높아지고 Serializable에서는 데이터를 완벽히 일관되게 처리하기 위해 잠금을 많이 걸기 때문에 Dead Lock은 거의 필연적이다.
이러한 여러 단점들 때문에 Serializable을 통한 동시성 제어는 별로 권장하지 않는 바이다.
V3. DB 레벨에서의 Lock 제어(Locking)

스프링에서는 낙관적 락(Optimistic Lock), 비관적 락(Pessimistic Lock) 두 가지 방식의 락(Lock)을 제공한다.
1. 낙관적 락(Optimistic Lock)

낙관적 락(Optimistic Lock): 낙관적 락은 데이터베이스나 애플리케이션에서 데이터의 충돌 가능성이 낮다고 가정하고, 락을 걸지 않고 동시성을 제어하는 방법이다. 데이터의 수정이 끝날 때version필드나타임 스탬프등을 통하여 데이터가 변경되었는지 확인하는 방식으로 충돌 여부를 검사하여 문제를 해결하는 방식이다.
장점으로는 데이터를 읽는 시점에는 아무 대응하지 않고 데이터를 쓰는 시점에 대응하기 때문에 다른 트랜잭션에 영향을 끼치지 않는다.
즉, 낙관적 락은 데이터를 읽을 때는 락을 걸지 않고, 데이터를 업데이트할 때만 이전 데이터와 현재 데이터를 비교하여 충돌 여부를 판단한다. 이 방식은 데이터베이스의 성능 저하를 최소화하고, 동시성을 높이는 데 유리하다.
하지만 충돌이 일어날 때마다 재시도를 해야 한다는 단점이 존재하기 때문에 충돌이 자주 발생하는 상황이면 반복되는 재시도들로 인하여 성능이 저하된다.
이미지를 통하여 낙관적 락의 원리를 살펴보자.

트랜잭션 A에서Course의 react라는 데이터를 조회하고 있는데 비관적 락과 다르게 아무 락도 걸지 않았기 때문에 트랜잭션 B에서도 같은 데이터를 조회할 수 있다. 낙관적 락에서는 트랜잭션이 데이터를 조회할 때 해당 데이터의 version 값을 함께 읽어온다.
근데 트랜잭션 A보다 트랜잭션 B가 먼저 데이터를 Java로 수정해서 커밋을 시도하면 DB는 UPDATE 시점에 현재 DB에 저장된 version 값과 트랜잭션이 처음 조회했을 때의 version 값을 비교한다. 만약 두 값이 동일하면 다른 트랜잭션의 변경이 없었다고 판단해 업데이트를 수행하고 version을 증가시키며, 값이 다르면 이미 다른 트랜잭션에 의해 수정된 데이터로 판단하여 업데이트를 실패시킨다.
(※ version: 각 트랜잭션에 의해 데이터가 몇 번째로 수정되었나 확인하는 수치 정도로 생각하면 될 듯하다.)
이후 트랜잭션 A에서 데이터 수정 후 커밋하는 과정에서 DB에 있는 데이터의 현재 version 과 해당 트랜잭션이 들고 있는 수정한 데이터의 verson 을 비교해보니까 DB의 version은 트랜잭션 B에 의해 이미 수정되어 값이 2인데 반해 트랜잭션 A는 수정되기 이전의 데이터를 사용왔기 때문에 version이 1이어서 version의 값이 동일하지 않아 커밋에 실패하고 롤백되고 다시 조회 - 수정 시도하는 과정을 시도한다.
만약 충돌이 계속 발생한다면 (retry count를 따로 설정해주지 않는 이상은) 이러한 조회 - 수정 시도 과정이 반복이 될 것이고 애플리케이션의 성능 저하가 심화될 것이다.
JPA에서 낙관적 락을 적용하고 싶다면 락을 걸고 싶은 대상의 엔티티에 version이라는 필드를 만들고 @Version 애노테이션을 붙여 활성화해줘야 한다.
@Version을 사용하면 데이터를 조회하면 낙관적 락이 적용되어 쓰기 작업을 수행하면 내부적으로 version의 수치가 1씩 증가하도록 되어 있기 때문에 따로 증가 로직을 구현하면 안 된다.
[엔티티에 version 추가]
import jakarta.persistence.*;
@Entity
public class Example {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int quantity;
@Version // 버전 필드로 낙관적 락을 사용
private Long version;
}
이후 데이터 충돌을 감지하는 로직과 충돌 시 재시도를 처리하는 서비스 로직을 추가해야 한다.
낙관적 락은 충돌이 발생할 경우 OptimisticLockException을 던지는데 서비스 로직에서 이를 감지하고 처리해줘야 한다.
상품의 재고를 감소시키는 예시 코드로 낙관적 락의 서비스 로직 처리를 살펴보자.
// 충돌 감지 및 예외 처리 로직
@Transactional
public void updateStock(Long productId, int quantity) {
try {
Product product = productRepository.findById(productId)
.orElseThrow(() -> new IllegalArgumentException("Product not found"));
product.setStock(product.getStock() - quantity);
} catch (OptimisticLockException e) {
// 충돌 시 재시도 또는 사용자에게 알림
throw new RuntimeException("Data conflict occurred. Please try again.");
}
}
// 충돌 발생시 재시도 로직
public void updateWithRetry(Long productId, int quantity, int maxRetries) {
int attempt = 0;
while (attempt < maxRetries) {
try {
updateStock(productId, quantity);
break; // 성공 시 루프 종료
} catch (OptimisticLockException e) {
attempt++;
if (attempt >= maxRetries) {
throw new RuntimeException("Failed to update after " + maxRetries + " attempts");
}
}
}
}2. 비관적 락(Pessimistic Lock)

비관적 락(Pessimistic Lock): 비관적 락은
"충돌이 자주 발생하여 다른 트랜잭션이 내 데이터를 변경할 가능성이 높다"고 가정하고, 데이터 사용을 시작할 때 미리 잠금(Lock)을 걸어 충돌을 방지하는 방식이다.
데이터를 읽거나 쓰기 전에 잠금을 걸어 다른 트랜잭션이 접근하지 못하게 하고 트랜잭션이 끝난 후 잠금을 해제한다.
장점으로는 아예 시작 때 락을 걸어버리기 때문에 다른 트랜잭션들은 대기 중이어서 만약 충돌이 발생하더라도 추가적인 재시도 로직이 필요 없고 일정 시간 기다리거나 쉽게 에러 처리가 가능하여 충돌 비용이 낮고, 확실하게 직접적으로 락을 걸기 때문에 데이터 안정성이 높다는 점이 있다.
하지만 락으로 인하여 특정 자원에 동시에 트랜잭션이 접근하지 못하고 처리 중인 트랜잭션을 제외하고 나머지 트랜잭션들은 대기 상태에 있기 때문에 성능 저하가 발생한다.
이미지를 통해 비관적 락의 원리에 대해 천천히 살펴보자.
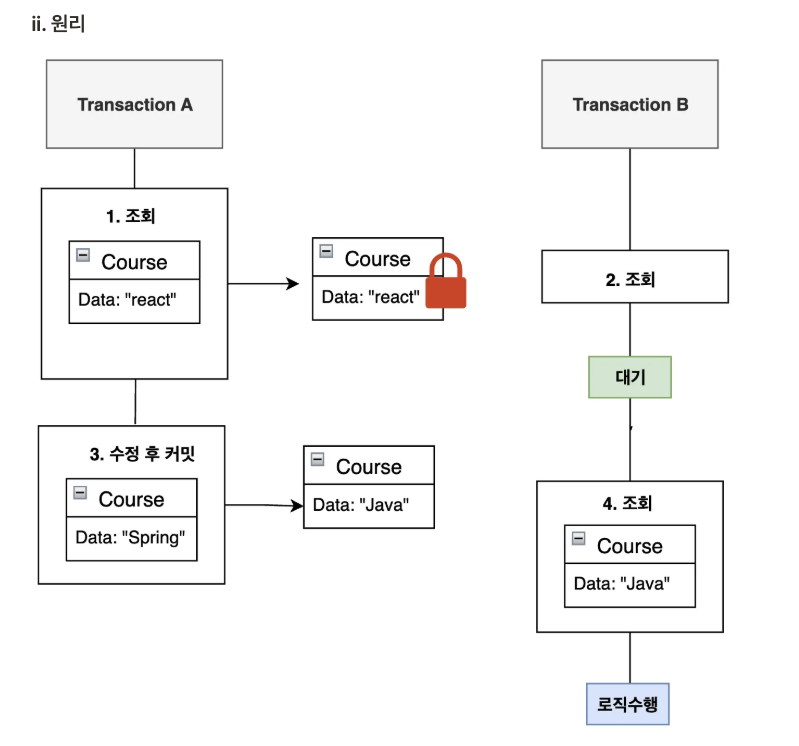
Course라는 테이블의 react라는 같은 데이터에 접근하려는 트랜잭션 A, B가 있다고 가정해보자.
트랜잭션 A에서 먼저 아무 트랜잭션도 사용하고 있지 않은 해당 데이터에 접근하다. 이 때 MySQL에서는 내부적으로 SELECT ... FOR UPDATE 쿼리를 발생시켜 배타 락(Exclusive Lock)을 걸고 특정 행을 다른 트랜잭션이 접근, 수정하거나 삭제하지 못하도록 잠금을 설정한다.
(상황에 따라서는 비관적 락에서 배타 락이 아니라 공유 락(Shared Lock)을 걸도록 설정할 수도 있다. 공유 락을 걸면 MySQL에서 내부적으로 SELECT FOR SHARE 쿼리가 발생한다.)
※
배타 락(Exclusvie Lock)(쓰기 락(Write Lock)): 배타 락(Exclusive Lock)은 (쓰기 락(Write Lock)이라고도 한다) 데이터에 대한읽기와 쓰기 모두를 차단하는 락의 한 종류이다.
배타 락이 걸린 데이터는 해당 트랜잭션이 끝나기 전까지 다른 트랜잭션이 읽거나 수정할 수 없다.
[배타 락 쿼리 예시]
START TRANSACTION;
SELECT * FROM course WHERE course_id = 1 FOR UPDATE;
COMMIT;
공유 락(Shared Lock)(읽기 락(Read Lock)): 공유 락은 다른 트랙재션도 데이터를 읽을 수는 있지만, 수정은 제한하는 락의 한 종류이다. 공유 락은 읽기 작업(Read) 간의 동시성을 허용하면서도 데이터의 일관성을 보장하는 데 사용된다.
즉, 공유 락이 걸린 데이터는 여러 트랜잭션이 동시에 읽을 수 있지만 데이터를 수정하려는 트랜잭션은 해당 공유 락이 해제될 때까지 대기해야 한다.
[공유 락 쿼리 예시]
START TRANSACTION;
-- 공유 락을 걸고 데이터 읽기
SELECT * FROM course WHERE course_id = 1 LOCK IN SHARE MODE;
-- 다른 트랜잭션에서 동일 데이터를 읽는 것은 가능
-- 하지만 데이터 수정은 불가능
COMMIT;
트랜잭션 A가 락을 걸고 작업 도중인데 트랜잭션 B가 해당 데이터에 접근하면 락이 걸려있기 때문에 트랜잭션 B는 트랜잭션 A가 작업을 끝내고 락을 해제할 때까지 대기 상태에 빠진다. 이후 락이 풀리면 트랜잭션 B도 SELECT ... FOR UPDATE 쿼리로 락을 걸고 데이터를 조회하고 로직을 수행한다.
JPA 비관적 락을 사용하고 싶으면 트랜잭션을 필수로 사용하고 @Lock(LockModeType.PESSIMISTIC_WRITE)/@Lock(LockModeType.PESSIMISTIC_READ) 애노테이션을 명시해주거나 EntityManager의 옵션으로 LockModeType.PESSIMISTIC_WRITE/LockModeType.PESSIMISTIC_READ을 명시해주면 된다.
[예시 1: @Lock 사용]
public interface AccountRepository extends JpaRepository<Account, Long> {
// @Lock(LockModeType.PESSIMISTIC_READ) // 공유 락
@Lock(LockModeType.PESSIMISTIC_WRITE) // 배타 락
@Query("SELECT a FROM Account a WHERE a.id = :id")
Optional<Account> findByIdWithLock(@Param("id") Long id);
}
[예시 2: EntityManager 사용]
@Service
public class AccountService {
@PersistenceContext
private EntityManager entityManager;
@Transactional
public Account findAccountWithLock(Long id) {
// return entityManager.find(Account.class, id, LockModeType.PESSIMISTIC_WRITE); // 공유 락
return entityManager.find(Account.class, id, LockModeType.PESSIMISTIC_WRITE); // 배타 락
}
}
비관적 락을 사용하면 데이터 일관성을 확실하게 유지할 수 있고 충돌을 미리 사전에 방지하기 때문에 트랜잭션 실패가 현저히 줄어들어 트랜잭션 충돌로 인한 회복 비용을 아낄 수 있다는 장점이 존재한다.
하지만 데드 락이 발생할 위험성이 존재하며 이를 방지하거나 해결하기 위한 설계가 필요하고 성능이 저하된다는 단점이 존재한다.
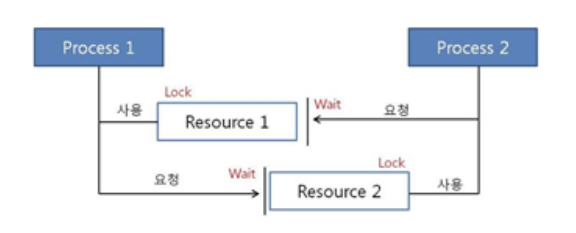
데드 락(Dead Lock): 데드 락은 컴퓨터 시스템에서 두 개 이상의 작업(프로세스, 스레드, 트랜잭션 등)이 서로 상대방이 점유한 자원을 무한정 기다리며 멈춰 서서 아무것도 완료되지 못하는 교착 상태이다. 이는 동시성 제어 환경에서 주로 발생하며, 각 프로세스나 트랜잭션이 필요한 자원을 얻지 못한 채 대기하면서 작업이 진행되지 않는 상태를 의미한다.
낙관적 락 vs 비관적 락

3. 분산 락 (By Redisson)
분산 락: 분산 락(Distributed Lock)은 여러 대의 서버나 프로세스가 동시에 하나의 공유 자원(데이터, 파일 등)에 접근하려 할 때, 한 번에 단 하나의 요청만 자원을 사용하도록 제어하여 데이터 무결성과 동시성 문제를 해결하는 기술이다. 단일 시스템에서는 단일 메모리 공간이나 OS 수준의 락으로 동시성 문제를 해결할 수 있지만, 분산 환경에서는 여러 노드에서 동시에 동일한 리소스를 사용할 수 있기 때문에 별도의 분산 락 메커니즘이 필요하다.
분산 환경에서 동일한 자원에 대한 경쟁 조건을 방지하고 데이터의 무결성을 유지하기 위해 사용된다. 일반적으로 Redis, ZooKeeper, MySQL 등의 외부 공용 저장소를 이용하여 구현한다.
분산락에 일반적으로 사용되는 Redis에는 Jedis, Lettuce, Redisson 등의 다양한 선택지들이 존재하지만 이번 포스팅에서는 현재 가장 각광받고 있는 Redisson를 통한 분산 락을 살펴보자.
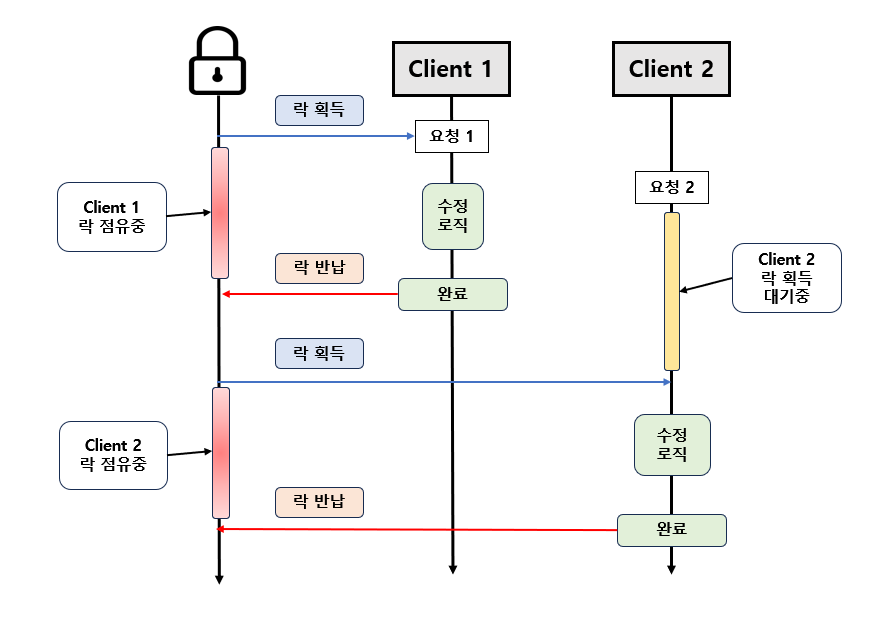
한 서버가 특정 자원을 점유하여 사용하고 싶으면 락 관리자인 Redisson에게 해당 자원에 대한 락을 요청하는데, 만약 아무 서버도 점유하지 않은 상태라면 해당 자원에 대한 락을 획득하고 이미 다른 서버가 점유 중이라면 서버의 요청은 대기하거나 거절된다. 이후 자원을 점유하고 있던 서버의 작업이 끝나면 락은 다시 락 관리작인 Redisson에게 반납되고 Redisson은 대기하고 있던 다른 서버에 락을 부여한다.
Redisson은 Redis의 Pub/sub 기능을 사용해서 Lock 획득을 재시도한다.
만약 동시성 문제로 Lock 획득에 실패하면, Redisson은 특정 채널을 구독하고, Lock이 다시 획득할 수 있는 이벤트가 재발행되어 신호를 받았을 때, 다시 Lock 점유 권한을 부여하는 것이다.
이는 Lock이 획득될 때까지 계속 setnx, setex과 같은 명령어를 이용해 지속적으로 Redis에게 락이 해제되었는지 요청을 보내는 방식인 스핀락을 사용하는 Lettuce보다 효율적이고, Redis 서버에도 부하를 덜 간다는 장점이 존재한다.
또한 Lettuce로 분산락을 사용하기 위해서는 setnx, setex 등을 이용해 분산락을 직접 구현해야 돼서 개발자가 직접 retry, timeout과 같은 기능을 구현해 주어야 한다는 번거로움이 있지만,
이에 비해 Redisson은 별도의 Lock interface를 지원한다. 락에 대해 타임아웃과 같은 설정을 지원하기에 락을 보다 안전하게 사용할 수 있다.
Redison 환경 설정
Redisson을 통한 분산 락을 사용하기 위해서는 우선 build.gradle에 Redis와 Redisson 의존성 주입이 필요하다.
[build.gradle]
// 필요한 의존성
implementation 'org.springframework.boot:spring-boot-starter-data-redis' // 레디스 주입
implementation 'org.redisson:redisson-spring-boot-starter:3.37.0' // 레디슨 주입※
Redisson: Redisson은 Java 기반의 Redis 클라이언트 라이브러리로, Redis를 더 쉽게 활용할 수 있게 도와주는 고수준 API를 제공한다. Redis의 다양한 기능을 Java 애플리케이션에서 손쉽게 사용할 수 있도록 하며, 특히 분산 락, 분산 데이터 구조, 분산 캐시 등 고급 기능을 지원한다.
[RedissonConfig]
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedissonConfig {
@Value("${spring.redis.host}")
private String redisHost;
@Value("${spring.redis.port}")
private int redisPort;
private static final String REDISSON_HOST_PREFIX = "redis://";
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
// 단일 노드(기본 레디스 or 레디스 센티널) 사용시
config.useSingleServer().setAddress(REDISSON_HOST_PREFIX + "localhost:6379");
// 레디스 클러스터 사용시
// config.useClusterServers().addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001");
return Redisson.create(config);
}
}
이후 Redis가 기본 포트인 localhost:6379에 떠 있다는 가정 하에서 RedissonClient을 사용하기 위해 Redisson 설정 클래스를 만들고 Bean으로 등록해주자.
분산 락에 AOP 적용
분산락을 구현하는 데에는 다양한 방법이 존재한다. 그 중에서도 애노테이션을 이용하여 AOP를 적용하면 여러 이점을 챙길 수 있다.
- 분산락 처리 로직을 비즈니스 로직이 오염되지 않게 분리해서 사용할 수 있다.
- waitTime, leaseTime을 커스텀하게 지정이 가능하다.
- 락의 name에 대해 사용자로부터 손쉽게 커스텀하게 받아 처리할 수 있다.
- 추가 요구사항에 대해서 공통으로 관리할 수 있다.
[DistributedLock.java]
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DistributedLock {
/**
* 락의 이름
*/
String key();
/**
* 락의 시간 단위
*/
TimeUnit timeUnit() default TimeUnit.SECONDS;
/**
* 락을 기다리는 시간 (default - 5s)
* 락 획득을 위해 waitTime 만큼 대기한다
*/
long waitTime() default 5L;
/**
* 락 임대 시간 (default - 3s)
* 락을 획득한 이후 leaseTime 이 지나면 락을 해제한다
*/
long leaseTime() default 3L;
}DistributedLock 애노테이션의 파라미터 중에서 key는 필수, 나머지 값들은 커스텀 하게 설정할 수 있다.
[DistributedLockAop]
/**
* @DistributedLock 선언 시 수행되는 Aop class
*/
@Aspect // 특정 시점(메서드 호출 전후 등)에 실행될 로직을 정의
@Component
@RequiredArgsConstructor
@Sl4j
public class DistributedLockAop {
// 모든 락 키에 "LOCK:"를 접두사로 추가하여 이름 충돌을 방지
private static final String REDISSON_LOCK_PREFIX = "LOCK:";
// Redisson의 클라이언트 객체로, Redis와의 통신 및 락 관리를 수행
private final RedissonClient redissonClient;
// 트랜잭션 처리를 지원하는 커스텀 클래스. AOP로 트랜잭션 경계를 설정하는 역할
private final AopForTransaction aopForTransaction;
@Around("@annotation(com.kurly.rms.aop.DistributedLock)")
public Object lock(final ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature(); // 호출된 메서드의 메타정보를 가져오기
Method method = signature.getMethod(); // 메서드 정보를 추출
DistributedLock distributedLock = method.getAnnotation(DistributedLock.class); // 해당 메서드에 선언된 @DistributedLock 어노테이션 정보를 가져오기. 이 어노테이션을 통해 락 키, 대기 시간, 임대 시간 등을 설정
String key = REDISSON_LOCK_PREFIX + CustomSpringELParser.getDynamicValue(signature.getParameterNames(), joinPoint.getArgs(), distributedLock.key()); // 메서드의 매개변수 이름과 값, 그리고 @DistributedLock의 key() 속성을 기반으로 동적인 락 키를 생성
RLock rLock = redissonClient.getLock(key); // (1) 주어진 키에 대한 Redis 기반 락 객체(RLock)를 가져오기. 이 객체를 사용하여 락을 획득하거나 해제
try {
// available: 락 획득 여부
boolean available = rLock.tryLock(distributedLock.waitTime(), distributedLock.leaseTime(), distributedLock.timeUnit()); // (2) 지정된 대기 시간(waitTime) 동안 락 시도. 락을 획득하면 임대 시간(leaseTime) 동안 유지
if (!available) {
return false; // 락을 획득하지 못한 경우 false를 반환
}
return aopForTransaction.proceed(joinPoint); // (3) AOP를 사용해 원래 호출된 비즈니스 메서드를 실행
} catch (InterruptedException e) {
throw new InterruptedException();
} finally {
try {
rLock.unlock(); // (4) 락을 해제
} catch (IllegalMonitorStateException e) {
// 예외 발생 시 락이 이미 해제되었음을 로그로 기록
log.info("Redisson Lock Already UnLock {} {}",
kv("serviceName", method.getName()),
kv("key", key)
);
}
}
}
}
DistributedLockAop은 @DistributedLock 어노테이션 선언 시 수행되는 aop 클래스이다.
@DistributedLock 어노테이션의 파라미터 값을 가져와 분산락을 획득 시도하고 애노테이션이 선언된 메서드를 실행한다.
작동 방식과 순서는 다음과 같다.
- 락의 이름으로 RLock 인스턴스를 가져온다.
- 정의된 waitTime까지 획득을 시도하고 락을 획득했으면 정의된 leaseTime이 지나면 잠금을 해제한다.
- DistributedLock 어노테이션이 선언된 메서드를 별도의 트랜잭션으로 실행한다.
- 종료 시 무조건 락을 해제한다.
해당 로직에서 신경써야 할 부분은 CustomSpringELParser 와 AopForTransaction 클래스이다.
이 두 클래스는 어떤 역할을 수행할까???
[CustomSpringELParser]
/**
* Spring Expression Language Parser
*/
public class CustomSpringELParser {
private CustomSpringELParser() {
}
public static Object getDynamicValue(String[] parameterNames, Object[] args, String key) {
ExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i]);
}
return parser.parseExpression(key).getValue(context, Object.class);
}
}CustomSpringELParser는 전달받은 Lock의 이름을 Spring Expression Language 로 파싱하여 읽어온다.
※
Spring Expression Language(SpEL): SPEL(스프링 표현 언어)는 Spring Framework에서 제공하는 강력하고 유연한 표현 언어로, 런타임 시점에 객체 그래프의 속성, 메서드 호출, 배열/리스트/맵 조회, 조건문, 수학 연산 등을 처리할 수 있게 설계되었다.
스프링의 빈 설정, AOP, 보안, 데이터 검증 등 다양한 영역에서 표현식을 동적으로 정의하거나 처리하는 데 사용된다.
[SpEL 사용 예시]
// (1)
@DistributedLock(key = "#lockName")
public void shipment(String lockName) {
...
}
// (2)
@DistributedLock(key = "#model.getName().concat('-').concat(#model.getShipmentOrderNumber())")
public void shipment(ShipmentModel model) {
...
}
ShipmentModel.java
public class ShipmentModel {
private String name;
private String shipmentNumber;
public String getName() {
return name;
}
public String getShipmentNumber() {
return shipmentNumber;
}
...
}Spring Expression Language를 사용하면 다음과 같이 Lock의 이름을 보다 자유롭게 전달할 수 있다.
[AopForTransaction]
/**
* AOP에서 트랜잭션 분리를 위한 클래스
*/
@Component
public class AopForTransaction {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Object proceed(final ProceedingJoinPoint joinPoint) throws Throwable {
return joinPoint.proceed();
}
}
AopForTransactional 클래스를 정의하여 락을 획득하고 비즈니스 로직이 정의된 메서드를 실행함으로써 @DistributedLock 이 선언된 메서드는 Propagation.REQUIRES_NEW 옵션을 지정해 부모 트랜잭션의 유무에 관계없이 별도의 트랜잭션으로 동작하게끔 설정 한 후에 반드시 트랜잭션 커밋 이후 락이 해제되게끔 처리하였다.
그렇다면 왜 트랜잭션 커밋 이후에 락이 해제되어야 하는 것일까???
간단하게 재고 감소 로직을 통한 예를 생각해보자.
만약 재고 감소 로직에서 커밋 이전에 락이 해제된다고 생각해보자. 재고가 10개인 상태에서 트랜잭션 A가 재고를 1개 감소시키고 커밋 이전에 락을 해제한다면 트랜잭션 B가 락 해제 신호를 받고 락을 획득하고 재고를 조회해보면 아직 커밋이 되지 않았기 때문에 재고가 10개로 나올 수 있다. 이 상태에서 트랜잭션 B에서도 재고를 1 감소시킨다면 개발자의 의도는 재고가 두 번 감소하였으니 재고가 8이 나와야 하지만 실제로는 트랜잭션 A, B가 각각 재고가 10인 상태에서 재고를 1 감소시켰으니 재고는 9가 되는 race codntion 현상이 발생한다.
이렇듯 트랜잭션을 커밋한 직후에 락을 해제하는 이유는 포스팅 위쪽에서 자세히 설명한 동시성 환경에서의 race condition으로 인하여 데이터 정합성이 깨지는 것을 방지하여 데이터 정합성을 보장하기 위해서이다.
※
데이터 정합성: 데이터 정합성은 데이터가 일관성 있고 정확하게 유지되는 상태를 의미한다. 시스템 내의 데이터가 서로 모순되지 않고, 신뢰할 수 있는 상태를 보장하는 것이 목표이다.
