매칭 서비스 개발 배경
저희가 만든 서비스는 타인과 관심사나 취미를 함께 공유하고 싶은 사람들을 겨냥하여 개발되었기 때문에 최소한의 노력으로 타인과 어울리고 싶은 서비스 사용자들을 위해 지역, 관심사 등을 기준으로 매칭되는 1:1 유저 매칭 서비스를 기획하고 개발하게 되었습니다.
Problem 1 : 서버 과부하
단기간에 수많은 유저가 몰릴 수 있는 매칭 서비스의 특성상 초당 10000명의 유저가 매칭 서비스에 동시에 몰려도 충분히 버틸 수 있는 서비스를 만드는 것이 기존의 설계였지만 실제로 10초에 걸쳐 점진적으로 10000개의 매칭 요청을 전송한 후 서버의 상태를 프로메테우스와 그라파나를 연동하여 모니터링해봤더니
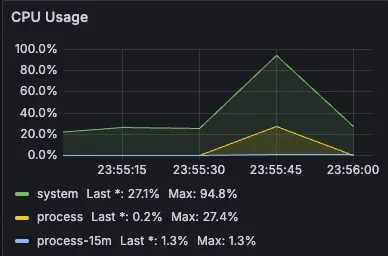
이미 해당 매칭 요청들을 처리하는 데에만 서버의 CPU의 94.8%가 사용되어 서버 과부하가 매우 심하여 실제 서비스였다면 서버의 장애로 이어져 매칭 서비스를 포함한 모든 서비스가 확실하게 셧다운되었을 심각한 상황이기 때문에 시급한 대응이 필요한 상황이라고 판단했습니다.
Solution 1 : 서버 부하 분산
이러한 매칭 트래픽 폭증으로 인한 서버 과부하 문제를 해결하기 위해 저희는 현재와 같은 단일 서버구조만으로는 한계가 있다고 판단하고 오로지 매칭 비즈니스 로직만을 따로 처리하는 매칭 서버를 증설하여 서버의 온전한 리소스를 매칭에 사용함으로써 매칭 서비스에 대한 대량의 트래픽에 대비하고 다른 모든 기능들이 존재하는 메인 서버의 부하 매칭 서버로 분산시키기로 결정하였습니다.
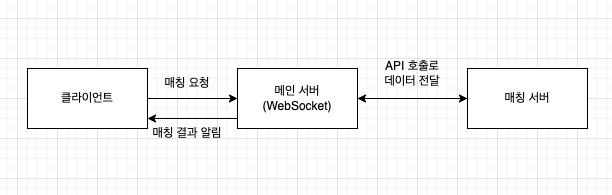
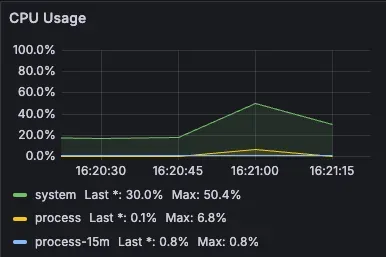
매칭 서비스를 별도의 서버로 분리한 뒤 똑같은 조건에서 이전과 같은 트래픽을 발생시켜 보니 메인 서버의 CPU 사용량이 기존 94.8%에서 50.4%까지 감소하여 여전히 안정적인 수치는 아니지만 기존 대비 46.83%의 CPU 사용량 감소율을 보여주어 서버의 분산 부하가 성공적으로 이루어졌다는 것을 확인할 수 있었습니다.
Problem 2 : 저조한 처리량
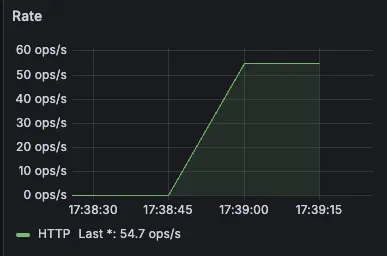
이후 처리량을 확인해보니 메인 서버의 초당 처리량이 54.7ops/s에 불과하여 성능적으로 매우 저조한 모습이 확인되어 성능 개선 또한 시급한 문제였습니다.
Solution 2 : 메세지 큐를 통한 비동기 처리
왜 이렇게 처리 성능이 저조한 것인지 생각해보니 기존의 방식은 매칭 요청이 들어오면 메인 서버가 매칭 서버의 API를 호출한 뒤 매칭 처리가 끝난 후 매칭 결과를 응답값으로 받아야 다음 요청을 처리하는 동기 방식이기 때문에 이러한 동기 방식이 성능 저하의 원인이라고 생각하고 매칭 처리가 완전히 끝날 때까지 기다리지 않아도 되어 처리 속도의 향상을 기대할 수 있는 비동기 방식을 적용하기로 결정하였습니다.
그렇다면 이제 어떤 방식으로 비동기를 적용할지 고려해봐야 했습니다. 비동기 방식을 적용하는 데에는 수많은 방법이 존재하지만 저희는 메세지 큐를 통한 비동기 처리 방식을 선택하였습니다.
저희가 메세지 큐를 통한 비동기 방식을 선택한 이유는 우선 첫 번째, 메세지 큐를 사용하면 메세지 큐의 작동 방식 덕분에 서버 부하 개선 과 처리 성능 개선 이라는 두 마리 토끼를 동시에 잡을 수 있다고 생각했기 때문입니다. 메세지 큐를 사용하면 메세지를 큐에 일시적으로 저장하고 서버의 상태와 처리 능력에 따라 순차적으로 메세지를 처리할 수 있어 트래픽 폭증시 매칭 서버의 부하를 관리하는 데에 효과적일 것이라고 생각하였습니다. 또한 메세지 큐를 사용함으로써 메인 서버는 이전과는 달리 응답을 기다리지 않고 단순히 메세지 큐에 데이터를 전송하고 다음 요청을 비동기적으로 처리할 수 있어 매칭 요청 처리의 성능의 향상 또한 기대할 수 있다는 점을 고려하였습니다.
두 번째 이유는 메세지 큐를 사용하면 여타 다른 메인 서비스들과 메인 서비스간에 결합을 느슨하게 할 수 있어 그저 부가기능인 매칭 서비스에서 발생한 장애가 메인 서비스로 전파되는 것을 방지할 수 있다는 점 때문이었습니다.
저희가 고려한 메세지 및 이벤트 브로커 선택지는 Redis Pub/Sub, RabbitMQ, Kafka 3가지였습니다.
우선 Redis Pub/Sub의 경우 데이터 영속성이 아예 보장되지 않아 메세지 처리가 실패한 경우 해당 메세지가 소실된다는 점이 우려되어 선택지에서 제외하였고 Kafka는 실시간 처리량이 높고 대규모 데이터 전송에 유리하며 데이터 영속성이 보장된다는 강력한 장점이 존재하지만 RabbitMQ에 비해 초기 설정이 복잡하고 초기 학습 비용이 높아 막대한 대규모의 트래픽의 발생할 염려가 적고 매칭 시스템 특성상 매칭 데이터는 처리가 끝나면 영속성이 보장되어야할 만큼 중요한 데이터는 아니라고 판단하여 굳이 Kafka를 적용할 필요를 느끼지 못하여 RabbitMQ를 적용하였습니다.
메인 서버와 매칭 서버간에 RabbitMQ를 적용시켜 비동기 방식으로 매칭 처리가 이루어지게 설정한 후 같은 조건에서 모니터링해보니

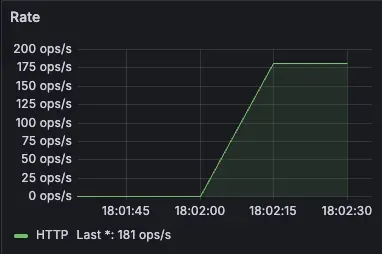
이전과 달리 서버간 API 호출을 통한 동기적 처리가 아니라 메세지 큐를 통해 비동기로 매칭이 처리되어 54.7ops/s에 불과했던 수치가 181ops/s까지 기존 처리량에 비해 처리량이 3.31배 증가했음을 확인할 수 있었습니다.
Problem 3 : 큐 병목 현상 발생
성능을 더 개선하기 위해 두 서버 사이에서 데이터를 전달하는 RabbitMQ의 동작을 프로메테우스와 그라파나를 통해 모니터링해보았더니 메세지 큐 안에 적재되어 있는 데이터 양을 나타내는 “Message ready to be delivered to consumers” 항목에서
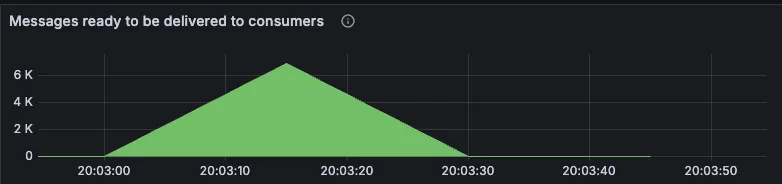
프로듀서의 데이터 전송량에 비해 컨슈머의 데이터 처리량이 훨씬 떨어져 10000건의 데이터를 전달하는 데에 최대 7000건의 데이터가 메세지 큐 안에 쌓여있는 병목 현상이 발생하여 매칭 요청 처리 성능이 저하되고 있다는 것을 확인할 수 있었습니다.
Solution 3 : RabbitMQ 클러스터 적용
이러한 병목 현상으로 인한 성능 저하를 해결하기 위해 기존 1개의 RabbitMQ 서버를 운영하던 것을 2개의 RabbitMQ를 더 추가하여 총 3개의 RabbitMQ를 생성한 후 RabbitMQ 클러스터를 생성하여 기존 1개에서 처리하던 전송-수신 작업을 3개의 노드에서 병렬적으로 작업하게 설정하였습니다.
networks:
rabbitmq-net:
driver: bridge
services:
rabbit1:
image: rabbitmq:management
hostname: rabbit1
container_name: rabbit1
ports:
- "15672:15672" # RabbitMQ UI
- "5672:5672" # AMQP
- "15692:15692" # RabbitMQ Prometheus
networks:
- rabbitmq-net
environment:
RABBITMQ_ERLANG_COOKIE: 'secret'
RABBITMQ_DEFAULT_USER: admin
RABBITMQ_DEFAULT_PASS: 1234
rabbit2:
image: rabbitmq:management
hostname: rabbit2
container_name: rabbit2
networks:
- rabbitmq-net
environment:
RABBITMQ_ERLANG_COOKIE: 'secret'
rabbit3:
image: rabbitmq:management
hostname: rabbit3
container_name: rabbit3
networks:
- rabbitmq-net
environment:
RABBITMQ_ERLANG_COOKIE: 'secret'# rabbit2를 rabbit@rabbit1가 속한 클러스터에 합류
docker exec -it rabbit2 rabbitmqctl stop_app
docker exec -it rabbit2 rabbitmqctl join_cluster rabbit@rabbit1
docker exec -it rabbit2 rabbitmqctl start_app
# rabbit3를 rabbit@rabbit1가 속한 클러스터에 합류
docker exec -it rabbit3 rabbitmqctl stop_app
docker exec -it rabbit3 rabbitmqctl join_cluster rabbit@rabbit1
docker exec -it rabbit3 rabbitmqctl start_app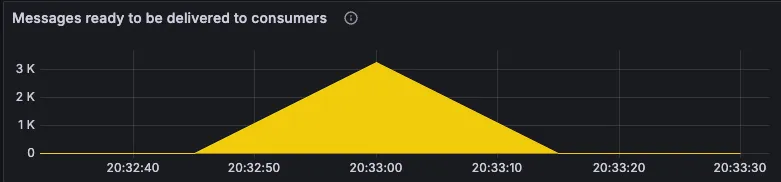
3개의 노드를 클러스터로 적용한 후 동일한 조건에서 10초 동안 10000개의 매칭 요청을 발생시켜보았더니 기존 7000개까지 큐에 적재되던 데이터가 3000개까지 대폭 완화되어 데이터 병목 현상이 기존 대비 약 57.14% 감소된 것을 확인할 수 있었습니다.
