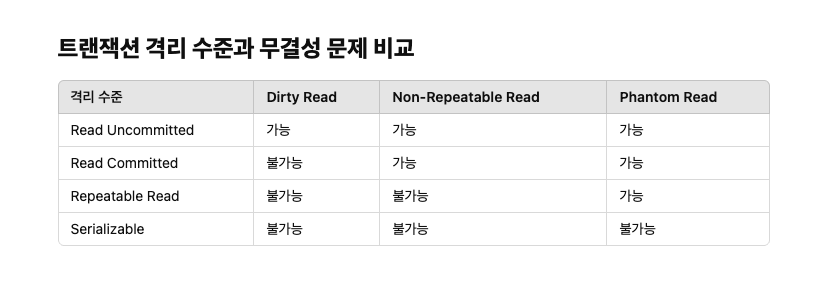
트랜잭션 격리 수준이란
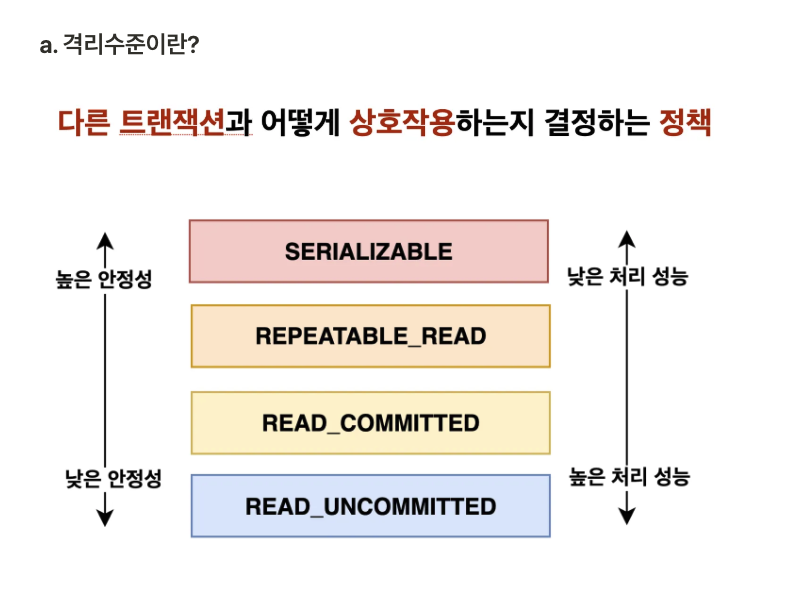
트랜잭션 격리 수준(Transaction Isolation Level): 트랜잭션 격리 수준은 데이터베이스에서 여러 트랜잭션이 동시에 실행될 때, 트랜잭션 간의 데이터 간섭을 방지하기 위한 동작 방식을 설정하는 것이다. 어떤 데이터에 접근을 허용하고 차단할지를 결정하여 데이터 무결성을 유지하려는 것에 목적이 있다.
트랜잭션 격리 수준은 낮은 수준일수록 성능은 좋아지지만 데이터 무결성 문제가 발생할 가능성이 높아지고, 높은 수준일수록 무결성은 잘 보장되지만 성능에 영향을 줄 수 있다.
트랜잭션 격리 수준 종류과 각 문제점들
개발을 하다 보면 상황에 따라, 비즈니스 요구 사항에 따라 트랜잭션에 어떤 격리 수준을 적용해야 하는지 판단해야 하는 상황이 발생한다.
예를 들어, 요금 결제같은 정말 중요한 작업에서는 가장 성능이 느리지만 가장 안전한 SERIALIZABLE을, 하지만 약간의 충돌이 발생해도 무방하지만 성능이 중요시되는 작업에서는 READ_UNCOMMITED을 고려해보는 등 어떤 격리 수준이 현재 상황에 적절하진 잘 판단할 수 있어야 한다.
이제 각각의 격리수준 종류에 대해 자세히 알아보자.
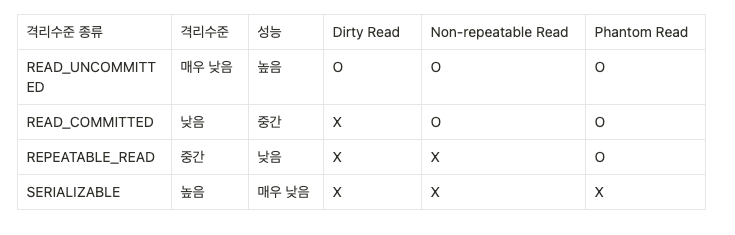
1. READ_UNCOMMITED & Dirty Read

Read Uncommitted (커밋되지 않은 읽기 허용)
- 특징: 가장 낮은 수준의 격리. 다른 트랜잭션이 아직 커밋하지 않은 데이터를 읽을 수 있음.
- 문제 발생 가능: Dirty Read, Non-Repeatable Read, Phantom Read.
- 장점: 동시성이 가장 높아 성능이 좋음.
- 사용: 실시간 데이터 업데이트가 빈번하고 약간의 데이터 불일치가 허용되는 경우.
실제 예시를 통해 알아보자.
<왼쪽: 세션 1, 오른쪽: 세션 2>
MySQL에서 세션 1,2에서 두 개의 트랜잭션이 같은 DB에서 동시에 진행되는 상황을 가정해보자.
<세션 1, 2>
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;두 트랜잭션의 격리 수준을 모두 READ UNCOMMITED로 설정해주고
<세션 1, 2>
SET autocommit = 0;AutoCommit을 취소하여 두 개의 트랜잭션을 모두 수동관리 설정해주고
<세션 1, 2>
START transaction;세션 1,2의 트랜잭션을 모두 시작해주자.
(트랜잭션 격리 수준을 변경하려면 트랜잭션을 명시적으로 시작해야 한다.
<세션 1, 2>
SELECT * from course;DB의 수강 과목을 뜻하는 course라는 테이블을 조회해보면
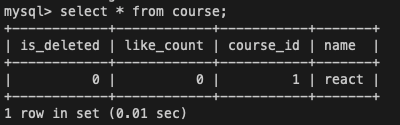
현재 세션 1,2 모두 동일하게 react라는 과목이 존재함을 확인할 수 있다.
<세션 1>
UPDATE course SET name="java" WHERE course_id=1;이 때 세션 1에서 과목의 이름을 java로 바꾸고
<세션 2>
SELECT * from course;세션 2에서 다시 테이블을 조회해보면
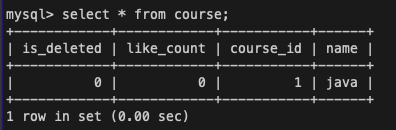
세션 1에서 한 update 결과가 세션 2에서도 반영한 것을 확인할 수 있다.
즉, READ_UNCOMMITED을 사용하면 다른 트랜잭션에서 변경한 아직 커밋되지 않은 데이터도 실시간으로 읽을 수 있는 Dirty Read(더티 리드) 문제가 발생한다.
(가장 낮은 격리 수준이기 때문에 Non-Repeatable Read, Phantom Read 문제점도 발생하지만 해당 문제들은 이후의 다른 격리 수준에서 다루겠다.)
Dirty Read(더티 리드): Dirty Read는 데이터베이스 트랜잭션에서 발생할 수 있는 트랜잭션 격리 수준 관련 문제 중 하나로, 한 트랜잭션에서 아직 커밋되지 않은 데이터를 다른 트랜잭션이 실시간으로 읽는 현상을 말한다.
그럼 Dirty Read는 어떠한 문제를 일으킬 수 있을까???
<세션 1>
rollback;만약 세션 1에서 롤백하여 다시 과목 이름을 react로 돌려버려도 세션 2에서는 다시 테이블을 재조회하지 않는 이상은 과목 이름이 react로 반영되어 있어 Dirty Read가 발생하면 데이터 무결성이 깨져 버리고 잘못된 데이터를 조작할 수 있다는 의도치 않은 문제점이 발생한다.
2. READ_COMMITED & Non-repeatable Read

Read Committed (커밋된 읽기)
특징: 다른 트랜잭션이 커밋한 데이터만 읽을 수 있음.
문제 발생 가능: Non-Repeatable Read, Phantom Read.
장점: Dirty Read 방지.
사용: 일반적인 트랜잭션에서 가장 널리 사용됨.
※ READ_COMMITED는 대부분의 데이터베이스의 기본 격리 수준이지만 현재 포스팅에서 다루는 MySQL의 경우에는 기본 격리 수준이 REPEATABLE_READ이다.
READ_COMMITED는 READ_UNCOMMITED와는 달리 다른 트랜잭션에서 커밋하여 데이터베이스에 완전히 반영된 데이터만 읽을 수 있기 때문에 Dirty Read가 발생하지 않아 데이터 일관성 보장 수준이 더 높다.
다만 데이터 안정성이 더 높아졌기 때문에 READ_UNCOMMITED에 비해 성능과 동시성 처리가 더 뒤떨어진다는 단점도 존재한다.
직접 실습을 통해 알아보자.
<왼쪽: 세션 1, 오른쪽: 세션 2>
<세션1, 2> 격리수준(READ_COMMITTED) 설정
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;<세션1, 2> 트랜잭션 시작
START transaction;<세션1, 2> course 데이터 조회
SELECT * FROM course;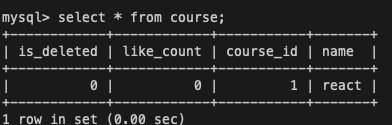
아직까지는 당연히 세션 1,2 모두 같은 데이터를 가지고 있다.
<세션1> course 데이터 변경
UPDATE course SET name="java" WHERE course_id=1;이제 세션 1에서 아까처럼 과목 이름을 java로 바꿔보자.
<세션1, 2> course 데이터 조회 확인
SELECT * FROM course;변경 이후 세션 1,2에서 각각 course 테이블을 확인해보면
<세션 1>
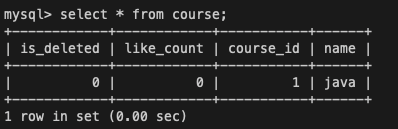
데이터를 update로 직접 수정한 세션 1은 아직 커밋되지 않았더라도 당연히 데이터가 java로 변경된 것을 확인할 수 있지만
<세션 2>
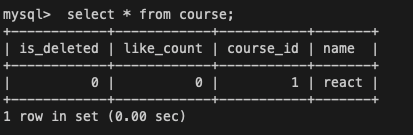
데이터를 직접 변경하지 않은 세션 2에서는 데이터가 아직 커밋되었지 않기 때문에 변경되지 않은 기존의 데이터인 react가 조회되는 것을 확인할 수 있다.
<세션1> 커밋
commit;여기서 데이터를 커밋하면
<세션2> course 데이터 조회
SELECT * FROM course;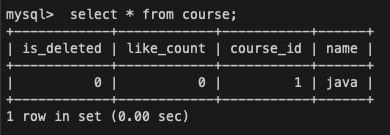
세션 2에서도 비로소 수정된 데이터를 조회할 수 있다.
하지만 세션 2에서 아직 트랜잭션이 끝나지도 않았는데 다른 트랜잭션들에 의해 데이터 값들이 변경되는 것이 정말 옳은 것일까???
read_committed 격리 수준에서는 한 트랜잭션이 데이터를 읽고 나서 같은 데이터를 다시 읽을 때, 다른 트랜잭션이 그 사이에 해당 데이터를 수정하거나 삭제할 수 있다. 그래서 두 번째 읽기 결과가 첫 번째 읽기 결과와 다를 수 있다.
이로 인해 발생하는 문제가 바로 Non-repeatable read 문제이다.
Non-repeatable read: non-repeatable read 문제는 트랜잭션의 격리 수준에서 발생하는 문제 중 하나로, 트랜잭션이 동일한 데이터를 두 번 읽을 때 그 사이에 다른 트랜잭션에 의해 데이터가 변경될 수 있는 상황을 의미한다. 이로 인해 같은 쿼리를 두 번 실행할 때 서로 다른 결과가 나올 수 있다.
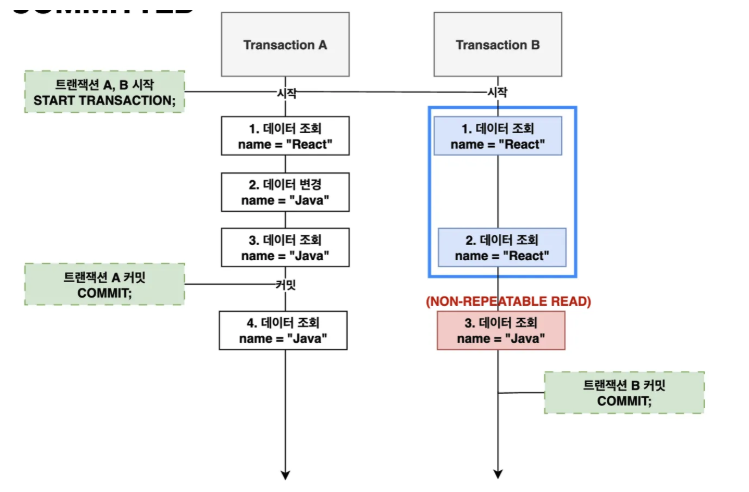
전처럼 트랜잭션 A 에서 롤백이 발생한 경우, 트랜잭션 B 가 영향을 받지는 않는다.
하지만 롤백이 아니라 트랜잭션 A 에서 데이터 변경이 성공적으로 커밋된다면, 트랜잭션 B는 이제는 새로이 변경된 데이터 값을 읽어 처리하기 때문에 예상치 못한 동작이 발생할 수 있다.
같은 트랜잭션 내에서 동일한 데이터를 여러 번 읽을 때 그 값이 달라져 데이터 일관성을 보장할 수 없는 문제가 바로 Non-repeatable Read 문제다.
3. REPEATABLE_READ & Phantom Read

특징: 한 트랜잭션에서 같은 데이터를 여러 번 읽어도 결과가 동일하도록 보장.
Repeatable Read
문제 발생 가능: Phantom Read.
장점: Dirty Read, Non-Repeatable Read 방지.
사용: 높은 무결성이 요구되는 경우, 예를 들어 은행 계좌 잔액 계산.
Repeatable Read는 말 그대로 특정 트랜잭션 내에서 트랜잭션이 끝날 때까지 데이터를 여러 번 읽어와도 처음에 읽어온 데이터를 보장시켜주는 격리 수준이다.
직접 실습으로 해보자.
<왼쪽: 세션 1, 오른쪽: 세션 2>
<세션1, 2> 격리수준(REPRETABLE READ) 설정
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;세션 1,2의 격리 수준을 모두 REPEATABLE_READ로 맞춰주고
<세션1, 2> 트랜잭션 시작
START transaction;세션 1,2 각각 트랜잭션을 시작해보자.
<세션1, 2> 데이터조회
SELECT * FROM course;트랜잭션을 시작하고 세션 1,2 에서 데이터를 조회하면
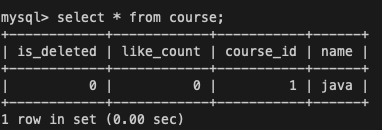
트랜잭션 시작 이후 별도의 데이터 수정이 없었기 때문에 세션 1,2 모두 초기값으로 course 테이블의 name 값이 방금 READ_COMMITED에서 바꾼대로 java인 것을 확인할 수 있을 것이다.
<세션1> 데이터 변경
UPDATE course SET name="spring" WHERE course_id=1;세션 1에서 course의 이름을 기존 java에서 spring으로 바꾼 후에
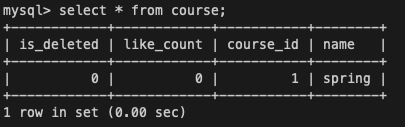
<세션2> 데이터 조회
SELECT * FROM course;세션 2의 트랜잭션에서 데이터를 다시 조회해보면
세션 1에서 커밋을 하지 않고 데이터를 수정한 상태와는 달리 세션 2에서는 데이터가 수정되지 않고 그대로 java인 것을 보아 Dirty Read 문제가 발생하지 않은 것을 확인할 수 있다.
<세션 1> 변경된 데이터 커밋
commit;세션 1에서 커밋하여 바뀐 데이터를 DB에 영구반영시킨 뒤에
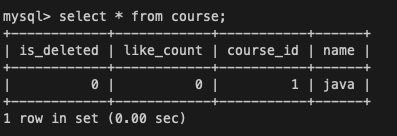
<세션2> 데이터 조회
SELECT * FROM course;세션 2에서 다시 데이터를 조회해보면
최초 조회, 직전 조회와 마찬가지로 name이 java 그대로인 것을 확인할 수 있어 Non-repeatable read 문제도 발생하지 않을 것을 확인할 수 있다.
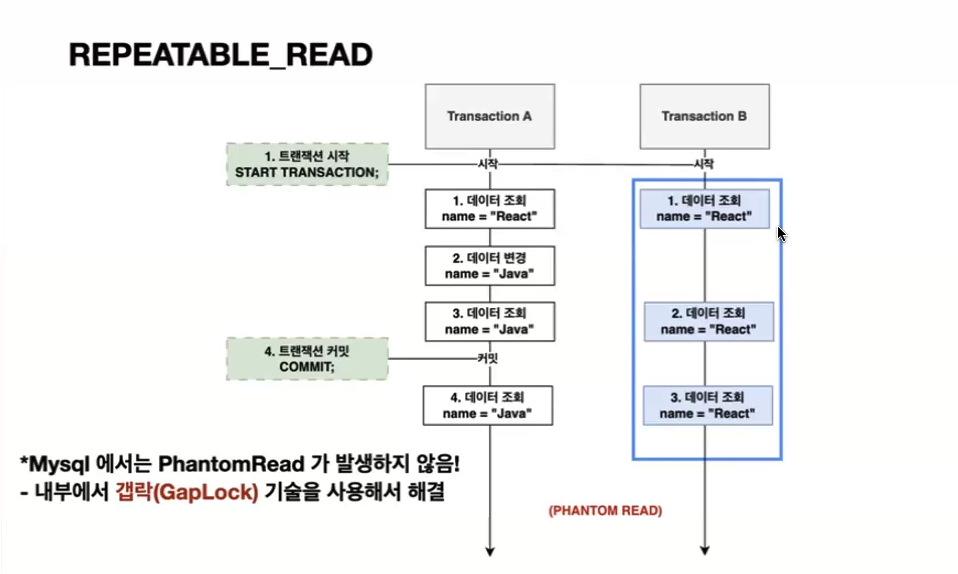
마지막으로 요약하자면 REPEATABLE_READ는 특정 트랜잭션에서 데이터들의 값 수정이 일어나고 그에 따른 커밋, 롤백이 일어난다 하더라도 변경 이전에 다른 트랜잭션이 이미 조회한 데이터들의 값에 한해서는 트랜잭션이 끝날 때까지 변하지 않고 보호되는 격리 수준이다.
하지만 REPEATABLE_READ에서는 Phantom Read라는 새로운 문제점이 발생한다.
※ 다만 MySQL, MariaDB에서는 Gap Lock이라는 자체 기술을 사용하여 문제점을 해결했기 때문에 Phantom Read가 발생하지 않는다.
그렇다면 Phantom Read란 무엇일까???
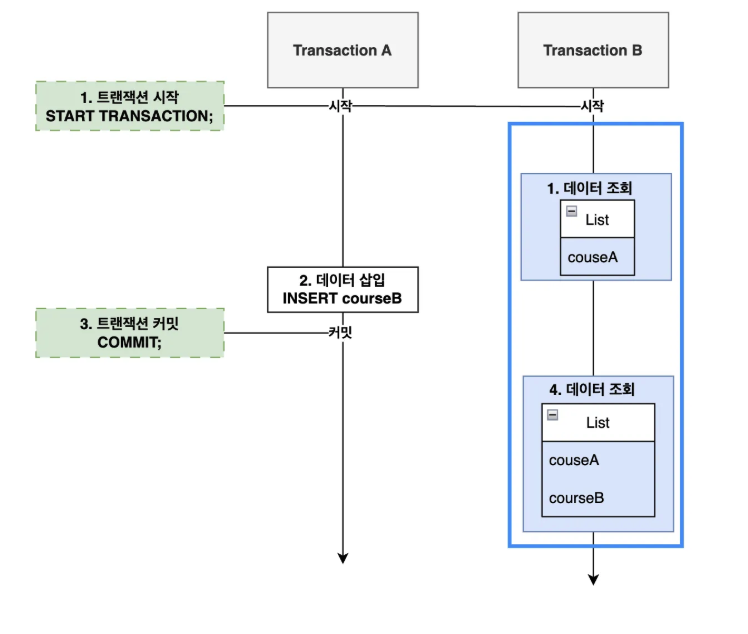
Phantom Read: Phantom Read는 데이터베이스 트랜잭션에서 발생하는 일관성 문제 중 하나로, 트랜잭션이 동일한 조회 쿼리를 두 번 이상 실행할 때, 중간에 다른 트랜잭션이 데이터를삽입하거나삭제하여 첫 번째 조회에서는 없던 레코드(유령 데이터)가 두 번째 조회에서 나타나거나 사라지는 데이터 불일치 현상을 말한다.
즉, Phantom Read는 특정 트랜잭션에서 데이터 반복 조회시 다른 트랜잭션에서의 데이터 삽입, 삭제로 인하여 데이터 결과 집합이 달라지는 문제이다.
Phantom Read는 가장 엄격한 격리 수준인 SERIALIZABLE에서 해결이 가능하다.
4. SERIALIZABLE

Serializable
특징: 가장 높은 수준의 격리. 트랜잭션이 순차적으로 실행되는 것처럼 동작.
문제 발생 가능: 없음 (Dirty Read, Non-Repeatable Read, Phantom Read 모두 방지).
단점: 동시성 처리 능력 저하, 성능 부담.
사용: 무결성이 최우선인 상황, 예: 금융 시스템, 주식 거래.
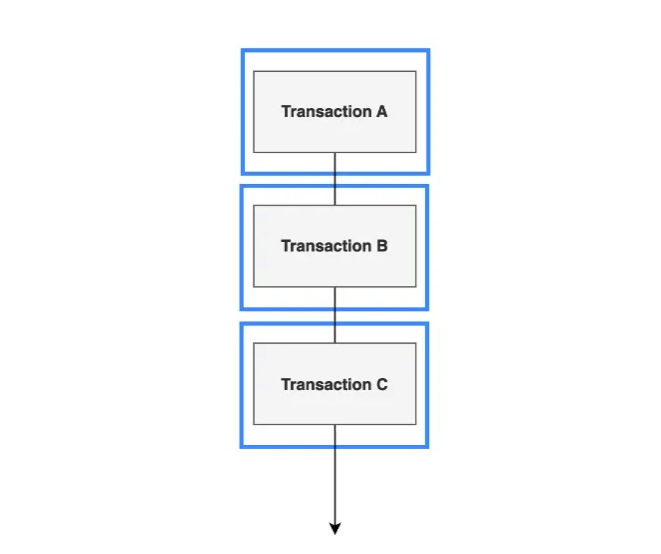
SERIALIZABLE에서는 이전에 발생했던 모든 문제점들인 Dirty Read, Non-Repeatable Read, Phantom Read가 모두 방지된다.
이미지처럼 모든 데이터베이스 작업이 직렬적으로 처리되어 모든 트랜잭션이 완전한 격리가 보장되어 다른 트랜잭션에 의한 간섭이 일어나지 않기 때문이다. 하지만 모든 작업이 직렬적으로 이루어지기 때문에 이로 인하여 동시성 처리 성능이 매우 떨어진다.
실습을 통해 알아보자.
<왼쪽: 세션 1, 오른쪽: 세션 2>
<세션1, 2> 격리수준(SERIALZABLE) 설정
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE;세션 1,2 모두 격리수준을 SERIALZABLE로 설정하고
<세션1, 2> 트랜잭션 시작
START transaction;각각 트랜잭션을 시작해보자.
<세션1, 2> 조회
SELECT * FROM course;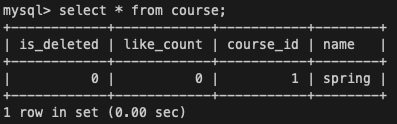
아직까지는 아무런 작업을 하지 않았기 때문에 모두 course의 name이 spring으로 조회된다.
<세션1> 데이터 수정
UPDATE course SET name="java" WHERE course_id=1;
여기서 세션 1에서 이름을 java로 바꾸어보면 이전과 달리 Query Ok 문구가 뜨지 않고 데이터 쓰기 작업이 발생하는 즉시 멈춰버린다. 왜냐하면 다른 트랜잭션이 끝나기를 대기하고 있는 상황이기 때문이다.
Serializable 격리 수준에서는 동일 데이터를 다루는 다른 트랜잭션이 완료되어야 특정 트랜잭션의 쓰기 작업이 완료된다.

ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction일정 시간(기본 1분) 내에 다른 트랜잭션이 완료되지 않으면 위의 문구가 출력되고 다시 롤백되어버린다.
<세션2> 커밋
commit;세션 2에서 커밋이나 롤백으로 트랜잭션을 끝내야 비로소

세션 1에서 한 쓰기 작업이 반영되어 Query Ok 문구가 출력된다.
스프링에서의 트랜잭션 격리 수준(ISOLATION) 사용 방법
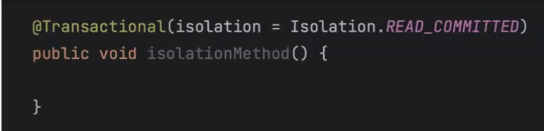
스프링에서의 트랜잭션 ISOLATION 사용 방법은 매우 간단하다.
어떤 격리 수준을 사용할 것인지 @Transactional 애노테이션 옆에 옵션을 넣어 @Transactional(isolation = Isolation.READ_COMMITTED) 설정해주면 된다.
