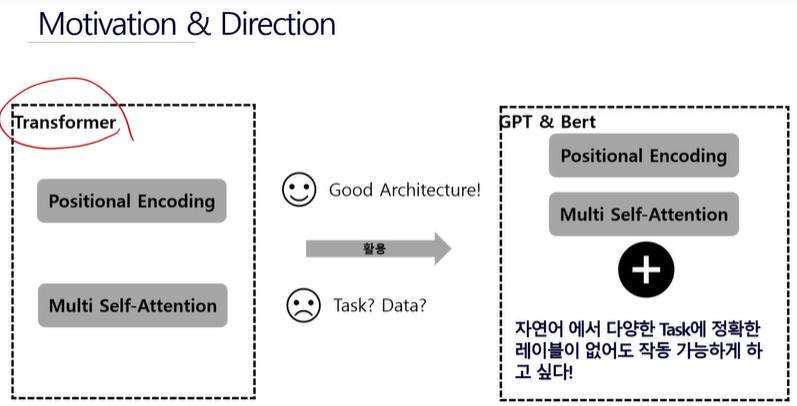
GPT를 사용하는 이유
자연어 데이터의 특징
tabular dataset
- 각각의 데이터 샘플들이 구성하고 있는 features는 독립적
이미지
- 이미지 안의 의미있는 정보는 위치에 무관
- convolution 연산은 위치에 무관한 지역적인 정보를 추출하기 좋은 연산
반연 자연어 데이터의 경우
- 문장을 구성하고 있는 단어들의 위치가 변해서는 안됨
- 단어들 간의 관계가 중요하고 하나의 단어만 바뀌거나 추가되어도 전혀 다른 의미를 가질 수 있음
summary
- GPT를 구성하고 있는 모델은 TRANSFORMER에서 가져온 것이다.
- bert, gpt의 경우 특히 자연어 데이터에 특화된 프레임워크이다.
- 자연어 데이터는 단어와 단어들 사이의 순서와 관계가 중요하다,
- 문장이 갖고 있는 문맥을 알고리즘이 이해할 수 있게 하는 것이 어렵다.
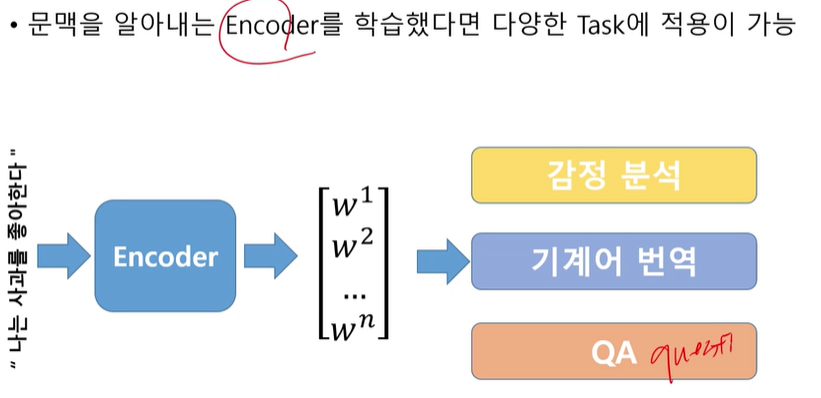
자연어 처리 task
하나의 문장을 여러 개로 나누고 나눈 토큰들의 결합분포로 문장에 대해서 확률을 계산
p(W) = p(w1, w2, w3)
기존연구
문장은 순서를 가지고 있으니, 문장의 처음부터 끝까지 순서대로 입력을 받아서 최종적으로 벡터를 생성하자
RNNs
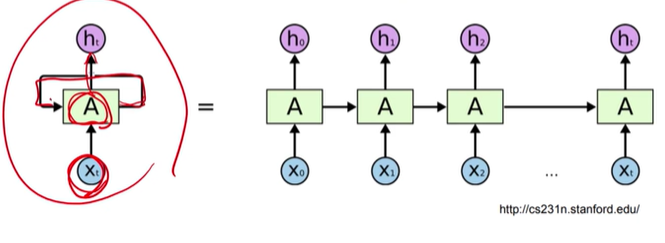
단점
- 중요한 단어들이 처음 부분에 있다면 정보를 잃어 버리지 않을까?

문과생 데이터사이언티스트되기 프로젝트