캐시(Cache)
개요
CPU와 메인 메모리(RAM) 사이에 있는 고속 임시 저장 공간
- 자주 사용하는 데이터를 미리 저장해서 빠르게 뽑아올수있는곳
- 캐시는 물리적인 장치라기보다는 CPU 내부에서 자동으로 동작하는 추상적인 매커니즘에 가까움
- 물리적으로 존재하는 부분도 있음 : L1 ~ L3 캐시는 CPU 칩 안에 실제 회로 형태로 존재 하지만 직접 관리하지 않음(RAM처럼 명령할수 없고 CPU가 스스로 캐시에 넣고 안쓰면 버림)
지역성
1) 시간 지역성
최근 사용한 데이터를 또 쓸 확률이 높음(캐릭터가 계속 뛸때 달리는 애니매이션 반복 / 체력 값을 매 프레임 확인할시)
2) 공간 지역성
사용한 데이터 주변도 함께 쓸 가능성이 있음(LandScape 타일 한칸 로딩 시 주변 타일도 미리 불러둠)
왜 쓰냐
- RAM에서 데이터를 가져오는 속도는 상대적으로 매우 느림
- CPU는 너무 빠르고 RAM은 매우 느려서 그 사이를 메꾸기 위해 사용
- 때문에 자주 쓰는 데이터를 미리 CPU가까이 저장하고 또 쓸때 즉시 처리할수있게끔해줌
-> 빠르게 반복되는 연산(물리 / 충돌 / 이동)은 캐시에 올라가야 프레임 드랍없이 실행됨(Character Movement / Line Trace / Lumen 등)
어떻게 쓰냐
- 우리는 캐시에 직접 뭘 넣을수가 없음(CPU가 판단)
-> 그렇기 때문에 캐시에 잘 들어가게 유도 하는것이 중요함
-> Tick() 최적화 : 동일 구조체 필드에 순차적으로 접근해서 공간 지역성을 확보
-> 다수의 Actor 반복 꼐산 : 연속된 배열(TArray)을 사용해서 캐시 히트율 증가 유도
-> AI BT : 상태 캐싱 : 매 틱마다 계산하지 않고 저장해서 재사용
-> Tarray<>에 적 데이터를 담고 순차 루프에서 접근하는식
캐시 내부 구조
캐시 안에 어떤 용도로 나뉘어 저장됨?
- Instruction Cache (I-Cache) : 실행할 명령어들을 저장함 (함수 코드, 로직 흐름)
- Data Cache (D-Cache) : 연산에 사용되는 실제 데이터를 저장함 (변수, 구조체 값 등)
직접 지정 불가. CPU가 알아서 데이터 주소 해시값을 바탕으로 저장 위치를 찾음현대 대부분의 CPU에서는 L1캐시에 명령어/데이터 캐시가 분리되어있음. -> 접근이 빠르기 때문
L2/L3 캐시는 명령어/데이터를 통합해 저장하는 구조가 일반적 -> 속도보다는 용량과 공유성에 초점을 둠
직접 지정 불가. CPU가 데이터 주소의 해시값 또는 Index/Tag 방식으로 자동으로 저장 위치를 계산함 (맵핑(Mapping))
-> L1: Tick, BT Task, AnimUpdate, PhysicsUpdate 같은 짧고 반복적인 명령어들이 주로 올라감
-> L2~L3: UObject 참조, BTMemory, Actor Component 상태 값들이 이쪽에서 접근
-> 구조체 기반으로 짜인 TArray< FVector > 같은 데이터는 D-Cache로 자주 접근됨
캐시 구현 구조
캐시가 데이터를 어떤 규칙으로 저장함?
1) Direct-Mapping
1개의 주소에 1개의 캐시라인사용(빠름 / 충돌 위험 높음)
2) Fully-Associative
아무 캐시 라인에 저장가능(충돌 없지만 검색 느림)
3) Set-Associative Cache
현대 CPU에서 가장 많이 사용하는 구조
Set-Associative Cache 어떻게?
1) 전체 캐시를 여러개의 셋(Set)으로 나눔
2) 각 Set은 여러 개의 캐시 라인(Slot)을 가짐 (2-Way : 2개 슬롯)
슬롯이 다 찼을 경우엔 가장 오래된 데이터 제거 (LRU, Least Recently Used)
3) 새 데이터가 오면 주소를 기반으로 특정 Set이 자동 결정하고 그 Set 안에서 비어있는 라인이 있으면 저장, 없으면 오래된 항목 제거 (LRU) 덕분에 충돌이 적으면서도 검색 속도도 빠름
-> 여러 Actor들이 유사한 Tick, 구조체 패턴을 가지면 캐시 Set 충돌이 발생 가능
-> TArray<>를 쓸 때, 모든 적의 구조체 크기/정렬이 같으면 특정 Set에만 몰릴 수 있음
-> 이럴 땐 LRU로 덜 사용된 캐시가 제거되므로 불필요한 캐시 미스 발생 가능성 있음
캐시 라인
- 캐시의 최소 단위는 1줄(라인)
- 보통 64바이트(512비트) 정도의 고정 크기
- 캐시에 한번에 데이터를 가져올 때, 라인 단위로 가져옴
-> 캐시 라인은 한 번에 연속된 64바이트를 가져오므로,
배열처럼 인접한 메모리 구조를 사용할 경우 한번에 여러 데이터를 가져올 수 있어
캐시 히트율이 높아지고 성능이 향상됨
-> FTransform이나 FVector가 배열로 연속된 메모리에 있을때 캐시 라인 1개로 여러 데이터 읽을 수 있음
-> 구조체를 TArray가 아닌 포인터 배열로 만들면 다른 위치에 있는 메모리를 불규칙하게 접근해서 캐시 라인 히트율을 저하시킴예시
Good
- 모두 4바이트 정렬된 float -> 인접 메모리에 배치되어서 캐시 라인 접근 1번이면 됨
Bad
- 중간에 패딩이 생기고 캐시 라인 접근이 2번 이상 필요할 수 있음
-> 메모리 낭비 + 캐시 미스 발생 가능성 증가
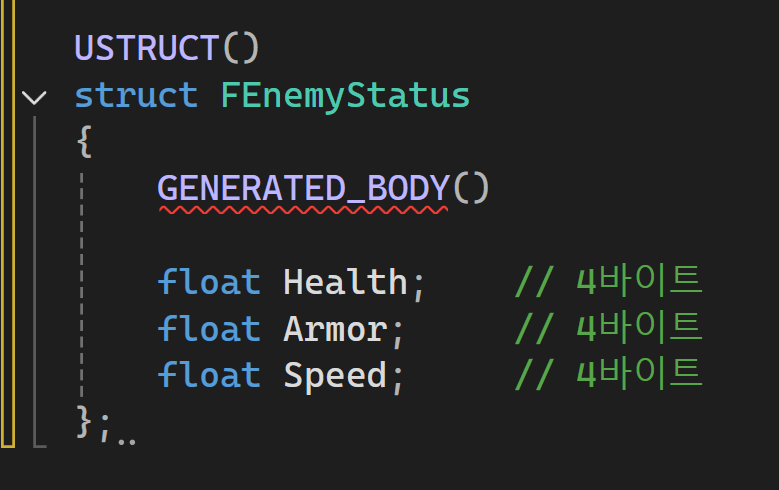
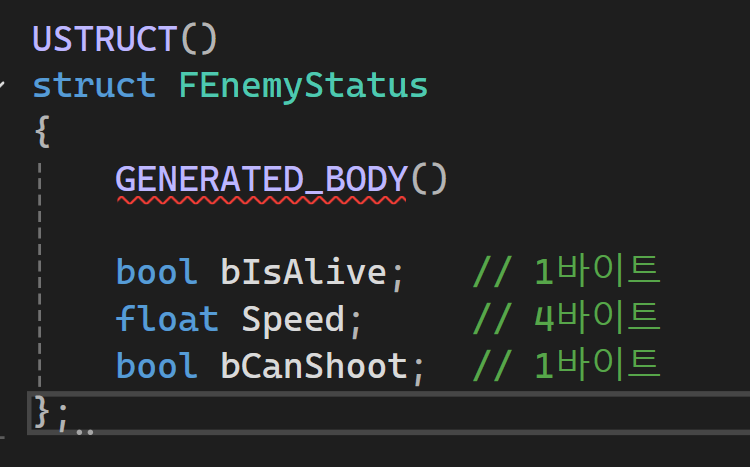
패딩(Padding)?
- 메모리 정렬을 위해 구조체 사이에 자동으로 채워지는 빈 공간
- 1파이트와 4바이트가 있는 구조체일때 중간에 3바이트 패딩이 자동으로 들어감(정렬 보정) -> 패팅이 많으면 캐시 라인 낭비 -> 캐시 미스 가능성 높아짐
-> 구조체에 bool / FVecgtor / float / bool 처럼 섞어 쓰면 정렬 비효율적이기 때문에 FVector / float / bool 순으로 정렬해 패딩을 최소화시키면 좋음
캐시 미스?
- CPU가 필요한 데이터가 캐시에 없는 상황으로 RAM에서 다시 가져와야하니까 훨씬 느림 -> 게임 중에는 프레임 드롭/지연으로 이어질수 있음
- L1에 없네? -> L2 -> L3 -> RAM -> SSD/HDD 순으로 계층적 조회함
->언리얼에서는 TArray < Struct >같은 연속 메모리 배열을 추천(불규칙한 포인터 배열 X)
-> 포인터 배열로 구성된 AI 행동 루틴이 많을 경우 매 틱마다 다양한 주소를 접근해 캐시 미스 증가시킬수있음
-> UObject* 참조가 많은 경우에도 위치가 흩어져 있어 캐시 미스 유발 가능성 있음
언리얼 내부에서도 이미 캐시 최적화가 되어있음
- FTransform, FVector, FRotator 구조체는 4/8 바이트 단위 정렬로 최적화되어 있음
- UObjet도 연속 접근보단 Index 기반 / WeakRefernce로 접근 시 캐시 효율 감소
- UObject는 포인터 기반이라 연속 접근엔 불리하므로 필요 시 Index 배열로 캐시 친화적 접근 유도 가능
